Mapreduce数据分析实例
数据包
百度网盘
链接:https://pan.baidu.com/s/1v9M3jNdT4vwsqup9N0mGOA
提取码:hs9c
复制这段内容后打开百度网盘手机App,操作更方便哦
1、 数据清洗说明:
(1) 第一列是时间;
(2) 第二列是卖出方;
(3) 第三列是买入方;
(4) 第四列是票的数量;
(5) 第五列是金额。
卖出方,买入方一共三个角色,机场(C开头),代理人(O开头)和一般顾客(PAX)
2、 数据清洗要求:
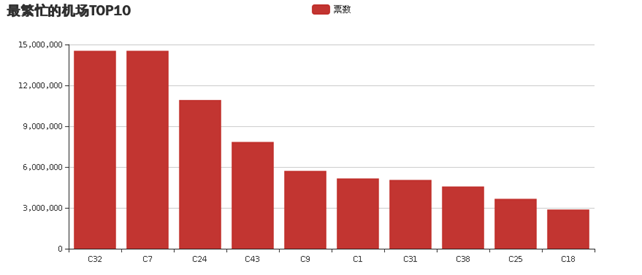
(1)统计最繁忙的机场Top10(包括买入卖出);
(2)统计最受欢迎的航线;(起点终点一致(或相反))
(3)统计最大的代理人TOP10;
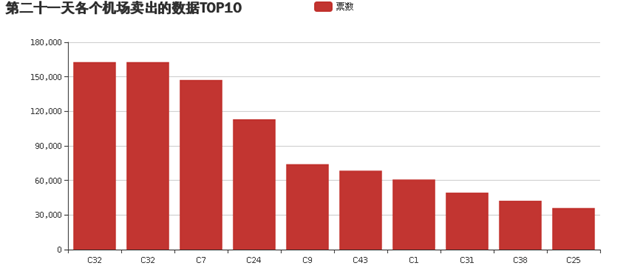
(4)统计某一天的各个机场的卖出数据top10。
3、 数据可视化要求:
(1)上述四中统计要求可以用饼图、柱状图等显示;
(2)可用关系图展示各个机场之间的联系程度(以机票数量作为分析来源)。
实验关键部分代码(列举统计最繁忙机场的代码,其他代码大同小异):
数据初步情理,主要是过滤出各个机场个总票数
- 1. package mapreduce;
- 2. import java.io.IOException;
- 3. import java.net.URI;
- 4. import org.apache.hadoop.conf.Configuration;
- 5. import org.apache.hadoop.fs.Path;
- 6. import org.apache.hadoop.io.LongWritable;
- 7. import org.apache.hadoop.io.Text;
- 8. import org.apache.hadoop.mapreduce.Job;
- 9. import org.apache.hadoop.mapreduce.Mapper;
- 10. import org.apache.hadoop.mapreduce.Reducer;
- 11. import org.apache.hadoop.mapreduce.lib.chain.ChainMapper;
- 12. import org.apache.hadoop.mapreduce.lib.chain.ChainReducer;
- 13. import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
- 14. import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
- 15. import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
- 16. import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
- 17. import org.apache.hadoop.mapreduce.lib.partition.HashPartitioner;
- 18. import org.apache.hadoop.fs.FileSystem;
- 19. import org.apache.hadoop.io.IntWritable;
- 20. public class ChainMapReduce {
- 21. private static final String INPUTPATH = "hdfs://localhost:9000/mapreducetest/region.txt";
- 22. private static final String OUTPUTPATH = "hdfs://localhost:9000/mapreducetest/out1";
- 23. public static void main(String[] args) {
- 24. try {
- 25. Configuration conf = new Configuration();
- 26. FileSystem fileSystem = FileSystem.get(new URI(OUTPUTPATH), conf);
- 27. if (fileSystem.exists(new Path(OUTPUTPATH))) {
- 28. fileSystem.delete(new Path(OUTPUTPATH), true);
- 29. }
- 30. Job job = new Job(conf, ChainMapReduce.class.getSimpleName());
- 31. FileInputFormat.addInputPath(job, new Path(INPUTPATH));
- 32. job.setInputFormatClass(TextInputFormat.class);
- 33. ChainMapper.addMapper(job, FilterMapper1.class, LongWritable.class, Text.class, Text.class, IntWritable.class, conf);
- 34. ChainReducer.setReducer(job, SumReducer.class, Text.class, IntWritable.class, Text.class, IntWritable.class, conf);
- 35. job.setMapOutputKeyClass(Text.class);
- 36. job.setMapOutputValueClass(IntWritable.class);
- 37. job.setPartitionerClass(HashPartitioner.class);
- 38. job.setNumReduceTasks(1);
- 39. job.setOutputKeyClass(Text.class);
- 40. job.setOutputValueClass(IntWritable.class);
- 41. FileOutputFormat.setOutputPath(job, new Path(OUTPUTPATH));
- 42. job.setOutputFormatClass(TextOutputFormat.class);
- 43. System.exit(job.waitForCompletion(true) ? 0 : 1);
- 44. } catch (Exception e) {
- 45. e.printStackTrace();
- 46. }
- 47. }
- 48. public static class FilterMapper1 extends Mapper<LongWritable, Text, Text, IntWritable> {
- 49. private Text outKey = new Text();
- 50. private IntWritable outValue = new IntWritable();
