删除SQL Server大容量日志的方法(转)
删除SQL Server大容量日志的方法
亲自实践的方法
1、分享数据库,如果提示被其他连接占用,不能分离,刚勾上drop connections
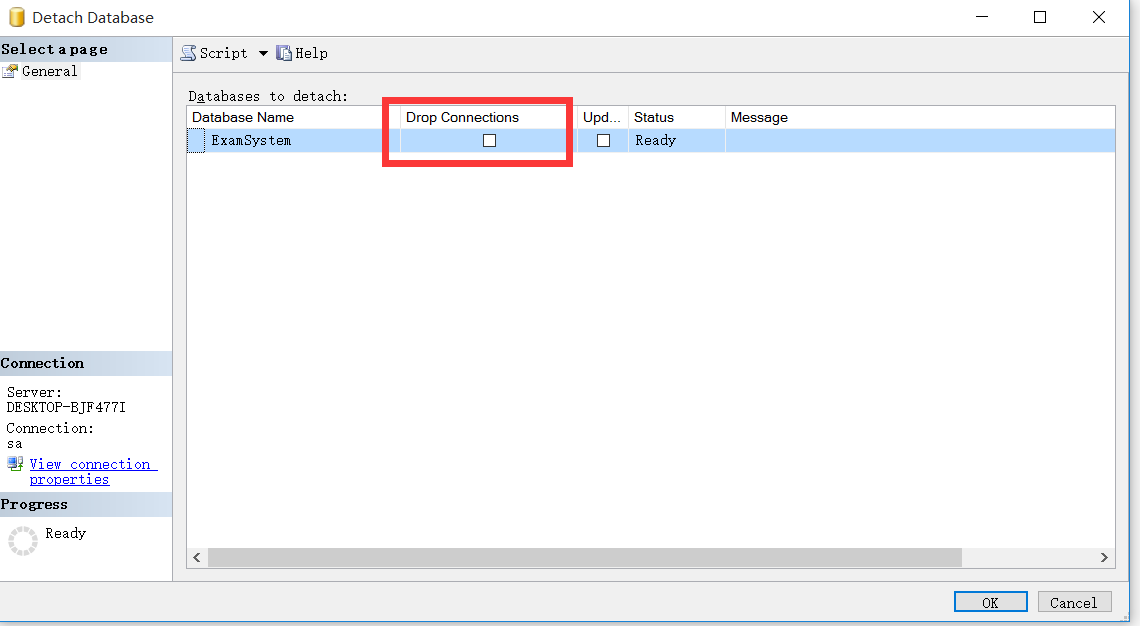
2、复制下所有文件,一定要备份好,以防自己操作失误

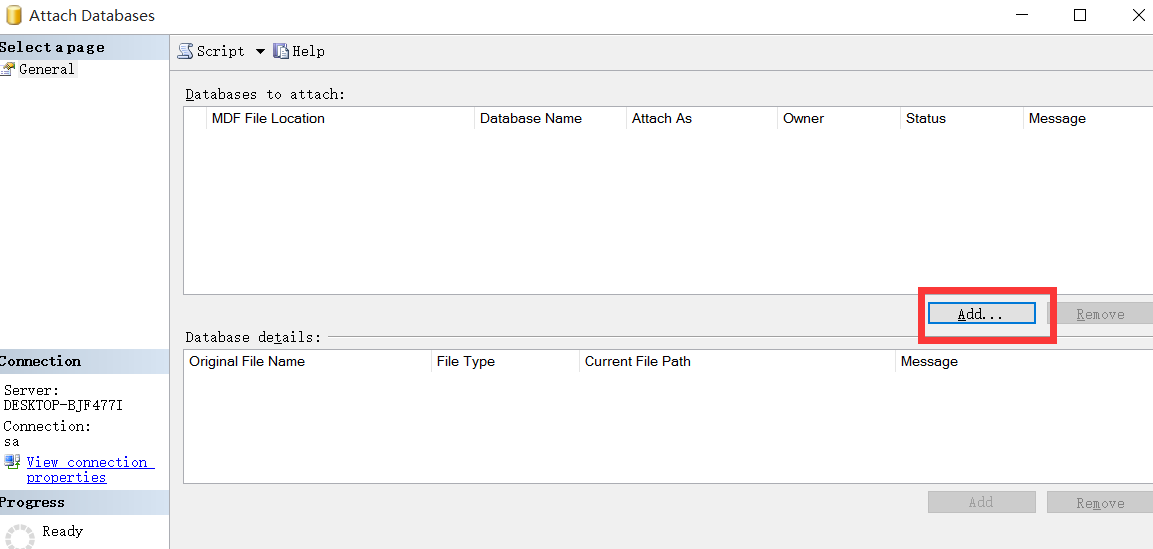
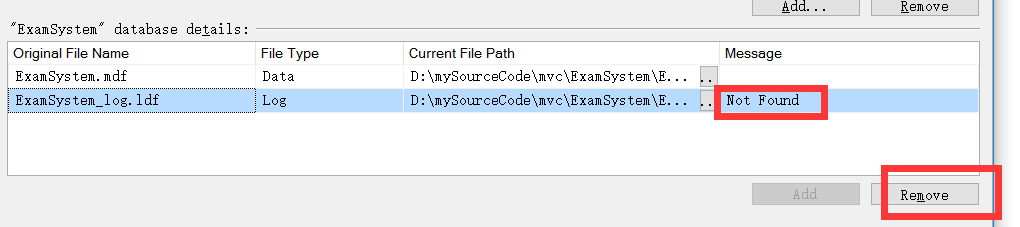
3、附加数据库时,你会发现Log文件not found,选中,remove,确定后,就会生成新的Log文件
转自http://www.dedecms.com/knowledge/data-base/sql-server/2012/0821/11808.html
编辑语:像我们服务器一般使用工具将log1M,不嫌麻烦可以看看手工方法:
1: 删除LOG
1:分离 企业管理器->服务器->数据库->右键->分离数据库
2:删除LOG文件
3:附加数据库 企业管理器->服务器->数据库->右键->附加数据库
此法生成新的LOG,大小只有520多K
再将此数据库设置自动收缩
或用代码:
下面的示例分离 77169database,然后将 77169database 中的一个文件附加到当前服务器。
EXEC sp_detach_db @dbname = 77169database
EXEC sp_attach_single_file_db @dbname = 77169database,
@physname = c:Program FilesMicrosoft SQL ServerMSSQLData77169database.mdf
2:清空日志
DUMP TRANSACTION 库名 WITH NO_LOG
再:
企业管理器--右键你要压缩的数据库--所有任务--收缩数据库--收缩文件--选择日志文件--在收缩方式里选择收缩至XXM,这里会给出一个允许收缩到的最小M数,直接输入这个数,确定就可以了
3:不让它增长
企业管理器->服务器->数据库->属性->事务日志->将文件增长限制为2M
自动收缩日志,也可以用下面这条语句
ALTER DATABASE 数据库名
SET AUTO_SHRINK ON
故障还原模型改为简单,用语句是
USE MASTER
GO
ALTER DATABASE 数据库名 SET RECOVERY SIMPLE
GO
---------------------------------------------------------------------------------
截断事务日志:
BACKUP LOG { database_name | @database_name_var }
{
[ WITH
{ NO_LOG | TRUNCATE_ONLY } ]
}
--压缩日志及数据库文件大小
/*--特别注意
请按步骤进行,未进行前面的步骤,请不要做后面的步骤
否则可能损坏你的数据库.
