使用python实现简单的爬虫
python爬虫的简单实现
开发环境配置
python环境的安装
python环境使用的是3.0以上版本
为了便于安装这里使用的是anaconda
下载链接是anaconda
选择下载64位即可 

编辑器的安装
这里使用pycharm作为python开发的编辑器,下载网址 pycharm
下载Community社区版即可 
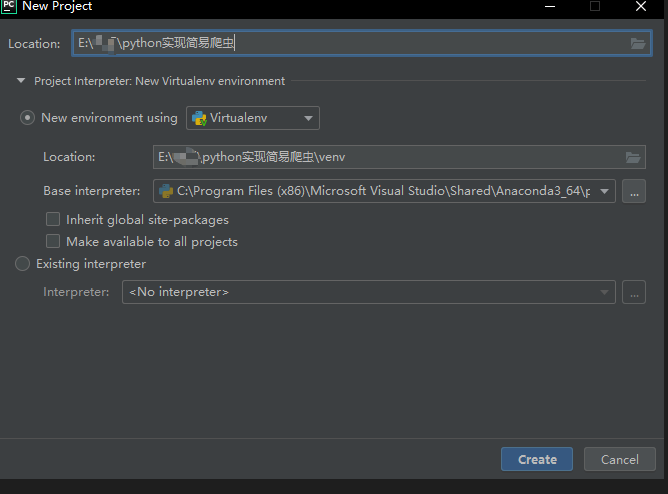
在打开pycharm创建新项目的时候如下图所示,那么就代表了环境已经安装好了 
爬虫的实现
包的安装
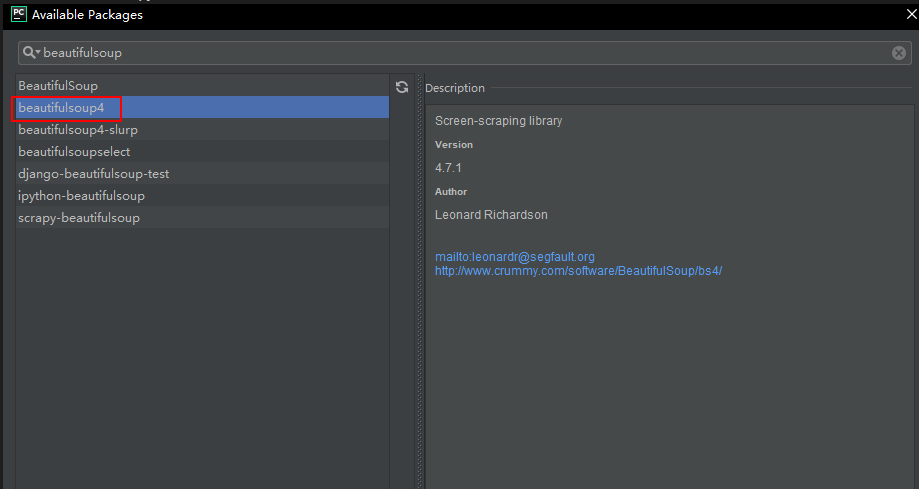
我们这里使用的爬虫插件是beautifulsoup不属于python的基础库,所以我们需要另行添加插件,在pycharm添加插件也是非常简单的,只需要在file->settings->project->project interpreter添加对应的插件即可 

点击+号即可选择需要的python包进行安装 
简单爬虫的初步实现
接下来就要开始真正的写爬虫了
#首先需要引入包
from urllib.request import urlopen
from bs4 import BeautifulSoup html = urlopen("https://www.cnblogs.com/ladyzhu/p/9617567.html")#括号内的是需要爬取的网址地址
bsObj = BeautifulSoup(html.read()) print(bsObj.title)
将数据写入到数据库
简单的数据清洗
前面我们已经爬取到到了一个简单的网页的信息,但是这些信息是杂乱无章的,接下我们已爬取研招网的院校库为例,爬取每个院校的校名、所在地、院校隶属,学习一下如何进行一个简单的数据处理与爬取。
我们可以看到整个界面是十分复杂的,但是我们可以进行一个分析,我们所需要的数据仅仅是最下面的表格内的数据
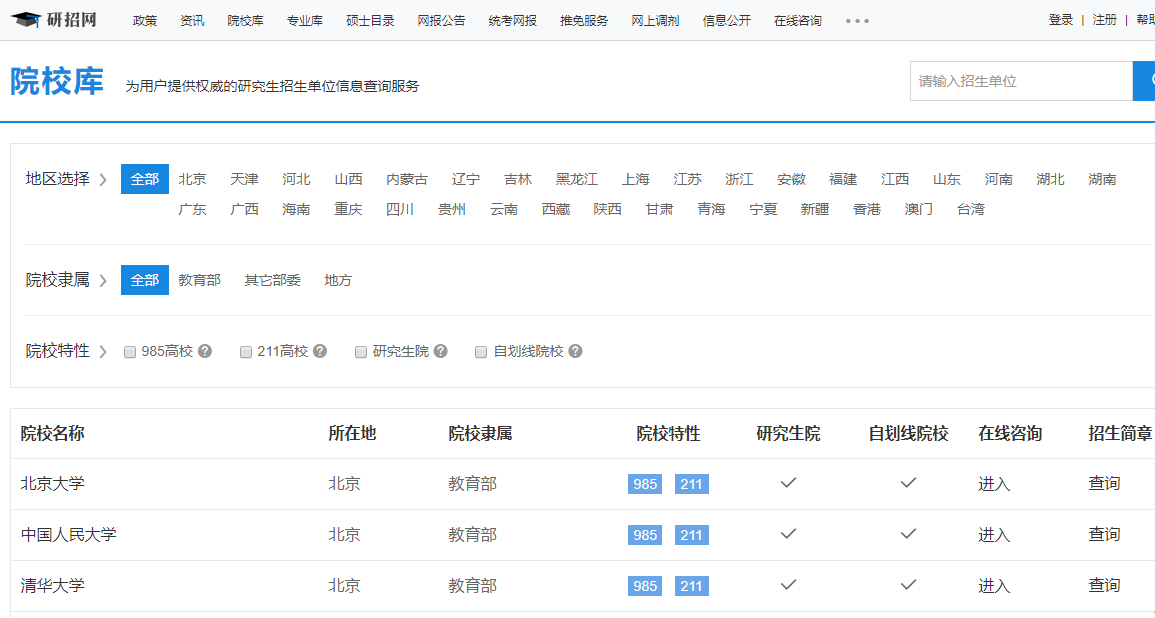

通过查看网页源码可以发现,所有的院校信息确实是保存在下面的一个table之中的
<table class="ch-table">
<thead>
<tr>
<th>院校名称</th>
<th width="100">所在地</th>
<th width="150">院校隶属</th>
<th width="100" class="ch-table-center">院校特性</th>
<th width="100" class="ch-table-center">研究生院</th>
<th width="100" class="ch-table-center">自划线院校</th>
<th width="90">在线咨询</th>
<th width="90">招生简章</th>
</tr>
</thead>
<tbody>
<tr>
<td>
<a href="/sch/schoolInfo--schId-367878.dhtml" target="_blank">北京大学</a>
</td>
<td>北京</td>
<td>教育部</td>
<td class="ch-table-center">
<span class="ch-table-tag">985</span>
<span class="ch-table-tag">211</span>
</td>
<td class="ch-table-center">
<i class="iconfont ch-table-tick"></i>
</td>
<td class="ch-table-center">
<i class="iconfont ch-table-tick"></i>
</td>
<td>
<a href="/zxdy/forum--type-sch,forumid-455559,method-listDefault,start-0,year-2014.dhtml"target="_blank">进入</a>
</td>
<td class="text_center">
<a href="/sch/listZszc--schId-367878,categoryId-10460768,mindex-13,start-0.dhtml" target="_blank">查询</a>
