关于编码:Unicode/UTF-8/UTF-16/UTF-32
关于编码,绕不开下面这些概念
①Unicode/UTF-8/UTF-16/UTF-32
②大小端字节序(big-endian/little-endian)
③BOM(Byte Order Mark)
1.关于Unicode/UTF-8/UTF-16/UTF-32
①Unicode其实应该是一个码值表。(百度百科:Unicode的功用是为每一个字符提供一个唯一的代码(即一组数字))。
②UTF-8/UTF-16/UTF-32是通过对Unicode码值进行对应规则转换后,编码保持到内存/文件中。UTF-8/UTF-16/UTF-32都是可变长度的编码方式。(后面将进行Unicode码值转换为UTF-8的说明)。
③我们平常说的 “Unicode编码是2个字节” 这句话,其实是因为windows默认的Unicode编码就是UTF-16,在常用基本字符上2个字节的编码方式已经够用导致的误解,其实是可变长度的。
在没有特殊说明的情况下,常说的Unicode编码可以理解为UTF-16编码。
④UTF-32是因为UTF-16编码方式不能表示全部的字符而扩充的编码方式。
ps:显示的字符是表现形式,具体内存中的编码方式和字符显示之间通过中间层进行转换。(根据编码规则,1个字符可能对应内存中1个到几个字节。)
2.UTF-8编码
①UTF编码方式,按照规则转换后,第1个字节仍与ASCII兼容,这使得原来处理ASCII字符的软件无须或只须做少部分修改,即可继续使用。
网络上数据传输英文字符只需要1个字节,可以节省带宽资源。当前大部分的网络应用都使用UTF-8编码。(中文按照规则会转换为3个字节,反而浪费资源,没办法,规则别人定好了!)
②UTF-8编码需要进行字节数转换+补码两个步骤
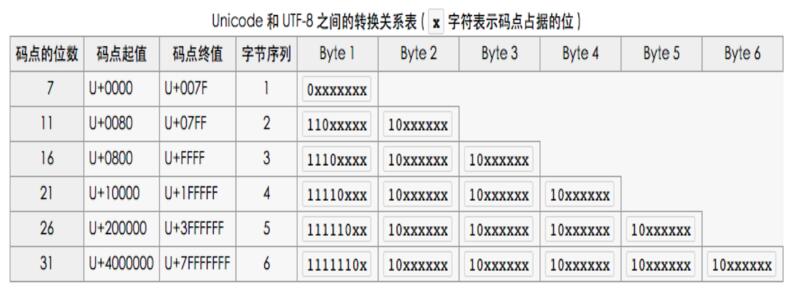
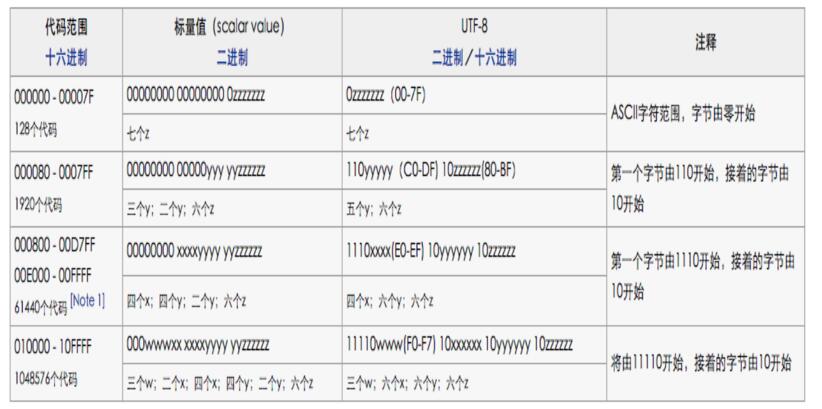
Unicode码值转UTF-8编码规则之一(字节数转换)
•1个字节:Unicode码为0 - 127
•2个字节:Unicode码为128 - 2047
•3个字节:Unicode码为2048 - 0xFFFF
•4个字节:Unicode码为65536 - 0x1FFFFF
•5个字节:Unicode码为0x200000 - 0x3FFFFFF
•6个字节:Unicode码为0x4000000 - 0x7FFFFFFF
Unicode码值转UTF-8编码规则之二(二进制补码)
对应上面规则一字节数转换后,具体的补位码如下,"x"表示空位,用来补位的,补不全则使用0。
可以看到规律,第一个字节前面有多少个1就表示占用多少个字节,红色颜色位固定不变。(0-127的值直接使用0表示占用1个字节)
•1个字节:xxxxxxx
•2个字节:xxxxx xxxxxx
•3个字节:xxxx xxxxxx xxxxxx
•4个字节:xxx xxxxxx xxxxxx xxxxxx
•5个字节:xx xxxxxx xxxxxx xxxxxx xxxxxx
•6个字节:x xxxxxx xxxxxx xxxxxx xxxxxx xxxxxx
③使用UTF-8编码字符A
•字节数转换:字符A的Unicode码值为65,位于0-127的区间,所以占1个字节,其二进制值为(7位)
•补码:使用1个字节xxxxxxx格式进行补码(7个x),将上面的7位二进制值从右到左填到7个x中,得到(8位)
得到字符A的UTF-8编码为01000001(8位)
④使用UTF-8编码中文字符“中”
•字节数转换:中文字符“中”的Unicode码值为20013,位于2048-0xFFFF的区间,所以占3个字节,其二进制值为1001110 00101101(15位)
