python 全栈开发,Day123(图灵机器人,web录音实现自动化交互问答)
昨日内容回顾
- . 百度ai开放平台
- . AipSpeech技术,语言合成,语言识别
- . Nlp技术,短文本相似度
- . 实现一个简单的问答机器人
- . 语言识别 ffmpeg (目前所有音乐,视频领域,这个工具应用非常广泛)
- 在不要求采样率的情况下,它会根据文件后缀名自动转换
- ffmpeg a.mp3 a.wav
一、图灵机器人
介绍
图灵机器人 是以语义技术为核心驱动力的人工智能公司,致力于“让机器理解世界”,产品服务包括机器人开放平台、机器人OS和场景方案。
官方地址为:
使用
首先得注册一个账号,或者使用第3方登录,都可以。
登录之后,点击创建机器人
机器人名称,可以是自己定义的名字
选择网站->教育学习->其他 输入简介
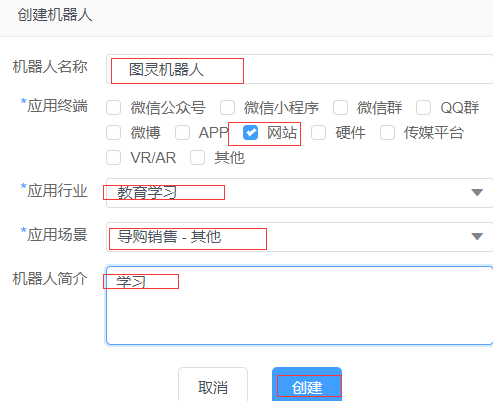
创建成功之后,点击终端设置,拉到最后。
可以看到api接入,下面有一个apikey,待会会用到

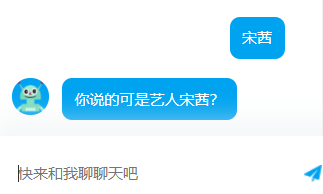
右侧有一个窗口,可以和机器人聊天
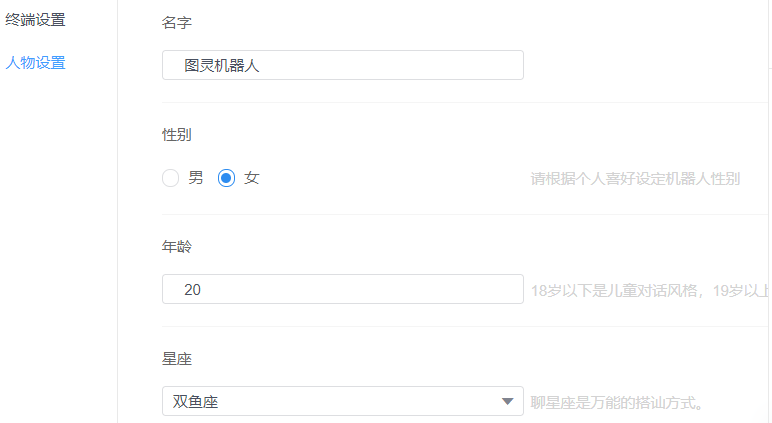
可以设置它的个人信息
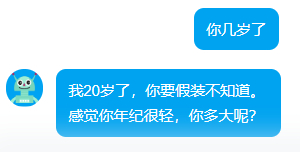
测试聊天
星座下面的功能都要花钱的
技能扩展,可以全开
使用api
点击api使用文档,1.0的api已经下线了。目前只有2.0
https://www.kancloud.cn/turing/www-tuling123-com/718227
编码方式
UTF-8(调用图灵API的各个环节的编码方式均为UTF-8)
接口地址
http://openapi.tuling123.com/openapi/api/v2
请求方式
HTTP POST
请求参数
请求参数格式为 json
请求示例:
- {
- "reqType":0,
- "perception": {
- "inputText": {
- "text": "附近的酒店"
- },
- "inputImage": {
- "url": "imageUrl"
- },
- "selfInfo": {
- "location": {
- "city": "北京",
- "province": "北京",
- "street": "信息路"
- }
- }
- },
- "userInfo": {
- "apiKey": "",
- "userId": ""
- }
- }
举例:
新建文件 tuling.py,询问天气
- import requests
- import json
- apiKey = "6a944508fd5c4d499b9991862ea12345"
- userId = "xiao" # 名字可以随意,必须是英文
- data = {
- # 请求的类型 0 文本 1 图片 2 音频
- "reqType": 0,
- # // 输入信息(必要参数)
- "perception": {
- # 文本信息
- "inputText": {
- # 问题
- "text": "北京未来七天,天气怎么样"
- }
- },
- # 用户必要信息
- "userInfo": {
- # 图灵机器人的apikey
- "apiKey": apiKey,
- # 用户唯一标识
- "userId": userId
- }
- }
- tuling_url = "http://openapi.tuling123.com/openapi/api/v2"
- res = requests.post(tuling_url,json=data) # 请求url
- # 将返回信息解码
- res_dic = json.loads(res.content.decode("utf-8")) # type:dict
- # 得到返回信息中的文本信息
- res_type = res_dic.get("results")[0].get("values").get("text")
- print(res_type)
执行输出:
- 北京:周二 09月11日,多云 南风微风,最低气温19度,最高气温26度
那么输出的文本,可以调用百度api,转换为音频文件,并自动播放!
