死磕Java面试系列:深拷贝与浅拷贝的实现原理
深拷贝与浅拷贝的问题,也是面试中的常客。虽然大家都知道两者表现形式不同点在哪里,但是很少去深究其底层原理,也不知道怎么才能优雅的实现一个深拷贝。其实工作中也常常需要实现深拷贝,今天一灯就带大家一块深入剖析一下深拷贝与浅拷贝的实现原理,并手把手教你怎么优雅的实现深拷贝。
1. 什么是深拷贝与浅拷贝
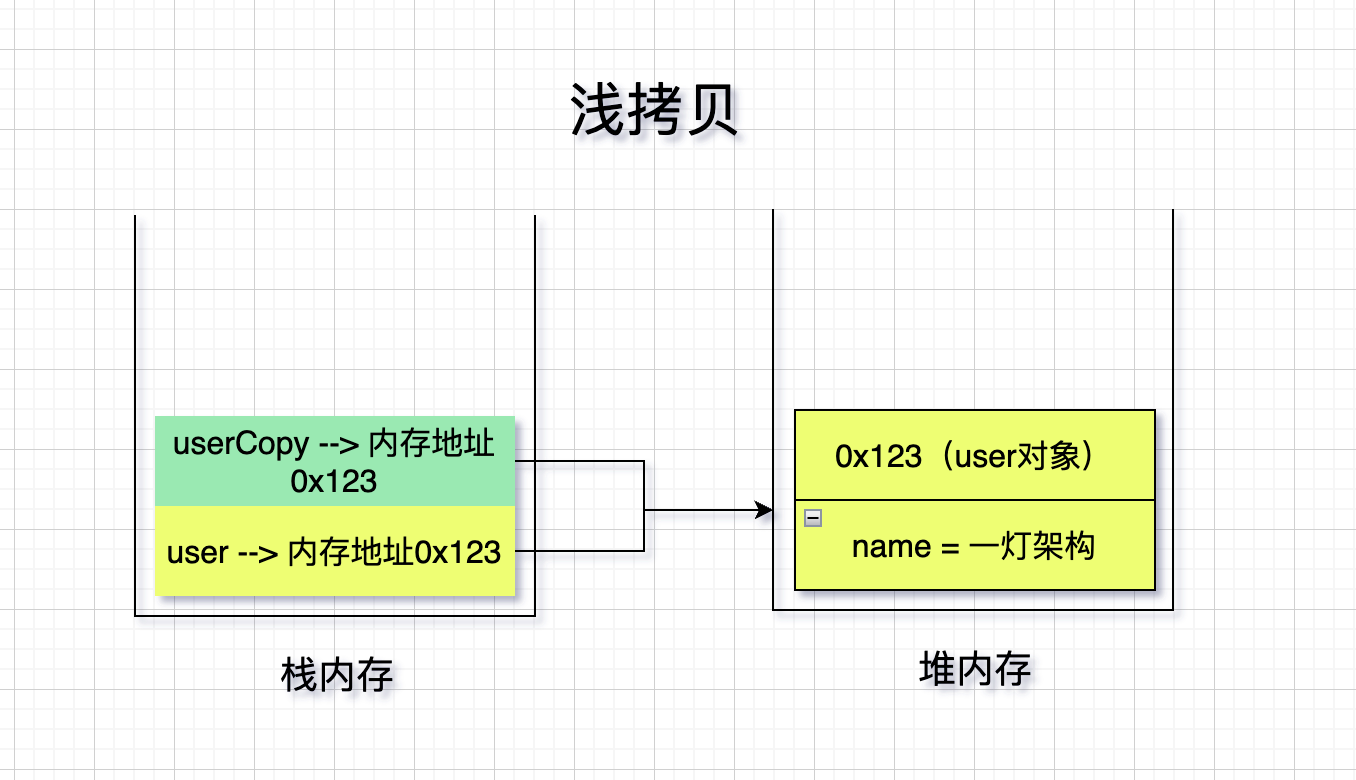
浅拷贝: 只拷贝栈内存中的数据,不拷贝堆内存中数据。
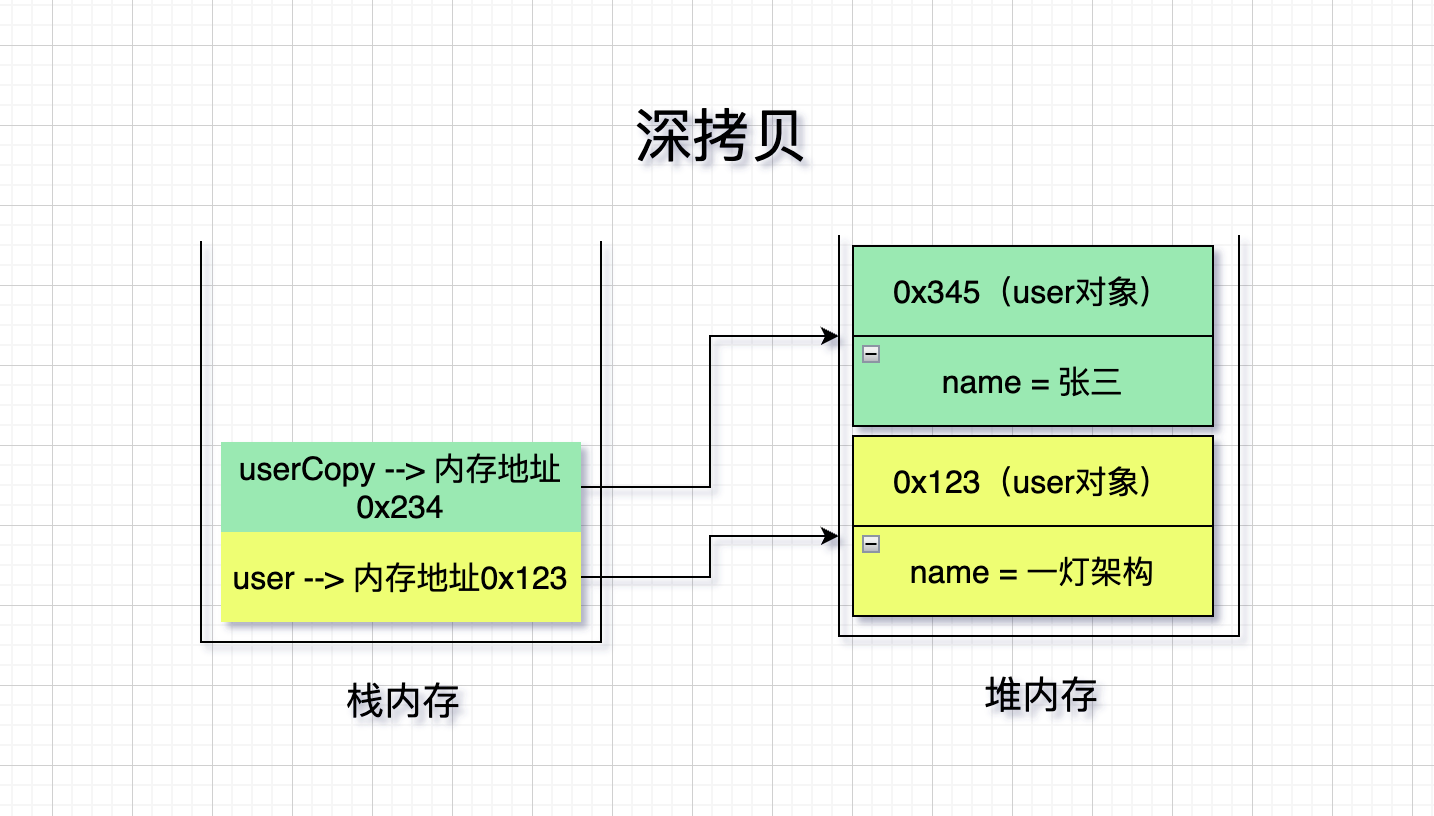
深拷贝: 既拷贝栈内存中的数据,又拷贝堆内存中的数据。
2. 浅拷贝的实现原理
由于浅拷贝只拷贝了栈内存中数据,栈内存中存储的都是基本数据类型,堆内存中存储了数组、引用数据类型等。
使用代码验证一下:
想要实现clone功能,需要实现 Cloneable 接口,并重写 clone 方法。
- 先创建一个用户类
// 用户的实体类,用作验证
public class User implements Cloneable {
private String name;
// 每个用户都有一个工作
private Job job;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Job getJob() {
return job;
}
public void setJob(Job job) {
this.job = job;
}
@Override
public User clone() throws CloneNotSupportedException {
User user = (User) super.clone();
return user;
}
}
- 再创建一个工作类
// 工作的实体类,并没有实现Cloneable接口
public class Job {
private String content;
public String getContent() {
return content;
}
public void setContent(String content) {
this.content = content;
}
}
- 测试浅拷贝
/**
* @author 一灯架构
* @apiNote Java浅拷贝示例
**/
public class Demo {
public static void main(String[] args) throws CloneNotSupportedException {
// 1. 创建用户对象,{"name":"一灯架构","job":{"content":"开发"}}
User user1 = new User();
user1.setName("一灯架构");
Job job1 = new Job();
job1.setContent("开发");
user1.setJob(job1);
// 2. 拷贝用户对象,name修改为"张三",工作内容修改"测试"
