原来CNN是这样提取图像特征的。。。
对于即将到来的人工智能时代,作为一个有理想有追求的程序员,不懂深度学习(Deep Learning)这个超热的领域,会不会感觉马上就out了?作为机器学习的一个分支,深度学习同样需要计算机获得强大的学习能力,那么问题来了,我们究竟要计算机学习什么东西?答案当然是图像特征了。将一张图像看做是一个个像素值组成的矩阵,那么对图像的分析就是对矩阵的数字进行分析,而图像的特征,就隐藏在这些数字规律中。
深度学习对外推荐自己的一个很重要的点——深度学习能够自动提取特征。本文主要介绍卷积层提取特征的原理过程,文章通过几个简单的例子,展示卷积层是如何工作的,以及概述了反向传播的过程,将让你对卷积神经网络CNN提取图像特征有一个透彻的理解。那么我们首先从最基本的数学计算——卷积操作开始。
1.卷积操作
假设有一个55的图像,使用一个33的卷积核(filter)进行卷积,得到一个3*3的矩阵(其实是Feature Map,后面会讲),如下所示:
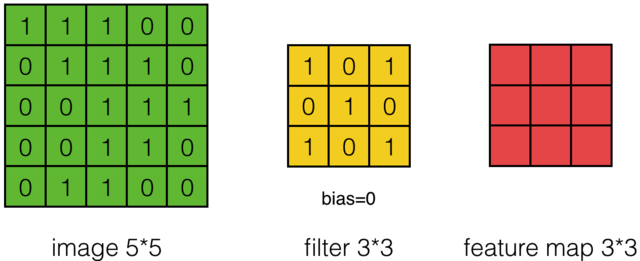
下面的动图清楚地展示了如何进行卷积操作(其实就是简单的点乘运算):
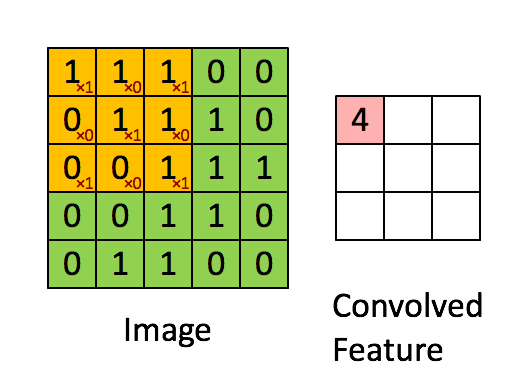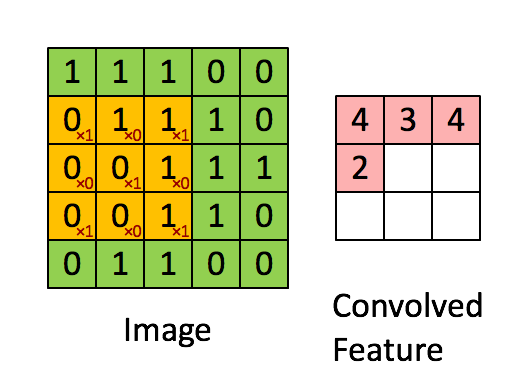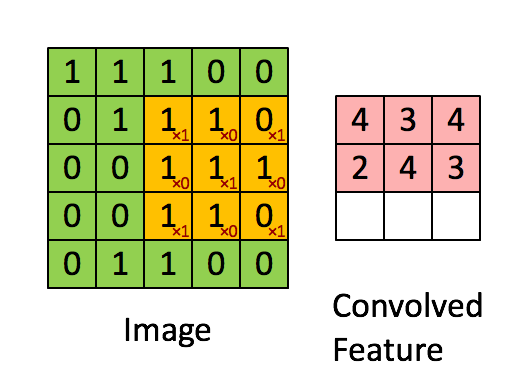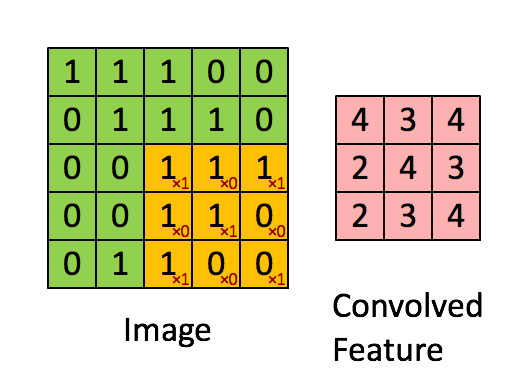