修改 baidu_ai.py,封装函数text2audio
- import os
- from aip import AipSpeech
- from aip import AipNlp
- """ 你的 APPID AK SK """
- APP_ID = ''
- API_KEY = 'pVxdhsXS1BIaiwYYNT712345'
- SECRET_KEY = 'BvHQOts27LpGFbt3RAOv84WfPCW12345'
- client = AipSpeech(APP_ID, API_KEY, SECRET_KEY)
- nlp_client = AipNlp(APP_ID, API_KEY, SECRET_KEY)
- # 读取音频文件函数
- def get_file_content(filePath):
- cmd_str = "ffmpeg -y -i %s -acodec pcm_s16le -f s16le -ac 1 -ar 16000 %s.pcm"%(filePath,filePath)
- os.system(cmd_str) # 调用系统命令ffmpeg,传入音频文件名即可
- with open(filePath + ".pcm", 'rb') as fp:
- return fp.read()
- def text2audio(text): # 文本转换为音频
- ret = client.synthesis(text, 'zh', 1, {'spd': 4, 'vol': 5, 'pit': 8, 'per': 4})
- if not isinstance(ret, dict):
- with open('audio.mp3', 'wb') as f:
- f.write(ret)
- os.system("audio.mp3") # 打开系统默认的音频播放器
修改tuling.py,调用函数text2audio
- import requests
- import json
- import baidu_ai
- apiKey = "6a944508fd5c4d499b9991862ea12345"
- userId = "xiao" # 名字可以随意,必须是英文
- data = {
- # 请求的类型 0 文本 1 图片 2 音频
- "reqType": 0,
- # // 输入信息(必要参数)
- "perception": {
- # 文本信息
- "inputText": {
- # 问题
- "text": "北京未来七天,天气怎么样"
- }
- },
- # 用户必要信息
- "userInfo": {
- # 图灵机器人的apikey
- "apiKey": apiKey,
- # 用户唯一标识
- "userId": userId
- }
- }
- tuling_url = "http://openapi.tuling123.com/openapi/api/v2"
- res = requests.post(tuling_url,json=data) # 请求url
- # 将返回信息解码
- res_dic = json.loads(res.content.decode("utf-8")) # type:dict
- # 得到返回信息中的文本信息
- result = res_dic.get("results")[0].get("values").get("text")
- # print(res_type)
- baidu_ai.text2audio(result)
执行tuling.py,它会自动打开音频播放器,说: 北京:周二 09月11日,多云 南风微风,最低气温19度,最高气温26度
关于图灵机器人的参数说明,这里有一份别人整理好的
- 图灵机器人2.0
- POST: http://openapi.tuling123.com/openapi/api/v2
- 实现参数:
- {
- // 返回值类型 0 文本 1图片 2音频
- "reqType":0,
- // 输入信息(必要参数)
- "perception": {
- // 文本信息 三者非必填,但必有一填
- "inputText": {
- // 文本问题
- "text": "附近的酒店"
- },
- // 图片信息
- "inputImage": {
- // 提交图片地址
- "url": "imageUrl"
- },
- // 音频信息
- "inputMedia": {
- // 提交音频地址
- "url":"mediaUrl"
- }
- // 客户端属性(非必要)
- "selfInfo": {
- // 地理位置信息(非必要)
- "location": {
- // 城市
- "city": "北京",
- // 省份
- "province": "北京",
- // 街道
- "street": "信息路"
- }
- }
- },
- // 用户参数信息(原版的userid)
- "userInfo": {
- // apikey 应用的key
- "apiKey": "",
- // 用户唯一标志
- "userId": ""
- }
- }
- {
- // 请求意图
- "intent": {
- // 输出功能code
- "code": 10005,
- // 意图名称
- "intentName": "",
- // 意图动作名称
- "actionName": "",
- // 功能相关参数
- "parameters": {
- "nearby_place": "酒店"
- }
- },
- // 输出结果集
- "results": [
- {
- // 返回组 相同的 GroupType 为一组 0为独立
- "groupType": 1,
- // 返回值类型 : 文本(text);连接(url);音频(voice);视频(video);图片(image);图文(news)
- "resultType": "url",
- // 返回值
- "values": {
- "url": "http://m.elong.com/hotel/0101/nlist/#indate=2016-12-10&outdate=2016-12-11&keywords=%E4%BF%A1%E6%81%AF%E8%B7%AF
- "
- }
- },
- {
- // 此GroupType与 1 同组
- "groupType": 1,
- "resultType": "text",
- "values": {
- "text": "亲,已帮你找到相关酒店信息"
- }
- }
- ]
- }
或者参数官方API文档:
https://www.kancloud.cn/turing/www-tuling123-com/718227
接下来,还是使用前面的 whatyouname.m4a。
当问到 你的名字叫什么时?说出:我叫小青龙
当问到 其他问题时,由 图灵机器人回答
修改 baidu_ai.py
- from aip import AipSpeech
- import time, os
- from baidu_nlp import nlp_client
- import tuling
- """ 你的 APPID AK SK """
- APP_ID = ''
- API_KEY = 'pVxdhsXS1BIaiwYYNT712345'
- SECRET_KEY = 'BvHQOts27LpGFbt3RAOv84WfPCW12345'
- client = AipSpeech(APP_ID, API_KEY, SECRET_KEY)
- # nlp_client = AipNlp(APP_ID, API_KEY, SECRET_KEY)
- # 读取音频文件函数
- def get_file_content(filePath):
