堆排序(heap sort)
参考博客:http://bubkoo.com/2014/01/14/sort-algorithm/heap-sort/
1.二叉树
二叉树的第 i 层至多有 2i-1 个结点;深度为 k 的二叉树至多有 2k - 1 个结点;对任何一棵二叉树 T,如果其终端结点数为 n0,度为 2 的结点数为 n2,则n0 = n2 + 1。
二叉树又分为完全二叉树(complete binary tree)和满二叉树(full binary tree)
满二叉树:一棵深度为 k,且有 2k - 1 个节点称之为满二叉树
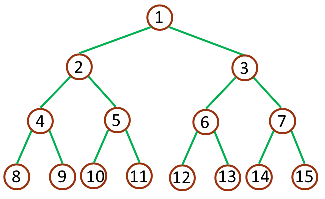
深度为 3 的满二叉树 full binary tree
完全二叉树:深度为 k,有 n 个节点的二叉树,当且仅当其每一个节点都与深度为 k 的满二叉树中序号为 1 至 n 的节点对应时,称之为完全二叉树
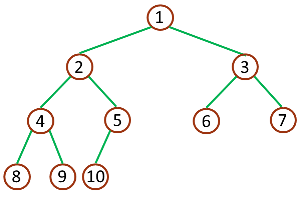
深度为 3 的完全二叉树 complete binary tree
2. 什么是堆?
堆(二叉堆)可以视为一棵完全的二叉树,完全二叉树的一个“优秀”的性质是,除了最底层之外,每一层都是满的,这使得堆可以利用数组来表示(普通的一般的二叉树通常用链表作为基本容器表示),每一个结点对应数组中的一个元素。
对于给定的某个结点的下标 i,可以很容易的计算出这个结点的父结点、孩子结点的下标:
- Parent(i) = floor(i/2),i 的父节点下标
- Left(i) = 2i,i 的左子节点下标
- Right(i) = 2i + 1,i 的右子节点下标
二叉堆一般分为两种:最大堆和最小堆。
最大堆:
- 最大堆中的最大元素值出现在根结点(堆顶)
- 堆中每个父节点的元素值都大于等于其孩子结点(如果存在)
最小堆:
- 最小堆中的最小元素值出现在根结点(堆顶)
- 堆中每个父节点的元素值都小于等于其孩子结点(如果存在)
3. 堆排序原理
堆排序就是把最大堆堆顶的最大数取出,将剩余的堆继续调整为最大堆,再次将堆顶的最大数取出,这个过程持续到剩余数只有一个时结束。在堆中定义以下几种操作:
- 最大堆调整(Max-Heapify):将堆的末端子节点作调整,使得子节点永远小于父节点
- 创建最大堆(Build-Max-Heap):将堆所有数据重新排序,使其成为最大堆
- 堆排序(Heap-Sort):移除位于第一个数据的根节点,并做最大堆调整的递归运算
Max-Heapify:递归调用自身
Build-Max-Heap:调用Max-Heapify
Heap-Sort:接口,调用Build-Max-Heap和Max-Heapify
数组都是 Zero-Based,这就意味着我们的堆数据结构模型要发生改变.。。。
相应的,几个计算公式也要作出相应调整:
- Parent(i) = floor((i-1)/2),i 的父节点下标
- Left(i) = 2i + 1,i 的左子节点下标
- Right(i) = 2(i + 1),i 的右子节点下标
最大堆调整(MAX‐HEAPIFY)的作用是保持最大堆的性质,是创建最大堆的核心子程序,由于一次调整后,堆仍然违反堆性质,所以需要递归的测试,使得整个堆都满足堆性质
创建最大堆(Build-Max-Heap)的作用是将一个数组改造成一个最大堆,接受数组和堆大小两个参数,Build-Max-Heap 将自下而上的调用 Max-Heapify 来改造数组,建立最大堆,
因为 Max-Heapify 能够保证下标 i 的结点之后结点都满足最大堆的性质,所以自下而上的调用 Max-Heapify 能够在改造过程中保持这一性质
堆排序(Heap-Sort)是堆排序的接口算法,Heap-Sort先调用Build-Max-Heap将数组改造为最大堆,然后将堆顶和堆底元素交换,之后将底部上升,最后重新调用Max-Heapify保持最大堆性质。由于堆顶元素必然是堆中最大的元素,所以一次操作之后,堆中存在的最大元素被分离出堆,重复n-1次之后,数组排列完毕。
堆排序(heap sort)的更多相关文章
- 数据结构 - 堆排序(heap sort) 具体解释 及 代码(C++)
堆排序(heap sort) 具体解释 及 代码(C++) 本文地址: http://blog.csdn.net/caroline_wendy 堆排序包括两个步骤: 第一步: 是建立大顶堆(从大到小排 ...
- Python入门篇-数据结构堆排序Heap Sort
Python入门篇-数据结构堆排序Heap Sort 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.堆Heap 堆是一个完全二叉树 每个非叶子结点都要大于或者等于其左右孩子结点 ...
