C++进阶(map+set容器模拟实现)
关联式容器
关联式容器也是用来存储数据的,与序列式容器(如vector、list等)不同的是,其里面存储的是<key,value>结构的键值对,在数据检索时比序列式容器效率更高。今天要介绍的的四种容器是树形关联式容器:map、set、multimap和multiset。它们的底层都是用红黑树来实现的,容器中的元素是一个有序的序列。
匿名对象
概念:匿名对象可以理解为是一个临时对象,一般系统自动生成的
匿名对象的生命周期
- Cat(); ---> 生成了一个匿名对象,执行完Cat( )代码后,此匿名对象就此消失。这就是匿名对象的生命周期。
- Cat cc = Cat(); --->当发现匿名对象初始化一个新对象时,会直接把这个匿名对象转成新对象,首先生成了一个匿名对象,然后将此匿名对象变为了cc对象,其生命周期就变成了cc对象的生命周期
注意匿名对象的赋值(=)操作含义是不一样的:
//观察这两个语句
A.Cat cc = cat();
B.Cat cc2 = cc;
A中=是一个初始化操作,表示初始化一个匿名对象,只会调用一次构造函数,然后将匿名对象进行类型转换转化成有名对象cc,注意是Cat()匿名对象调用的构造函数,转化为有名对象cc之后,cc的生命周期就是匿名对象的生命周期
B中的=就是赋值操作,也就是调用拷贝构造,深浅拷贝问题,要注意区分
例子1:我们来看看,匿名对象赋值的几种情况
class A
{
public:
A(int s)
{
cout << "调用有参构造" << endl;
i = s;
}
A(const A& a)
{
cout << "调用拷贝构造" << endl;
}
~A()
{
cout << "调用析构函数" << endl;
}
void show()
{
cout << this->i << endl;
}
private:
int i;
};
void playstage()
{
//1.此处发生隐身转换。。。。相当于 A a = A(11); 此处的A(11)就是一个匿名对象
/*
输出结果:调用有参构造
调用析构函数
分析:首先此时A(11)是一个匿名对象,调用了有参构造函数,这时将匿名对象进行类型转化转化成a,此时匿名对象就是a,生命周期和a相同
*/
A a = 11;
//2.当匿名对象有等待初始化的对象接的时候,只调用一次构造和析构函数,和上面的情况差不多
A b = A(12);
//3.当匿名对象有已经初始化的对象接的时候
A c(12);
//此处为赋值,此处的匿名对象会调用一次构造函数
/*
输出结果:调用有参构造
调用有参构造
调用析构函数
13
调用析构函数
分析:首先这就不是一个普通的初始化匿名对象了,因为匿名对象赋值的是一个已经初始化的对象,首先A c(12);会调用有参构造,其次A(13)会调用有参构造,此时的(=)是一个赋值的操作,但是不会调用拷贝构造,当A(13)执行完代码之后,调用析构,结束匿名对象的生命周期,此时匿名对象的值赋值给对象c,随后c调用析构,结束程序
总结:所以当匿名对象赋值给一个已经初始化的对象的时候,匿名对象在执行完函数体后就会自动释放,这时候不是普通的赋值,是一种特殊的赋值,不会调用拷贝构造函数,但是会将匿名对象内成员变量的值赋值给有名对象
*/
c = A(13);
c.show();
}
例子2:看看匿名对象的生命周期
class Cat
{
public:
Cat()
{
cout<<"Cat类 无参构造函数"<<endl;
}
Cat(Cat& obj)
{
cout<<"Cat类 拷贝构造函数"<<endl;
}
~Cat()
{
cout<<"Cat类 析构函数 "<<endl;
}
};
void playStage() //一个舞台,展示对象的生命周期
{
Cat(); /*在执行此代码时,利用无参构造函数生成了一个匿名Cat类对象;执行完此行代码,
因为外部没有接此匿名对象的变量,此匿名又被析构了*/
Cat cc = Cat(); /*在执行此代码时,利用无参构造函数生成了一个匿名Cat类对象;然后将此匿名变 成了cc这个实例对象*/
}
int main()
{
playStage();
system("pause");
return 0;
}
产生匿名对象的三种情况
以值的方式给函数传参
类型转换
函数需要返回一个对象
我们来看一个例子:在代码中给出了运行结果和解释,小伙伴们可以赋值代码到编译器中自己运行调试一下看看具体的过程
#define _CRT_SECURE_NO_WARNINGS
#include<iostream> //引入头文件
#include<algorithm>
using namespace std; //标准命名空间
//键值对的定义
template <class T1, class T2>
struct pair
{
typedef T1 first_type;
typedef T2 second_type;
T1 first;
T2 second;
pair() :first(T1()), second(T2()) {}
pair(const T1& a, const T2& b) :first(a),second(b){}
};
//匿名对象产生的三种情况
class Maker
{
public:
Maker()
{
cout << "调用无参构造函数" << endl;
this->a = 0;
}
Maker(int a)
{
cout << "调用有参构造函数" << endl;
this->a = a;
}
Maker(const Maker& maker)
{
cout << "调用拷贝构造函数" << endl;
this->a = maker.a;
}
Maker Makertest1()
{
//执行 return *this; 会产生一个匿名对象,作为返回值
//本质:Maker 匿名对象名 = *this;
//强调一下:如果返回值是引用,则不会产生匿名对象,因为返回的其实是地址,给地址取别名,和对象无关
return *this;
}
Maker Makertest2()
{
//执行 return temp;会先产生一个匿名对象,执行拷贝构造函数,作为返回值,
// 本质:Maker 匿名对象名 = maker1;
//然后释放临时对象temp
Maker temp(2);
return temp;
}
//总结:函数返回值为一个对象(非引用)的时候会产生一个匿名对象,匿名对象根据主函数的操作决定生命周期