- cmd_str = "ffmpeg -y -i %s -acodec pcm_s16le -f s16le -ac 1 -ar 16000 %s.pcm"%(filePath,filePath)
- os.system(cmd_str) # 调用系统命令ffmpeg,传入音频文件名即可
- with open(filePath + ".pcm", 'rb') as fp:
- return fp.read()
- def text2audio(text): # 文本转换为音频
- ret = client.synthesis(text, 'zh', 1, {'spd': 4, 'vol': 5, 'pit': 8, 'per': 4})
- if not isinstance(ret, dict):
- with open('audio.mp3', 'wb') as f:
- f.write(ret)
- os.system("audio.mp3") # 打开系统默认的音频播放器
- # 识别本地文件
- def audio2text(file_path):
- a = client.asr(get_file_content(file_path), 'pcm', 16000, {
- 'dev_pid': 1536,
- })
- # print(a["result"])
- if a.get("result") :
- return a.get("result")[0]
- def my_nlp(q,uid):
- a = "我不知道你在说什么"
- if nlp_client.simnet(q,"你的名字叫什么").get("score") >= 0.7:
- a = "我叫小青龙"
- return a
- a = tuling.to_tuling(q,uid)
- return a
修改 baidu_nlp.py
- from aip import AipNlp
- APP_ID = ''
- API_KEY = 'pVxdhsXS1BIaiwYYNT712345'
- SECRET_KEY = 'BvHQOts27LpGFbt3RAOv84WfPCW12345'
- nlp_client = AipNlp(APP_ID,API_KEY,SECRET_KEY)
- """ 调用短文本相似度 """
- res = nlp_client.simnet("你叫什么名字","你的名字叫什么")
- print(res)
- # 如果相似度达到70%
- if res.get("score") > 0.7:
- print("我叫青龙")
修改tuling.py
- import requests
- import json
- apiKey = "6a944508fd5c4d499b9991862ea12345"
- userId = "xiao" # 名字可以随意,必须是英文
- data = {
- # 请求的类型 0 文本 1 图片 2 音频
- "reqType": 0,
- # // 输入信息(必要参数)
- "perception": {
- # 文本信息
- "inputText": {
- # 问题
- "text": "北京今天天气怎么样"
- }
- },
- # 用户必要信息
- "userInfo": {
- # 图灵机器人的apikey
- "apiKey": apiKey,
- # 用户唯一标识
- "userId": userId
- }
- }
- tuling_url = "http://openapi.tuling123.com/openapi/api/v2"
- def to_tuling(q,user_id):
- # 修改请求参数中的inputText,也就是问题
- data["perception"]["inputText"]["text"] = q
- # 修改userInfo
- data["userInfo"]["userId"] = user_id
- res = requests.post(tuling_url,json=data) # 请求url
- # 将返回信息解码
- res_dic = json.loads(res.content.decode("utf-8")) # type:dict
- # 得到返回信息中的文本信息
- result = res_dic.get("results")[0].get("values").get("text")
- # print(res_type)
- return result
创建main.py
- import baidu_ai
- uid = 1234
- file_name = "whatyouname.m4a"
- q = baidu_ai.audio2text(file_name)
- # print(q,'qqqqqqqqqq')
- a = baidu_ai.my_nlp(q,uid)
- # print(a,'aaaaaaaaa')
- baidu_ai.text2audio(a)
执行main.py,执行之后,会打开音频,说: 我叫小青龙
修改 baidu_ai.py,注释掉问题:你的名字叫什么
- from aip import AipSpeech
- import time, os
- from baidu_nlp import nlp_client
- import tuling
- """ 你的 APPID AK SK """
- APP_ID = ''
- API_KEY = 'pVxdhsXS1BIaiwYYNT712345'
- SECRET_KEY = 'BvHQOts27LpGFbt3RAOv84WfPCW12345'
- client = AipSpeech(APP_ID, API_KEY, SECRET_KEY)
- # nlp_client = AipNlp(APP_ID, API_KEY, SECRET_KEY)
- # 读取音频文件函数
- def get_file_content(filePath):
- cmd_str = "ffmpeg -y -i %s -acodec pcm_s16le -f s16le -ac 1 -ar 16000 %s.pcm"%(filePath,filePath)
- os.system(cmd_str) # 调用系统命令ffmpeg,传入音频文件名即可
- with open(filePath + ".pcm", 'rb') as fp:
- return fp.read()
- def text2audio(text): # 文本转换为音频
- ret = client.synthesis(text, 'zh', 1, {'spd': 4, 'vol': 5, 'pit': 8, 'per': 4})
- if not isinstance(ret, dict):
- with open('audio.mp3', 'wb') as f:
- f.write(ret)
- os.system("audio.mp3") # 打开系统默认的音频播放器
- # 识别本地文件
- def audio2text(file_path):
- a = client.asr(get_file_content(file_path), 'pcm', 16000, {
- 'dev_pid': 1536,
- })
- # print(a["result"])
- if a.get("result") :
- return a.get("result")[0]
- def my_nlp(q,uid):
- # a = "我不知道你在说什么"
- # if nlp_client.simnet(q,"你的名字叫什么").get("score") >= 0.7:
- # a = "我叫小青龙"
- # return a
- a = tuling.to_tuling(q,uid)
- return a
再次执行main.py,执行之后,会打开音频,说:叫我图灵机器人就可以了!
