ELK 构建 MySQL 慢日志收集平台详解
ELK 介绍
ELK 最早是 Elasticsearch(以下简称ES)、Logstash、Kibana 三款开源软件的简称,三款软件后来被同一公司收购,并加入了Xpark、Beats等组件,改名为Elastic Stack,成为现在最流行的开源日志解决方案,虽然有了新名字但大家依然喜欢叫她ELK,现在所说的ELK就指的是基于这些开源软件构建的日志系统。
我们收集mysql慢日志的方案如下:
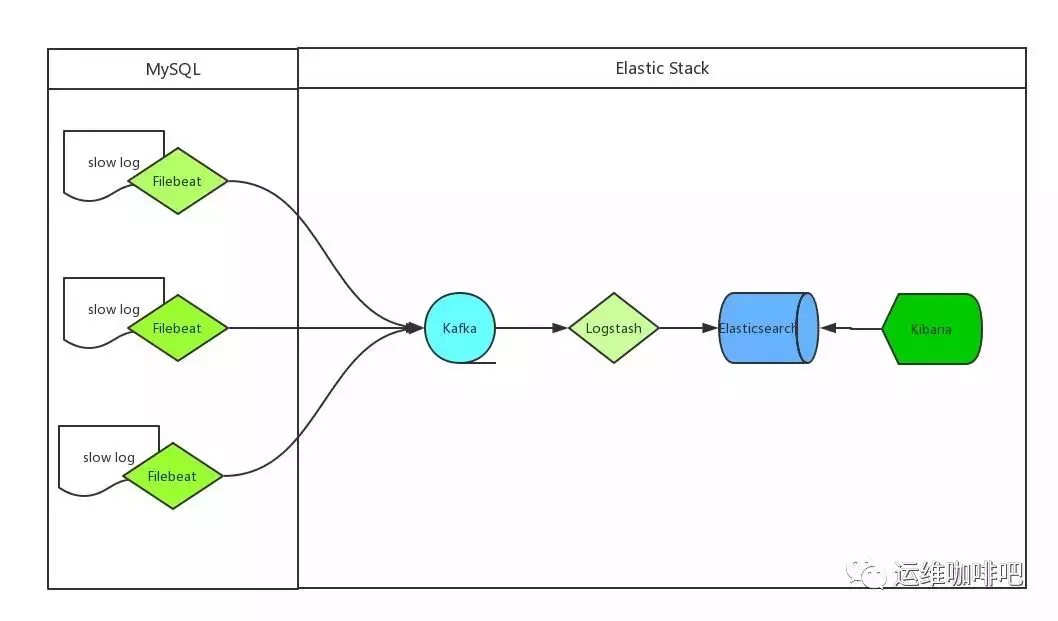
mysql 服务器安装 Filebeat 作为 agent 收集 slowLog
Filebeat 读取 mysql 慢日志文件做简单过滤传给 Kafka 集群
Logstash 读取 Kafka 集群数据并按字段拆分后转成 JSON 格式存入 ES 集群
Kibana读取ES集群数据展示到web页面上
慢日志分类
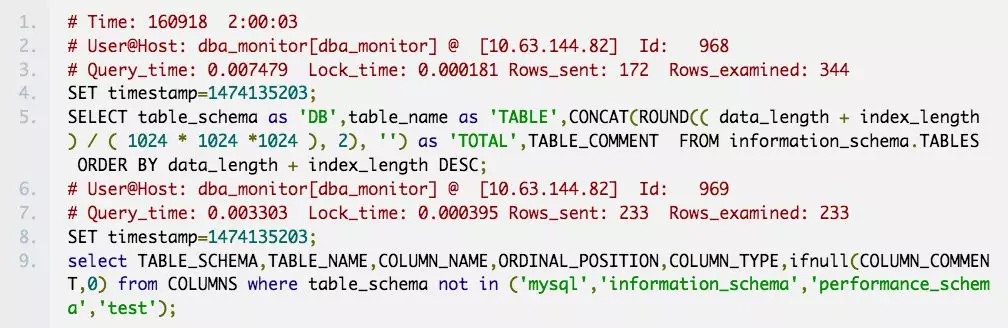
目前主要使用的mysql版本有5.5、5.6 和 5.7,经过仔细对比发现每个版本的慢查询日志都稍有不同,如下:
5.5 版本慢查询日志

5.6 版本慢查询日志

5.7 版本慢查询日志

慢查询日志异同点:
每个版本的Time字段格式都不一样
相较于5.6、5.7版本,5.5版本少了Id字段
use db语句不是每条慢日志都有的
可能会出现像下边这样的情况,慢查询块# Time:下可能跟了多个慢查询语句
处理思路
上边我们已经分析了各个版本慢查询语句的构成,接下来我们就要开始收集这些数据了,究竟应该怎么收集呢?
