sklearn聚类模型:基于密度的DBSCAN;基于混合高斯模型的GMM
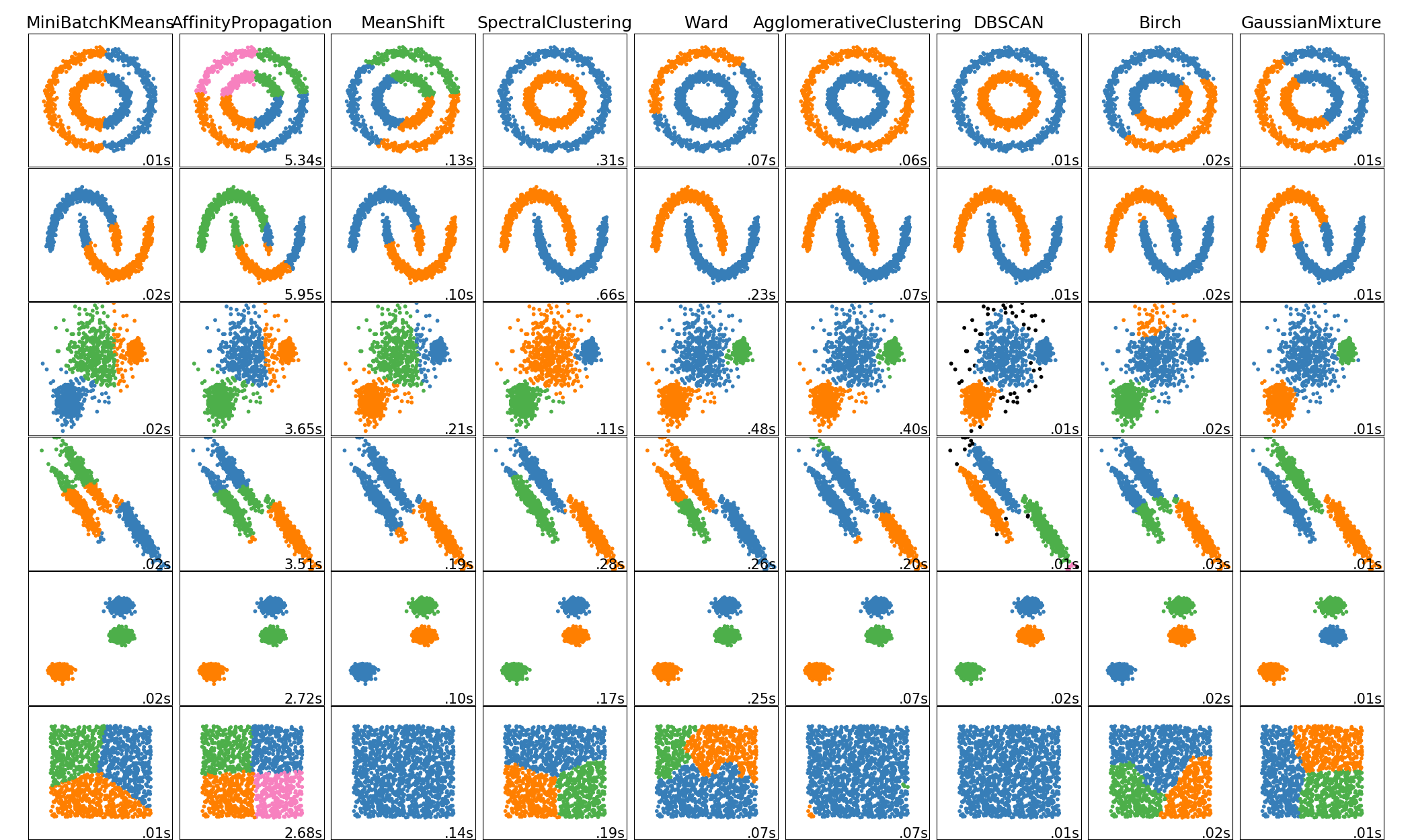
4 用scikit-learn学习DBSCAN聚类 (基于密度的聚类)
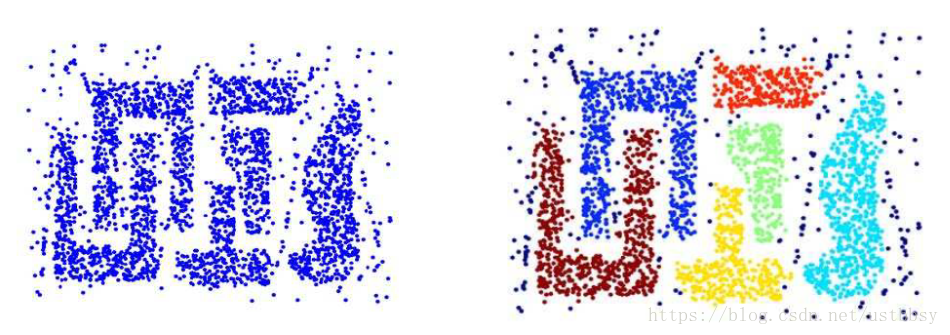
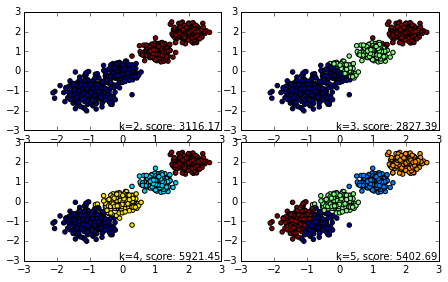
6 混合高斯模型Gaussian Mixture Model(GMM)

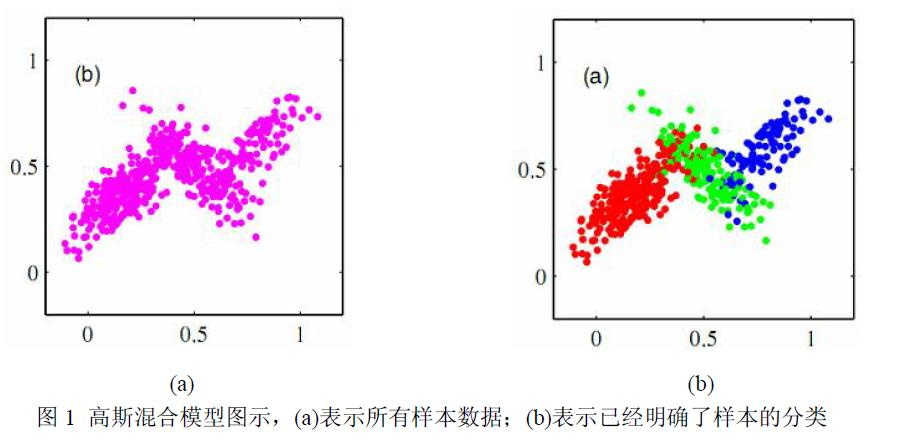
#===============================================
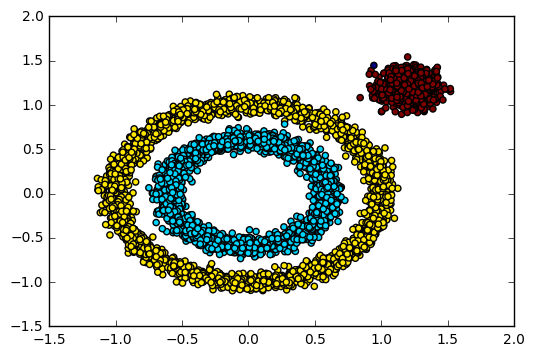
从左到右依次为: k-means聚类, DBSCAN聚类 , GMM聚类
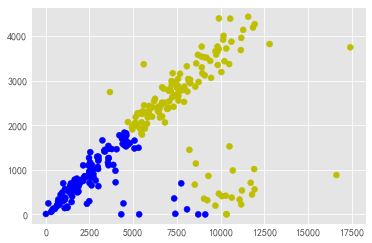


对应代码:
# kmeans聚类
from sklearn.cluster import KMeans
estimator = KMeans(n_clusters=2)#构造聚类器
y_pred =estimator.fit_predict(X_train_2)#聚类 clr = ['b' if i==0 else 'y' if i==1 else 'r' for i in y_pred]
plt.scatter(X_train[:,0],X_train[:,1],c=clr) # DBSCAN(Density-Based Spatial Clustering of Application with Noise)基于密度的空间聚类算法