一个图像矩阵经过一个卷积核的卷积操作后,得到了另一个矩阵,这个矩阵叫做特征映射(feature map)。每一个卷积核都可以提取特定的特征,不同的卷积核提取不同的特征,举个例子,现在我们输入一张人脸的图像,使用某一卷积核提取到眼睛的特征,用另一个卷积核提取嘴巴的特征等等。而特征映射就是某张图像经过卷积运算得到的特征值矩阵。
讲到这里,可能大家还不清楚卷积核和特征映射到底是个什么东西,有什么用?没关系,毕竟理解了CNN 的卷积层如何运算,并不能自动给我们关于 CNN 卷积层原理的洞见。为了帮助指导你理解卷积神经网络的特征提取,我们将采用一个非常简化的例子。
2.特征提取—“X” or “O”?
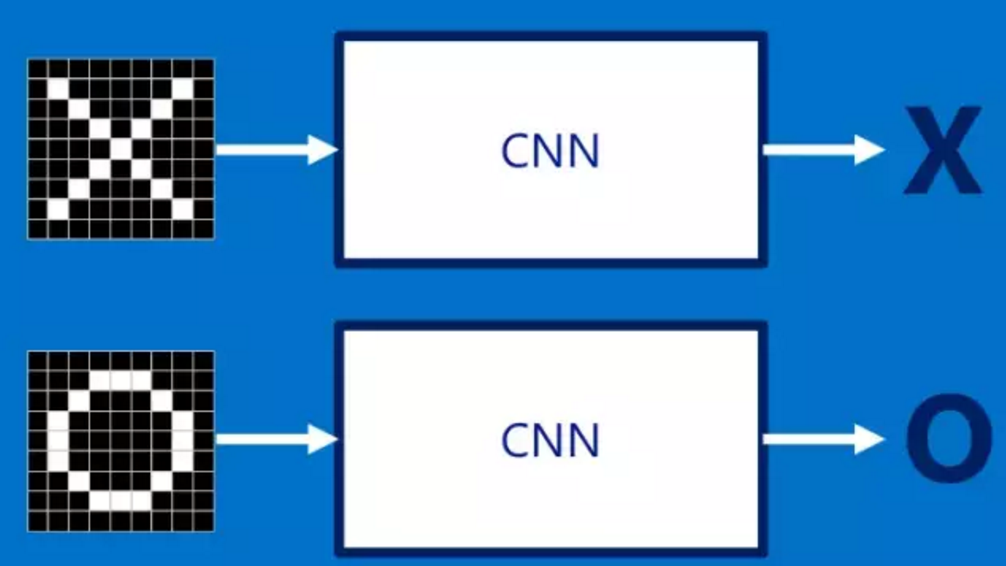
在CNN中有这样一个问题,就是每次给你一张图,你需要判断它是否含有"X"或者"O"。并且假设必须两者选其一,不是"X"就是"O"。理想的情况就像下面这个样子:
那么如果图像如果经过变形、旋转等简单操作后,如何识别呢?这就好比老师教你1+1等于2,让你独立计算1+2等于几是一个道理,就像下面这些情况,我们同样希望计算机依然能够很快并且很准的识别出来:
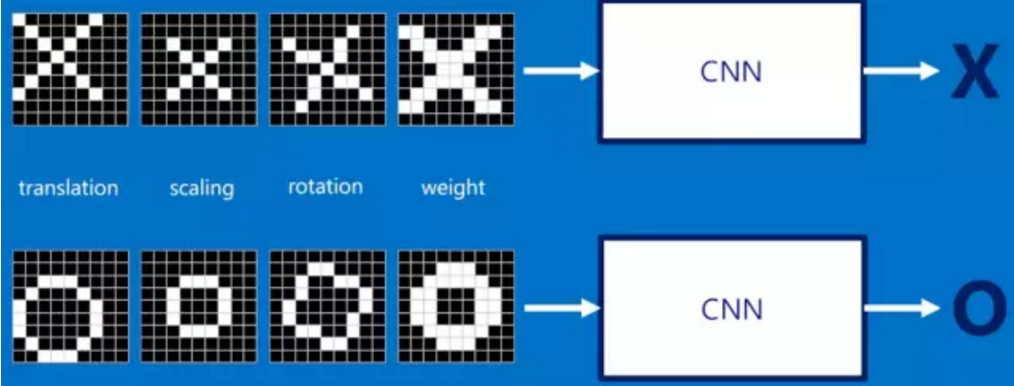