Maker& Makertest3()
{
//执行 return temp;不会产生匿名对象,而是会将temp的地址先赋值到引用中,
//在释放temp的内存,此时Point&得到是一个脏数据,是非法的,因为temp在函数结束的时候被释放了,此时地址非法
Maker temp(3);
return temp;
}
~Maker()
{
cout << "调用析构函数" << endl;
this->a = 0;
}
private:
int a;
};
//1.以值的方式给函数传参
/*
让我们看看本质:
输出结果:调用无参构造函数
调用拷贝构造函数
调用析构函数
调用析构函数
为什么会有这样的结果呢?首先main函数调用test01,进入函数体,调用Maker m1;会调用无参构造函数,然后
调用func函数,在func函数传参的过程中发生了Maker m = m1;会调用拷贝构造,然后func函数结束,m调用析构,test01结束,m1调用析构
我们看到了调用了拷贝构造函数,在传参的时候创建了临时对象m;对m的修改不会影响原来对象,这是第一种产生临时对象的情况,所以我们传参的时候尽量传入对象的引用
*/
void func(Maker m)//本质 Maker m = m1;
{
}
void test01()
{
Maker m1;
func(m1);
}
//2.类型转换,生成临时对象
/*
让我们看看本质:
输出结果:
调用无参构造函数
调用析构函数
为什么会出现这种结果呢?因为用做类型转换的时候,实际上调用的是Maker()这个匿名对象的构造函数,
此时匿名对象会直接转换成新对象maker2,此时Maker()的生命周期就是maker2的生命周期
*/
void test02()
{
//生成一个匿名对象,因为用来初始化同类型的对象,这个匿名对象会直接转化成新对象,减少资源消耗
Maker maker2 = Maker();
}
//3.函数需要返回一个对象
void test3()
{
/*
测试1:Makertest1()
运行结果:调用有参构造函数
调用拷贝构造函数
调用析构函数
调用函数
分析:首先调用Maker(2)创建匿名对象,调用有参构造,这时候=不是赋值,而是初始化匿名对象,这一点要注意,其次调用函数Makertest1(),函数的返回值return *this;此时会发生拷贝构造 Maker 匿名对象 = *this;
匿名对象调用拷贝构造拷贝this中的内容,所以此时会输出调用拷贝构造函数,函数Makertest1()返回的是一个匿名对象,所以Maker m1 = Maker(2).Makertest1()本质上就是Maker m1 = 匿名对象,注意此时的匿名对象是新生成的
而不是原来的Maker(2),所以原来的Maker(2)在执行完函数之后会调用析构函数,赋值给Maker m1不是原来的Maker(2)的那个匿名对象,而是一个新的匿名对象,新的匿名对象和m1绑定在一起,生命周期一致
*/
//Maker m1 = Maker(2).Makertest1();
/*
测试2:Makertest2()
运行结果:调用有参构造
调用有参构造
调用拷贝构造函数
析构
析构
析构
分析:首先调用Maker(2)调用有参构造,初始化匿名对象,随后调用Makertest2()函数,进入函数体内,又创建了一个对象tmp,所以又调用了一次有参构造,当把对象return的时候,发生了Maker 匿名对象 = tmp,所以调用了拷贝构造,此时重新生成了一个匿名对象,当函数Makertest2()结束的时候tmp析构,当Maker(2).Makertest2()执行完毕,匿名对象Maker(2)析构,当test03结束,m2析构
*/
//Maker m2 = Maker(2).Makertest2();
/*
测试3:Makertest3()
运行结果:调用有参构造
调用有参构造
析构
调用拷贝构造
析构
析构
分析:首先调用Maker(2)调用有参构造,初始化匿名对象,随后调用Makertest3()函数,进入函数体,函数体内创建了一个对象tmp,所以又调用了一次有参构造,此时return tmp,返回的是引用:Maker &a = tmp;此时a是一个真实的对象,而不是匿名对象,因为是对tmp对象的引用,此时函数Makertest3()函数执行完毕,tmp作为局部变量被释放,调用了析构,此时Maker(2).Makertest3()返回了对象a,Maker m3 = Maker(2).Makertest3()-->Maker m3 = a;所以调用了拷贝构造,Maker(2).Makertest3()执行完毕之后,Maker(2)始终都是匿名对象,Maker(2).Makertest3()执行完毕之后,Maker(2)生命周期走到了尽头,调用析构,test3执行完毕,m3调用析构
*/
Maker m3 = Maker(2).Makertest3();
cout << "hh" << endl;
}
int main() {
//test01();
//test02();
test3();
system("pause");
}
键值对
键值对: 用来表示具有一一对应关系的一种结构,该结构中一般只包含两个成员变量key和value,key代表键值,value表示与key对应的信息
键值对的定义
STL中键值对定义如下:
//键值对的定义
template <class T1, class T2>
struct pair
{
typedef T1 first_type;
typedef T2 second_type;
T1 first;
T2 second;
pair() :first(T1()), second(T2()) {}
pair(const T1& a, const T2& b) :first(a), second(b){}
};
键值对创建
方法一: pair<T1, T2>(x, y) 使用构造函数的方式构造一个匿名对象
方法二: make_pair(x, y) 是一个函数模板,其中返回的是一个pair的匿名对象
//函数模板
template <class T1, class T2>
pair<T1, T2> make_pair(T1 x, T2 y)
{
return (pair<T1, T2>(x, y));
}
举个例子:
void test()
{
// pair<T1, T2>(T1(), T2()) 通过构造函数构造一个匿名对象