</td>
</tr>
<tr>
<td>
<a href="/sch/schoolInfo--schId-367879.dhtml" target="_blank">中国人民大学</a>
</td>
<td>北京</td>
<td>教育部</td>
<td class="ch-table-center">
<span class="ch-table-tag">985</span>
<span class="ch-table-tag">211</span>
</td>
<td class="ch-table-center">
<i class="iconfont ch-table-tick"></i>
</td>
<td class="ch-table-center">
<i class="iconfont ch-table-tick"></i>
</td>
<td>
<a href="/zxdy/forum--type-sch,forumid-441209,method-listDefault,start-0,year-2014.dhtml"
target="_blank">进入</a>
</td>
<a href="/sch/listZszc--schId-367879,categoryId-10460770,mindex-13,start-0.dhtml" target="_blank">查询</a>
</td>
</tr>
<tr>
<td>
<a href="/sch/schoolInfo--schId-367880.dhtml" target="_blank">
清华大学
</a>
</td>
<td>北京</td>
<td>教育部</td>
<td class="ch-table-center">
<span class="ch-table-tag">985</span>
<span class="ch-table-tag">211</span>
</td>
<td class="ch-table-center">
<i class="iconfont ch-table-tick"></i>
</td>
<td class="ch-table-center">
<i class="iconfont ch-table-tick"></i>
</td>
<td>
<a href="/zxdy/forum--type-sch,forumid-441314,method-listDefault,start-0,year-2014.dhtml"
target="_blank">进入</a>
</td>
<td class="text_center">
<a href="/sch/listZszc--schId-367880,categoryId-10460772,mindex-13,start-0.dhtml" target="_blank">查询</a>
</td>
</tr>
<tr>
<td>
<a href="/sch/schoolInfo--schId-367881.dhtml" target="_blank">
北京交通大学
</a>
</td>
<td>北京</td>
<td>教育部</td>
<td class="ch-table-center">
<span class="ch-table-tag ch-table-tag-empty"></span>
<span class="ch-table-tag">211</span>
</td>
<td class="ch-table-center">
<i class="iconfont ch-table-tick"></i>
</td>
<td class="ch-table-center">
</td>
<td>
<a href="/zxdy/forum--type-sch,forumid-455567,method-listDefault,start-0,year-2014.dhtml"
target="_blank">进入</a>
</td>
<td class="text_center">
<a href="/sch/listZszc--schId-367881,categoryId-10460774,mindex-13,start-0.dhtml" target="_blank">查询</a>
</td>
</tr>
<tr>
<td>