--*/
1.清空日志
DUMP TRANSACTION 库名 WITH NO_LOG
2.截断事务日志:
BACKUP LOG 数据库名 WITH NO_LOG
3.收缩数据库文件(如果不压缩,数据库的文件不会减小
企业管理器--右键你要压缩的数据库--所有任务--收缩数据库--收缩文件
--选择日志文件--在收缩方式里选择收缩至XXM,这里会给出一个允许收缩到的最小M数,直接输入这个数,确定就可以了
--选择数据文件--在收缩方式里选择收缩至XXM,这里会给出一个允许收缩到的最小M数,直接输入这个数,确定就可以了
也可以用SQL语句来完成
--收缩数据库
DBCC SHRINKDATABASE(客户资料)
--收缩指定数据文件,1是文件号,可以通过这个语句查询到:select * from sysfiles
DBCC SHRINKFILE(1)
4.为了最大化的缩小日志文件(如果是sql 7.0,这步只能在查询分析器中进行)
a.分离数据库:
企业管理器--服务器--数据库--右键--分离数据库
b.在我的电脑中删除LOG文件
c.附加数据库:
企业管理器--服务器--数据库--右键--附加数据库
此法将生成新的LOG,大小只有500多K
或用代码:
下面的示例分离 77169database,然后将 77169database 中的一个文件附加到当前服务器。
a.分离
EXEC sp_detach_db @dbname = 77169database
b.删除日志文件
c.再附加
EXEC sp_attach_single_file_db @dbname = 77169database,
@physname = c:Program FilesMicrosoft SQL ServerMSSQLData77169database.mdf
5.为了以后能自动收缩,做如下设置:
企业管理器--服务器--右键数据库--属性--选项--选择"自动收缩"
--SQL语句设置方式:
EXEC sp_dboption 数据库名, autoshrink, TRUE
6.如果想以后不让它日志增长得太大
企业管理器--服务器--右键数据库--属性--事务日志
--将文件增长限制为xM(x是你允许的最大数据文件大小)
--SQL语句的设置方式:
alter database 数据库名 modify file(name=逻辑文件名,maxsize=20)
-------------------------------------------------------------------------------------------
/*--压缩数据库的通用存储过程
压缩日志及数据库文件大小
因为要对数据库进行分离处理
所以存储过程不能创建在被压缩的数据库中 /*
--调用示例
exec p_compdb test
--*/
use master --注意,此存储过程要建在master数据库中
go
if exists (select * from dbo.sysobjects where id = object_id(N[dbo].[p_compdb]) and OBJECTPROPERTY(id, NIsProcedure) = 1)
drop procedure [dbo].[p_compdb]
GO
create proc p_compdb
@dbname sysname, --要压缩的数据库名
@bkdatabase bit=1, --因为分离日志的步骤中,可能会损坏数据库,所以你可以选择是否自动数据库
@bkfname nvarchar(260)= --备份的文件名,如果不指定,自动备份到默认备份目录,备份文件名为:数据库名+日期时间
as
--1.清空日志
exec(DUMP TRANSACTION [+@dbname+] WITH NO_LOG)
--2.截断事务日志:
exec(BACKUP LOG [+@dbname+] WITH NO_LOG)
--3.收缩数据库文件(如果不压缩,数据库的文件不会减小
exec(DBCC SHRINKDATABASE([+@dbname+]))
--4.设置自动收缩
exec(EXEC sp_dboption )
--后面的步骤有一定危险,你可以可以选择是否应该这些步骤
--5.分离数据库
if @bkdatabase=1
begin
if isnull(@bkfname,)=
set @bkfname=@dbname+_+convert(varchar,getdate(),112)
+replace(convert(varchar,getdate(),108),:,)
select 提示信息=备份数据库到SQL 默认备份目录,备份文件名:+@bkfname
exec(backup database [+@dbname+] to )
end
--进行分离处理
create table #t(fname nvarchar(260),type int)
exec(insert into #t select filename,type=status&0x40 from [+@dbname+]..sysfiles)
exec(sp_detach_db )
--删除日志文件
declare @fname nvarchar(260),@s varchar(8000)
declare tb cursor local for select fname from #t where type=64
open tb
fetch next from tb into @fname
while @@fetch_status=0
begin
set @s=del "+rtrim(@fname)+"
exec master..xp_cmdshell @s,no_output
fetch next from tb into @fname
end
close tb
deallocate tb
--附加数据库
set @s=
declare tb cursor local for select fname from #t where type=0
open tb
fetch next from tb into @fname
while @@fetch_status=0
begin
set @s=@s+,+rtrim(@fname)+
fetch next from tb into @fname
end
close tb
deallocate tb
exec(sp_attach_single_file_db )
go
删除SQL Server大容量日志的方法(转)的更多相关文章
- MS SQL SERVER 数据库日志压缩方法与代码
MS SQL性能是很不错的,但是数据库用了一段时间之后,数据库却变得很大,实际的数据量不大.一般都是数据库日志引起的!数据库日志的增长可以达到好几百M. DUMP TRANSACTION [数据库名] ...
- SQL Server 2008删除或压缩数据库日志的方法
SQL Server 2008删除或压缩数据库日志的方法 2010-09-20 20:15 由 于数据库日志增长被设置为“无限制”,所以时间一长日志文件必然会很大,一个400G的数据库居然有600G的 ...
- 最简单删除SQL Server中所有数据的方法
最简单删除SQL Server中所有数据的方法 编写人:CC阿爸 2014-3-14 其实删除数据库中数据的方法并不复杂,为什么我还要多此一举呢,一是我这里介绍的是删除数据库的所有数据,因为数据之间 ...