// make_pair(T1() , T2()) 是一个模板函数,返回的是pair的匿名对象,用起来更方便
pair<int, int>(1, 1);
make_pair(1, 1);
}
set
概述
- set容器时关联式容器,容器自身有规则,通过键值(key)排序,set不像map那样,同时拥有key和value(pair),set的元素既是键值也是实值,set不允许两个元素有两个元素有相同的键值
- set容器和multiset容器的区别就是multiset允许有相同的元素,而在set容器中不允许相同元素的实现
- 在set中,元素的value也标识它(value就是key,类型为T),并且每个value必须是唯一的。set中的元素不能在容器中修改(元素总是const),但是可以从容器中插入或删除它们
- 数据结构:二叉搜索树
- 迭代器:双向迭代器
- 常用api:
- 构造
- 赋值
- 大小
- 插入和删除
- 查找
- 改变规则:默认是从小到大,改变规则,加入谓词到<>第二个参数中
- 注意:
- set容器插入相同元素的时候,不会报错,但是不插入数据
- set容器存储对象的时候,需要告诉set容器的规则
set中常用的接口
构造函数
set<T> st;//set默认的构造函数,构造空的set容器
set(const set& st);//拷贝构造函数
大小和容量
size();//返回容器中元素的数目
empty();//判断容器是否为空
插入和删除
pair<iterator,bool> insert(const value_type& val);//插入元素,返回值是键值对,其中如果第二个参数为true,那么第一个参数是插入元素的迭代器的位置,为false的话,第一个参数就是已经存在元素的迭代器的位置
clear();//清除所有元素
erase(iterator position);//删除pos迭代器所指的元素,返回下一个元素的迭代器
erase(begin,end);//删除区间[begin,end)的所有元素,返回下一个元素的迭代器
erase(elem);//删除容器中值为elem的元素
查找
这里只介绍find一个,find 查找某个元素。这里find的时间复杂度为O(logN),比算法中的find(时间复杂是O(N))更高效,所以set容器一般使用自己的find进行查找
iterator find(const value_type& val) const;//查找键val是否存在,若存在,返回该键的元素的迭代器;若不存在,返回set.end()
1.count(key);//查找键key的元素个数
2.lower_bound(keyElem);//返回第一个key>=keyElem元素的迭代器。
3.upper_bound(keyElem);//返回第一个key>keyElem元素的迭代器。
equal_range(keyElem);//返回容器中key与keyElem相等的上下限的两个迭代器
实例演示1:插入、删除、查找和迭代器遍历
void test_set1()
{
set<int> s;
s.insert(5);
s.insert(1);
s.insert(6);
s.insert(3);
s.insert(6);
s.insert(s.begin(), 10);
set<int>::iterator pos = s.find(15);// 底层是搜索二叉树,时间复杂度是O(logN)
// set<int>::iterator pos = find(s.begin(), s.end(), 3);// 遍历查找,时间复杂度是O(N)
if (pos != s.end())
{
// cout << *pos << endl;
s.erase(pos);// 没有会报错
}
//s.erase(1); // 没找到不会报错
set<int>::iterator it = s.begin();
while (it != s.end())
{
cout << *it << " ";
++it;
}
cout << endl;
for (auto e : s)
{
cout << e << " ";
}
cout << endl;
}
运行结果如下:

实例演示2:算法中的find和set中的find进行效率比较
void test_set2()
{
srand((size_t)time(nullptr));
set<int> s;
for (size_t i = 0; i < 10000; ++i)
{
s.insert(rand());
}
cout << "个数:" << s.size() << endl;
int begin1 = clock();
for (auto e : s)
{
s.find(e);
}
int end1 = clock();
int begin2 = clock();
for (auto e : s)
{
find(s.begin(), s.end(), e);
}
int end2 = clock();
cout << "用时1:" << end1 - begin1 << "ms" << endl;
cout << "用时2:" << end2 - begin2 << "ms" << endl;
}
运行结果如下:

map
概述
- map是关联容器,它按照特定的次序(按照key来比较)存储由键值key和值value组合而成的元素,也就是说map所有的元素都是pair,pair第一个元素被视为key值,第二个value值,map中不允许两个元素有相同的key值
- 在内部,map中的元素总是按照键值key进行比较排序的
- map支持下标访问符,支持operator[],即在[]中放入key,就可以找到与key对应的value
- 我们可以通过map迭代器改变map的键值吗?答案是不可以的,因为map的键值关系到map元素的排序规则,任意改变map值将会严重破坏map组织,如果想要修改value值,当然是可以的
- 数据结构:平衡二叉搜索树(红黑树)
- map和multimap容器的区别是multimap允许有相同元素
- 常用的api:
- 构造函数
- 赋值
- 大小
- 查找
- 插入
- 删除
map常用的接口
构造函数
map<T1,T2> mapTT;//map默认构造函数,构造一个空的map容器
map(const map& mp);//拷贝构造函数
大小和容量
size();//返回容器中元素的数目
empty();//判断容器是否为空
插入和删除