这样很麻烦,每次问问题,都要录制一段音频才可以!
接下来介绍使用web录音,实现自动化交互问答
二、web录音实现自动化交互问答
werkzeug
首先,先向大家介绍一下什么是 werkzeug,Werkzeug是一个WSGI工具包,他可以作为一个Web框架的底层库。这里稍微说一下, werkzeug 不是一个web服务器,也不是一个web框架,而是一个工具包,官方的介绍说是一个 WSGI 工具包,它可以作为一个 Web 框架的底层库,因为它封装好了很多 Web 框架的东西,例如 Request,Response 等等。
例如我最常用的 Flask 框架就是一 Werkzeug 为基础开发的,它只能处理HTTP请求
WebSocket
WebSocket 是一种网络通信协议。RFC6455 定义了它的通信标准。
WebSocket 是 HTML5 开始提供的一种在单个 TCP 连接上进行全双工通讯的协议。
为什么不用werkzeug
HTTP 协议是一种无状态的、无连接的、单向的应用层协议。HTTP 协议无法实现服务器主动向客户端发起消息!
WebSockets 是长连接(连接长期存在),Web浏览器和服务器都必须实现 WebSockets 协议来建立和维护连接
这里使用flask作为后端程序,使用websocket来接收前端发送的音频。因为不知道用户啥时候发起录音!
正式开始
新建一个文件夹web_ai
创建文件ai.py,使用websocket监听!
- from flask import Flask,request,render_template,send_file
- from geventwebsocket.handler import WebSocketHandler
- from gevent.pywsgi import WSGIServer
- from geventwebsocket.websocket import WebSocket
- app = Flask(__name__)
- @app.route("/index")
- def index():
- # 获取请求的WebSocket对象
- user_socket = request.environ.get("wsgi.websocket") # type:WebSocket
- print(user_socket)
- print(request.remote_addr) # 远程ip地址
- while True:
- # 接收消息
- msg = user_socket.receive()
- print(msg)
- @app.route("/")
- def home_page():
- return render_template("index.html")
- if __name__ == '__main__':
- # 创建一个WebSocket服务器
- http_serv = WSGIServer(("0.0.0.0",5000),app,handler_class=WebSocketHandler)
- # 开始监听HTTP请求
- http_serv.serve_forever()
创建目录templates,在此目录下,新建文件index.html,创建 WebSocket 对象
- <!DOCTYPE html>
- <html lang="en">
- <head>
- <meta charset="UTF-8">
- <title>Title</title>
- </head>
- <body>
- </body>
- <script type="application/javascript">
- //创建 WebSocket 对象
- var ws = new WebSocket("ws://127.0.0.1:5000/index");
- </script>
- </html>
启动flask,访问首页:

注意:此时页面是空白的,不要惊讶!
查看Pycharm控制台输出:
- <geventwebsocket.websocket.WebSocket object at 0x000002EA6A3F39A0>
- 127.0.0.1
那么网页如何发送音频给后端呢?使用Recorder.js
Recorder
Recorder.js是HTML5录音插件,它可以实现在线录音。
它不支持ie,不支持Safari 其他ok,但是部分版本有点小要求
Chrome47以上以及QQ浏览器需要HTTPS的支持。注意:公网访问时,网页必须是HTTPS方式,否则无法录音!
github下载地址为:
https://github.com/mattdiamond/Recorderjs
关于html5 Audio常用属性和函数事件,请参考链接:
https://blog.csdn.net/bright2017/article/details/80041448
下载之后,解压文件。进入dict目录,将recorder.js复制到桌面上!