User user2 = user1.clone();
user2.setName("张三");
Job job2 = user2.getJob();
job2.setContent("测试");
// 3. 输出结果
System.out.println("user原对象= " + user1);
System.out.println("user拷贝对象= " + user2);
}
}
输出结果:
user原对象= {"name":"一灯架构","job":{"content":"测试"}}
user拷贝对象= {"name":"张三","job":{"content":"测试"}}
从结果中可以看出,对象拷贝把name修改为”张三“,原对象并没有变,name是String类型,是基本数据类型,存储在栈内存中。对象拷贝了一份新的栈内存数据,修改并不会影响原对象。
然后对象拷贝把Job中content修改为”测试“,原对象也跟着变了,原因是Job是引用类型,存储在堆内存中。对象拷贝和原对象指向的同一个堆内存的地址,所以修改会影响到原对象。
3. 深拷贝的实现原理
深拷贝是既拷贝栈内存中的数据,又拷贝堆内存中的数据。
实现深拷贝有很多种方法,下面就详细讲解一下,看使用哪种方式更方便快捷。
3.1 实现Cloneable接口
通过实现Cloneable接口来实现深拷贝是最常见的。
想要实现clone功能,需要实现Cloneable接口,并重写clone方法。
- 先创建一个用户类
// 用户的实体类,用作验证
public class User implements Cloneable {
private String name;
// 每个用户都有一个工作
private Job job;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Job getJob() {
return job;
}
public void setJob(Job job) {
this.job = job;
}
@Override
public User clone() throws CloneNotSupportedException {
User user = (User) super.clone();
// User对象中所有引用类型属性都要执行clone方法
user.setJob(user.getJob().clone());
return user;
}
}
- 再创建一个工作类
// 工作的实体类,需要实现Cloneable接口
public class Job implements Cloneable {
private String content;
public String getContent() {
return content;
}
public void setContent(String content) {
this.content = content;
}
@Override
protected Job clone() throws CloneNotSupportedException {