pair<iterator,bool> insert (const value_type& x );//返回的是一个键值对,插入元素,其中如果第二个参数为true,那么第一个参数是插入元素的迭代器的位置,为false的话,第一个参数就是已经存在元素的迭代器的位置
map<int,string> mapStu;
// 第一种通过pair的方式插入对象
mapStu.insert(pair<int,string>(3, "小张"));
// 第二种通过
pair的方式插入对象mapStu.inset(make_pair(-1, "校长"));
// 第三种通过
value_type的方式插入对象mapStu.insert(map<int,string>::value_type(1,"小李"));
// 第四种通过数组的方式插入值
mapStu[3] = "小刘";
mapStu[5] = "小王";
clear();//删除所有元素
erase(iterator position);//删除pos迭代器所指的元素,返回下一个元素的迭代器
erase(begin,end);//删除区间[begin,end)的所有元素,返回下一个元素的迭代器
erase(elem);//删除容器中值为elem的元素
查找
find(key);//查找键key是否存在,若存在,返回该键的元素的迭代器;若不存在,返回map.end()
count(keyElem);//返回容器中key为keyElem的对组个数,对map来说,要么是0,要么是1;对multimap来说,值可能大于1
lower_bound(keyElem);//返回第一个key>=keyElem元素的迭代器
upper_bound(keyElem);//返回第一个key>keyElem元素的迭代器
equal_range(keyElem);//返回容器中key与keyElem相等的上下限的两个迭代器
operator[] (重点)
operator[]函数的定义如下
mapped_type& operator[] (const key_type& k)
{
return (*((this->insert(make_pair(k,mapped_type()))).first)).second;
}
//通俗点介绍[]的功能,[]在底层其实是一个insert操作,而上面介绍过,insert返回的pair<iterator,bool>,如果插入成功,那么第一个参数就是插入元素迭代器的位置,如果插入失败,那么第一个参数就是已经存在元素的迭代器的位置,所以(*((this>insert(make_pair(k,mapped_type()))).first)).second简化一下就是( *(pair <iterator,bool> .first)).second,pair <iterator,bool>.first代表取出pair中的迭代器iterator,(*(pair <iterator,bool> .first)).second简化一下就是(*iterator).second,而 *iterator指向的又是一个pair元素,也就是键为k的那个迭代器,取这个pair的second,也就是value值,返回这个value值的引用,返回引用就可以对value值实现直接的修改和访问,这样大家应该就理解了这么一大段代码是什么意思了吧
其中,mapped_type是KV模型中V的类型,也就是返回value值的引用。我们可以对这个value进行修改。
分析:((this->insert(make_pair(k,mapped_type()))).first这是一个迭代器,迭代器指向键值对中的第二个元素就是value。所以operato[]的底层是用到了插入,同时可以对value进行修改和访问。
总结: operator[]的三个用处:插入、修改和访问
实例演示:
实例1 用map统计水果个数,以下用了3种方式,同时还对operator的几种作用进行了说明
void test_map2()
{
map<string, int> Map;
string fruitArray[] = { "西瓜","桃子","香蕉","桃子","苹果","西瓜", "香蕉","苹果", "香蕉","西瓜","桃子", "西瓜", "西瓜","桃子",
"桃子", "桃子", "西瓜","桃子","香蕉","桃子","苹果","西瓜" };
//方法一
for (auto& e : fruitArray)
{
map<string, int>::iterator ret = Map.find(e);
//判断是否找到了
if (ret != Map.end())
{
//注意此时迭代器指向的是pair元素
//找到了,说明容器里有,第二个参数加1即可
++ret->second;
}
else
{
//没有就插入,第二个参数记作1
Map.insert(make_pair(e, 1));
}
}
//方法二
for (auto& e : fruitArray)
{
// Map无此元素,pair的第一个参数返回新的迭代器,第二个参数返回true
// Map有此元素,pair的第一个参数返回旧的迭代器,第二个参数返回false
pair<map<string, int>::iterator, bool> ret = Map.insert(make_pair(e, 1));
// 插入失败,只需要++value即可
if (ret.second == false)
{
++ret.first->second;
}
}
// 方法三
for (auto& e : fruitArray)
{
// mapped_type& operator[] (const key_type& k) ;
// mapped_type& operator[] (const key_type& k) { return (*((this->insert(make_pair(k,mapped_type()))).first)).second; }
// ((this->insert(make_pair(k,mapped_type()))).first 迭代器
// (*((this->insert(make_pair(k,mapped_type()))).first)).second 返回value的值的引用 operator[]的原型
Map[e]++;// 有插入、查找和修改的功能 返回value的值的引用
}
Map["梨子"];// 插入
Map["梨子"] = 5;// 修改