<a href="/sch/schoolInfo--schId-367882.dhtml" target="_blank">
北京工业大学
</a>
</td>
<td>北京</td>
<td>北京市</td>
<td class="ch-table-center">
<span class="ch-table-tag ch-table-tag-empty"></span>
<span class="ch-table-tag">211</span>
</td>
<td class="ch-table-center">
</td>
<td class="ch-table-center">
</td>
<td>
<a href="/zxdy/forum--type-sch,forumid-441418,method-listDefault,start-0,year-2014.dhtml"
target="_blank">进入</a>
</td>
<td class="text_center">
<a href="/sch/listZszc--schId-367882,categoryId-10460776,mindex-13,start-0.dhtml" target="_blank">查询</a>
</td>
</tr>
<tr>
<td>
<a href="/sch/schoolInfo--schId-367883.dhtml" target="_blank">北京航空航天大学
</a>
</td>
<td>北京</td>
<td>工业与信息化部</td>
<td class="ch-table-center">
<span class="ch-table-tag">985</span>
<span class="ch-table-tag">211</span>
</td>
</tbody>
</table>
我们可以发现数据是有规律的,每个tr的首个td是学校的名称,第二个td是院校所在地,第三个td是院校的隶属,我们需要的信息都有了,应该如何对这些复杂的信息进行一个简单的清洗呢?
#爬取院校信息方法
from urllib.request import urlopen
import pymysql
from urllib.error import HTTPError,URLError
from bs4 import BeautifulSoup
import re #爬取院校信息方法
def findSchoolInfo(url):
try:
html = urlopen(url)
except HTTPError as e:
return None
try:
bsObj = BeautifulSoup(html.read(),'lxml')
shcoolInfo = bsObj.findAll("table",{"class":"ch-table"})
except AttributeError as e:
return None
return shcoolInfo #处理信息为需要的信息
def handleSchoolInfo(info):
if info == None:
print("没有院校信息")
else:
school_list = []
for item in info:
list = item.findAll("tr")
for x in list:
school = x.findAll("td")
if len(school)
school_list.append(school[0:3])
else:
continue
for item in school_list:
school_name = item[0].get_text().strip()
school_shengfen = item[1].get_text()
shcool_belong = item[2].get_text() shcoolInfo = findSchoolInfo("https://yz.chsi.com.cn/sch/search.do?start=0"
handleSchoolInfo(shcoolInfo)
print("爬取完成")
在findSchoolInfo方法中我们初步对数据进行了一个处理,使用了findAll来进行了数据的首次爬取,可以看到所需要的表格已经被爬取到了 

