mysql一次性和多次取数据的性能测试
1.表结构

2.数据量
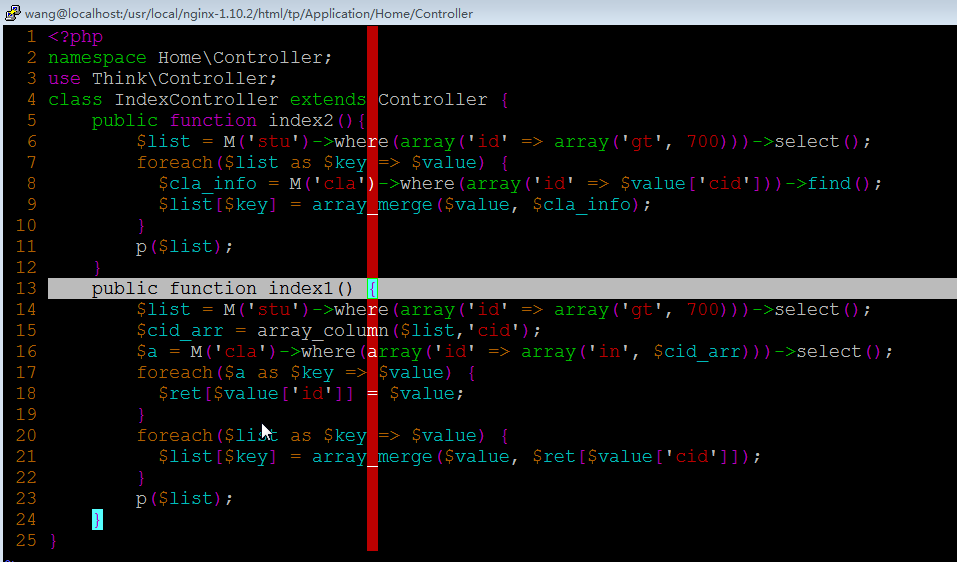
3.代码
先从学生表里面查出300名学生,然后找出每个学生的班级信息,然后merge起来
3.性能对比
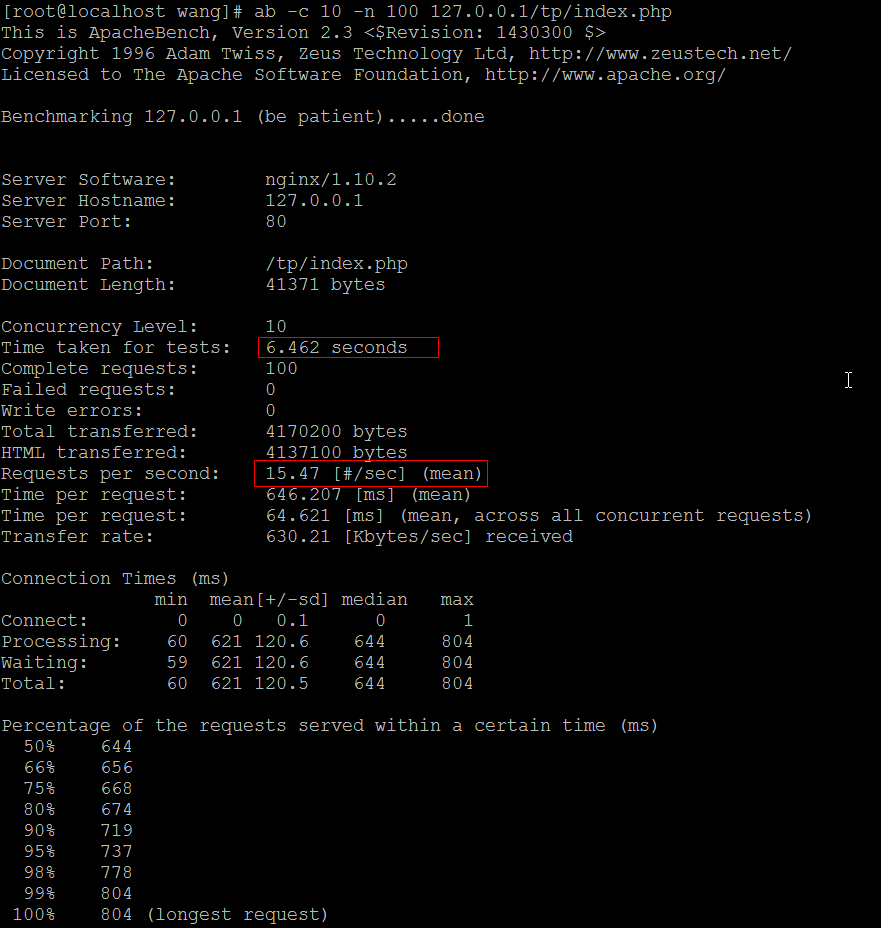
第一种:每次取一条
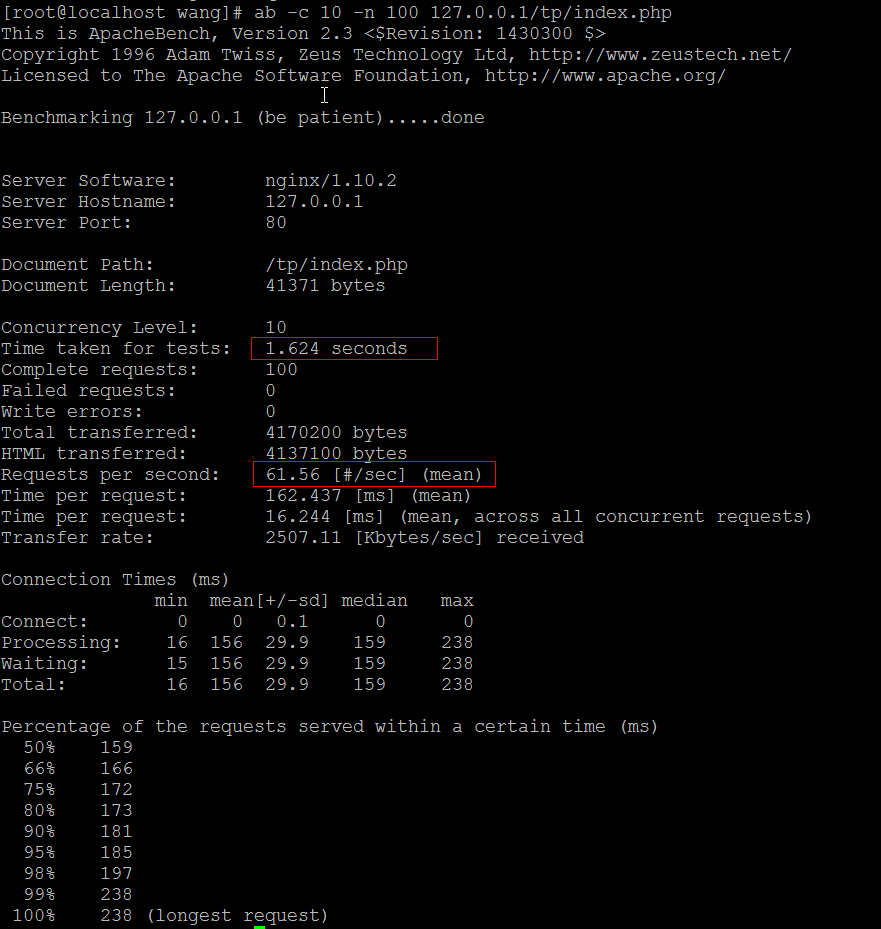
第二种:一次全去除
4.总结
不能循环取从数据库中取数据,性能会很差,与mysql建立连接很耗时,IO次数多也耗性能。mysql一次性和多次取数据的性能测试的更多相关文章
- mysql 查询 根据时分秒取数据 比如 取 时间为 8点半的 dateformat 时间函数转换
date_format(date,'%H') = 8 and date_format(date,'%i') = 30 SELECT * FROM `t_pda_trucklog` WHERE D ...
- 解决 MySQL 比如我要拉取一个消息表中用户id为1的前10条最新数据
我们都知道,各种主流的社交应用或者阅读应用,基本都有列表类视图,并且都有滑到底部加载更多这一功能, 对应后端就是分页拉取数据.好处不言而喻,一般来说,这些数据项都是按时间倒序排列的,用户只关心最新的动 ...
- windows环境下nutch2.x 在eclipse中实现抓取数据存进mysql详细步骤
nutch2.x 在eclipse中实现抓取数据存进mysql步骤 最近在研究nutch,花了几天时间,也遇到很多问题,最终结果还是成功了,在此记录,并给其他有兴趣的人提供参考,共同进步. 对nutc ...