from sklearn.cluster import DBSCAN
dbs1 = DBSCAN(eps=0.5, # 邻域半径
min_samples=5 ) # 最小样本点数,MinPts
y_pred = dbs1.fit_predict(X_train_2) #训练集的标签 clr = ['b' if i==0 else 'y' if i==1 else 'r' for i in y_pred]
plt.scatter(X_train_2[:,0],X_train_2[:,1],c=clr) #混合高斯模型Gaussian Mixture Model(GMM)聚类
from sklearn import mixture
clf = mixture.GaussianMixture(n_components=2,covariance_type='full')
clf.fit(X_train_2) #.fit_predict
y_pred = clf.predict(X_train_2) #预测
clr = ['b' if i==0 else 'y' if i==1 else 'r' for i in y_pred]
plt.scatter(X_train_2[:,0],X_train_2[:,1],c=clr)
sklearn聚类模型:基于密度的DBSCAN;基于混合高斯模型的GMM的更多相关文章
- PRML读书会第九章 Mixture Models and EM(Kmeans,混合高斯模型,Expectation Maximization)
主讲人 网络上的尼采 (新浪微博: @Nietzsche_复杂网络机器学习) 网络上的尼采(813394698) 9:10:56 今天的主要内容有k-means.混合高斯模型. EM算法.对于k-me ...