这也就是CNN出现所要解决的问题。
如下图所示,像素值"1"代表白色,像素值"-1"代表黑色。对于CNN来说,它是一块一块地来进行比对。它拿来比对的这个“小块”我们称之为Features(特征)。在两幅图中大致相同的位置找到一些粗糙的特征进行匹配,CNN能够更好的看到两幅图的相似性。
对于字母"X"的例子中,那些由对角线和交叉线组成的features基本上能够识别出大多数"X"所具有的重要特征。
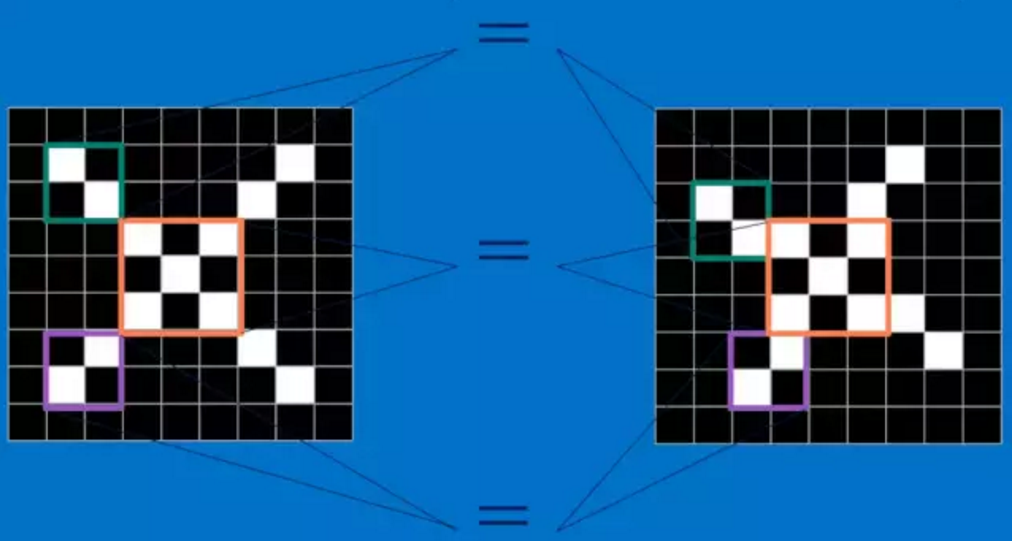
这些features很有可能就是匹配任何含有字母"X"的图中字母X的四个角和它的中心。那么具体到底是怎么匹配的呢?如下三个特征矩阵a,b,c:

观察下面几张图,a可以匹配到“X”的左上角和右下角,b可以匹配到中间交叉部位,而c可以匹配到“X”的右上角和左上角。

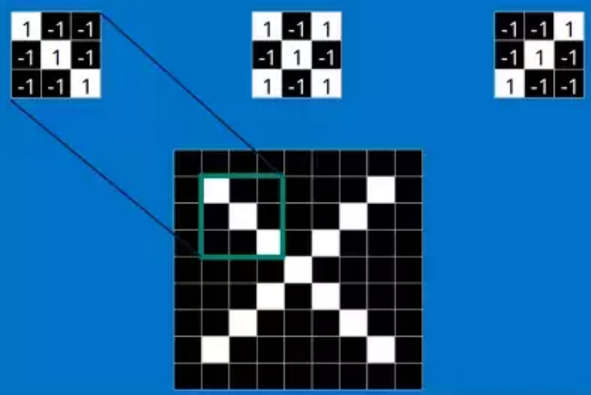
把上面三个小矩阵作为卷积核,就如第一部分结尾介绍的,每一个卷积核可以提取特定的特征,现在给一张新的包含“X”的图像,CNN并不能准确地知道这些features到底要匹配原图的哪些部分,所以它会在原图中每一个可能的位置进行尝试,即使用该卷积核在图像上进行滑动,每滑动一次就进行一次卷积操作,得到一个特征值。仔细想想,是否有一点头目呢?
(下图中求平均是为了让所有特征值回归到-1到1之间)