cout << Map["梨子"] << endl;// 查找 一般不会用 operator[] 来进行查找,因为没找到会进行插入
Map["哈密瓜"] = 3;// 插入+修改
for (auto& e : Map)
{
cout << e.first << ":" << e.second << endl;
}
}
运行结果如下:

实例2: 测试map的插入、删除和迭代器的使用
void test_map1()
{
map<int, int> m;
// 键值对
// pair<T1, T2>(T1(), T2()) 通过构造函数构造一个匿名对象
// make_pair(T1() , T2()) 是一个模板函数,返回的是pair的匿名对象,用起来更方便
//m.insert(pair<int, int>(1, 1));
m.insert(make_pair(1, 1));
m.insert(pair<int, int>(2, 2));
m.insert(pair<int, int>(3, 3));
m.insert(pair<int, int>(4, 4));
map<int, int>::iterator it = m.begin();
while (it != m.end())
{
// *it 返回 值得引用
cout << (*it).first << ":" << (*it).second << endl;
// it-> 返回 值的地址 -> 解引用访问两个元素
// cout << it->first << ":" << it->second << endl;
++it;
}
// e是自定义类型,传引用防止有拷贝构造发生
for (auto& e : m)
{
cout << e.first << ":" << e.second << endl;
}
}
运行结果如下:

multiset
概述
- multiset是按照特定顺序存储元素的容器,其中元素是可以重复的
- 底层是红黑树,和set特点基本类似,但是multiset可以存放多个key相同的元素
用法
void test_multiset()
{
multiset<int> ms;
// multiset 和 set 的接口基本一致,multiset可以插入重复的
ms.insert(1);
ms.insert(5);
ms.insert(3);
ms.insert(2);
ms.insert(3);
multiset<int>::iterator pos = ms.find(3);// 返回的是第一个3
cout << *pos << endl;
++pos;
cout << *pos << endl;
++pos;
cout << *pos << endl;
++pos;
for (auto e : ms)
{
cout << e << " ";
}
cout << endl;
}
运行结果如下:

multimap
概述
multimaps是关联式容器,它按照特定的顺序,存储由key和value映射成的键值对<key, value>,其中多个键值对之间的key是可以重复的。
底层也是红黑树,和map的性质基本类似
用法
void test_multimap()
{
// multimap 和 map 的区别:可以有相同的key
// 不支持operator[] 因为有多个key时,不知道返回哪个key对应的value的引用
multimap<int, int> mm;
mm.insert(make_pair(1, 1));
mm.insert(make_pair(1, 2));
mm.insert(make_pair(1, 3));
mm.insert(make_pair(2, 1));
mm.insert(make_pair(2, 2));
for (auto& e : mm)
{
cout << e.first << ":" << e.second << endl;
}
}
运行结果如下:

红黑树封装map和set
这里是我关于红黑树的博客——数据结构高阶--红黑树(图解+实现) - 一只少年AAA - 博客园 (cnblogs.com)
对红黑树进行改造
红黑树节点框架:这里和红黑树博客中写的不一样,类变成了结构体,红黑树博客那里没有介绍键值对pair,本文介绍了,所以进行了改进,类和结构体没有本质的区别
enum Color
{
RED,
BLACK
};
template<class T>
struct RBTreeNode
{
RBTreeNode<T>* _left;
RBTreeNode<T>* _right;
RBTreeNode<T>* _parent;
T _data;
Color _color;
RBTreeNode(const T& data, Color color = RED)
:_left(nullptr)
, _right(nullptr)
, _parent(nullptr)
, _data(data)
, _color(color)
{}
};
红黑树框架:
template<class K, class V>
class RBTree
{
typedef RBTreeNode<K, V> Node;
private:
Node* _root = nullptr;
};
这里的红黑树是一个KV模型,我们要用这个红黑树同时封装出map和set两个容器,直接使用这棵红黑树显然是不行的,set属于是K模型的容器,我们要做怎样的改造才能够同时封装出这两个容器呢?
这里我们参考STL源码的处理方式,下面是源码的部分截图:
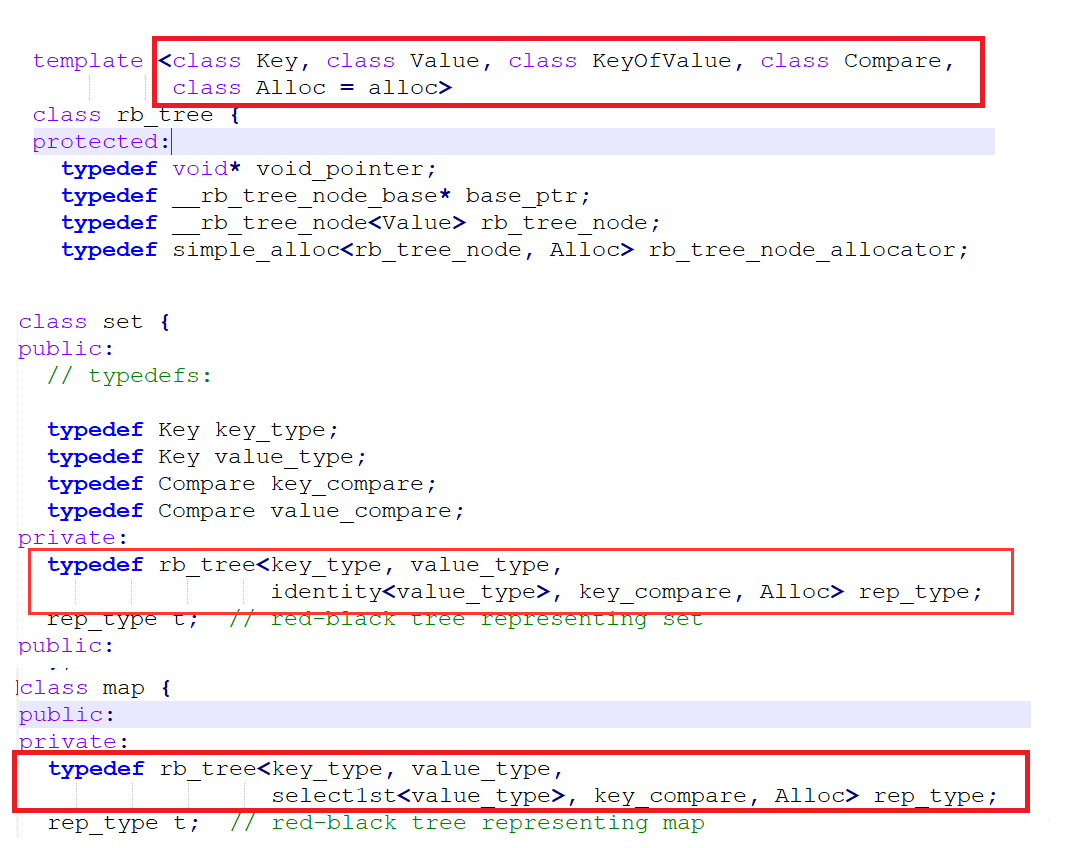
可以看出这里,红黑树的第一个类模板参数和之前是一样的,但是第二个参数value和之前是不一样的,这里的直接把value存放在节点里面,通过map和set构造红黑树可以看出value存的是pair<K, V>或K,对于map而言,value存的是pair<K, V>;对于set而言,value存的是K。所以这里的红黑树暂时可以这样改造:
template <class K,class T>
class RB_Tree
{
// 根据T的类型判断是map还是set 可能是pair<K, V>或K
typedef RBTree_Node<T> Node;
public:
private:
Node* root = nullptr;
};
同时,我们还会发现,上面的红黑树的类模板中有第三个参数是什么呢?
