HanLP中文分词Lucene插件
基于HanLP,支持包括Solr(7.x)在内的任何基于Lucene(7.x)的系统。
Maven
<dependency>
<groupId>com.hankcs.nlp</groupId>
<artifactId>hanlp-lucene-plugin</artifactId>
<version>1.1.6</version>
</dependency>
Solr快速上手
1.将hanlp-portable.jar和hanlp-lucene-plugin.jar共两个jar放入${webapp}/WEB-INF/lib下。(或者使用mvn package对源码打包,拷贝target/hanlp-lucene-plugin-x.x.x.jar到${webapp}/WEB-INF/lib下)
2. 修改solr core的配置文件${core}/conf/schema.xml:
<fieldType name="text_cn" class="solr.TextField">
<analyzer type="index">
<tokenizer class="com.hankcs.lucene.HanLPTokenizerFactory" enableIndexMode="true"/>
</analyzer>
<analyzer type="query">
<!-- 切记不要在query中开启index模式 -->
<tokenizer class="com.hankcs.lucene.HanLPTokenizerFactory" enableIndexMode="false"/>
</analyzer>
</fieldType>
<!-- 业务系统中需要分词的字段都需要指定type为text_cn -->
<field name="my_field1" type="text_cn" indexed="true" stored="true"/>
<field name="my_field2" type="text_cn" indexed="true" stored="true"/>
· 如果你的业务系统中有其他字段,比如location,summary之类,也需要一一指定其type="text_cn"。切记,否则这些字段仍旧是solr默认分词器。
· 另外,切记不要在query中开启indexMode,否则会影响PhaseQuery。indexMode只需在index中开启一遍即可。
高级配置
目前本插件支持如下基于schema.xml的配置:
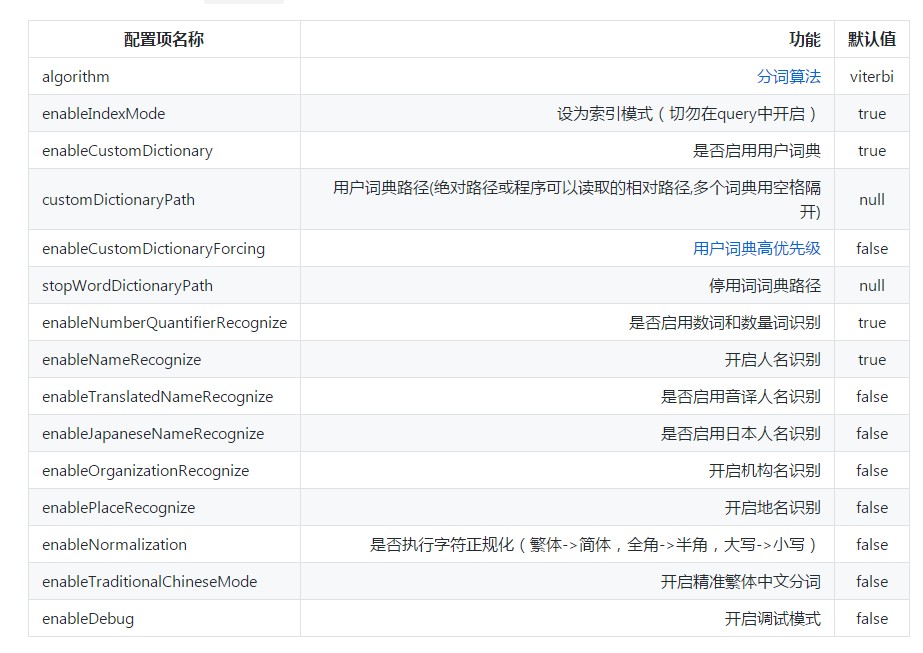
更高级的配置主要通过class path下的hanlp.properties进行配置,请阅读HanLP自然语言处理包文档以了解更多相关配置,如:
0.用户词典
1.词性标注
2.简繁转换
3.……
停用词与同义词
推荐利用Lucene或Solr自带的filter实现,本插件不会越俎代庖。 一个示例配置如下:

调用方法
在Query改写的时候,可以利用HanLPAnalyzer分词结果中的词性等属性,如
String text = "中华人民共和国很辽阔";
for (int i = 0; i < text.length(); ++i)
{
System.out.print(text.charAt(i) + "" + i + " ");
}
System.out.println();
Analyzer analyzer = new HanLPAnalyzer();
TokenStream tokenStream = analyzer.tokenStream("field", text);
tokenStream.reset();
while (tokenStream.incrementToken())
{
CharTermAttribute attribute = tokenStream.getAttribute(CharTermAttribute.class);
// 偏移量
OffsetAttribute offsetAtt = tokenStream.getAttribute(OffsetAttribute.class);
// 距离
PositionIncrementAttribute positionAttr = tokenStream.getAttribute(PositionIncrementAttribute.class);
// 词性
TypeAttribute typeAttr = tokenStream.getAttribute(TypeAttribute.class);
System.out.printf("[%d:%d %d] %s/%s\n", offsetAtt.startOffset(), offsetAtt.endOffset(), positionAttr.getPositionIncrement(), attribute, typeAttr.type());
}
在另一些场景,支持以自定义的分词器(比如开启了命名实体识别的分词器、繁体中文分词器、CRF分词器等)构造HanLPTokenizer,比如:
tokenizer = new HanLPTokenizer(HanLP.newSegment()
.enableJapaneseNameRecognize(true)
.enableIndexMode(true), null, false);
tokenizer.setReader(new StringReader("林志玲亮相网友:确定不是波多野结衣?"));
文章摘自:2019 github
HanLP中文分词Lucene插件的更多相关文章
- 全文检索Solr集成HanLP中文分词
以前发布过HanLP的Lucene插件,后来很多人跟我说其实Solr更流行(反正我是觉得既然Solr是Lucene的子项目,那么稍微改改配置就能支持Solr),于是就抽空做了个Solr插件出来,开源在 ...