在handleSchoolInfo方法中同样使用到了findAll("tr")来对数据进行一个清洗,通过tr的筛选之后,table标签已经没有了 
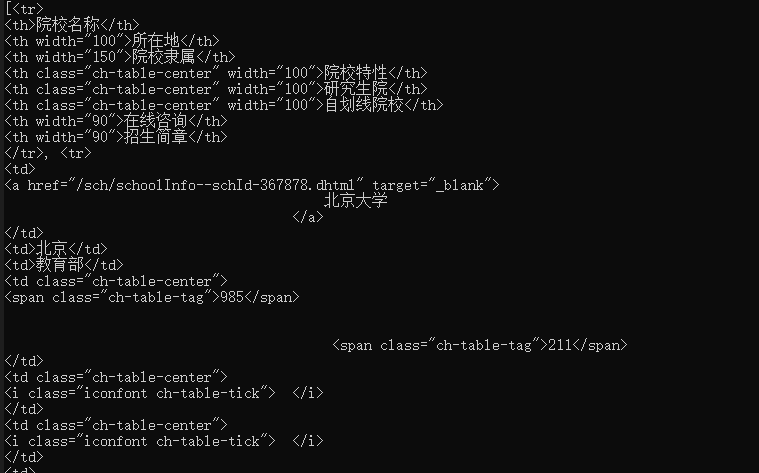
同理我们使用findAll("td")来进行td的筛选,同时可以发现一个数据是为空的,因为通过前面tr的筛选的首行信息里面是th而不是td的 

接下来由于只需要每个数据的前三行,所以只需要将前三个数据保存即可,然后将保存的数据进行一个有效数据的剥离
school_list.append(school[0:3])
for item in school_list:
school_name = item[0].get_text().strip()
school_shengfen = item[1].get_text()
shcool_belong = item[2].get_text()
但是此时爬取到的数据也仅仅是当前页的数据,通过分析研招网的链接不难得知,每一页之间的差距仅仅是在最后的参数不同,那么在爬虫的URL进行修改即可
https://yz.chsi.com.cn/sch/?start=0
https://yz.chsi.com.cn/sch/?start=20
index = 0
while index < 44:
shcoolInfo = findSchoolInfo("https://yz.chsi.com.cn/sch/search.do?start="+str(index*20))
handleSchoolInfo(shcoolInfo)
index+=1
数据库的连接
使用的数据库是SQL Server 2012,首先需要的是进行包的安装与引入使用的是
import pyodbc
安装参考包的安装
pyodbc模块是用于odbc数据库(一种数据库通用接口标准)的连接,不仅限于SQL server,还包括Oracle,MySQL,Access,Excel等
连接字符串的编写
conn = pyodbc.connect(r'DRIVER={SQL Server Native Client 11.0};SERVER=数据库的IP地址;DATABASE=需要连接的数据库名称;UID=用户名;PWD=密码')
连接对象的建立
在完成连接字符串之后,我们需要建立连接对象
cursor = conn.cursor()
数据库连接就已经完成了,接下来就是数据库的基本操作了
数据写入到数据库
上面我们已经找到了需要的数据同时也建立了数据库的连接,接下来就是将数据插入到数据库了
def insertDB(school_name,school_shengfen,shcool_belong):
sql = "INSERT INTO tb_school(school_name,school_shengfen,school_belong) \
VALUES ('%s', '%s', '%s')" % \
(school_name,school_shengfen,shcool_belong)
try:
cursor.execute(sql)
conn.commit()
print(school_shengfen+"\t"+school_name+"添加成功")
except:
print("插入出错")
conn.rollback()
我们可以看到数据库内确实已经有数据了
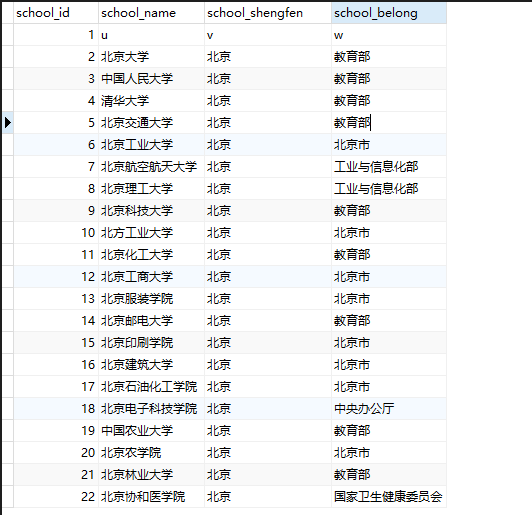

最后关闭数据库的连接
conn.close()
参考引用:
[1] Ryan Mitchell. Web Scraping with Python[M]. O'Reilly Media ,2015.
[2] Python连接SQL Server入门
使用python实现简单的爬虫的更多相关文章
- Python 利用Python编写简单网络爬虫实例3
利用Python编写简单网络爬虫实例3 by:授客 QQ:1033553122 实验环境 python版本:3.3.5(2.7下报错 实验目的 获取目标网站“http://bbs.51testing. ...
- Python 利用Python编写简单网络爬虫实例2
利用Python编写简单网络爬虫实例2 by:授客 QQ:1033553122 实验环境 python版本:3.3.5(2.7下报错 实验目的 获取目标网站“http://www.51testing. ...