- 51. @Override
- 52. protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context)
- 53. throws IOException,InterruptedException {
- 54. String line = value.toString();
- 55. if (line.length() > 0) {
- 56. String[] arr = line.split(",");
- 57. int visit = Integer.parseInt(arr[3]);
- 58. if(arr[1].substring(0, 1).equals("C")||arr[2].substring(0, 1).equals("C")){
- 59. outKey.set(arr[1]);
- 60. outValue.set(visit);
- 61. context.write(outKey, outValue);
- 62. }
- 63. }
- 64. }
- 65. }
- 66.
- 67. public static class SumReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
- 68. private IntWritable outValue = new IntWritable();
- 69. @Override
- 70. protected void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context)
- 71. throws IOException, InterruptedException {
- 72. int sum = 0;
- 73. for (IntWritable val : values) {
- 74. sum += val.get();
- 75. }
- 76. outValue.set(sum);
- 77. context.write(key, outValue);
- 78. }
- 79. }
- 80.
- 81.
- 82. }
数据二次清理,进行排序
- package mapreduce;
- import java.io.IOException;
- import org.apache.hadoop.conf.Configuration;
- import org.apache.hadoop.fs.Path;
- import org.apache.hadoop.io.IntWritable;
- import org.apache.hadoop.io.Text;
- import org.apache.hadoop.mapreduce.Job;
- import org.apache.hadoop.mapreduce.Mapper;
- import org.apache.hadoop.mapreduce.Reducer;
- import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
- import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
- import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
- import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
- public class OneSort {
- public static class Map extends Mapper<Object , Text , IntWritable,Text >{
- private static Text goods=new Text();
- private static IntWritable num=new IntWritable();
- public void map(Object key,Text value,Context context) throws IOException, InterruptedException{
- String line=value.toString();
- String arr[]=line.split("\t");
- num.set(Integer.parseInt(arr[1]));
- goods.set(arr[0]);
- context.write(num,goods);
- }
- }
- public static class Reduce extends Reducer< IntWritable, Text, IntWritable, Text>{
- private static IntWritable result= new IntWritable();
- public void reduce(IntWritable key,Iterable<Text> values,Context context) throws IOException, InterruptedException{
- for(Text val:values){
- context.write(key,val);
- }
- }
- }
- public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException{
- Configuration conf=new Configuration();
- Job job =new Job(conf,"OneSort");
- job.setJarByClass(OneSort.class);
- job.setMapperClass(Map.class);
- job.setReducerClass(Reduce.class);
- job.setOutputKeyClass(IntWritable.class);
- job.setOutputValueClass(Text.class);
- job.setInputFormatClass(TextInputFormat.class);
- job.setOutputFormatClass(TextOutputFormat.class);
- Path in=new Path("hdfs://localhost:9000/mapreducetest/out1/part-r-00000");
- Path out=new Path("hdfs://localhost:9000/mapreducetest/out2");
- FileInputFormat.addInputPath(job,in);
- FileOutputFormat.setOutputPath(job,out);
- System.exit(job.waitForCompletion(true) ? 0 : 1);
- }
- }
从hadoop中读取文件
- package mapreduce;
