Scrapyd
scrapyd
安装
scrapyd-中心节点,子节点安装scrapyd-client
pip3 install scrapyd
pip3 install scrapyd-client

scrapyd-client两个作用
把本地的代码打包生成egg包
把egg上传到远程的服务器上
windows配置scrapyd-deploy
H:\Python36\Scripts下创建scrapyd-deploy.bat
python H:/Python36/Scripts/scrapyd-deploy %*
curl.exe放入H:\Python36\Scripts
启动scrapyd启动服务!!!!!!!!!!
scrapyd-deploy 查询
切换到scrapy中cmd运行scrapyd-deploy
H:\DDD-scrapy\douban>scrapyd-deploy
scrapyd-deploy -l

scrapy中scrapy.cfg修改配置
[deploy:dj] #开发项目名
url = http://localhost:6800/
project = douban #项目名
scrapy list这个命令确认可用,结果dang是spider名

如不可用,setting中添加以下

scrapyd-deploy 添加爬虫
scrapyd-deploy dj -p douban
H:/Python36/Scripts/scrapyd-deploy dang1 -p dangdang
dang1是开发项目名,dangdang是项目名

http://127.0.0.1:6800/jobs
scrapyd 当前项目的状态
curl http://localhost:6800/daemonstatus.json

curl启动爬虫
curl http://localhost:6800/schedule.json -d project=dangdang -d spider=dang
dangdang是项目名,dang是爬虫名

project=douban,spider=doubanlogin
curl http://localhost:6800/schedule.json -d project=douban -d spider=doubanlogin


远程部署:scrapyd-deploy
scrapyd-deploy 17k -p my17k
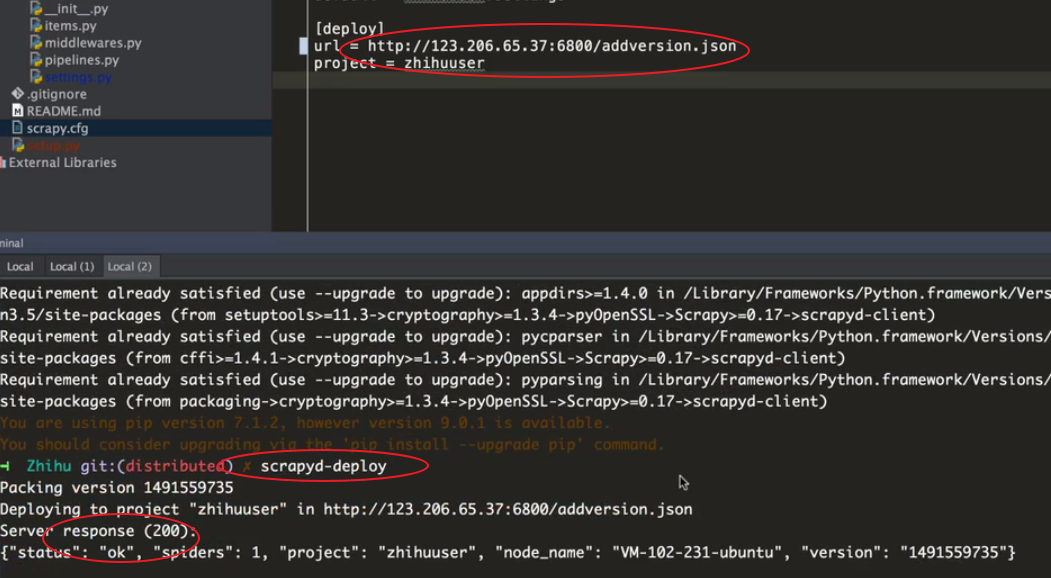
列出所有已经上传的spider
curl http://47.97.169.234:6800/listprojects.json

列出当前项目project的版本version
curl http://47.97.169.234:6800/listversions.json\?project\=my17k

远程启动spider
curl http://47.97.169.234:6800/schedule.json -d project=my17k-d spider=mys1

运行三次,就类似于开启三个进程
curl http://47.97.169.234:6800/schedule.json -d project=my17k-d spider=mys1