- 全文检索Solr集成HanLP中文分词【转】
以前发布过HanLP的Lucene插件,后来很多人跟我说其实Solr更流行(反正我是觉得既然Solr是Lucene的子项目,那么稍微改改配置就能支持Solr),于是就抽空做了个Solr插件出来,开源在 ...
- Elasticsearch:hanlp 中文分词器
HanLP 中文分词器是一个开源的分词器,是专为Elasticsearch而设计的.它是基于HanLP,并提供了HanLP中大部分的分词方式.它的源码位于: https://github.com/Ke ...
- 【自定义IK词典】Elasticsearch之中文分词器插件es-ik的自定义词库
Elasticsearch之中文分词器插件es-ik 针对一些特殊的词语在分词的时候也需要能够识别 有人会问,那么,例如: 如果我想根据自己的本家姓氏来查询,如zhouls,姓氏“周”. 如 ...
- Elasticsearch之中文分词器插件es-ik(博主推荐)
前提 什么是倒排索引? Elasticsearch之分词器的作用 Elasticsearch之分词器的工作流程 Elasticsearch之停用词 Elasticsearch之中文分词器 Elasti ...
- Elasticsearch之中文分词器插件es-ik的自定义热更新词库
不多说,直接上干货! 欢迎大家,关注微信扫码并加入我的4个微信公众号: 大数据躺过的坑 Java从入门到架构师 人工智能躺过的坑 Java全栈大联盟 ...
- elasticsearch安装中文分词器插件smartcn
原文:http://blog.java1234.com/blog/articles/373.html elasticsearch安装中文分词器插件smartcn elasticsearch默认分词器比 ...
- lucene6+HanLP中文分词
1.前言 前一阵把博客换了个模版,模版提供了一个搜索按钮,这让我想起一直以来都想折腾的全文搜索技术,于是就用lucene6.2.1加上HanLP的分词插件做了这么一个模块CSearch.效果看这里:h ...
- 搜索引擎ElasticSearch系列(五): ElasticSearch2.4.4 IK中文分词器插件安装
一:IK分词器简介 IK Analyzer是一个开源的,基于java语言开发的轻量级的中文分词工具包.从2006年12月推出1.0版开始, IKAnalyzer已经推出了4个大版本.最初,它是以开源 ...
随机推荐
- 第一次作业_ChenHong1998
我的目标 学习到软件工程的实践过程 回想一下你初入大学时对软件工程专业的畅想 当初你是如何做出选择软件工程专业的决定的? 计算机是热门专业,软件工程专业好找工作 你认为过去两年中接触到的课程是否符合你 ...
- jar包自动化部署---jenkins
B.Application Server SVN账号:svn://192.168.1.49/svn/keenyoda-trunk/xxxxxcht=xxxxx 安装jenkins:安装目录:/usr/ ...
- Promise学习使用
Promise是承诺的意思,“承诺可以获取异步操作的消息”,是一种异步执行的方案,Promise有各种开源实现,在ES6中被统一规范,由浏览器直接支持. Promise 对象有三种状态:pending ...
- 173zrx个人简介
码云链接:https://gitee.com/zhrx-617/codes/947dbs2fi5kw3jz8hc0ma74 效果图: 源代码: <html> <head> &l ...
- React Navigation基本用法
/** * Created by apple on 2018/9/23. */ import React, { Component } from 'react'; import {AppRegistr ...
- eclipse 项目中嵌入jetty
Jetty是一个提供HHTP服务器.HTTP客户端和javax.servlet容器的开源项目,Jetty 目前的是一个比较被看好的 Servlet 引擎,它的架构比较简单,也是一个可扩展性和非常灵活的 ...
- dos3章
FOR命令中有一些变量,他们的用法许多新手朋友还不太了解,今天给大家讲解他们的用法! 先把FOR的变量全部列出来: ~I - 删除任何引号("),扩展 %I %~f ...
- Linux 驱动——Button驱动2
button_drv.c驱动文件: #include <linux/module.h>#include <linux/kernel.h>#include <linux/f ...
- WEB学习笔记9-添加必要的<meta>标签
<meta>标签放置在HTML页面的head中,主要用于标示网站.其中主要包含网站的一些描述信息,如简介,作者等.这些信息有助于搜索引擎更准确地识别网页的内容,也有助于第三方工具抓取网站基 ...
- JDK1.8环境下依然报错 Unsupported major.minor version 52.0
JDK1.8环境下依然报错 Unsupported major.minor version 52.0 在配置elasticsearch-rtf全文搜索引擎时,按照Github上项目readme.md来 ...