return (Job) super.clone();
}
}
- 测试浅拷贝
/**
* @author 一灯架构
* @apiNote Java深拷贝示例
**/
public class Demo {
public static void main(String[] args) throws CloneNotSupportedException {
// 1. 创建用户对象,{"name":"一灯架构","job":{"content":"开发"}}
User user1 = new User();
user1.setName("一灯架构");
Job job1 = new Job();
job1.setContent("开发");
user1.setJob(job1);
// 2. 拷贝用户对象,name修改为"张三",工作内容修改"测试"
User user2 = user1.clone();
user2.setName("张三");
Job job2 = user2.getJob();
job2.setContent("测试");
// 3. 输出结果
System.out.println("user原对象= " + user1);
System.out.println("user拷贝对象= " + user2);
}
}
输出结果:
user原对象= {"name":"一灯架构","job":{"content":"开发"}}
user拷贝对象= {"name":"张三","job":{"content":"测试"}}
从结果中可以看出,user拷贝对象修改了name属性和Job对象中内容,都没有影响到原对象,实现了深拷贝。
通过实现Cloneable接口的方式来实现深拷贝,是Java中最常见的实现方式。
缺点是: 比较麻烦,需要所有实体类都实现Cloneable接口,并重写clone方法。如果实体类中新增了一个引用对象类型的属性,还需要添加到clone方法中。如果继任者忘了修改clone方法,相当于挖了一个坑。
3.2 使用JSON字符串转换
实现方式就是:
- 先把user对象转换成json字符串
- 再把json字符串转换成user对象
这是个偏方,但是偏方治大病,使用起来非常方便,一行代码即可实现。
下面使用fastjson实现,使用Gson、Jackson也是一样的:
import com.alibaba.fastjson.JSON;
/**
* @author 一灯架构
* @apiNote Java深拷贝示例
**/
public class Demo {
public static void main(String[] args) throws CloneNotSupportedException {
// 1. 创建用户对象,{"name":"一灯架构","job":{"content":"开发"}}
User user1 = new User();
user1.setName("一灯架构");
Job job1 = new Job();