- 最简单删除SQL Server中所有数据的方法(不用考虑表之间的约束条件,即主表与子表的关系)
其实删除数据库中数据的方法并不复杂,为什么我还要多此一举呢,一是我这里介绍的是删除数据库的所有数据,因为数据之间可能形成相互约束关系,删除操作可能陷入死循环,二是这里使用了微软未正式公开的sp_MSF ...
- SQL Server 错误日志收缩(ERRORLOG)
一.基础知识 默认情况下,错误日志位于 : C:\Program Files\Microsoft SQL Server\MSSQL.1\MSSQL\LOG\ERRORLOG 和ERRORLOG.n 文 ...
- SQL Server 使用日志传送
参考文献: http://msdn.microsoft.com/en-us/library/ms187103.aspx 概述 SQL Server 使用日志传送,您可以自动将“主服务器”实例上“主数据 ...
- 【数据库】Sql Server 2008完全卸载方法(其他版本类似)
本文介绍如何卸载 Microsoft SQL Server 2008的方法.当您按照本文中的步骤时,您还准备系统以便可以重新安装 SQL Server 2008版本 一. SQL2008卸载. ...
- SQL Server 错误日志过滤(ERRORLOG)
一.背景 有一天我发现SQL Server服务器的错误日志中包括非常多关于sa用户的登陆错误信息:“Login failed for user 'sa'. 原因: 评估密码时出错.[客户端: XX.X ...
- SQL Server自动化运维系列——监控磁盘剩余空间及SQL Server错误日志(Power Shell)
需求描述 在我们的生产环境中,大部分情况下需要有自己的运维体制,包括自己健康状态的检测等.如果发生异常,需要提前预警的,通知形式一般为发邮件告知. 在所有的自检流程中最基础的一个就是磁盘剩余空间检测. ...
随机推荐
- isinstance与type的区别
1.isinstance()内置函数 python中的isinstance()函数是python的内置函数,用来判断一个函数是否是一个已知类型.类似type. 2.用法: isinstance(obj ...
- Java 输入/输出——处理流(RandomAccessFile)
RandomAccessFile是Java输入/输出流体系中功能最丰富的文件内容访问类,它提供了众多的方法来访问文件内容,它既可以读取文件内容,也可以向文件输出数据.与普通的输入/输出流不同的是,Ra ...
- [qemu][cloud][centos][ovs][sdn] centos7安装高版本的qemu 以及 virtio/vhost/vhost-user咋回事
因为要搭建ovs-dpdk,所以需要vhost-user的qemu centos默认的qemu与qemu-kvm都不支持vhost-user,qemu最高版本是2.0.0, qemu-kvm最高版本是 ...
- Kafka – kafka consumer
ConsumerRecords<String, String> records = consumer.poll(100); /** * Fetch data for the topic ...
- mysql学习【第2篇】:MySQL数据管理
狂神声明 : 文章均为自己的学习笔记 , 转载一定注明出处 ; 编辑不易 , 防君子不防小人~共勉 ! mysql学习[第2篇]:MySQL数据管理 外键管理 外键概念 如果公共关键字在一个关系中是主 ...
- mysql报错Establishing SSL connection without server's identity verification is not recommended
使用mysql数据库时报错:Establishing SSL connection without server's identity verification is not recommended ...
- B+树vs. LSM树(转)
原文:<大型网站技术架构:核心原理与案例分析>,作者:李智慧 本书前面提到,由于传统的机械磁盘具有快速顺序读写.慢速随机读写的访问特性,这个特性对磁盘存储结构和算法的选择影响甚大. 为了改 ...
- 分布式任务队列Celery入门与进阶
一.简介 Celery是由Python开发.简单.灵活.可靠的分布式任务队列,其本质是生产者消费者模型,生产者发送任务到消息队列,消费者负责处理任务.Celery侧重于实时操作,但对调度支持也很好,其 ...
- UVA11491 奖品的价值
奖品的价值C804 运行时间限制:1000ms: 运行空间限制:51200KB 试题描述 你是一个电视节目的获奖嘉宾.主持人在黑板上写出一个 n 位非负整数(不以 0 开头),邀请你删除其中的 d 个 ...
- FastDFS的使用
1.FastDFS 1.1. 什么是FastDFS? FastDFS是用c语言编写的一款开源的分布式文件系统.FastDFS为互联网量身定制,充分考虑了冗余备份.负载均衡.线性扩容等机制,并注重高可用 ...