- python第一个爬虫的例子抓取数据到mysql,实测有数据
python3.5 先安装库或者扩展 1 requests第三方扩展库 pip3 install requests 2 pymysql pip3 install pymysql 3 lxml pip3 ...
- python之scrapy爬取数据保存到mysql数据库
1.创建工程 scrapy startproject tencent 2.创建项目 scrapy genspider mahuateng 3.既然保存到数据库,自然要安装pymsql pip inst ...
- 从redis数据库取数据存放到本地mysql数据库
redis数据库属于非关系型数据库,数据存放在内存堆栈中,效率比较高. 其存储数据是以json格式字符串存储字典的,而类似的关系型数据库无法实现这种数据的存储. 在爬取数据时,将数据暂存到redis中 ...
- canal从mysql拉取数据,并以protobuf的格式往kafka中写数据
大致思路: canal去mysql拉取数据,放在canal所在的节点上,并且自身对外提供一个tcp服务,我们只要写一个连接该服务的客户端,去拉取数据并且指定往kafka写数据的格式就能达到以proto ...
- mysql实现高效率随机取数据
从数据库中(mysql)随机获取几条数据很简单,但是如果一个表的数据基数很大,比如一千万,从一千万中随机产生10条数据,那就相当慢了,如果同时一百个人访问网站,处理这些个进程,对于一般的服务器来说,肯 ...
- Mysql分片后分页排序拉取数据的方法
高并发大流量的互联网架构,一般通过服务层来访问数据库,随着数据量的增大,数据库需要进行水平切分,分库后将数据分布到不同的数据库实例(甚至物理机器)上,以达到降低数据量,增加实例数的扩容目的. 一旦涉及 ...
随机推荐
- 重读金典------高质量C编程指南(林锐)-------第七章 内存管理
2015/12/10补充: 当我们需要给一个数组返回所赋的值的时候,我们需要传入指针的指针.当我们只需要一个值的时候,传入指针即可,或者引用也可以. 结构大致如下: char* p = (char*) ...
- bottle的几个小坑
距离我在<web.py应用工具库:webpyext>里说要换用bottle,已经过去快两个月了--事实上在那之前我已经開始着手在换了.眼下那个用于 Backbone.js 介绍的样例程序已 ...
- 团队项目的Git分支管理规范
原文地址: http://blog.jboost.cn/2019/06/17/git-branch.html 许多公司的开发团队都采用Git来做代码版本控制.如何有效地协同开发人员之间,以及开发.测试 ...
- (webstorm的css编写插件)Emmet:HTML/CSS代码快速编写神器
Emmet的前身是大名鼎鼎的Zen coding,如果你从事Web前端开发的话,对该插件一定不会陌生.它使用仿CSS选择器的语法来生成代码,大大提高了HTML/CSS代码编写的速度,比如下面的演示: ...
- FileInputStream 的读取操作
package xinhuiji_day07; import java.io.File;import java.io.FileInputStream;import java.io.FileNotFou ...
- Spark源码分析之九:内存管理模型
Spark是现在很流行的一个基于内存的分布式计算框架,既然是基于内存,那么自然而然的,内存的管理就是Spark存储管理的重中之重了.那么,Spark究竟采用什么样的内存管理模型呢?本文就为大家揭开Sp ...
- php解析带有命名空间的xml
xml如果带有命名空间我们将如何解析,例如: <ns1:CreateBillResponse xmlns:ns1="http://neusoft.com" xmlns:xsd ...
- RethinkDB创始人教你怎样找到创业点子
watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQvemh1YmFpdGlhbg==/font/5a6L5L2T/fontsize/400/fill/I0JBQk ...
- 【PyCharm编辑器】之报:Spellchecker inspection helps locate typos and misspelling in your code, comments and literals, and fix them in one click.问题
如上图,输入一个单词时会出现波浪线,报:Spellchecker inspection helps locate typos and misspelling in your code, comment ...
- 1_Jsp标签_简单自定义
一 简介 主要用于移除jsp页面中的java代码 编写一个实现Tag接口的Java类,为避免需要实现不必要的方法,只需继承TagSupport类, 把页面java代码移到这个标签处理类中, 然后编写标 ...