ElasticSearch基础之批量操作(mget+mbulk)
在前面的演示中,我们都是基于一次http查询,每次查询都要建立http的三次握手请求,这样比较耗费性能!因此ES给我们提供了基本的批量查询功能,例如如下的查询,注意里面的index是可以任意指明的,不需要都一致
【01】批量查询之_mget操作,如下查询表示指定同时查询索引testdb下的两个type(job1和job2)里面的数据:注意我们可以在这里指定不同的索引,例如testdb1,testdb2;另外这里要指定doc关键词,表示我查询的是一个文档:
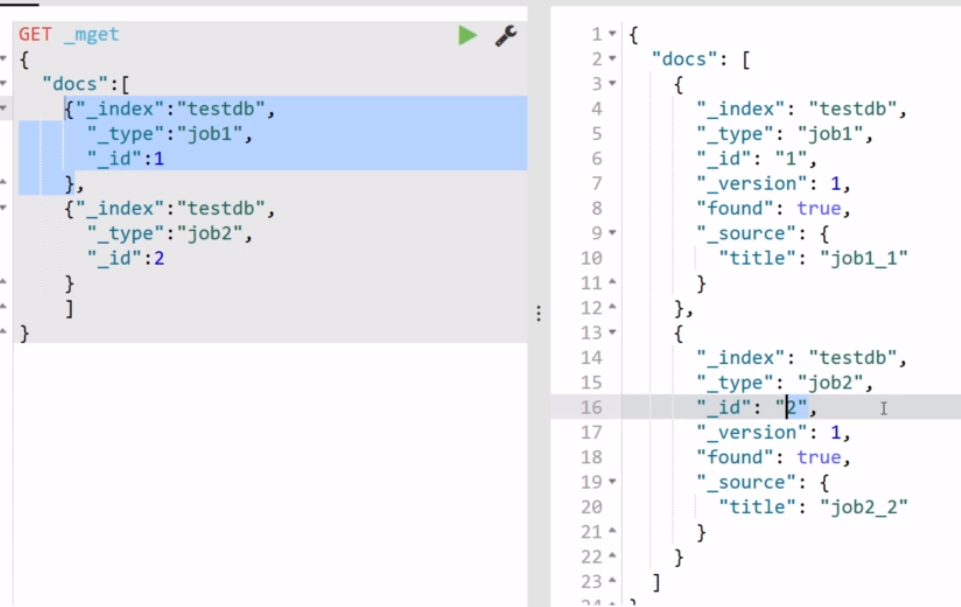
【02】查询同一个index下面不同type的数据,我们直接在url地址中先指明index为testdb,然后在里面就不用指明了:
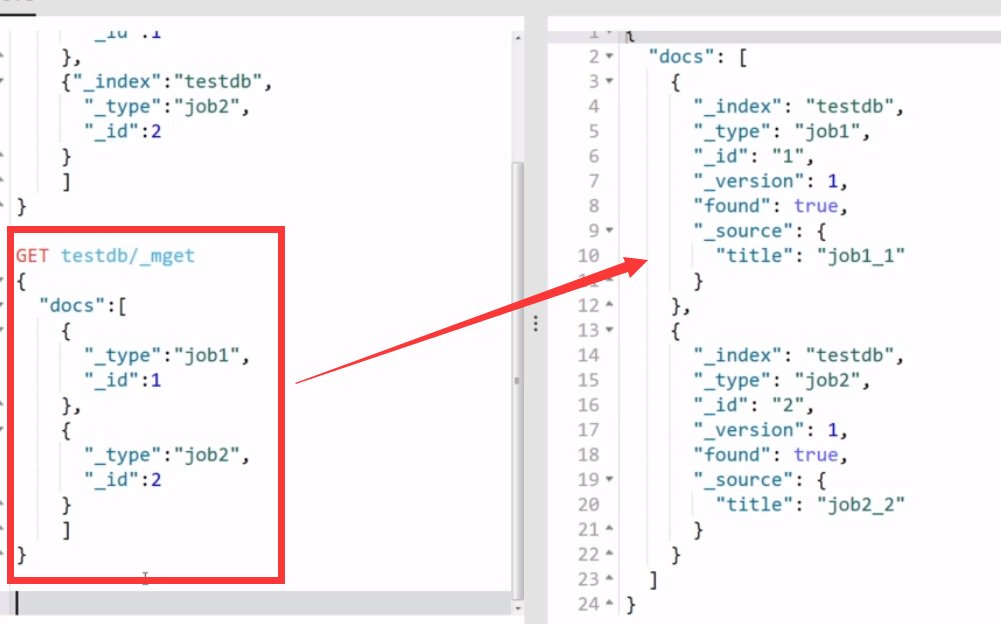
【03】如果连type都是一样的,那就只需要查询id了,依然不要忘记使用doc关键词
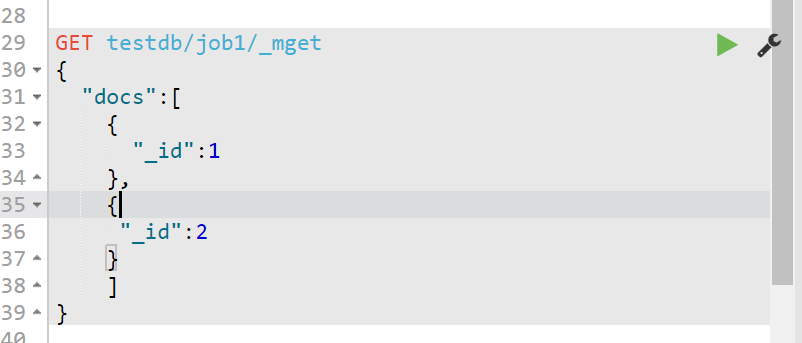
我们还可以基于上面的情形继续简写,下面这种写法就更加简便了

需要注意的是:上面使用docs指定时,它对应的value是一个数组,数组里面的每个元素都是字典。
【04】ES的bulk批量操作 来看看网络上的一张截图:

相当于就是使用了元数据来完成数据的批量导入,每导入一条数据,由两行构成,一条是元信息,另一条是数据行,来看看笔者实际的例子:

注意上面的数据格式一定要做成一行,不要优化成json数据格式
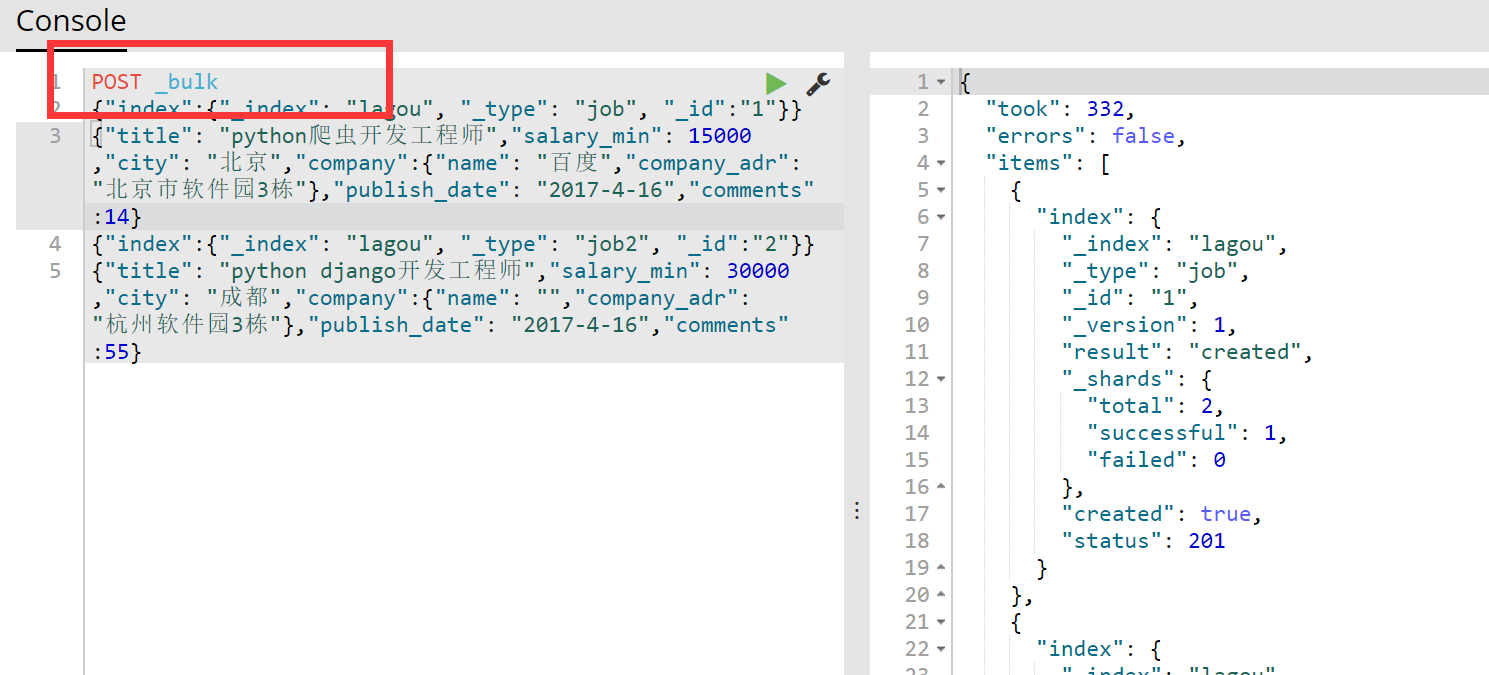
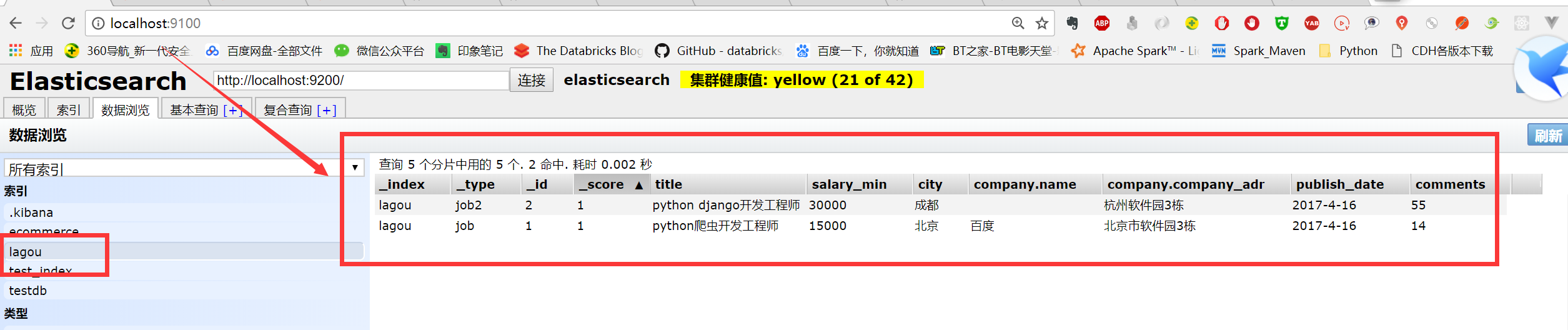
示例1:使用POST来完成bulk操作演示:蓝色的为元数据信息:
{"index":{"_index": "lagou", "_type": "job", "_id":"1"}}
{"title": "python爬虫开发工程师","salary_min": ,"city": "北京","company":{"name": "百度","company_adr": "北京市软件园3栋"},"publish_date": "2017-4-16","comments":}
{"index":{"_index": "lagou", "_type": "job2", "_id":"2"}}
{"title": "python django开发工程师","salary_min": ,"city": "成都","company":{"name": "","company_adr": "杭州软件园3栋"},"publish_date": "2017-4-16","comments":}
运行截图如下所示:记住在上面使用POST _bulk
注意事项:
关于bulk操作的解说:
.第一行是操作,例如index操作,后面的value是元数据,指明index操作是针对哪个索引,哪个type,哪个id进行的;
.第二行才是数据 但是要注意的是delete操作只有一行数据,因为只需要提供一个id即可 下面的create操作和update操作都是两行数据。
示例如下:

ElasticSearch基础之批量操作(mget+mbulk)的更多相关文章
- ELK(elasticsearch+kibana+logstash)搜索引擎(二): elasticsearch基础教程
1.elasticsearch的结构 首先elasticsearch目前的结构为 /index/type/id id对应的就是存储的文档ID,elasticsearch一般将数据以JSON格式存储. ...
- Elasticsearch 基础入门
原文地址:Elasticsearch 基础入门 博客地址:http://www.extlight.com 一.什么是 ElasticSearch ElasticSearch是一个基于 Lucene 的 ...
- ElasticSearch 基础 1
ElasticSearch 基础=============================== 索引创建 ========================== 1. RESTFUL APIAPI 基本 ...