- import java.io.BufferedReader;
- import java.io.IOException;
- import java.io.InputStreamReader;
- import java.net.URI;
- import java.util.ArrayList;
- import java.util.List;
- import org.apache.hadoop.conf.Configuration;
- import org.apache.hadoop.fs.FSDataInputStream;
- import org.apache.hadoop.fs.FileSystem;
- import org.apache.hadoop.fs.Path;
- public class ReadFile {
- public static List<String> ReadFromHDFS(String file) throws IOException
- {
- //System.setProperty("hadoop.home.dir", "H:\\文件\\hadoop\\hadoop-2.6.4");
- List<String> list=new ArrayList();
- int i=0;
- Configuration conf = new Configuration();
- StringBuffer buffer = new StringBuffer();
- FSDataInputStream fsr = null;
- BufferedReader bufferedReader = null;
- String lineTxt = null;
- try
- {
- FileSystem fs = FileSystem.get(URI.create(file),conf);
- fsr = fs.open(new Path(file));
- bufferedReader = new BufferedReader(new InputStreamReader(fsr));
- while ((lineTxt = bufferedReader.readLine()) != null)
- {
- String[] arg=lineTxt.split("\t");
- list.add(arg[0]);
- list.add(arg[1]);
- }
- } catch (Exception e)
- {
- e.printStackTrace();
- } finally
- {
- if (bufferedReader != null)
- {
- try
- {
- bufferedReader.close();
- } catch (IOException e)
- {
- e.printStackTrace();
- }
- }
- }
- return list;
- }
- public static void main(String[] args) throws IOException {
- List<String> ll=new ReadFile().ReadFromHDFS("hdfs://localhost:9000/mapreducetest/out2/part-r-00000");
- for(int i=0;i<ll.size();i++)
- {
- System.out.println(ll.get(i));
- }
- }
- }
前台网页代码
- <%@page import="mapreduce.ReadFile"%>
- <%@page import="java.util.List"%>
- <%@page import="java.util.ArrayList"%>
- <%@page import="org.apache.hadoop.fs.FSDataInputStream" %>
- <%@ page language="java" contentType="text/html; charset=UTF-8"
- pageEncoding="UTF-8"%>
- <!DOCTYPE html>
- <html>
- <head>
- <meta charset="UTF-8">
- <title>Insert title here</title>
- <% List<String> ll= ReadFile.ReadFromHDFS("hdfs://localhost:9000/mapreducetest/out2/part-r-00000");%>
- <script src="../js/echarts.js"></script>
- </head>
- <body>
- <div id="main" style="width: 900px;height:400px;"></div>
- <script type="text/javascript">
- // 基于准备好的dom,初始化echarts实例
- var myChart = echarts.init(document.getElementById('main'));
- // 指定图表的配置项和数据
- var option = {
- title: {
- text: '最繁忙的机场TOP10'
- },
- tooltip: {},
- legend: {
- data:['票数']
- },
- xAxis: {
- data:["<%=ll.get(ll.size()-1)%>"<%for(int i=ll.size()-3;i>=ll.size()-19;i--){
- if(i%2==1){
- %>,"<%=ll.get(i)%>"
- <%
- }
- }
- %>]
- },
- yAxis: {},
- series: [{
- name: '票数',
- type: 'bar',
- data: [<%=ll.get(ll.size()-2)%>
- <%for(int i=ll.size()-1;i>=ll.size()-19;i--){
- if(i%2==0){
- %>,<%=ll.get(i)%>
- <%
- }
- }
- %>]
- }]
- };
- // 使用刚指定的配置项和数据显示图表。
- myChart.setOption(option);
- </script>
- <h2 color="red"><a href="NewFile.jsp">返回</a></h2>
- </body>
结果截图:


Mapreduce数据分析实例的更多相关文章
- Hadoop数据分析实例:P2P借款人信用风险实时监控模型设计
Hadoop数据分析实例:P2P借款人信用风险实时监控模型设计 一提到hadoop相信熟悉IT领域或者经常关注互联网新闻的朋友都应该很熟悉了,当然,这种熟悉可能也只是听着名字耳熟,但并不知道它具体是什 ...
- MapReduce编程实例6
前提准备: 1.hadoop安装运行正常.Hadoop安装配置请参考:Ubuntu下 Hadoop 1.2.1 配置安装 2.集成开发环境正常.集成开发环境配置请参考 :Ubuntu 搭建Hadoop ...