查看当前项目的运行情况

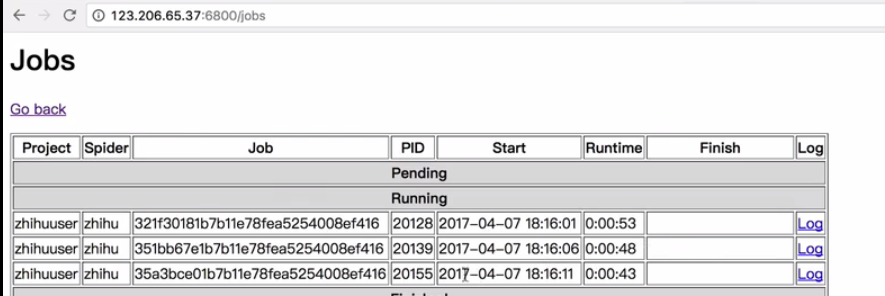
取消爬虫项目的job任务
curl http://localhost:6800/cancel.json -d project=dangdang -d job=68d25db0506111e9a4c0e2df1c2eb35b
curl http://47.97.169.234:6800/cancel.json -d project=my17k -d job=be6ed036508611e9b68000163e08dec9

centos配置scrapyd
https://www.cnblogs.com/ss-py/p/9661928.html
安装后新建一个配置文件:
sudo mkdir /etc/scrapyd
sudo vim /etc/scrapyd/scrapyd.conf
写入如下内容:(给内容在https://scrapyd.readthedocs.io/en/stable/config.html可找到)
[scrapyd]
eggs_dir = eggs
logs_dir = logs
items_dir =
jobs_to_keep = 5
dbs_dir = dbs
max_proc = 0
max_proc_per_cpu = 10
finished_to_keep = 100
poll_interval = 5.0
bind_address = 0.0.0.0
http_port = 6800
debug = off
runner = scrapyd.runner
application = scrapyd.app.application
launcher = scrapyd.launcher.Launcher
webroot = scrapyd.website.Root [services]
schedule.json = scrapyd.webservice.Schedule
cancel.json = scrapyd.webservice.Cancel
addversion.json = scrapyd.webservice.AddVersion
listprojects.json = scrapyd.webservice.ListProjects
listversions.json = scrapyd.webservice.ListVersions
listspiders.json = scrapyd.webservice.ListSpiders
delproject.json = scrapyd.webservice.DeleteProject
delversion.json = scrapyd.webservice.DeleteVersion
listjobs.json = scrapyd.webservice.ListJobs
daemonstatus.json = scrapyd.webservice.DaemonStatus
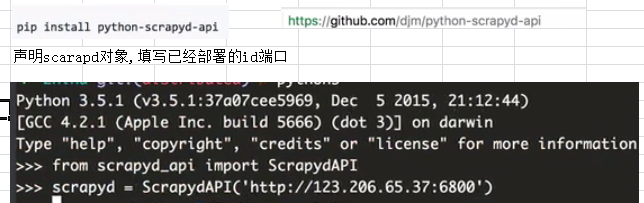
scrapyd-api
安装
scrapyd-api对scrapyd进行了一些封装
from scrapyd_api import ScrapydAPI
scrapyd=ScrapydAPI('http://47.97.169.234:6800')
使用
显示所有的projects
scrapyd.list_projects()

显示该项目下的spiders
scrapyd.list_spiders('my17k')