打开flask项目web_ai,进入目录static,将recorder.js移动到此目录
项目结构如下:
- ./
- ├── ai.py
- ├── static
- │ └── recorder.js
- └── templates
- └── index.html
录制声音
修改index.html,导入recorder.js
- <!DOCTYPE html>
- <html lang="en">
- <head>
- <meta charset="UTF-8">
- <title>Title</title>
- </head>
- <body>
- {#audio是HTML5的标签,autoplay表示自动播放,controls表示展示组件#}
- <audio src="" autoplay controls id="player"></audio>
- <br>
- <button onclick="start_reco()">开始废话</button>
- <br>
- <button onclick="stop_reco()">发送语音</button>
- </body>
- <script src="/static/recorder.js"></script>
- <script type="application/javascript">
- // 创建WebSocket对象
- var ws = new WebSocket("ws://127.0.0.1:5000/index");
- var reco = null; //录音对象
- // 创建AudioContext对象
- // AudioContext() 构造方法创建了一个新的 AudioContext 对象 它代表了一个由音频模块链接而成的音频处理图, 每一个模块由 AudioNode 表示
- var audio_context = new AudioContext();
- //要获取音频和视频,需要用到getUserMedia。桌面平台支持的浏览器包括Chrome, Firefox, Opera和Edge。
- // 这里的|| 表示或者的关系,也就是能支持的浏览器
- navigator.getUserMedia = (navigator.getUserMedia ||
- navigator.webkitGetUserMedia ||
- navigator.mozGetUserMedia ||
- navigator.msGetUserMedia);
- // 拿到媒体对象,允许音频对象
- navigator.getUserMedia({audio: true}, create_stream, function (err) {
- console.log(err)
- });
- //创建媒体流容器
- function create_stream(user_media) {
- //AudioContext接口的createMediaStreamSource()方法用于创建一个新的MediaStreamAudioSourceNode 对象,
- // 需要传入一个媒体流对象(MediaStream对象)(可以从 navigator.getUserMedia 获得MediaStream对象实例),
- // 然后来自MediaStream的音频就可以被播放和操作。
- // MediaStreamAudioSourceNode 接口代表一个音频接口,是WebRTC MediaStream (比如一个摄像头或者麦克风)的一部分。
- // 是个表现为音频源的AudioNode。
- var stream_input = audio_context.createMediaStreamSource(user_media);
- // 给Recoder 创建一个空间,麦克风说的话,都可以录入。是一个流
- reco = new Recorder(stream_input);
- }
- function start_reco() { //开始录音
- reco.record(); //往里面写流
- }
- function stop_reco() { //停止录音
- reco.stop(); //停止写入流
- get_audio(); //调用自定义方法
- reco.clear(); //清空容器
- }
- // 获取音频
- function get_audio() {
- reco.exportWAV(function (wav_file) {
- // 发送数据给后端
- ws.send(wav_file);
- })
- }
- </script>
- </html>
重启flask,访问网页,效果如下:
点击允许麦克风
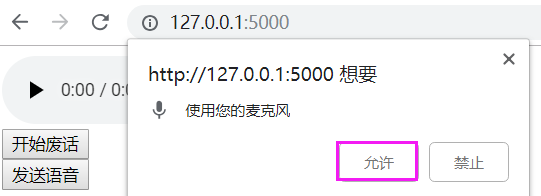
点击开始废话,说一段话,再点击停止!
查看Pycharm控制台输出:
- <geventwebsocket.websocket.WebSocket object at 0x000002515BFE3C10>
- 127.0.0.1
- bytearray(b'RIFF$\x00\x04\x00WAVEfmt...\x10')
它返回一个bytearray数据,这些都是流数据,它可以保存为音频文件
修改ai.py,判断类型为bytearray,写入文件
- from flask import Flask,request,render_template,send_file
- from geventwebsocket.handler import WebSocketHandler
- from gevent.pywsgi import WSGIServer
- from geventwebsocket.websocket import WebSocket
- app = Flask(__name__)
- @app.route("/index")
- def index():
- # 获取请求的WebSocket对象
- user_socket = request.environ.get("wsgi.websocket") # type:WebSocket
- print(user_socket)
- print(request.remote_addr) # 远程ip地址
- while True:
- # 接收消息
- msg = user_socket.receive()
- if type(msg) == bytearray:
- # 写入文件123.wav
- with open("123.wav", "wb") as f:
- f.write(msg)
- @app.route("/")
- def home_page():
- return render_template("index.html")
- if __name__ == '__main__':
- # 创建一个WebSocket服务器
- http_serv = WSGIServer(("0.0.0.0",5000),app,handler_class=WebSocketHandler)
- # 开始监听HTTP请求
- http_serv.serve_forever()
重启flask,重新录制一段声音。就会发现项目目录,多了一个文件123.wav
打开这文件,播放一下,就是刚刚录制的声音!
获取文件名
将上一篇写的baidu_ai.py和tuling.py复制过来。
修改 baidu_ai.py,修改text2audio函数,返回文件名
- from aip import AipSpeech
- import time, os
- # from baidu_nlp import nlp_client
- import tuling
- """ 你的 APPID AK SK """
- APP_ID = ''
- API_KEY = 'pVxdhsXS1BIaiwYYNT712345'
- SECRET_KEY = 'BvHQOts27LpGFbt3RAOv84WfPCW12345'
- client = AipSpeech(APP_ID, API_KEY, SECRET_KEY)
- # nlp_client = AipNlp(APP_ID, API_KEY, SECRET_KEY)
- # 读取音频文件函数
- def get_file_content(filePath):
- cmd_str = "ffmpeg -y -i %s -acodec pcm_s16le -f s16le -ac 1 -ar 16000 %s.pcm"%(filePath,filePath)
- os.system(cmd_str) # 调用系统命令ffmpeg,传入音频文件名即可