•补码:使用3个字节xxxx xxxxxx xxxxxx格式进行补码(16个x),将上面的15位二进制值从右到左填到16个x中(不足位则将x变为0),得到0
得到中文字符“中的”UTF-8编码位11100100 10111000 10101101(24位)
3.大小端字节序(big-endian/little-endian)
①字节序表示在内存/文件中字节的保存顺序,由于硬件读写顺序的不同,导致出现了大端和小端两种方式。
大端:数据的高字节保存在内存的低地址中,低字节保存到内存的地址中,和我们的阅读习惯一致;小端则相反,常用的X86结构是小端模式。
采用大端方式进行数据存放符合人类的正常思维,而采用小端方式进行数据存放利于计算机处理。
②UTF-8编码不存在字节序大小端问题!(因为字节序只影响同时处理多于两个字节的编码方式,比如UTF-16/UTF-32,而UTF-8是按照单字节进行处理的)
UTF-8的解码都必须先读取首字节获取字节数,所以必须找到首字节的第一位要么是,要么是////1111110,所以上面的“中”字,无论是保存为11100100 10111000 10101101还是10101101 10111000 11100100,都必须要先找到11100100这个字节,所以UTF-8从机制上就能避免字节序的问题。
③UTF-16/UTF-32存在字节序问题(UTF-16常用情况下一次处理2个字节/UTF-32一次处理4个字节)!一个“奎”的Unicode码值是0x594E,“乙”的Unicode码值是0x4E59。如果我们的UTF-16字节数据是0x594E,那么这是“奎”还是“乙”?如果大端序,0x594E是“奎”,如果是小端序,0x4E59,是“乙”。
4.BOM(Byte Order Mark)
①为了保证编码和解码字节顺序问题(因为只有保证编码和解码的规则一致才能保证是同一个字符),所以Unicode规范中推荐的标记字节顺序的方法是BOM(Byte Order Mark)。
②UTF-8不需要BOM来表明字节顺序,但可以用BOM来表明编码方式。根据BOM的规则,在一段字节流开始时,如果接收到以下字节,则分别表明了该文本文件的编码。
UTF-8: EF BB BF
UTF-16 : FF FE
UTF-16 big-endian: FE FF
UTF-32 little-endian: FF FE 00 00
UTF-32 big-endian: 00 00 FE FF
而如果不是以这个开头,那程序则会以ANSI,也就是系统默认编码读取。
如同样是字符“A”﹐在以下几种格式中的存储形式分别是﹕
UTF-16 big-endian : 00 41
UTF-16 little-endian : 41 00
UTF-32 big-endian : 00 00 00 41
UTF-32 little-endian : 41 00 00 00
参考资料:
以上。
关于编码:Unicode/UTF-8/UTF-16/UTF-32的更多相关文章
- Ansi、GB2312、GBK、Unicode(utf8、16、32)
关于ansi,一般默认为本地编码方式,中文应该是gb编码 他们之间的关系在这边文章里描写的很清楚:http://blog.csdn.net/ldanduo/article/details/820353 ...
- 转载:谈谈Unicode编码,简要解释UCS、UTF、BMP、BOM等名词
转载: 谈谈Unicode编码,简要解释UCS.UTF.BMP.BOM等名词 这是一篇程序员写给程序员的趣味读物.所谓趣味是指可以比较轻松地了解一些原来不清楚的概念,增进知识,类似于打RPG游戏的升级 ...