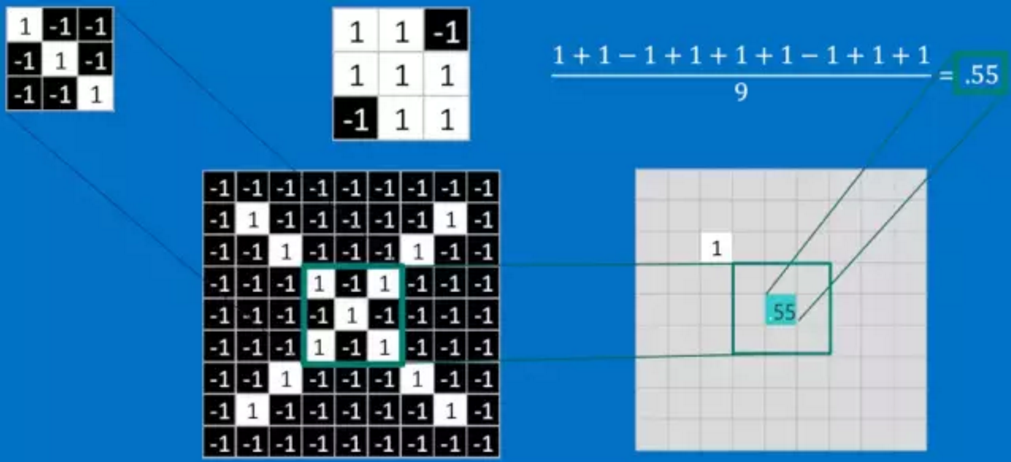
最后将整张图卷积过后,得到这样的特征矩阵:

使用全部卷积核卷积过后,得到的结果是这样的:

仔细观察,可以发现,其中的值,越接近为1表示对应位置和卷积核代表的特征越接近,越是接近-1,表示对应位置和卷积核代表的反向特征越匹配,而值接近0的表示对应位置没有任何匹配或者说没有什么关联。
那么最后得到的特征矩阵就叫做feature map特征映射,通过特定的卷积核得到其对应的feature map。在CNN中,我们称之为卷积层(convolution layer),卷积核在图像上不断滑动运算,就是卷积层所要做的事情。同时,在内积结果上取每一局部块的最大值就是最大池化层的操作。CNN 用卷积层和池化层实现了图片特征提取方法。
3.反向传播算法BP
通过上面的学习,我们知道CNN是如何利用卷积层和池化层提取图片的特征,其中的关键是卷积核表示图片中的局部特征。
而在现实中,使用卷积神经网络进行多分类获目标检测的时候,图像构成要比上面的X和O要复杂得多,我们并不知道哪个局部特征是有效的,即使我们选定局部特征,也会因为太过具体而失去反泛化性。还以人脸为例,我们使用一个卷积核检测眼睛位置,但是不同的人,眼睛大小、状态是不同的,如果卷积核太过具体化,卷积核代表一个睁开的眼睛特征,那如果一个图像中的眼睛是闭合的,就很大可能检测不出来,那么我们怎么应对这中问题呢,即如何确定卷积核的值呢?