- [Python学习] 简单网络爬虫抓取博客文章及思想介绍
前面一直强调Python运用到网络爬虫方面很有效,这篇文章也是结合学习的Python视频知识及我研究生数据挖掘方向的知识.从而简介下Python是怎样爬去网络数据的,文章知识很easy ...
- 使用Python编写简单网络爬虫抓取视频下载资源
我第一次接触爬虫这东西是在今年的5月份,当时写了一个博客搜索引擎.所用到的爬虫也挺智能的,起码比电影来了这个站用到的爬虫水平高多了! 回到用Python写爬虫的话题. Python一直是我主要使用的脚 ...
- Python实现简单的爬虫获取某刀网的更新数据
昨天晚上无聊时,想着练习一下Python所以写了一个小爬虫获取小刀娱乐网里的更新数据 #!/usr/bin/python # coding: utf-8 import urllib.request i ...
- python一个简单的爬虫测试
之前稍微学了一点python,后来一直都没用,今天稍微做一个小爬虫试一试.. 参考了: http://www.cnblogs.com/fnng/p/3576154.html 太久没用了,都忘记pych ...
- 用Python写简单的爬虫
准备: 1.扒网页,根据URL来获取网页信息 import urllib.parse import urllib.request response = urllib.request.urlopen(& ...
- 【Python开发】【神经网络与深度学习】如何利用Python写简单网络爬虫
平时没事喜欢看看freebuf的文章,今天在看文章的时候,无线网总是时断时续,于是自己心血来潮就动手写了这个网络爬虫,将页面保存下来方便查看 先分析网站内容,红色部分即是网站文章内容div,可以看 ...
- python`最简单的爬虫`实现
不管怎么样,一天一更的好习惯一定要保持,现在一天不写点东西都感觉不踏实,总会感觉少了点什么,废话少说,记录一下今天初学的spider(甚至说不上是spider,I'm so vagetable [/认 ...
随机推荐
- Vue的十个常用指令
1.v-text:用于更新标签包含的文本,作用和{{}}的效果一样. 2.v-html:绑定一些包含html代码的数据在视图上. 3.v-show:用来控制元素的display属性,和显示隐藏有关.v ...
- Somethings about Floors题解
题目内容:一个楼梯有N级(N >=0), 每次走1级或2级, 从底走到顶一共有多少种走法? 输入要求:只有一行输入,并且只有一个数N(如果N > 20,则N = N%21,即保证N的范围控 ...
- SQL 转换函数
1.字符串与字符串相加 字符串相加 得到的是拼接成一列的字符串类型 例如 select name+code from car name是nvarchar code也是nvarchar ...
- 洛谷 P2068 统计和
题目描述 给定一个长度为n(n<=100000),初始值都为0的序列,x(x<=10000)次的修改某些位置上的数字,每次加上一个数,然后提出y (y<=10000)个问题,求每段区 ...
- codevs 1146 ISBN号码
时间限制: 1 s 空间限制: 128000 KB 题目等级 : 白银 Silver 题目描述 Description 每一本正式出版的图书都有一个ISBN号码与之对应,ISBN码包括9位数字.1 ...
- openstack安装dashboard后访问horizon出错 End of script output before headers: django.wsgi
在配置文件中增加如下的一句解决问题 /etc/apache2/conf-available/openstack-dashboard.conf WSGIApplicationGroup %{GLOBAL ...
- App Store上的开源应用汇总
以下是互联网上主要的开源iOS应用的列表,在学习的时候,多看看完成的功能代码可以给我们带来很多经验,但是除了Apple官方提供的Sample Code之外,我们很难找到优质的开源项目代码,所以我搜集了 ...
- WPF中引入外部资源
有时候需要在WPF中引入外部资源,比如图片.音频.视频等,所以这个常见的技能还是需要GET到. 第一步:在VS中创建一个WPF窗口程序 第二步:从外部引入资源,这里以引入图片资源为例 1)新建Reso ...
- JavaWeb项目实现图片验证码
一.什么是图片验证码? 可以参考下面这张图: 我们在一些网站注册的时候,经常需要填写以上图片的信息. 这种图片验证方式是我们最常见的形式,它可以有效的防范恶意攻击者采用恶意工具,调用“动态验证码短信获 ...
- django 第一次运行出错
直接运行整个项目正常,直接运行url文件报错 报错内容: E:\Python\python.exe D:/Python储存文件/ceshiweb/ceshiweb/urls.pyTraceback ( ...