- 字符编码-UNICODE,GBK,UTF-8区别【转转】
字符编码介绍及不同编码区别 今天看到这篇关于字符编码的文章,抑制不住喜悦(总结的好详细)所以转到这里来.转自:祥龙之子http://www.cnblogs.com/cy163/archive/2007 ...
- 各种编码中汉字所占字节数;中文字符集编码Unicode ,gb2312 , cp936 ,GBK,GB18030
vim settings set fileencodings=utf-8,ucs-bom,gb18030,gbk,gb2312,cp936,latin1set termencoding=utf-8se ...
- 中文字符集编码Unicode ,gb2312 , cp936 ,GBK,GB18030
中文字符集编码Unicode ,gb2312 , cp936 ,GBK,GB18030 cp936是微软自己发布的用在文件系统中的编码方式.而bg2312是中国国家标准.我明白mount -t vfa ...
- 彻底搞懂字符编码(unicode,mbcs,utf-8,utf-16,utf-32,big endian,little endian...)[转]
最近有一些朋友常问我一些乱码的问题,和他们交流过程中,发现这个编码的相关知识还真是杂乱不堪,不少人对一些知识理解似乎也有些偏差,网上百度, google的内容,也有不少以讹传讹,根本就是错误的(例如说 ...
- 各种编码UNICODE、UTF-8、ANSI、ASCII、GB2312、GBK详解
来自:http://blog.csdn.net/lvxiangan/article/details/8151670 ------------------------------------------ ...
- java字符编码-Unicode编码问题刨根究底
博客搬家: java字符编码问题 前段时间在读<java核心技术卷一>,遇到一些名词:码点.代码单元等,其实字面意思不难理解,解释如下 码点(code point):Unicode编码表中 ...
- 各种编码UNICODE、UTF-8、ASCII学习笔记
本文转自csdn博客:http://www.ruanyifeng.com/blog/2007/10/ascii_unicode_and_utf-8.html ,感谢作者的分享 作者: 阮一峰 日期: ...
- 引用 字库编码Unicode相关知识
引用 weifeng.shen 的 字库编码Unicode相关知识 1. 各地编码 首先说明一下现在常用的一些编码方案: 1. 在中国,大陆最常用的就是GBK18030编码, ...
随机推荐
- php 把秒数转换为时长(h:i:s格式)
/** * 把秒数转换为时分秒的格式 * @param Int $times 时间,单位 秒 * @return String */ function secToTime($times){ $resu ...
- Windows下用cmd命令实例讲解yii2.0 的控制台定时任务
Yii中的资源是和Web页面相关的文件,可为CSS文件,JavaScript文件,图片或视频等,资源放在Web可访问的目录下,直接被Web服务器调用. 有时候有些功能需要做到计划任务中去,因此就需要y ...
- linux 实时显示网速bash
执行方法先授权再运行 chmod +x shi.sh脚本+网卡名称 ./shi.sh ens33 #!/bin/bash while [ "1" ] do eth=$1 RXpre ...
- JS实现对数器
对数器的概念和使用 对数器一般用于验证你写的算法是否正确,因为自己写的测试用例可能写的考虑不够全面. 0.有一个你想测试的方法a 1.实现一个绝对正确但是时间复杂度不好的方法b 2.实现一个随机样本产 ...
- webpack对于引入的模块无法智能代码提示
前端模块太多了,模块里的方法比较难记住,所以我们一般靠的都是IDE的代码提示. 但是有时候我们会发现对于引入的模块没有代码提示,我也安装了模块呀,为什么没有代码提示? 主要是package.json的 ...
- wait()和notify()的理解与使用
void notify() Wakes up a single thread that is waiting on this object’s monitor. 译:唤醒在此对象监视器上等待的单个线程 ...
- Python3 tkinter基础 Label imag显示图片
Python : 3.7.0 OS : Ubuntu 18.04.1 LTS IDE : PyCharm 2018.2.4 Conda ...
- Python3 tkinter基础 Entry validate validatecommand 失去焦点时,检查输入内容
Python : 3.7.0 OS : Ubuntu 18.04.1 LTS IDE : PyCharm 2018.2.4 Conda ...
- Python 装饰器实例
retry 偶然看到一篇文章,想到了前几天的一个需求,git pull性能不稳,需要加入重试机制,正好这个装饰器的实例符合这样的场景. # coding:utf-8 import time impor ...
- 一些常用的mysql语句实例-以后照写
create database blog; create table blog_user ( user_Name char(15) not null check(user_Name !=''), us ...