这就引出了反向传播算法。什么是反向传播,以猜数字为例,B手中有一张数字牌让A猜,首先A将随意给出一个数字,B反馈给A是大了还是小了,然后A经过修改,再次给出一个数字,B再反馈给A是否正确以及大小关系,经过数次猜测和反馈,最后得到正确答案(当然,在实际的CNN中不可能存在百分之百的正确,只能是最大可能正确)。
所以反向传播,就是对比预测值和真实值,继而返回去修改网络参数的过程,一开始我们随机初始化卷积核的参数,然后以误差为指导通过反向传播算法,自适应地调整卷积核的值,从而最小化模型预测值和真实值之间的误差。
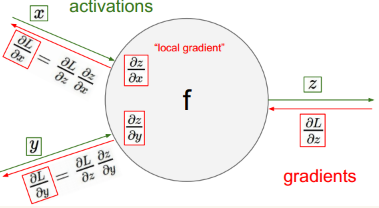
举一个简单例子。绿色箭头代表前向传播,红色代表为反向传播过程,x、y是权重参数,L为误差,L对x、y的导数表示误差L的变化对x、y的影响程度,得到偏导数delta(x)后,x* = x-η*delta(x),其中η为学习率,从而实现权重的更新。
在此放一个简单的反向传播代码,python版本,结合代码理解BP思想。
链接:https://pan.baidu.com/s/1WNm-rKO1exYKu2IiGtfBKw 提取码: hwsu
4.总结
本文主要讲解基本CNN的原理过程,卷积层和池化层可以提取图像特征,经过反向传播最终确定卷积核参数,得到最终的特征,这就是一个大致的CNN提取特征的过程。考虑到反向传播计算的复杂性,在本文中不做重点讲解,先作为了解思路,日后专门再讲解反向传播的方法原理。
我们的学习过程也像神经网络一样,不断地进行自学习和纠错,提升自身实力。学无止境,希望本文可以让你有那么一点点的收获。
5.参考
[1]http://www.algorithmdog.com/cnn-extracts-feat?open_source=weibo_search&from=timeline
[2]https://mp.weixin.qq.com/s/G5hNwX7mnJK11Cyr7E5b_Q
[3] https://www.zybuluo.com/hanbingtao/note/485480
欢迎关注公众号:计算机视觉life,一起探索计算机视觉新世界~
---------------------
作者:electech6
来源:CSDN
原文:https://blog.csdn.net/electech6/article/details/84584791
版权声明:本文为博主原创文章,转载请附上博文链接!
原来CNN是这样提取图像特征的。。。的更多相关文章
- CNN基础二:使用预训练网络提取图像特征
上一节中,我们采用了一个自定义的网络结构,从头开始训练猫狗大战分类器,最终在使用图像增强的方式下得到了82%的验证准确率.但是,想要将深度学习应用于小型图像数据集,通常不会贸然采用复杂网络并且从头开始 ...
- VGG16提取图像特征 (torch7)
VGG16提取图像特征 (torch7) VGG16 loadcaffe torch7 下载pretrained model,保存到当前目录下 th> caffemodel_url = 'htt ...