- Elasticsearch基础但非常有用的功能之二:模板
文章转载自: https://mp.weixin.qq.com/s?__biz=MzI2NDY1MTA3OQ==&mid=2247484584&idx=1&sn=accfb65 ...
- elasticsearch 基础 —— _mget取回多个文档及_bulk批量操作
取回多个文档 Elasticsearch 的速度已经很快了,但甚至能更快. 将多个请求合并成一个,避免单独处理每个请求花费的网络延时和开销. 如果你需要从 Elasticsearch 检索很多文档,那 ...
- elasticsearch 基础 —— 分布式文档存储原理
路由一个文档到一个分片中 当索引一个文档的时候,文档会被存储到一个主分片中. Elasticsearch 如何知道一个文档应该存放到哪个分片中呢?当我们创建文档时,它如何决定这个文档应当被存储在分片 ...
- 最完整的Elasticsearch 基础教程
翻译:潘飞(tinylambda@gmail.com) 基础概念 Elasticsearch有几个核心概念.从一开始理解这些概念会对整个学习过程有莫大的帮助. 接近实时(NRT) Ela ...
- ELK 之一:ElasticSearch 基础和集群搭建
一:需求及基础: 场景: 1.开发人员不能登录线上服务器查看详细日志 2.各个系统都有日志,日志数据分散难以查找 3.日志数据量大,查询速度慢,或者数据不够实时 4.一个调用会涉及到多个系统,难以在这 ...
- Elasticsearch基础教程
Reference: http://blog.csdn.net/cnweike/article/details/33736429 基础概念 Elasticsearch有几个核心概念.从一开始理解这些概 ...
随机推荐
- linux查找文件夹下的全部文件里是否含有某个字符串
查找文件夹下的全部文件里是否含有某个字符串 find .|xargs grep -ri "IBM" 查找文件夹下的全部文件里是否含有某个字符串,而且仅仅打印出文件名称 fin ...
- 将iconv编译成lua接口
前一篇博文说了.在cocos2dx中怎么样使用iconv转码,这节我们将上一节中写的转码函数,做成一个lua接口.在lua脚本中使用. 网上能够下载到luaconv.可是编译的时候总是报错,所以自己写 ...
- PA-RISC
http://baike.baidu.com/view/167703.htm PA-RISC处理器 编辑 HP(惠普)公司的RISC芯片PA-RISC于1986年问世. 第一款芯片的型号为PA-8 ...
- 算法排序-NB三人组
快速排序: 堆排序: 二叉树: 两种特殊二叉树: 二叉树的存储方式: 小结: 堆排序正题: 向下调整: 堆排序过程: 堆排序-内置模块: 扩展问题topk: 归并排序: 怎么使用: NB三人组小结
- C# Winform 中webBrowser显示html内容时禁止错误提示的方法
在winform中有一个控件可以显示html的内容,该控件就是webbrowser,设置它的DocumenText属性为HTML的内容即可. 在使用WebBrowser做UI的时候,我们有时不希望里面 ...
- MongoDB 征途
到目前为止,对数据库这块仍然捉襟见肘,仅限于懂一些MySQL,就更谈不上什么优化了. 细想来,还是没有项目驱动造成的...既然跟关系型数据库缘分未到,干脆直接go to NoSQL - MongoDB ...
- 在Livemedia的基础上开发自己的流媒体客户端 V 0.01
在Livemedia的基础上开发自己的流媒体客户端 V 0.01 桂堂东 xiaoguizi@gmail.com 2004-10 2004-12 友情申明: 本文档适合已经从事流媒体传输工作或者对网络 ...
- 模式识别之分类器knn---c语言实现带训练数据---反余弦匹配
邻近算法 KNN算法的决策过程 k-Nearest Neighbor algorithm是K最邻近结点算法(k-Nearest Neighbor algorithm)的缩写形式,是电子信息分类器算 ...
- 多线程(C++)临界区Critical Sections
一 .Critical Sections(功能与Mutex相同,保证某一时刻只有一个线程能够访问共享资源,但是不是内核对象,所以访问速度比Mutex快,但是没有等待超时的功能,所以有可能导致死锁,使用 ...
- 用live555做流媒体转发服务器?
当我们看到这里,说明大家都有这样的一个想法:那就是如何用live555实现一个直播代理转发的流媒体服务器? 我们先不着急去讨论用live555实现流媒体转发的技术方法123,先从live555的整个架 ...