job1.setContent("开发");
user1.setJob(job1);
//// 2. 拷贝用户对象,name修改为"张三",工作内容修改"测试"
User user2 = JSON.parseObject(JSON.toJSONString(user1), User.class);
user2.setName("张三");
Job job2 = user2.getJob();
job2.setContent("测试");
// 3. 输出结果
System.out.println("user原对象= " + JSON.toJSONString(user1));
System.out.println("user拷贝对象= " + JSON.toJSONString(user2));
}
}
输出结果:
user原对象= {"name":"一灯架构","job":{"content":"开发"}}
user拷贝对象= {"name":"张三","job":{"content":"测试"}}
从结果中可以看出,user拷贝对象修改了name属性和Job对象中内容,并没有影响到原对象,实现了深拷贝。
3.3 集合实现深拷贝
再说一下Java集合怎么实现深拷贝?
其实非常简单,只需要初始化新对象的时候,把原对象传入到新对象的构造方法中即可。
以最常用的ArrayList为例:
/**
* @author 一灯架构
* @apiNote Java深拷贝示例
**/
public class Demo {
public static void main(String[] args) throws CloneNotSupportedException {
// 1. 创建原对象
List<User> userList = new ArrayList<>();
// 2. 创建深拷贝对象
List<User> userCopyList = new ArrayList<>(userList);
}
}
我是「一灯架构」,如果本文对你有帮助,欢迎各位小伙伴点赞、评论和关注,感谢各位老铁,我们下期见

死磕Java面试系列:深拷贝与浅拷贝的实现原理的更多相关文章
- 死磕 java同步系列之AQS终篇(面试)
问题 (1)AQS的定位? (2)AQS的重要组成部分? (3)AQS运用的设计模式? (4)AQS的总体流程? 简介 AQS的全称是AbstractQueuedSynchronizer,它的定位是为 ...
- 死磕 java同步系列之redis分布式锁进化史
问题 (1)redis如何实现分布式锁? (2)redis分布式锁有哪些优点? (3)redis分布式锁有哪些缺点? (4)redis实现分布式锁有没有现成的轮子可以使用? 简介 Redis(全称:R ...
- 死磕 java同步系列之终结篇
简介 同步系列到此就结束了,本篇文章对同步系列做一个总结. 脑图 下面是关于同步系列的一份脑图,列举了主要的知识点和问题点,看过本系列文章的同学可以根据脑图自行回顾所学的内容,也可以作为面试前的准备. ...
