决策树分类算法及python代码实现案例
决策树分类算法
1、概述
决策树(decision tree)——是一种被广泛使用的分类算法。
相比贝叶斯算法,决策树的优势在于构造过程不需要任何领域知识或参数设置
在实际应用中,对于探测式的知识发现,决策树更加适用。
2、算法思想
通俗来说,决策树分类的思想类似于找对象。现想象一个女孩的母亲要给这个女孩介绍男朋友,于是有了下面的对话:
女儿:多大年纪了?
母亲:26。
女儿:长的帅不帅?
母亲:挺帅的。
女儿:收入高不?
母亲:不算很高,中等情况。
女儿:是公务员不?
母亲:是,在税务局上班呢。
女儿:那好,我去见见。
这个女孩的决策过程就是典型的分类树决策。
实质:通过年龄、长相、收入和是否公务员对将男人分为两个类别:见和不见
假设这个女孩对男人的要求是:30岁以下、长相中等以上并且是高收入者或中等以上收入的公务员,那么这个可以用下图表示女孩的决策逻辑

上图完整表达了这个女孩决定是否见一个约会对象的策略,其中:
◊绿色节点表示判断条件
◊橙色节点表示决策结果
◊箭头表示在一个判断条件在不同情况下的决策路径
图中红色箭头表示了上面例子中女孩的决策过程。
这幅图基本可以算是一颗决策树,说它“基本可以算”是因为图中的判定条件没有量化,如收入高中低等等,还不能算是严格意义上的决策树,如果将所有条件量化,则就变成真正的决策树了。
决策树分类算法的关键就是根据“先验数据”构造一棵最佳的决策树,用以预测未知数据的类别
决策树:是一个树结构(可以是二叉树或非二叉树)。其每个非叶节点表示一个特征属性上的测试,每个分支代表这个特征属性在某个值域上的输出,而每个叶节点存放一个类别。使用决策树进行决策的过程就是从根节点开始,测试待分类项中相应的特征属性,并按照其值选择输出分支,直到到达叶子节点,将叶子节点存放的类别作为决策结果。
3、决策树构造
假如有以下判断苹果好坏的数据样本:
|
样本 红 大 好苹果 0 1 1 1 1 1 0 1 2 0 1 0 3 0 0 0 |
样本中有2个属性,A0表示是否红苹果。A1表示是否大苹果。假如要根据这个数据样本构建一棵自动判断苹果好坏的决策树。
由于本例中的数据只有2个属性,因此,我们可以穷举所有可能构造出来的决策树,就2棵,如下图所示:
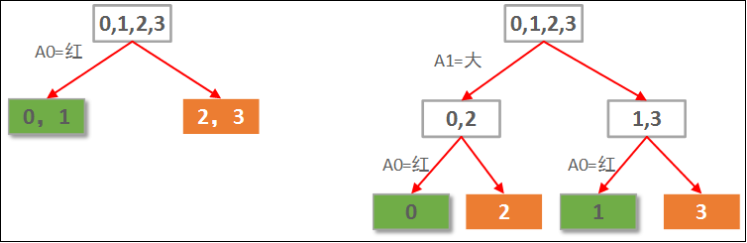
显然左边先使用A0(红色)做划分依据的决策树要优于右边用A1(大小)做划分依据的决策树。
当然这是直觉的认知。而直觉显然不适合转化成程序的实现,所以需要有一种定量的考察来评价这两棵树的性能好坏。
决策树的评价所用的定量考察方法为计算每种划分情况的信息熵增益:
如果经过某个选定的属性进行数据划分后的信息熵下降最多,则这个划分属性是最优选择
属性划分选择(即构造决策树)的依据:
简单来说,熵就是“无序,混乱”的程度。
通过计算来理解:
1、原始样本数据的熵:
样例总数:4
好苹果:2
坏苹果:2
熵: -(1/2 * log(1/2) + 1/2 * log(1/2)) = 1
信息熵为1表示当前处于最混乱,最无序的状态。
2、两颗决策树的划分结果熵增益计算
树1先选A0作划分,各子节点信息熵计算如下:
0,1叶子节点有2个正例,0个负例。信息熵为:e1 = -(2/2 * log(2/2) + 0/2 * log(0/2)) = 0。
2,3叶子节点有0个正例,2个负例。信息熵为:e2 = -(0/2 * log(0/2) + 2/2 * log(2/2)) = 0。
因此选择A0划分后的信息熵为每个子节点的信息熵所占比重的加权和:E = e1*2/4 + e2*2/4 = 0。
选择A0做划分的信息熵增益G(S, A0)=S - E = 1 - 0 = 1.
事实上,决策树叶子节点表示已经都属于相同类别,因此信息熵一定为0。
树2先选A1作划分,各子节点信息熵计算如下:
0,2子节点有1个正例,1个负例。信息熵为:e1 = -(1/2 * log(1/2) + 1/2 * log(1/2)) = 1。
1,3子节点有1个正例,1个负例。信息熵为:e2 = -(1/2 * log(1/2) + 1/2 * log(1/2)) = 1。
因此选择A1划分后的信息熵为每个子节点的信息熵所占比重的加权和:E = e1*2/4 + e2*2/4 = 1。也就是说分了跟没分一样!
选择A1做划分的信息熵增益G(S, A1)=S - E = 1 - 1 = 0.
因此,每次划分之前,我们只需要计算出信息熵增益最大的那种划分即可。
先做A0划分时的信息熵增益为1>先做A1划分时的信息熵增益,所以先做A0划分是最优选择!!!