- 深度学习tensorflow实战笔记 用预训练好的VGG-16模型提取图像特征
1.首先就要下载模型结构 首先要做的就是下载训练好的模型结构和预训练好的模型,结构地址是:点击打开链接 模型结构如下: 文件test_vgg16.py可以用于提取特征.其中vgg16.npy是需要单独 ...
- Pytorch如何用预训练模型提取图像特征
方法很简单,你只需要将模型最后的全连接层改成Dropout即可. import torch from torchvision import models # load data x, y = get_ ...
- opencv批处理提取图像的特征
____________________________________________________________________________________________________ ...
- 为什么CNN能自动提取图像特征
1.介绍 在大部分传统机器学习场景里,我们先经过特征工程等方法得到特征表示,然后选用一个机器学习算法进行训练.在训练过程中,表示事物的特征是固定的. 后来嘛,后来深度学习就崛起了.深度学习对外推荐自己 ...
- 基于CNN网络的汉字图像字体识别及其原理
现代办公要将纸质文档转换为电子文档的需求越来越多,目前针对这种应用场景的系统为OCR系统,也就是光学字符识别系统,例如对于古老出版物的数字化.但是目前OCR系统主要针对文字的识别上,对于出版物的版面以 ...
- paper 131:【图像算法】图像特征:GLCM【转载】
转载地址:http://www.cnblogs.com/skyseraph/archive/2011/08/27/2155776.html 一 原理 1 概念:GLCM,即灰度共生矩阵,GLCM是一个 ...
- 【图像算法】图像特征:GLCM灰度共生矩阵,纹理特征
[图像算法]图像特征:GLCM SkySeraph Aug 27th 2011 HQU Email:zgzhaobo@gmail.com QQ:452728574 Latest Modifie ...
随机推荐
- React组件的State
React组件的State 1.正确定义State React把组件看成一个状态机.通过与用户的交互,实现不同状态,然后渲染UI,让用户界面和数据保持一致.组件的任何UI改变,都可以从State的变化 ...
- Some untracked working tree files would be overwritten by checkout. Please move or remove them before you can checkout. View them
Some untracked working tree files would be overwritten by checkout. Please move or remove them befor ...
- Redis环境配置和命令语句
环境配置 拷贝Redis-x64-3.2.100到本地一个目录下,解压 然后设置环境变量PATH到该目录 Redis-server.exe:Redis服务端 Redis-cli.exe:Redis客户 ...
- python--json串相关的loads dumps load dump
#1 json串长的像字典,但不是字典类型,是str类型 #例如:user_info为json串,dict为字典,如果txt文本中标识dict的内容 为json串user_info = '''{&qu ...
- hung_task_timeout_secs和blocked for more than 120 seconds的解决方法
Linux系统出现hung_task_timeout_secs和blocked for more than 120 seconds的解决方法 Linux系统出现系统没有响应. 在/var/log/me ...
- 优化网站设计(十):最小化JAVASCRIPT和CSS
前言 网站设计的优化是一个很大的话题,有一些通用的原则,也有针对不同开发平台的一些建议.这方面的研究一直没有停止过,我在不同的场合也分享过这样的话题. 作为通用的原则,雅虎的工程师团队曾经给出过35个 ...
- day7:set和深浅copy
1,判断字符串是不是空格isspace函数 s1 = ' ' s2 = ' ssss' print(s1.isspace()) print(s2.isspace()) 运行结果: True False ...
- gitignore 不起作用的解决办法
gitignore 不起作用的解决办法 - sloong - 博客园 https://www.cnblogs.com/sloong/p/5523244.html Administrator@PC-20 ...
- Kafka – kafka consumer
ConsumerRecords<String, String> records = consumer.poll(100); /** * Fetch data for the topic ...
- 中位数&贪心
谁能想到基本算法就这么难呢?我想去冲省选,但是迟迟在这些地方 花时间 算是提升自己的思维算了. 这道题呢 答案其实很简单每个数在a的位置和在b的位置之差的累加/2即是答案为什么呢?考虑当前数字 要向后 ...