- with open(filePath + ".pcm", 'rb') as fp:
- return fp.read()
- def text2audio(text): # 文本转换为音频
- ret = client.synthesis(text, 'zh', 1, {'spd': 4, 'vol': 5, 'pit': 8, 'per': 4})
- if not isinstance(ret, dict):
- with open('audio.mp3', 'wb') as f:
- f.write(ret)
- # os.system("audio.mp3") # 打开系统默认的音频播放器
- return 'audio.mp3'
- # 识别本地文件
- def audio2text(file_path):
- a = client.asr(get_file_content(file_path), 'pcm', 16000, {
- 'dev_pid': 1536,
- })
- # print(a["result"])
- if a.get("result") :
- return a.get("result")[0]
- def my_nlp(q,uid):
- # a = "我不知道你在说什么"
- # if nlp_client.simnet(q,"你的名字叫什么").get("score") >= 0.7:
- # a = "我叫小青龙"
- # return a
- a = tuling.to_tuling(q,uid)
- return a
修改 tuling.py
- #!/usr/bin/env python
- # -*- coding: utf-8 -*-
- import requests
- import json
- apiKey = "6a944508fd5c4d499b9991862ea12345"
- userId = "xiao" # 名字可以随意,必须是英文
- data = {
- # 请求的类型 0 文本 1 图片 2 音频
- "reqType": 0,
- # // 输入信息(必要参数)
- "perception": {
- # 文本信息
- "inputText": {
- # 问题
- "text": "北京今天天气怎么样"
- }
- },
- # 用户必要信息
- "userInfo": {
- # 图灵机器人的apikey
- "apiKey": apiKey,
- # 用户唯一标识
- "userId": userId
- }
- }
- tuling_url = "http://openapi.tuling123.com/openapi/api/v2"
- def to_tuling(q,user_id):
- # 修改请求参数中的inputText,也就是问题
- data["perception"]["inputText"]["text"] = q
- # 修改userInfo
- data["userInfo"]["userId"] = user_id
- res = requests.post(tuling_url,json=data) # 请求url
- # 将返回信息解码
- res_dic = json.loads(res.content.decode("utf-8")) # type:dict
- # 得到返回信息中的文本信息
- result = res_dic.get("results")[0].get("values").get("text")
- # print(res_type)
- return result
修改ai.py,导入模块baidu_ai
- from flask import Flask,request,render_template,send_file
- from geventwebsocket.handler import WebSocketHandler
- from gevent.pywsgi import WSGIServer
- from geventwebsocket.websocket import WebSocket
- import baidu_ai
- app = Flask(__name__)
- @app.route("/index/<uid>")
- def index(uid): # 接收uid
- # 获取请求的WebSocket对象
- user_socket = request.environ.get("wsgi.websocket") # type:WebSocket
- print(user_socket)
- # print(request.remote_addr) # 远程ip地址
- while True:
- # 接收消息
- msg = user_socket.receive()
- if type(msg) == bytearray:
- # 写入文件123.wav
- with open("123.wav", "wb") as f:
- f.write(msg)
- # 将音频文件转换为文字
- res_q = baidu_ai.audio2text("123.wav")
- # 调用my_nlp函数,内部调用图灵机器人
- res_a = baidu_ai.my_nlp(res_q, uid)
- # 将文字转换为音频文件
- file_name = baidu_ai.text2audio(res_a)
- # 发送文件名给前端
- user_socket.send(file_name)
- @app.route("/")
- def home_page():
- return render_template("index.html")
- @app.route("/get_file/<file_name>") # 获取音频文件
- def get_file(file_name): # 此方法用于前端调取后端的音频文件,用于自动播放
- return send_file(file_name)
- if __name__ == '__main__':
- # 创建一个WebSocket服务器
- http_serv = WSGIServer(("0.0.0.0",5000),app,handler_class=WebSocketHandler)
- # 开始监听HTTP请求
- http_serv.serve_forever()
修改index.html,定义ws.onmessage,打印文件名
- <!DOCTYPE html>
- <html lang="en">
- <head>
- <meta charset="UTF-8">
- <title>Title</title>
- </head>
- <body>
- {#audio是HTML5的标签,autoplay表示自动播放,controls表示展示组件#}
- <audio src="" autoplay controls id="player"></audio>
- <br>
- <button onclick="start_reco()">开始废话</button>
- <br>
- <button onclick="stop_reco()">发送语音</button>
- </body>
- <script src="/static/recorder.js"></script>
- <script type="application/javascript">
- // 创建WebSocket对象,index后面的是userid,是图灵机器人需要的
- var ws = new WebSocket("ws://127.0.0.1:5000/index/xiao");
- var reco = null; //录音对象
- // 创建AudioContext对象
- // AudioContext() 构造方法创建了一个新的 AudioContext 对象 它代表了一个由音频模块链接而成的音频处理图, 每一个模块由 AudioNode 表示
- var audio_context = new AudioContext();
- //要获取音频和视频,需要用到getUserMedia。桌面平台支持的浏览器包括Chrome, Firefox, Opera和Edge。
- // 这里的|| 表示或者的关系,也就是能支持的浏览器
- navigator.getUserMedia = (navigator.getUserMedia ||
- navigator.webkitGetUserMedia ||
- navigator.mozGetUserMedia ||