4、算法指导思想
经过决策属性的划分后,数据的无序度越来越低,也就是信息熵越来越小
5、算法实现
梳理出数据中的属性
比较按照某特定属性划分后的数据的信息熵增益,选择信息熵增益最大的那个属性作为第一划分依据,然后继续选择第二属性,以此类推
决策树分类算法及python代码实现案例的更多相关文章
- KNN分类算法及python代码实现
KNN分类算法(先验数据中就有类别之分,未知的数据会被归类为之前类别中的某一类!) 1.KNN介绍 K最近邻(k-Nearest Neighbor,KNN)分类算法是最简单的机器学习算法. 机器学习, ...
- 用Python开始机器学习(2:决策树分类算法)
http://blog.csdn.net/lsldd/article/details/41223147 从这一章开始进入正式的算法学习. 首先我们学习经典而有效的分类算法:决策树分类算法. 1.决策树 ...
- python 之 决策树分类算法
发现帮助新手入门机器学习的一篇好文,首先感谢博主!:用Python开始机器学习(2:决策树分类算法) J. Ross Quinlan在1975提出将信息熵的概念引入决策树的构建,这就是鼎鼎大名的ID3 ...
- 机器学习之决策树(ID3)算法与Python实现
机器学习之决策树(ID3)算法与Python实现 机器学习中,决策树是一个预测模型:他代表的是对象属性与对象值之间的一种映射关系.树中每个节点表示某个对象,而每个分叉路径则代表的某个可能的属性值,而每 ...
- 数据关联分析 association analysis (Aprior算法,python代码)
1基本概念 购物篮事务(market basket transaction),如下表,表中每一行对应一个事务,包含唯一标识TID,和购买的商品集合.本文介绍一种成为关联分析(association a ...
- 朴素贝叶斯分类算法介绍及python代码实现案例
朴素贝叶斯分类算法 1.朴素贝叶斯分类算法原理 1.1.概述 贝叶斯分类算法是一大类分类算法的总称 贝叶斯分类算法以样本可能属于某类的概率来作为分类依据 朴素贝叶斯分类算法是贝叶斯分类算法中最简单的一 ...
- 决策树原理实例(python代码实现)
决策数(Decision Tree)在机器学习中也是比较常见的一种算法,属于监督学习中的一种.看字面意思应该也比较容易理解,相比其他算法比如支持向量机(SVM)或神经网络,似乎决策树感觉“亲切”许多. ...
- 分类算法的R语言实现案例
最近在读<R语言与网站分析>,书中对分类.聚类算法的讲解通俗易懂,和数据挖掘理论一起看的话,有很好的参照效果. 然而,这么好的讲解,作者居然没提供对应的数据集.手痒之余,我自己动手整理了一 ...
- spark 决策树分类算法demo
分类(Classification) 下面的例子说明了怎样导入LIBSVM 数据文件,解析成RDD[LabeledPoint],然后使用决策树进行分类.GINI不纯度作为不纯度衡量标准并且树的最大深度 ...
随机推荐
- vue自学入门-2(vue创建项目)
本人也是刚学习VUE,边找资料,边学习,边给大家分享.1.创建项目 2.启动项目 3.注意上面和下面全部用cnpm
- 网站程序CMS识别
CMS cms一般有dedecms(织梦),dzcms,phpweb,phpwind,phpcms,ecshop,dvbbs,siteweaver,aspcms,帝国,zblog,wordpress等 ...
- 安卓中location.href或者location.reload 不起作用
链接:https://www.cnblogs.com/joshua317/p/6163471.html 在移动wap中,经常会使用window.location.href去跳转页面,这个方法在绝大多数 ...
- c#中富文本编辑器Simditor带图片上传的全部过程(项目不是mvc架构)
描述:最近c#项目中使用富文本编辑器Simditor,记录一下以便以后查看. 注:此项目不是MVC架构的. 1.引用文件 项目中引用相应的css和js文件,注意顺序不能打乱,否则富文本编辑器不会正常显 ...
- MGR架构~单写模式架构的搭建
一 简介 :MGR一直没有时间测试,今天咱们来初步了解搭建一下呗 二 环境: mysql5.7.20 单台机器 启动三实例 三 mysql 搭建: 1 建立相关目录+ mkdir -p /data ...
- semantic segmentation 和instance segmentation
作者:周博磊链接:https://www.zhihu.com/question/51704852/answer/127120264来源:知乎著作权归作者所有,转载请联系作者获得授权. 图1. 这张图清 ...
- CentOS 6.5下快速搭建ftp服务器[转]
CentOS 6.5下快速搭建ftp服务器 1.用root 进入系统 2.使用命令 rpm -qa|grep vsftpd 查看系统是否安装了ftp,若安装了vsftp,使用这个命令会在屏幕上显示vs ...
- Python 的 six模块简介
Python 的 six模块简介 six : Six is a Python 2 and 3 compatibility library Six没有托管在Github上,而是托管在了Bitbucket ...
- Caching漫谈--关于Cache的几个理论
如今缓存是随处可见了,如果你的程序还没有使用到缓存,那可能是你的程序并发量很低,或对实时性要求很低.我们公司的ERP在显示某些报表时,每次打开都需要花上几分钟的时间,假如搜索引擎也是这么慢,我想这家搜 ...
- linux 串口0x03,0x13的问题【转】
linux 串口0x03,0x13的问题 本人最近在调linux串口的时候,发现其他数据接收正常,但是0x13怎么也接收不到,后面发现了这篇文章,两天的bug终于解决了,原来是linux底层uart配 ...