为了获取value中的key值,我们可以让map和set各自传一个仿函数过来,以便获得各自的key值
两个仿函数如下:
template<class K, class V>
class map
{
struct MAPOFV
{
const K& operator()(const pair<K, V>& kv)
{
return kv.first;
}
};
};
template<class K>
class set
{
struct SETOFV
{
const K& operator()(const K& key)
{
return key;
}
};
};
迭代器的实现:
其中operator++就是通过非递归中序遍历的方式走一遍红黑树,走到空就结束
template<class T, class Ptr, class Ref>
struct __rbtree_iterator
{
//typedef __rbtree_iterator<T, T*, T&> iterator;
typedef __rbtree_iterator<T, Ptr, Ref> Self;
typedef RBTreeNode<T> Node;
Node* _node;
__rbtree_iterator(Node* node)
:_node(node)
{}
// 返回值(data)的地址
Ptr operator->()
{
return &_node->_data;
}
// 返回值(data)的引用
Ref operator*()
{
return _node->_data;
}
Self& operator++()
{
// 1.先判断右子树是否为空,不为空就去右子树找最左节点
// 2.右子树为空,去找孩子是其左孩子的祖先
Node* cur = _node;
if (cur->_right)
{
cur = cur->_right;
while (cur->_left)
{
cur = cur->_left;
}
}
else
{
Node* parent = cur->_parent;
while (parent && parent->_right == cur)
{
cur = parent;
parent = parent->_parent;
}
cur = parent;
}
_node = cur;
return *this;
}
Self& operator--()
{
// 1.先判断左子树是否为空,不为空就去左子树找最右节点
// 2.右子树为空,去找孩子是其右孩子的祖先
Node* cur = _node;
if (cur->_left)
{
cur = cur->_left;
while (cur->_right)
{
cur = cur->_right;
}
}
else
{
Node* parent = cur->_parent;
while (parent && parent->_left == cur)
{
cur = parent;
parent = parent->_parent;
}
cur = parent;
}
_node = cur;
return *this;
}
bool operator!=(const Self& s)
{
return _node != s._node;
}
};
红黑树修改后的代码:
#pragma once
#include <iostream>
#include <vector>
#include <time.h>
using namespace std;
enum Color
{
RED,
BLACK
};
template<class T>
struct RBTreeNode
{
RBTreeNode<T>* _left;
RBTreeNode<T>* _right;
RBTreeNode<T>* _parent;
T _data;
Color _color;
RBTreeNode(const T& data, Color color = RED)
:_left(nullptr)
, _right(nullptr)
, _parent(nullptr)
, _data(data)
, _color(color)
{}
};
template<class T, class Ptr, class Ref>
struct __rbtree_iterator
{
typedef __rbtree_iterator<T, Ptr, Ref> Self;
typedef RBTreeNode<T> Node;
Node* _node;
__rbtree_iterator(Node* node)
:_node(node)
{}
// 返回值(data)的地址
Ptr operator->()
{
return &_node->_data;
}
// 返回值(data)的引用
Ref operator*()
{
return _node->_data;
}
Self& operator++()
{
// 1.先判断右子树是否为空,不为空就去右子树找最左节点
// 2.右子树为空,去找孩子是其左孩子的祖先
Node* cur = _node;
if (cur->_right)
{
cur = cur->_right;
while (cur->_left)
{
cur = cur->_left;
}
}
else
{
Node* parent = cur->_parent;
while (parent && parent->_right == cur)
{
cur = parent;
parent = parent->_parent;
}
cur = parent;
}
_node = cur;
return *this;
}
Self& operator--()
{
// 1.先判断左子树是否为空,不为空就去左子树找最右节点
// 2.右子树为空,去找孩子是其右孩子的祖先
Node* cur = _node;
if (cur->_left)
{
cur = cur->_left;
while (cur->_right)
{
cur = cur->_right;
}
}
else
{
Node* parent = cur->_parent;
while (parent && parent->_left == cur)
{
cur = parent;
parent = parent->_parent;
}
cur = parent;
}
_node = cur;
return *this;
}
bool operator!=(const Self& s)
{
return _node != s._node;
}
};
// KOFV是一个仿函数,返回的是对应类型的值 map返回pair中的key set也返回key
template<class K, class T, class KOFV>
class RBTree
{
typedef RBTreeNode<T> Node;// 根据T的类型判断是map还是set 可能是pair<K, V>或K
public:
typedef __rbtree_iterator<T, T*, T&> iterator;
typedef __rbtree_iterator<T, const T*, const T&> const_iterator;
iterator begin()
{
Node* cur = _root;
while (cur && cur->_left)
{
cur = cur->_left;
}
return iterator(cur);
}
iterator end()
{