- 堆排序 Heap Sort
堆排序虽然叫heap sort,但是和内存上的那个heap并没有实际关系.算法上,堆排序一般使用数组的形式来实现,即binary heap. 我们可以将堆排序所使用的堆int[] heap视为一个完全 ...
- 算法----堆排序(heap sort)
堆排序是利用堆进行排序的高效算法,其能实现O(NlogN)的排序时间复杂度,详细算法分析能够点击堆排序算法时间复杂度分析. 算法实现: 调整堆: void sort::sink(int* a, con ...
- 堆排序Heap sort
堆排序有点小复杂,分成三块 第一块,什么是堆,什么是最大堆 第二块,怎么将堆调整为最大堆,这部分是重点 第三块,堆排序介绍 第一块,什么是堆,什么是最大堆 什么是堆 这里的堆(二叉堆),指得不是堆栈的 ...
- Java实现---堆排序 Heap Sort
堆排序与快速排序,归并排序一样都是时间复杂度为O(N*logN)的几种常见排序方法.学习堆排序前,先讲解下什么是数据结构中的二叉堆. 堆的定义 n个元素的序列{k1,k2,…,kn}当且仅当满足下列关 ...
- 小小c#算法题 - 7 - 堆排序 (Heap Sort)
在讨论堆排序之前,我们先来讨论一下另外一种排序算法——插入排序.插入排序的逻辑相当简单,先遍历一遍数组找到最小值,然后将这个最小值跟第一个元素交换.然后遍历第一个元素之后的n-1个元素,得到这n-1个 ...
- 数据结构与算法---堆排序(Heap sort)
堆排序基本介绍 1.堆排序是利用堆这种数据结构而设计的一种排序算法,堆排序是一种选择排序,它的最坏,最好,平均时间复杂度均为O(nlogn),它也是不稳定排序. 2.堆是具有以下性质的完全二叉树:每个 ...
- [Unity][Heap sort]用Unity动态演示堆排序的过程(How Heap Sort Works)
[Unity][Heap sort]用Unity动态演示堆排序的过程 How Heap Sort Works 最近做了一个用Unity3D动态演示堆排序过程的程序. I've made this ap ...
- 堆排序(Heap Sort)的C语言实现
堆排序(Heap Sort)具体步骤为 将无序序列建成大顶堆(小顶堆):从最后一个非叶子节点开始通过堆调整HeapAdjust()变成小顶堆或大顶堆 将顶部元素与堆尾数组交换,此是末尾元素就是最大值, ...
随机推荐
- ASP.NET Zero--单元测试
单元测试 ASP.NET Zero启动项目包含单元和集成测试.使用以下工具开发测试: xUnit作为测试框架. Shouldly 作为断言库. Microsoft.EntityFrameworkCor ...
- WDS和DHCP配置说明
网络启动程序 (NBP) 是网络启动过程中第一个下载和执行的文件,它可以控制启动开始时的体验(例如,用户是否必须按 F12 才能开始网络启动) WDS服务器配置说明: 1)如果WDS和DHCP安装在同 ...
- linux下的别名机制
相当于用户自己创建一个属于自己的命令.在当前用户的家目录下有一个.bashrc文件,编辑该文件: eg:alias cls='clear' 如果命令要生效需要重新登录.用户输入cls就可以达到清屏的目 ...
- eclipse导入maven项目,但无法编译的问题
同事今天从git 导入项目到eclipse 后,发现项目所依赖的包找不到依赖,初步判定是maven的依赖没有导入项目中. 最终发现,在项目中的.classpath 文件加入以下代码即可解决问题. &l ...
- LVM 磁盘分区扩容
前提:将磁盘中未分区磁盘进行分区操作 https://www.cnblogs.com/guoxiangyue/p/10033367.html 然后进行vg扩容 pvcreate /dev/sdc lv ...
- Azure导出所有用户权限---powershell命令
直接运行脚本 #requires -Version 3.0 -Modules AzureRM.Resourcesparam( [switch] $GroupRolesB ...
- ABP之调试
虽然通常情况下不需要,但是Abp还是提供了能在调试项目中进入Abp源码的方法.. 所有的ABP NuGet包都启用了源码连接.这意味着我们可以在我们的项目中调试ABP源码,要启用它,更改Visual ...
- Appium 客户端类库
Appium 支持以下语言的客户端类库: 语言 Ruby Python Java JavaScript PHP C# Objective-C 锁定注意,一些方法类似 endTestCoverage() ...
- MongoDB系列:二、MongoDB常用操作练习
最近在自学MongoDB,在此记录一下,当做学习笔记了(不断更新中)!! 一.背景 MongoDB 是一个基于分布式文件存储的数据库.由 C++ 语言编写.旨在为 WEB 应用提供可扩展的高性能数据存 ...
- Scanner的使用 猜数字 +猜电影
猜数字public class Main { public static void main(String[] args) { int random=(int)(Math.random()*100)+ ...