拼装日志行:mysql 的慢查询日志多行构成了一条完整的日志,日志收集时要把这些行拼装成一条日志传输与存储。
Time行处理:# Time: 开头的行可能不存在,且我们可以通过SET timestamp这个值来确定SQL执行时间,所以选择过滤丢弃Time行
一条完整的日志:最终将以# User@Host: 开始的行,和以SQL语句结尾的行合并为一条完整的慢日志语句
确定SQL对应的DB:use db这一行不是所有慢日志SQL都存在的,所以不能通过这个来确定SQL对应的DB,慢日志中也没有字段记录DB,所以这里建议为DB创建账号时添加db name标识,例如我们的账号命名方式为:projectName_dbName,这样看到账号名就知道是哪个DB了
确定SQL对应的主机:我想通过日志知道这条SQL对应的是哪台数据库服务器怎么办?
慢日志中同样没有字段记录主机,可以通过filebeat注入字段来解决,例如我们给filebeat的name字段设置为服务器IP,这样最终通过beat.name这个字段就可以确定SQL对应的主机了。
Filebeat配置
filebeat 完整的配置文件如下:
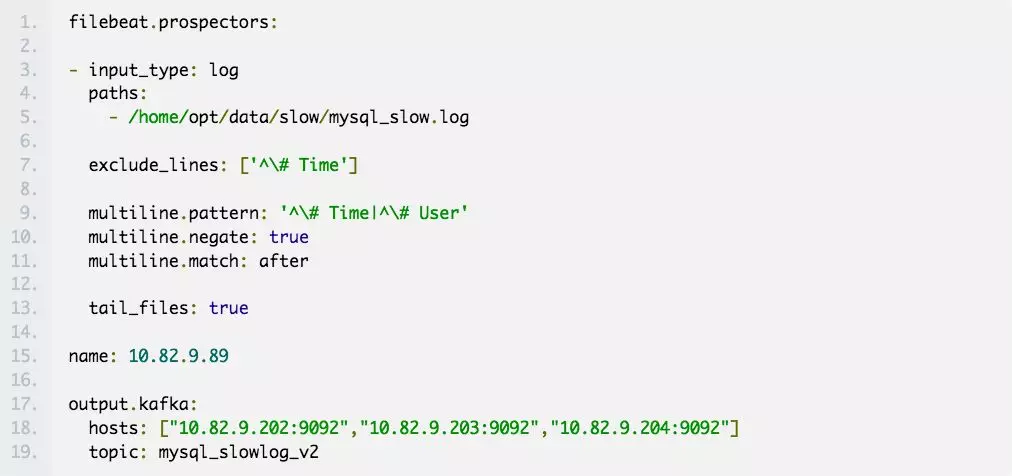
# mysql_slow.log
-
input_type: log
paths:
- /home/logs/mysql/mysqld_slow.log
document_type: mysqld-slow
exclude_lines: ['^\# Time'] multiline.pattern: '^\# Time|^\# User'
multiline.negate: true
multiline.match: after tail_files: true
重要参数解释:
input_type:指定输入的类型是log或者是stdin
paths:慢日志路径,支持正则,比如/data/*.log
exclude_lines:过滤掉# Time开头的行
multiline.pattern:匹配多行时指定正则表达式,这里匹配以# Time或者# User开头的行,Time行要先匹配再过滤
multiline.negate:定义上边pattern匹配到的行是否用于多行合并,也就是定义是不是作为日志的一部分
multiline.match:定义如何将皮排行组合成时间,在之前或者之后
tail_files:定义是从文件开头读取日志还是结尾,这里定义为true,从现在开始收集,之前已存在的不管
name:设置filebeat的名字,如果为空则为服务器的主机名,这里我们定义为服务器IP
output.kafka:配置要接收日志的kafka集群地址可topic名称
Kafka 接收到的日志格式:

{"@timestamp":"2018-08-07T09:36:00.140Z","beat":{"hostname":"db-7eb166d3","name":"10.63.144.71","version":"5.4.0"},"input_type":"log","message":"# User@Host: select[select] @ [10.63.144.16] Id: 23460596\n# Query_time: 0.155956 Lock_time: 0.000079 Rows_sent: 112 Rows_examined: 366458\nSET timestamp=1533634557;\nSELECT DISTINCT(uid) FROM common_member WHERE hideforum=-1 AND uid != 0;","offset":1753219021,"source":"/data/slow/mysql_slow.log","type":"log"}
Logstash配置
logstash完整的配置文件如下:

仅显示filter信息
if [type] =~ "mysqld-slow" {
mutate {
add_field => {"line_message" => "%{message} %{offset}"}
}
ruby {
code => "
require 'digest/md5';
event.set('computed_id', Digest::MD5.hexdigest(event.get('line_message')))
"
}
#有ID有use
grok {
match => {
"message" => "(?m)^# User@Host: %{USER:user}\[[^\]]+\] @\s+(?:(?<clienthost>\S*))?\s+\[(?:%{IP:clientip})?\]\s+Id:\s+%{NUMBER:id:
int}\n\#\s+Query_time: %{NUMBER:query_time:float}\s+Lock_time: %{NUMBER:lock_time:float}\s+Rows_sent:\s+%{NUMBER:rows_sent:int}\s+Rows_examined:
%{NUMBER:rows_examined:int}\nuse\s(?<dbname>\w+)\;\s+SET\s+timestamp=%{NUMBER:timestamp_mysql:int}\;\s+(?<query>.*)"
}
}
#有ID无use
grok {
match => {
"message" => "(?m)^# User@Host: %{USER:user}\[[^\]]+\] @\s+(?:(?<clienthost>\S*))?\s+\[(?:%{IP:clientip})?\]\s+Id:\s+%{NUMBER:id
:int}\n\#\s+Query_time: %{NUMBER:query_time:float}\s+Lock_time: %{NUMBER:lock_time:float}\s+Rows_sent:\s+%{NUMBER:rows_sent:int}\s+Rows_examined:
%{NUMBER:rows_examined:int}\nSET\s+timestamp=%{NUMBER:timestamp_mysql:int}\;\s+(?<query>.*)"
}
}
#无ID有use
grok {
match => {