return iterator(nullptr);
}
iterator begin() const
{
Node* cur = _root;
while (cur && cur->_left)
{
cur = cur->_left;
}
return const_iterator(cur);
}
iterator end() const
{
return const_iterator(nullptr);
}
pair<iterator, bool> Insert(const T& data)
{
if (_root == nullptr)
{
_root = new Node(data, BLACK);// 根节点默认给黑
return make_pair(iterator(_root), true);
}
Node* cur = _root;
Node* parent = nullptr;
KOFV kofv;
while (cur)
{
parent = cur;
if (kofv(data) < kofv(cur->_data))
cur = cur->_left;
else if (kofv(data) > kofv(cur->_data))
cur = cur->_right;
else
return make_pair(iterator(cur), false);;
}
// 节点默认给红节点,带来的影响更小
// 给黑节点的话会影响 每条路径的黑节点相同这条规则
cur = new Node(data);
Node* newnode = cur;
if (kofv(cur->_data) < kofv(parent->_data))
{
parent->_left = cur;
cur->_parent = parent;
}
else
{
parent->_right = cur;
cur->_parent = parent;
}
// 调整颜色
// 情况一:p是红,g是黑,u存在且为红
// 调整后的几种情况:
// 1.如果g为根节点,把g的颜色改成黑,结束;
// 2.如果g不为根节点,
// a.g的父节点为黑,结束;
// b.g的父节点为红,迭代向上调整,继续判断是哪种情况(一和三)
// cur = grandfather;
// father = cur->father;
// 这里不管cur是在p的左边还是右边,都是一样的,关心的是颜色而不是位置
// 情况二:p是红,g是黑,u不存在/u为黑 cur p g 三个是一条直线
// 调整方法(左边为例):1.右单旋 2.把p改成黑,g改成红
// a. u不存在时,cur必定是新增节点
// b. u存在时,cur必定是更新上来的节点
// 情况三:p是红,g是黑,u不存在/u为黑 cur p g 三个是一条折线
// 调整方法(左边为例):1.p左单旋 2.g右单旋 3.把cur改成黑,g改成红
// a. u不存在时,cur必定是新增节点
// b. u存在时,cur必定是更新上来的节点
while (parent && parent->_color == RED)
{
Node* grandfather = parent->_parent;
// 左边
if (grandfather->_left == parent)
{
// 红黑色的条件关键看叔叔
Node* uncle = grandfather->_right;
// u存在且为红
if (uncle && uncle->_color == RED)
{
// 调整 p和u改成黑,g改成红
parent->_color = uncle->_color = BLACK;
grandfather->_color = RED;
// 迭代 向上调整
cur = grandfather;
parent = cur->_parent;
}
else// u存在为黑/u不存在
{
// 折线用一个左单旋处理 1.p左单旋 2.g右单旋 3.把cur改成黑,g改成红 cur p g 三个是一条折线
if (cur == parent->_right)
{
RotateL(parent);
swap(parent, cur);
}
// 直线 cur p g 把p改成黑,g改成红
// 右单旋 有可能是第三种情况
RotateR(grandfather);
parent->_color = BLACK;
grandfather->_color = RED;
}
}
// uncle在左边
else
{
Node* uncle = grandfather->_left;
if (uncle && uncle->_color == RED)
{
parent->_color = uncle->_color = BLACK;
grandfather->_color = RED;
// 迭代 向上调整
cur = grandfather;
parent = cur->_parent;
}
else
{
// 折线用一个右单旋处理 g p cur g变红p边黑
if (cur == parent->_left)
{
RotateR(parent);
swap(parent, cur);
}
// 直线 g p cur 把p改成黑,g改成红
// 左单旋 有可能是第三种情况
RotateL(grandfather);
parent->_color = BLACK;
grandfather->_color = RED;
}
}
}
_root->_color = BLACK;
return make_pair(iterator(newnode), true);
}
bool Erase(const K& key)
{
// 如果树为空,删除失败
if (_root == nullptr)
return false;
KOFV kofv;
Node* parent = nullptr;
Node* cur = _root;
Node* delNode = nullptr;
Node* delNodeParent = nullptr;
while (cur)
{
// 小于往左边走
if (key < kofv(cur->_data))
{
parent = cur;
cur = cur->_left;
}
else if (key > kofv(cur->_data))
{
parent = cur;
cur = cur->_right;
}
else
{
// 找到了,开始删除
// 1.左右子树都为空 直接删除 可以归类为左为空
// 2.左右子树只有一边为空 左为空,父亲指向我的右,右为空,父亲指向我的左
// 3.左右子树都不为空 取左子树最大的节点或右子树最小的节点和要删除的节点交换,然后再删除
if (cur->_left == nullptr)
{
// 要删除节点为根节点时,直接把右子树的根节点赋值给——root
// 根节点的话会导致parent为nullptr
if (_root == cur)
{
_root = _root->_right;
if (_root)
{
_root->_parent = nullptr;
_root->_color = BLACK;
}
return true;
}
else
{
delNode = cur;
delNodeParent = parent;
}
}
else if (cur->_right == nullptr)
{
if (_root == cur)
{
_root = _root->_left;
if (_root)
{
_root->_parent = nullptr;
_root->_color = BLACK;
}