- 死磕 java同步系列之AQS起篇
问题 (1)AQS是什么? (2)AQS的定位? (3)AQS的实现原理? (4)基于AQS实现自己的锁? 简介 AQS的全称是AbstractQueuedSynchronizer,它的定位是为Jav ...
- 死磕 java同步系列之volatile解析
问题 (1)volatile是如何保证可见性的? (2)volatile是如何禁止重排序的? (3)volatile的实现原理? (4)volatile的缺陷? 简介 volatile可以说是Java ...
- 死磕 java同步系列之自己动手写一个锁Lock
问题 (1)自己动手写一个锁需要哪些知识? (2)自己动手写一个锁到底有多简单? (3)自己能不能写出来一个完美的锁? 简介 本篇文章的目标一是自己动手写一个锁,这个锁的功能很简单,能进行正常的加锁. ...
- 死磕 java同步系列之CyclicBarrier源码解析——有图有真相
问题 (1)CyclicBarrier是什么? (2)CyclicBarrier具有什么特性? (3)CyclicBarrier与CountDownLatch的对比? 简介 CyclicBarrier ...
- 死磕 java同步系列之Phaser源码解析
问题 (1)Phaser是什么? (2)Phaser具有哪些特性? (3)Phaser相对于CyclicBarrier和CountDownLatch的优势? 简介 Phaser,翻译为阶段,它适用于这 ...
- 死磕 java同步系列之zookeeper分布式锁
问题 (1)zookeeper如何实现分布式锁? (2)zookeeper分布式锁有哪些优点? (3)zookeeper分布式锁有哪些缺点? 简介 zooKeeper是一个分布式的,开放源码的分布式应 ...
随机推荐
- Hnoi2014世界树
题面 说明/提示 N<=300000, q<=300000,m[1]+m[2]+...+m[q]<=300000 题解 这道题一看 "m[1]+m[2]+...+m[q]& ...
- 1.7_CSS基础
层叠样式表 (Cascading Style Sheets) CSS产生缘由 HTML 标签原本被设计为用于定义文档内容.通过使用 <h1>.<p>.<table> ...
- Halcon C#开发OpenFramegrabber卡死问题
之前用Halcon12开发的时候,Hdevelop打开相机正常,但是用C#开发的时候,就出现了问题. 1.换库,甚至将x64中dll全部拷贝到debug中,始终不行 2.看到有说卸载360的,更是离谱 ...
- bat-CSV文件转MD文件
目录 1. bat文件里面写死文件名 2. 拖入文件 1. bat文件里面写死文件名 @echo off & setlocal enabledelayedexpansion SET filep ...
- Linux安装Jenkins及配置svn使用
目录 1. 下载 2. 创建文件夹 3. 安装 4. 修改端口,不用这步 5. 安装插件提速 6. 启动 7. 页面访问 8. 新建用户 9. 安装Subversion插件 10. 安装maven插件 ...
- 如何使用CSS伪类选择器
总览 CSS选择器允许你通过类型.属性.位于HTML文档中的位置来选择元素.本教程阐述了三个新选项:is().:where()和:has(). 选择器通常在样式表中使用.下面的示例会找到所有<p ...
- HCNP Routing&Switching之DHCP安全
前文我们了解了MAC地址防漂移技术,回顾请参考https://www.cnblogs.com/qiuhom-1874/p/16632239.html:今天我们来了解下DHCP安全相关话题: 回顾DHC ...
- 教大家怎么看monaco-editor的官方文档
最近业务中有用到浏览器在线编辑器,用的是monaco-editor,官网文档只在首页介绍了npm安装方式. 但其实还有另外一种<script>的引入方式,但是这种方式体现在API文档中,由 ...
- KingbaseES R6 集群主库网卡down测试案例
数据库版本: test=# select version(); version ------------------------------------------------------------ ...
- swagger访问url
http://172.16.5.130:8080/swagger-ui.html 上面的ip:port 根据实际情况调换 如果设置了server.servlet.context-path 比如: se ...