爬虫库之BeautifulSoup学习(二)
BeautifulSoup官方介绍文档:https://www.crummy.com/software/BeautifulSoup/bs4/doc/index.zh.html
四大对象种类:
BeautifulSoup 将复杂的html文件转换成一个复杂的树形结松,每个节点都是python对象。
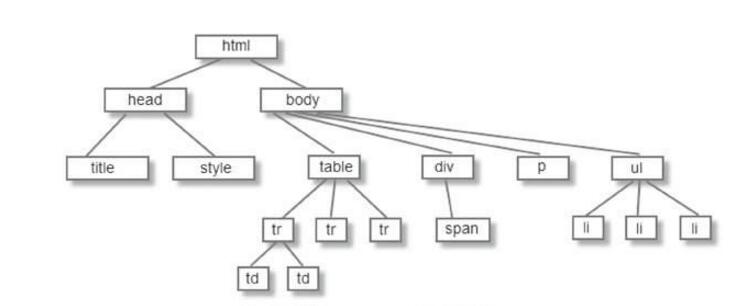
所有对象可以分下以下四类:
Tag
NavigableString
BeautifulSoup
Comment
下面进行一一介绍:
1、Tag
通俗点讲就是html中的一个个标签,例如:
<title>Hello world </title>
<a class ="test",href="http://www.baidu.com" id="link1"> Elsie </a>
上面的 title a 等等 HTML 标签加上里面包括的内容就是 Tag,下面我们来感受一下怎样用 Beautiful Soup 来方便地获取 Tags
下面每一段代码中注释部分为运行结果:
print soup.title
#<title>Hello world </title>
print soup.head
#<head><title>The Dormouse's story</title></head>
print soup.a
#<a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>
print soup.p
#<p class="title" name="dromouse"><b>The Dormouse's story</b></p>
我们可以利用 soup加标签名轻松地获取这些标签的内容,是不是感觉比正则表达式方便多了?
我们可以验证一下这些对象的类型:
print type(soup.a)
#<class 'bs4.element.Tag'>
对于tag,它有两个重要的属性,是name和attrs
name:
print soup.name
print soup.head.name
#[document]
2、NaviableString
既然我们已经得到了标签的内容,那么问题来了,我们要想获取标签内部的文字怎么办呢?很简单,用 .string 即可
print soup.p.string
#The Dormouse's story
检查一下它的类型
print type(soup.p.string)
#<class 'bs4.element.NavigableString'>
3、BeautifulSoup
对象表示的是一个文档的全部内容.大部分时候,可以把它当作 Tag 对象,是一个特殊的 Tag,我们可以分别获取它的类型,名称,以及属性来感受一下
print type(soup.name)
#<type 'unicode'>
print soup.name
#[document]
print soup.attrs
#{} 空字典
4、Comment
对象是一个特殊类型的 NavigableString 对象,其实输出的内容仍然不包括注释符号,但是如果不好好处理它,可能会对我们的文本处理造成意想不到的麻烦。
我们找一个带注释的标签
print soup.a
print soup.a.string
print type(soup.a.string)
结果如下:
<a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>
Elsie
<class 'bs4.element.Comment'>
a 标签里的内容实际上是注释,但是如果我们利用 .string 来输出它的内容,我们发现它已经把注释符号去掉了,所以这可能会给我们带来不必要的麻烦。
另外我们打印输出下它的类型,发现它是一个 Comment 类型,所以,我们在使用前最好做一下判断,判断代码如下:
if type(soup.a.string)=="bs4.element.Comment":
print soup.a.string
上面的代码中,我们首先判断了它的类型,是否为 Comment 类型,然后再进行其他操作,如打印输出。
实例应用:
import requests
from bs4 import BeautifulSoup
url = "http://www.baidu.com"
html_doc = requests.get(url).content
soup = BeautifulSoup(html_doc,'lxml')
for link in soup.find_all('a'):
print (link.get_text()) #获取tag中的文本内容
print (link.get('href')) #获取tag的属性,用get("attr")
爬虫库之BeautifulSoup学习(二)的更多相关文章
- 爬虫库之BeautifulSoup学习(一)
Beautiful Soup的简介 简单来说,Beautiful Soup是python的一个库,最主要的功能是从网页抓取数据. 官方解释如下: Beautiful Soup提供一些简单的.pytho ...