- [zz] 混合高斯模型 Gaussian Mixture Model
聚类(1)——混合高斯模型 Gaussian Mixture Model http://blog.csdn.net/jwh_bupt/article/details/7663885 聚类系列: 聚类( ...
- <转>与EM相关的两个算法-K-mean算法以及混合高斯模型
转自http://www.cnblogs.com/jerrylead/archive/2011/04/06/2006924.html http://www.cnblogs.com/jerrylead/ ...
- EM相关两个算法 k-mean算法和混合高斯模型
转自http://www.cnblogs.com/jerrylead/archive/2011/04/06/2006924.html http://www.cnblogs.com/jerrylead/ ...
- Opencv混合高斯模型前景分离
#include "stdio.h" #include "string.h" #include "iostream" #include &q ...
- 混合高斯模型:opencv中MOG2的代码结构梳理
/* 头文件:OurGaussmix2.h */ #include "opencv2/core/core.hpp" #include <list> #include&q ...
- 运动检测(前景检测)之(二)混合高斯模型GMM
运动检测(前景检测)之(二)混合高斯模型GMM zouxy09@qq.com http://blog.csdn.net/zouxy09 因为监控发展的需求,目前前景检测的研究还是很多的,也出现了很多新 ...
- 混合高斯模型(GMM)推导及实现
作者:桂. 时间:2017-03-20 06:20:54 链接:http://www.cnblogs.com/xingshansi/p/6584555.html 声明:欢迎被转载,不过记得注明出处哦 ...
- 混合高斯模型(Mixtures of Gaussians)和EM算法
这篇讨论使用期望最大化算法(Expectation-Maximization)来进行密度估计(density estimation). 与k-means一样,给定的训练样本是,我们将隐含类别标签用表示 ...
随机推荐
- c#中用lua脚本执行redis命令
直接贴出代码,实现执行lua脚本的方法,用到的第三方类库是 StackExchange.Redis(nuget上有) 注:下面的代码是简化后的,实际使用要修改, using System; using ...
- 安装架设Apache+MySQL+PHP网站环境
转载自 http://blog.sina.com.cn/s/blog_c02ed6590101d2sl.html 并进行了个人编辑整理 一.安装 MySQL 首先来进行 MySQL 的安装.打开超级终 ...
- k8s 常用命令汇集
通过yaml文件创建: kubectl create -f xxx.yaml (不建议使用,无法更新,必须先delete) kubectl apply -f xxx.yaml (创建+更新,可以重复使 ...
- kafka关于修改副本数和分区的数的案例实战(也可用作leader节点均衡案例)
kafka关于修改副本数和分区的数的案例实战(也可用作leader节点均衡案例) 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.关于topic分区数的修改 1>.创建1分 ...
- Golang面向对象编程-struct(结构体)
Golang面向对象编程-struct(结构体) 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.什么是面向对象编程 面向对象编程(Object Oriented Program ...
- python自动化运维之路~DAY2
python自动化运维之路~DAY2 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.字符编码与转码 1.什么是编码. 基本概念很简单.首先,我们从一段信息即消息说起,消息以人类 ...
- Git-Credential-Manager-for-Mac-and-Linux
1.安装brew 安装命令: /usr/bin/ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/instal ...
- java8的新特性详解-----------Lamda表达式
java8最大的亮点就是引入了Lamda表达式 , 函数式编程的概念 具体啥意思我也不知道.只管用就行了,非常的强大,简洁,一个表达式相当于以前的十几行代码 因为之前要实现这种效果全靠if el ...
- iscroll.js 手机上下滑动 加载更多
html <!DOCTYPE html> <html> <head> <title>下拉上拉刷新页面代码</title> <meta ...
- KillerBee
KillerBee介绍 KillerBee----是攻击zigbee和IEEE 802.15.4网络的框架和工具.使用killerBee工具和一个兼容的IEEE 802.15.4无线接口,你就能窃取z ...