"message" => "(?m)^# User@Host: %{USER:user}\[[^\]]+\] @\s+(?:(?<clienthost>\S*))?\s+\[(?:%{IP:clientip})?\]\n\#\s+Query_time: %
{NUMBER:query_time:float}\s+Lock_time: %{NUMBER:lock_time:float}\s+Rows_sent:\s+%{NUMBER:rows_sent:int}\s+Rows_examined: %{NUMBER:rows_examined:i
nt}\nuse\s(?<dbname>\w+)\;\nSET\s+timestamp=%{NUMBER:timestamp_mysql:int}\;\s+(?<query>.*)"
}
}
#无ID无use
grok {
match => {
"message" => "(?m)^# User@Host: %{USER:user}\[[^\]]+\] @\s+(?:(?<clienthost>\S*))?\s+\[(?:%{IP:clientip})?\]\n\#\s+Query_time: %{
NUMBER:query_time:float}\s+Lock_time: %{NUMBER:lock_time:float}\s+Rows_sent:\s+%{NUMBER:rows_sent:int}\s+Rows_examined: %{NUMBER:rows_examined:in
t}\nSET\s+timestamp=%{NUMBER:timestamp_mysql:int}\;\s+(?<query>.*)"
}
}
date {
match => ["timestamp_mysql", "UNIX"]
target => "@timestamp"
}
mutate {
remove_field => ["line_message","message","kafka","tags"]
}
}
重要参数解释:
input:配置 kafka 的集群地址和 topic 名字
filter:过滤日志文件,主要是对 message 信息(看前文 kafka 接收到的日志格式)进行拆分,拆分成一个一个易读的字段,例如User、Host、Query_time、Lock_time、timestamp等。
grok段根据我们前文对mysql慢日志的分类分别写不通的正则表达式去匹配,当有多条正则表达式存在时,logstash会从上到下依次匹配,匹配到一条后边的则不再匹配。
date字段定义了让SQL中的timestamp_mysql字段作为这条日志的时间字段,kibana上看到的实践排序的数据依赖的就是这个时间
output:配置ES服务器集群的地址和index,index自动按天分割
ES 中mysqld-slow-*索引模板
{
"order": 0,
"template": "mysqld-slow-*",
"settings": {
"index": {
"refresh_interval": "5s"
}
},
"mappings": {
"mysqld-slow": {
"numeric_detection": true,
"properties": {
"@timestamp": {
"type": "date",