- 爬虫库之BeautifulSoup学习(五)
css选择器: 我们在写 CSS 时,标签名不加任何修饰,类名前加点,id名前加 #,在这里我们也可以利用类似的方法来筛选元素,用到的方法是 soup.select(),返回类型是 list 1)通过 ...
- 爬虫库之BeautifulSoup学习(四)
探索文档树: find_all(name,attrs,recursive,text,**kwargs) 方法搜索当前tag的所有tag子节点,并判断是否符合过滤器的条件 1.name参数,可以查找所有 ...
- 爬虫库之BeautifulSoup学习(三)
遍历文档树: 1.查找子节点 .contents tag的.content属性可以将tag的子节点以列表的方式输出. print soup.body.contents print type(soup. ...
- 【Python】在Pycharm中安装爬虫库requests , BeautifulSoup , lxml 的解决方法
BeautifulSoup在学习Python过程中可能需要用到一些爬虫库 例如:requests BeautifulSoup和lxml库 前面的两个库,用Pychram都可以通过 File--> ...
- 网页3D效果库Three.js学习[二]-了解照相机
camera 上篇大致了解了three.js ,并可以创建一个简单的可动的立方体.下来我们着重了解下camera (照相机),照相机其实就是视角,就像你的眼睛.Three.js有两种不同的相机模式:直 ...
- 使用Python爬虫库BeautifulSoup遍历文档树并对标签进行操作详解(新手必学)
为大家介绍下Python爬虫库BeautifulSoup遍历文档树并对标签进行操作的详细方法与函数下面就是使用Python爬虫库BeautifulSoup对文档树进行遍历并对标签进行操作的实例,都是最 ...
- 爬虫概念与编程学习之如何爬取视频网站页面(用HttpClient)(二)
先看,前一期博客,理清好思路. 爬虫概念与编程学习之如何爬取网页源代码(一) 不多说,直接上代码. 编写代码 运行 <!DOCTYPE html><html><head& ...
- python爬虫解析库之Beautifulsoup模块
一 介绍 Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式.Beautiful Soup会 ...
随机推荐
- js event 的target 和currentTarget
target 点击的实际tag currentTarget 绑定事件的target
- 初识kbmmw 中的smartbind功能
关于kbmmw smartbind 的开发原因及思路,大家可以参见官方的博客说明和红鱼儿的翻译. 今天我就实例操作一下,给大家演示一下具体实现. 我们新建一个工程 放几个基本的控件 在单元里面加上引用 ...
- Hibernate基础知识介绍
一.什么是Hibernate? Hibernate,翻译过来是冬眠的意思,其实对于对象来说就是持久化.持久化(Persistence),即把数据(如内存中的对象)保存到可永久保存的存储设备中(如磁盘) ...
- 九度OJ 1117:整数奇偶排序 (排序)
时间限制:1 秒 内存限制:32 兆 特殊判题:否 提交:3174 解决:932 题目描述: 输入10个整数,彼此以空格分隔.重新排序以后输出(也按空格分隔),要求: 1.先输出其中的奇数,并按从大到 ...
- r squared
multiple r squared adjusted r squared http://web.maths.unsw.edu.au/~adelle/Garvan/Assays/GoodnessOfF ...
- cocos2d-js v3新特性
1.游戏对象 使用cc.game单例代替了原有的cc.Application以及cc.AppControl 2.属性风格API 旧的API ...
- Java版TicTacToe
MainFrame.java package com.bu_ish; import java.awt.BorderLayout; import java.awt.Color; import java. ...
- ABAP- INCLUDE Zxxx IF FOUND.
大顾代码: INCLUDE zinc_ca_0002 IF FOUND. - 这肯定是大顾问写出来的 - 一般都不会加东西啊 -加了 IF FOUND 不知道啥意思. 古道无仙(173120830) ...
- SQL 系统表应用
查看link server select DD.System,DD.DB,DD.previous_processing_dte, DD.processing_dte,LS.LinkServerName ...
- java 浮点数
package precisenumber; //import java.util.*;public class PreciseNumber { public int fore; public int ...