- MapReduce编程实例5
前提准备: 1.hadoop安装运行正常.Hadoop安装配置请参考:Ubuntu下 Hadoop 1.2.1 配置安装 2.集成开发环境正常.集成开发环境配置请参考 :Ubuntu 搭建Hadoop ...
- MapReduce编程实例4
MapReduce编程实例: MapReduce编程实例(一),详细介绍在集成环境中运行第一个MapReduce程序 WordCount及代码分析 MapReduce编程实例(二),计算学生平均成绩 ...
- MapReduce编程实例3
MapReduce编程实例: MapReduce编程实例(一),详细介绍在集成环境中运行第一个MapReduce程序 WordCount及代码分析 MapReduce编程实例(二),计算学生平均成绩 ...
- MapReduce编程实例2
MapReduce编程实例: MapReduce编程实例(一),详细介绍在集成环境中运行第一个MapReduce程序 WordCount及代码分析 MapReduce编程实例(二),计算学生平均成绩 ...
- 三、MapReduce编程实例
前文 一.CentOS7 hadoop3.3.1安装(单机分布式.伪分布式.分布式 二.JAVA API实现HDFS MapReduce编程实例 @ 目录 前文 MapReduce编程实例 前言 注意 ...
- hadoop2.2编程:使用MapReduce编程实例(转)
原文链接:http://www.cnblogs.com/xia520pi/archive/2012/06/04/2534533.html 从网上搜到的一篇hadoop的编程实例,对于初学者真是帮助太大 ...
- Python实现MapReduce,wordcount实例,MapReduce实现两表的Join
Python实现MapReduce 下面使用mapreduce模式实现了一个简单的统计日志中单词出现次数的程序: from functools import reduce from multiproc ...
随机推荐
- [十]基础数据类型之Unicode编码简介
编码含义 关于编码的含义,之前也说过,计算机只能存储二进制序列 所以对于字符,保存的时候,需要进行编码为二进制,进行存储 呈现的时候,需要将二进制进行解码,转换成字符的形式 有很多种编码方式,比如 ...
- 第20章 定义客户端 - Identity Server 4 中文文档(v1.0.0)
客户端表示可以从您的身份服务器请求令牌的应用程序. 详细信息各不相同,但您通常会为客户端定义以下常用设置: 唯一的客户ID 如果需要的秘密 允许与令牌服务的交互(称为授权类型) 身份和/或访问令牌发送 ...
- DSAPI之摄像头追踪指定颜色物体
Private CAM As New DSAPI.摄像头_avicap32 Private Clr As Color = Color.FromArgb(230, 50, 50) Private _Lo ...
- 前端项目git操作命名规范和协作开发流程
前言 一个项目的分支,一般包括主干 master 和 开发分支 dev,以及若干临时分支 分支命名规范 分支: 命名: 说明: 主分支 master 主分支,所有提供给用户使用的正式版本,都在这个主分 ...
- prufer序列笔记
prufer序列 度娘的定义 Prufer数列是无根树的一种数列.在组合数学中,Prufer数列由有一个对于顶点标过号的树转化来的数列,点数为n的树转化来的Prufer数列长度为n-2. 对于一棵确定 ...
- pthread_once()函数详解
转自:pthread_once()函数详解 pthread_once()函数详解 在多线程环境中,有些事仅需要执行一次.通常当初始化应用程序时,可以比较容易地将其放在main函数中.但当你写一个库 ...
- 虹软2.0 离线人脸识别 Android 开发 Demo
环境要求1.运行环境 armeabi-v7a2.系统要求 Android 5.0 (API Level 21)及以上3.开发环境 Android Studio 下载地址:https://github. ...
- ionic3 Toast组件
html页面 <button ion-button color="dark" class="button-block" (click)="sho ...
- Linux 环境下 Git 安装与基本配置
索引: 目录索引 参看代码 GitHub: git.txt 一.Linux (DeepinOS) 环境 1.安装 sudo apt-get update sudo apt-get install gi ...
- macos 安装sublime text 3,如何安装插件
1. 上面的代码如下: import urllib.request,os,hashlib; h = '2915d1851351e5ee549c20394736b442' + '8bc59f460fa1 ...