"format": "strict_date_optional_time||epoch_millis"
},
"@version": {
"type": "string"
},
"query_time": {
"type": "double"
},
"row_sent": {
"type": "string"
},
"rows_examined": {
"type": "string"
},
"clientip": {
"type": "string"
},
"clienthost": {
"type": "string"
},
"id": {
"type": "integer"
},
"lock_time": {
"type": "string"
},
"dbname": {
"type": "keyword"
},
"user": {
"type": "keyword"
},
"query": {
"type": "string",
"index": "not_analyzed"
},
"tags": {
"type": "string"
},
"timestamp": {
"type": "string"
},
"type": {
"type": "string"
}
}
}
},
"aliases": {}
}
kibana查询展示
打开Kibana添加
mysql-slowlog-*的Index,并选择timestamp,创建Index Pattern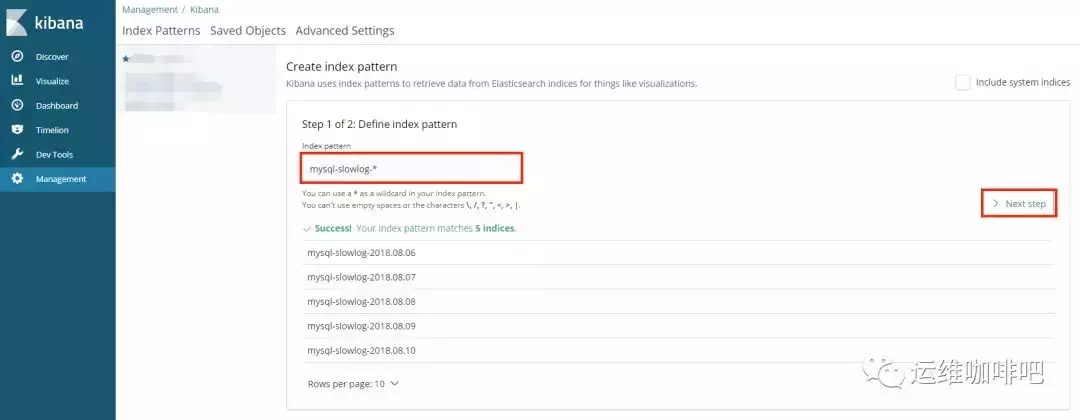
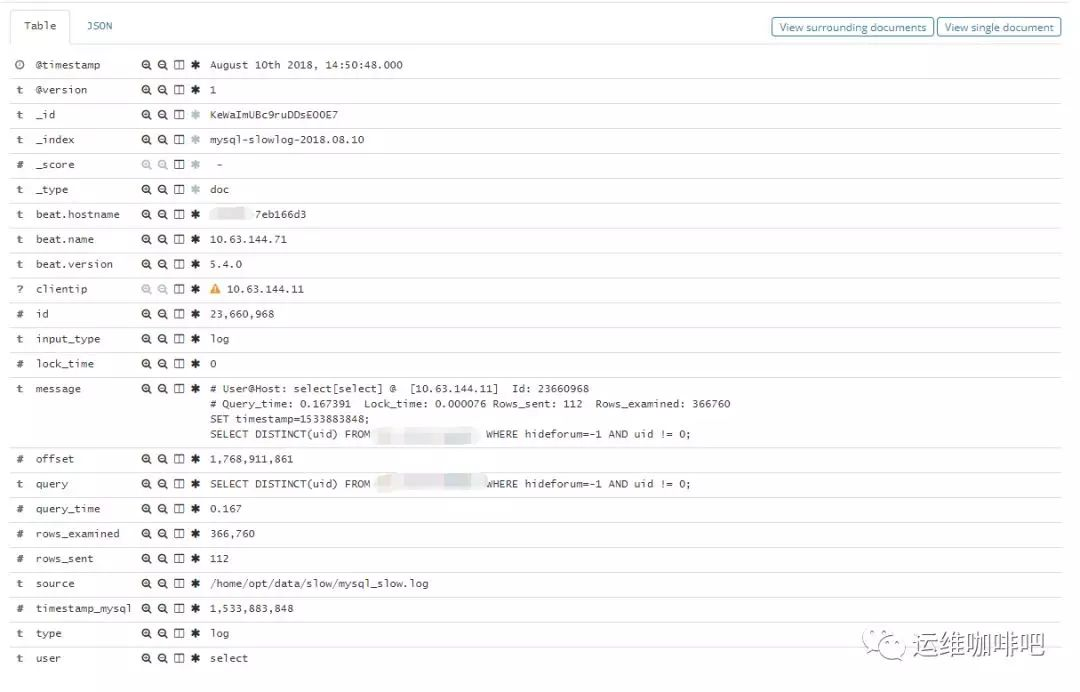
进入Discover页面,可以很直观的看到各个时间点慢日志的数量变化,可以根据左侧Field实现简单过滤,搜索框也方便搜索慢日志,例如我要找查询时间大于2s的慢日志,直接在搜索框输入
query_time: > 2回车即可。
点击每一条日志起边的很色箭头能查看具体某一条日志的详情。
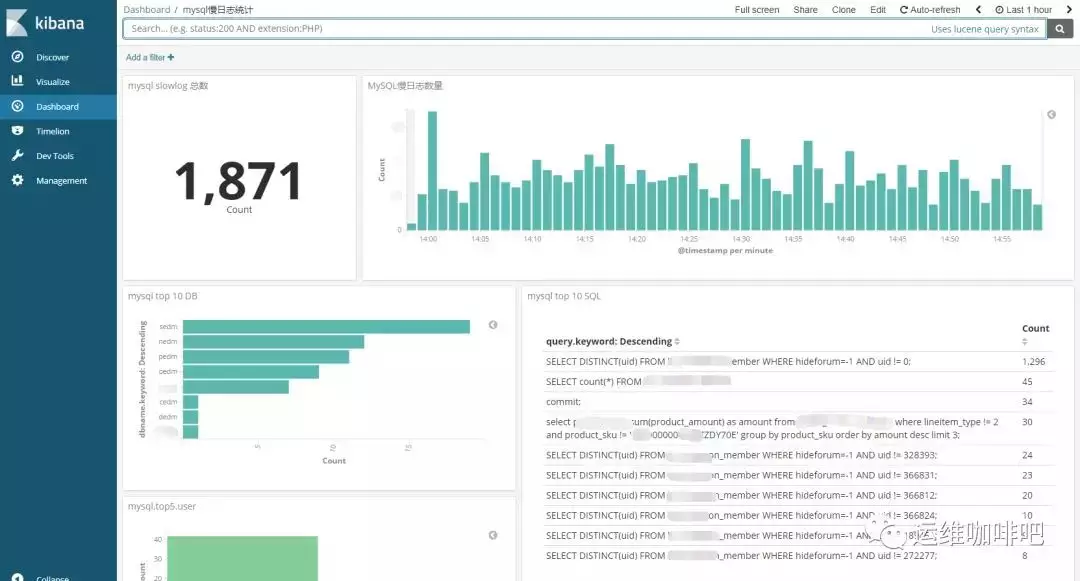
如果你想做个大盘统计慢日志的整体情况,例如top 10 SQL等,也可以很方便的通过web界面配置。
总结
不要望而却步,当你开始去做已经成功一半了
本篇文章详细介绍了关于mysql慢日志的收集,收集之后的处理呢?我们目前是DBA每天花时间去Kibana上查看分析,有优化的空间就跟开发一起沟通优化,后边达成默契之后考虑做成自动报警或处理
关于报警ELK生态的xpark已经提供,且最新版本也开源了,感兴趣的可以先研究起来,欢迎一起交流
ELK 构建 MySQL 慢日志收集平台详解的更多相关文章
- ELK构建MySQL慢日志收集平台详解
上篇文章<中小团队快速构建SQL自动审核系统>我们完成了SQL的自动审核与执行,不仅提高了效率还受到了同事的肯定,心里美滋滋.但关于慢查询的收集及处理也耗费了我们太多的时间和精力,如何在这 ...
- 利用ELK构建一个小型的日志收集平台
利用ELK构建一个小型日志收集平台 伴随着应用以及集群的扩展,查看日志的方式总是不方便,我们希望可以有一个便于我们查询及提醒功能的平台:那么首先需要剖析有几步呢? 格式定义 --> 日志收集 - ...