- navigator.msGetUserMedia);
- // 拿到媒体对象,允许音频对象
- navigator.getUserMedia({audio: true}, create_stream, function (err) {
- console.log(err)
- });
- //创建媒体流容器
- function create_stream(user_media) {
- //AudioContext接口的createMediaStreamSource()方法用于创建一个新的MediaStreamAudioSourceNode 对象,
- // 需要传入一个媒体流对象(MediaStream对象)(可以从 navigator.getUserMedia 获得MediaStream对象实例),
- // 然后来自MediaStream的音频就可以被播放和操作。
- // MediaStreamAudioSourceNode 接口代表一个音频接口,是WebRTC MediaStream (比如一个摄像头或者麦克风)的一部分。
- // 是个表现为音频源的AudioNode。
- var stream_input = audio_context.createMediaStreamSource(user_media);
- // 给Recoder 创建一个空间,麦克风说的话,都可以录入。是一个流
- reco = new Recorder(stream_input);
- }
- function start_reco() { //开始录音
- reco.record(); //往里面写流
- }
- function stop_reco() { //停止录音
- reco.stop(); //停止写入流
- get_audio(); //调用自定义方法
- reco.clear(); //清空容器
- }
- // 获取音频
- function get_audio() {
- reco.exportWAV(function (wav_file) {
- // 发送数据给后端
- ws.send(wav_file);
- })
- }
- // 接收到服务端数据时触发
- ws.onmessage = function (data) {
- console.log(data.data); //打印文件名
- }
- </script>
- </html>
重启flask,访问网页,重新录制一段声音
查看Pycharm控制台输出:
- encoder : Lavc58.19.102 pcm_s16le
- size= 35kB time=00:00:01.10 bitrate= 256.0kbits/s speed=42.6x
- video:0kB audio:35kB subtitle:0kB other streams:0kB global headers:0kB muxing overhead: 0.000000%
它正在将文字转换为音频文件,并返回音频的文件名
上面执行完成之后,网页的console,就会返回文件名
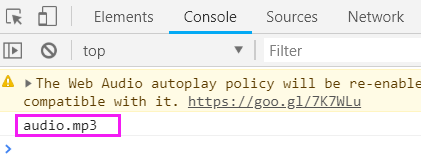
这个文件名,就是text2audio函数返回的。
自动播放
那么页面如何自动播放这个audio.mp3文件呢?
只要修改网页id为player的src属性就可以了,路径必须是可以访问的!
修改index.html
- <!DOCTYPE html>
- <html lang="en">
- <head>
- <meta charset="UTF-8">
- <title>Title</title>
- </head>
- <body>
- {#audio是HTML5的标签,autoplay表示自动播放,controls表示展示组件#}
- <audio src="" autoplay controls id="player"></audio>
- <br>
- <button onclick="start_reco()">开始废话</button>
- <br>
- <button onclick="stop_reco()">发送语音</button>
- </body>
- <script src="/static/recorder.js"></script>
- <script type="application/javascript">
- // 访问后端的get_file,得到一个文件名
- var get_file = "http://127.0.0.1:5000/get_file/";
- // 创建WebSocket对象,index后面的是userid,是图灵机器人需要的
- var ws = new WebSocket("ws://127.0.0.1:5000/index/xiao");
- var reco = null; //录音对象
- // 创建AudioContext对象
- // AudioContext() 构造方法创建了一个新的 AudioContext 对象 它代表了一个由音频模块链接而成的音频处理图, 每一个模块由 AudioNode 表示
- var audio_context = new AudioContext();
- //要获取音频和视频,需要用到getUserMedia。桌面平台支持的浏览器包括Chrome, Firefox, Opera和Edge。
- // 这里的|| 表示或者的关系,也就是能支持的浏览器
- navigator.getUserMedia = (navigator.getUserMedia ||
- navigator.webkitGetUserMedia ||
- navigator.mozGetUserMedia ||
- navigator.msGetUserMedia);
- // 拿到媒体对象,允许音频对象
- navigator.getUserMedia({audio: true}, create_stream, function (err) {
- console.log(err)
- });
- //创建媒体流容器
- function create_stream(user_media) {
- //AudioContext接口的createMediaStreamSource()方法用于创建一个新的MediaStreamAudioSourceNode 对象,
- // 需要传入一个媒体流对象(MediaStream对象)(可以从 navigator.getUserMedia 获得MediaStream对象实例),
- // 然后来自MediaStream的音频就可以被播放和操作。
- // MediaStreamAudioSourceNode 接口代表一个音频接口,是WebRTC MediaStream (比如一个摄像头或者麦克风)的一部分。
- // 是个表现为音频源的AudioNode。
- var stream_input = audio_context.createMediaStreamSource(user_media);
- // 给Recoder 创建一个空间,麦克风说的话,都可以录入。是一个流
- reco = new Recorder(stream_input);
- }
- function start_reco() { //开始录音
- reco.record(); //往里面写流
- }
- function stop_reco() { //停止录音
- reco.stop(); //停止写入流
- get_audio(); //调用自定义方法
- reco.clear(); //清空容器
- }
- // 获取音频
- function get_audio() {
- reco.exportWAV(function (wav_file) {
- // 发送数据给后端
- ws.send(wav_file);
- })
- }
- // 接收到服务端数据时触发
- ws.onmessage = function (data) {
- // console.log(data.data);
- console.log(get_file + data.data); //打印文件名
- // 修改id为player的src属性,
- document.getElementById("player").src = get_file + data.data;
- }
- </script>
- </html>
重启flask,刷新网页。重新录制一段声音,说:你叫什么名字?
效果如下:
网页说:在下江湖人称,图灵机器人
声音很萌,附上图片

这只是针对于网页的,那么手机端如何实现呢?