from scrapyd_api import ScrapydAPI
scrapyd=ScrapydAPI('http://47.97.169.234:6800')
print(scrapyd.list_projects()) #查询项目名
print(scrapyd.list_spiders('my17k')) #查询该项目名下的爬虫名
Scrapyd的更多相关文章
- scrapy的scrapyd使用方法
一直以来,很多人疑惑scrapy提供的scrapyd该怎么用,于我也是.自己在实际项目中只是使用scrapy crawl spider,用python来写一个多进程启动,还用一个shell脚本来监控进 ...
- 如何将Scrapy 部署到Scrapyd上?
安装上传工具 1.上传工具 scrapyd-client 2.安装方法: pip install scrapyd-client 3.上传方法: python d:\Python27\Scripts\s ...
- 如何部署Scrapy 到Scrapyd上?
安装上传工具 1.上传工具 scrapyd-client 2.安装方法: pip install scrapyd-client 3.上传方法: python d:\Python27\Scripts\s ...
- Scrapyd部署爬虫
Scrapyd部署爬虫 准备工作 安装scrapyd: pip install scrapyd 安装scrapyd-client : pip install scrapyd-client 安装curl ...
- 芝麻HTTP:Scrapyd的安装
Scrapyd是一个用于部署和运行Scrapy项目的工具,有了它,你可以将写好的Scrapy项目上传到云主机并通过API来控制它的运行. 既然是Scrapy项目部署,基本上都使用Linux主机,所以本 ...
- Scrapyd日志输出优化
现在维护着一个新浪微博爬虫,爬取量已经5亿+,使用了Scrapyd部署分布式. Scrapyd运行时会输出日志到本地,导致日志文件会越来越大,这个其实就是Scrapy控制台的输出.但是这个日志其实有用 ...
- Scrapy+Scrapy-redis+Scrapyd+Gerapy 分布式爬虫框架整合
简介:给正在学习的小伙伴们分享一下自己的感悟,如有理解不正确的地方,望指出,感谢~ 首先介绍一下这个标题吧~ 1. Scrapy:是一个基于Twisted的异步IO框架,有了这个框架,我们就不需要等待 ...
- Scrapyd 改进第二步: Web Interface 添加 STOP 和 START 超链接, 一键调用 Scrapyd API
0.提出问题 Scrapyd 提供的开始和结束项目的API如下,参考 Scrapyd 改进第一步: Web Interface 添加 charset=UTF-8, 避免查看 log 出现中文乱码,准备 ...
- Scrapyd 改进第一步: Web Interface 添加 charset=UTF-8, 避免查看 log 出现中文乱码
0.问题现象和原因 如下图所示,由于 Scrapyd 的 Web Interface 的 log 链接直接指向 log 文件,Response Headers 的 Content-Type 又没有声明 ...
随机推荐
- jenkins部署net core初探
一步一步,小心翼翼吖.看了好几个博客,摸索了两天了,才搭建成功,不容易,先写篇文章记下来,hhhhhhhhhhhh 相关环境配置 服务器:centos7 源代码管理器:git 技术选型:net cor ...
- Redhat6.4安装Oracle 11gr2 64位 注意事项
安装步骤略, 安装步骤参考:https://www.cnblogs.com/jhlong/p/5442459.html 注意的是,会出现找不到一些依赖库,我根据光盘已有的库安装了所有64位的依赖库,强 ...
- python之路3-元组、列表、字典、集合
1.元组 特点:一旦创建,内容不可修改,又叫只读列表 a= ('wang','zhang','zhao') print(a.count('zhao')) print(a.index('wang')) ...
- webBrowser兼容
using Microsoft.Win32; using System; using System.Collections.Generic; using System.ComponentModel; ...
- redis哨兵(Sentinel)、虚拟槽分区(cluster)和docker入门
一.Redis-Sentinel(哨兵) 1.介绍 Redis-Sentinel是redis官方推荐的高可用性解决方案,当用redis作master-slave的高可用时,如果master本身宕机,r ...
- mpvue——支持less
安装 安装less和less-loader,我用的是淘宝源,你也可以直接npm $ cnpm install less less-loader --save 配置 打开build目录下的webpack ...
- Android学习第九天
为什么需要内容提供者 a) 如何创建数据库 b) 文件权限 c) Chmod linux修改权限 内容提供者原理 a) 内容提供者把数据进行封 ...
- 洛谷P2634 聪明可可
还是点分治 树上问题真有趣ovo,这道题统计模3为0的距离,可以把重心的子树分开统计,也可以一次性统计,然后容斥原理减掉重复的.. 其他的过程就是点分治的板子啦. #include <bits/ ...
- vue之——从彩笔的进步之路
因为这个文章开的有点晚,不可能说从头教学vue的使用,所以大概还是记录一下我的学习路线吧: 一开始是想学一个前端框架,最后选择了vue,一开始是看了表严肃的vue课程,b站有,讲的相当好,就算打个小广 ...
- win32: 文本编辑框(Edit)控件响应事件
过去几年,关于文本编辑框(Edit)控件的响应事件,我都是在主程序 while(GetMessage(&messages, NULL, 0, 0)) { ... } 捕获. 总感觉这种方式让人 ...