- ELK+Kafka 企业日志收集平台(一)
背景: 最近线上上了ELK,但是只用了一台Redis在中间作为消息队列,以减轻前端es集群的压力,Redis的集群解决方案暂时没有接触过,并且Redis作为消息队列并不是它的强项:所以最近将Redis ...
- FILEBEAT+ELK日志收集平台搭建流程
filebeat+elk日志收集平台搭建流程 1. 整体简介: 模式:单机 平台:Linux - centos - 7 ELK:elasticsearch.logstash.kiban ...
- ELK+redis搭建nginx日志分析平台
ELK+redis搭建nginx日志分析平台发表于 2015-08-19 | 分类于 Linux/Unix | ELK简介ELKStack即Elasticsearch + Logstas ...
- 使用elk+redis搭建nginx日志分析平台
elk+redis 搭建nginx日志分析平台 logstash,elasticsearch,kibana 怎么进行nginx的日志分析呢?首先,架构方面,nginx是有日志文件的,它的每个请求的状态 ...
- centos7搭建ELK Cluster集群日志分析平台(一):Elasticsearch
应用场景: ELK实际上是三个工具的集合,ElasticSearch + Logstash + Kibana,这三个工具组合形成了一套实用.易用的监控架构, 很多公司利用它来搭建可视化的海量日志分析平 ...
- centos7搭建ELK Cluster集群日志分析平台
应用场景:ELK实际上是三个工具的集合,ElasticSearch + Logstash + Kibana,这三个工具组合形成了一套实用.易用的监控架构, 很多公司利用它来搭建可视化的海量日志分析平台 ...
- ELK之方便的日志收集、搜索、展示工具
大家在做分部署系统开发的时候是不是经常因为查找日志而头疼,因为各服务器各应用都有自己日志,但比较分散,查找起来也比较麻烦,今天就给大家推荐一整套方便的工具ELK,ELK是Elastic公司开发的一整套 ...
随机推荐
- Handler,Looper,MessageQueue流程梳理
目的:handle的出现主要是为了解决线程间通讯. 举个例子,android是不允许在主线程中访问网络,因为这样会阻塞主线程,影响性能,所以访问网络都是放在子线程中执行,对于网络返回的结果则需要显示在 ...
- 章节十一、1-Junit介绍
一.Junit是一个开源的测试框架,在selenium的jar包中,不需要单独安装和搭建环境 二.@BeforeClass:当在方法上加了这个注解的话,这个方法会在这个类的第一个test方法之前运行. ...
- SQL ----post漏洞测试注入
使用工具sqlmap 输入账号密码进行bp截断,获取文本保存在sqlmap下面2.txt 爆数据库 爆表爆表 爆数据 最后把数据密码md5解析
- cmd黑客入侵命令大全
nbtstat -A ip 对方136到139其中一个端口开了的话,就可查看对方最近登陆的用户名(03前的为用户名)-注意:参数-A要大写 tracert -参数 ip(或计算机名) 跟踪路由(数据包 ...
- Linux Mint chrome浏览器提示“需要安装adobe flash player”
出现这种情况,是因为系统没有安装flash 插件造成的,用以下的命令安装: sudo apt-get install adobe-flashplugin 安装完成后,重启浏览器. 如果chrome浏览 ...
- [十二省联考2019]D2T2春节十二响
嘟嘟嘟 这题真没想到这么简单-- 首先有60分大礼:\(O(n ^ 2logn)\)贪心.(我也不知道为啥就是对的) 然后又送15分链:维护两个堆,每次去堆顶的最大值. 这时候得到75分已经很开心了, ...
- Java多线程面试
1.说说进程.线程.协程之间的区别 简而言之,进程是程序运行和资源分配的基本单位,一个程序至少有一个进程,一个进程至少有一个线程.进程在执行过程中拥有独立的内存单元,而多个线程共享内存资源,减少切换次 ...
- 本地跑 spark ui 报错
java.lang.NoSuchMethodError: javax.servlet.http.HttpServletRequest.isAsyncStarted()Z at org.spark_pr ...
- HashMap、Hashtable、ConcurrentHashMap的原理与区别
同步首发:http://www.yuanrengu.com/index.php/2017-01-17.html 如果你去面试,面试官不问你这个问题,你来找我^_^ 下面直接来干货,先说这三个Map的区 ...
- [转帖]windows10,business版和consumer版本区别
windows10,business版和consumer版本区别 时间:2018-07-08 10:50来源:原创 作者:5分享 点击: 7113 次 windows10系统(1803)busines ...