也是同样的打开网页,或者内嵌API。
手机由于输入一段URL访问,非常麻烦。一般采用二维码

这是我做的图灵聊天机器人,注意:只能微信和手机QQ,因为这些APP能调用麦克风
前端使用 recorder.js+ajax
后端使用 flask,调用百度语言识别API+图灵机器人API
python 全栈开发,Day123(图灵机器人,web录音实现自动化交互问答)的更多相关文章
- 图灵机器人,web录音实现自动化交互问答
一.图灵机器人 介绍 图灵机器人 是以语义技术为核心驱动力的人工智能公司,致力于“让机器理解世界”,产品服务包括机器人开放平台.机器人OS和场景方案. 官方地址为: http://www.tuling ...
- python 全栈开发,Day99(作业讲解,DRF版本,DRF分页,DRF序列化进阶)
昨日内容回顾 1. 为什么要做前后端分离? - 前后端交给不同的人来编写,职责划分明确. - API (IOS,安卓,PC,微信小程序...) - vue.js等框架编写前端时,会比之前写jQuery ...
- 学习笔记之Python全栈开发/人工智能公开课_腾讯课堂
Python全栈开发/人工智能公开课_腾讯课堂 https://ke.qq.com/course/190378 https://github.com/haoran119/ke.qq.com.pytho ...
- Python全栈开发【面向对象】
Python全栈开发[面向对象] 本节内容: 三大编程范式 面向对象设计与面向对象编程 类和对象 静态属性.类方法.静态方法 类组合 继承 多态 封装 三大编程范式 三大编程范式: 1.面向过程编程 ...
- Win10构建Python全栈开发环境With WSL
目录 Win10构建Python全栈开发环境With WSL 启动WSL 总结 对<Dev on Windows with WSL>的补充 Win10构建Python全栈开发环境With ...
- python全栈开发中级班全程笔记(第二模块、第四章)(常用模块导入)
python全栈开发笔记第二模块 第四章 :常用模块(第二部分) 一.os 模块的 详解 1.os.getcwd() :得到当前工作目录,即当前python解释器所在目录路径 impor ...
- python全栈开发目录
python全栈开发目录 Linux系列 python基础 前端~HTML~CSS~JavaScript~JQuery~Vue web框架们~Django~Flask~Tornado 数据库们~MyS ...
- Python全栈开发相关课程
Python全栈开发 Python入门 Python安装 Pycharm安装.激活.使用 Python基础 Python语法 Python数据类型 Python进阶 面向对象 网络编程 并发编程 数据 ...
- Python 全栈开发【第0篇】:目录
Python 全栈开发[第0篇]:目录 第一阶段:Python 开发入门 Python 全栈开发[第一篇]:计算机原理&Linux系统入门 Python 全栈开发[第二篇]:Python基 ...
随机推荐
- 启动eclipse弹出提示Version 1.7.0_79 of the JVM is not suitable for this product. Version: 1.8 or greater is required怎样解决
启动eclipse时弹出如下弹出框: 解决办法: 在eclipse安装目录下找到eclipse.ini文件,并在 -vmargs-Dosgi.requiredJavaVersion=1.8 前面加上 ...
- SqlServer中的查询简单总结
一.sql语句的执行顺序 查询时数据库中使用最多的操作,一条sql语句的查询顺序是 1.from Tb1 [ join on ] 得到查询的数据源 2.where 对数据过滤(单条数据上过滤 ...
- Java 编程下使用 Class.forName() 加载类【转】
在一些应用中,无法事先知道使用者将加载什么类,而必须让使用者指定类名称以加载类,可以使用 Class 的静态 forName() 方法实现动态加载类.下面的范例让你可以指定类名称来获得类的相关信息. ...
- Windows环境墙内搭建Go语言集成开发环境
1 安装go环境 太简单略 2 安装vs code 找到微软的官方网站,下载Visual Studio Code,官网地址https://code.visualstudio.com/ 安装完成后进入V ...
- 获取客户端的请求IP地址
获取客户端的请求IP地址 package com.microClass.util; import javax.servlet.http.HttpServletRequest; import java. ...
- Varish 缓存
varish 缓存 2013年06月17日,Varnish Cache 3.0.4 发布,为目前最新版本. varish是以内存作为共享容器的:内存的大小决定了它的缓存容量.相对于主要以硬盘为存储的s ...
- [CQOI2011]放棋子 (DP,数论)
[CQOI2011]放棋子 \(solution:\) 看到这道题我们首先就应该想到有可能是DP和数论,因为题目已经很有特性了(首先题面是放棋子)(然后这一题方案数很多要取模)(而且这一题的数据范围很 ...
- mysql原理~undo
mysql undo详谈1 简介:undo是MVCC机制的基础部分之一2 作用:为了实现可重复性读,存储历史数据3 存储:5.6以前undo都存储在内存和ibdata1中,5.6以后undo可以独立成 ...
- 20165230田坤烨《网络对抗》Exp1 PC平台逆向破解
实践目标 本次实践的对象是一个名为pwn1的linux可执行文件. 该程序正常执行流程是:main调用foo函数,foo函数会简单回显任何用户输入的字符串. 该程序同时包含另一个代码片段,getShe ...
- JS执行一次任务与定期任务与清除执行
1.一次性任务的执行与清除执行 1.定期执行 <script> timer = 0; timer = setTimeout(function() { console.log("s ...