return true;
}
else
{
delNode = cur;
delNodeParent = parent;
}
}
else
{
// 找右子树中最小的节点
Node* rightMinParent = cur;
Node* rightMin = cur->_right;// 去右子树找
while (rightMin->_left)
{
rightMinParent = rightMin;
rightMin = rightMin->_left;
}
//swap(cur->_key, rightMin->_key);
// 替代删除
cur->_data = rightMin->_data;
delNode = rightMin;
delNodeParent = rightMinParent;
}
break;
}
}
// 没找到
if (cur == nullptr)
return false;
// 1.替代节点为红,直接删除(看上面)
// 2.替代节点为黑(只能有一个孩子或两个孩子)
// i)替代节点有一个孩子不为空(该孩子一定为红),把孩子的颜色改成黑
// ii)替代节点的两个孩子都为空
cur = delNode;
parent = delNodeParent;
if (cur->_color == BLACK)
{
if (cur->_left)// 左孩子不为空
{
cur->_left->_color = BLACK;
}
else if (cur->_right)
{
cur->_right->_color = BLACK;
}
else// 替代节点的两个孩子都为空
{
while (parent)
{
// cur是parent的左
if (cur == parent->_left)
{
Node* brother = parent->_right;
// p为黑
if (parent->_color == BLACK)
{
Node* bL = brother->_left;
Node* bR = brother->_right;
// SL和SR一定存在且为黑
if (brother->_color == RED)// b为红,SL和SR都为黑 b的颜色改黑,p的颜色改红 情况a
{
RotateL(parent);
brother->_color = BLACK;
parent->_color = RED;
// 没有结束,还要对cur进行检索
}
else if (bL && bR && bL->_color == BLACK && bR->_color == BLACK)// b为黑,孩子存在
{
// 且孩子也为黑 把brother改成红色,迭代 GP比GU小1 情况b
brother->_color = RED;
cur = parent;
parent = parent->_parent;
}
// bL存在为红,bR不存在或bR为黑 情况e 右旋后变色转为情况d
else if (bL && bL->_color == RED && (!bR || (bR && bR->_color == BLACK)))
{
RotateR(brother);
bL->_color = BLACK;
brother->_color = RED;
}
else if (bR && bR->_color == RED) // 右孩子为红,进行一个左旋,然后把右孩子的颜色改成黑色 情况d
{
RotateL(parent);
swap(brother->_color, parent->_color);
bR->_color = BLACK;
break;
}
else
{
// cur p b 都是黑,且b无孩子,迭代更新
// parent是红就结束
brother->_color = RED;
cur = parent;
parent = parent->_parent;
}
}
// p为红 b一定为黑
else
{
Node* bL = brother->_left;
Node* bR = brother->_right;
if (bL && bR && bL->_color == BLACK && bR->_color == BLACK)// b的孩子全为黑 情况c p变黑,b变红 结束
{
brother->_color = RED;
parent->_color = BLACK;
break;
}
// bL存在为红,bR不存在或bR为黑 情况e 右旋后变色转为情况d
else if (bL && bL->_color == RED && (!bR || (bR && bR->_color == BLACK)))
{
RotateR(brother);
bL->_color = BLACK;
brother->_color = RED;
}
else if (bR && bR->_color == RED) // 右孩子为红,进行一个左旋,然后把右孩子的颜色改成黑色 情况d
{
RotateL(parent);
//swap(brother->_color, parent->_color);
brother->_color = parent->_color;
parent->_color = BLACK;
bR->_color = BLACK;
break;
}
else// cur 为黑,p为红,b为黑 调整颜色,结束
{
parent->_color = BLACK;
brother->_color = RED;
break;
}
}
}
else
{
Node* brother = parent->_left;
// p为黑
if (parent->_color == BLACK)
{
Node* bL = brother->_left;
Node* bR = brother->_right;
// SL和SR一定存在且为黑
if (brother->_color == RED)// b为红,SL和SR都为黑 b的颜色改黑,p的颜色改红 情况a
{
RotateR(parent);
brother->_color = BLACK;
parent->_color = RED;
// 没有结束,还要对cur进行检索
}
else if (bL && bR && bL->_color == BLACK && bR->_color == BLACK)// b为黑,孩子存在
{
// 且孩子也为黑 把brother改成红色,迭代 GP比GU小1 情况b
brother->_color = RED;
cur = parent;
parent = parent->_parent;
}
// 右孩子存在且为红,但左孩子不存在或为黑 情况e 右旋后变色转为情况d
else if (bR && bR->_color == RED && (!bL || (bL && bL->_color == BLACK)))
{
RotateL(brother);
brother->_color = RED;
bR->_color = BLACK;
}
else if (bL && bL->_color == RED) // 左孩子为红,进行一个右旋,然后把左孩子的颜色改成黑色 情况d
{
RotateR(parent);
swap(brother->_color, parent->_color);
bL->_color = BLACK;
break;
}
else
{
// cur p b 都是黑,且b无孩子,迭代更新
// if (parent == _root) // p是根节点,把b变红 否则迭代
brother->_color = RED;
cur = parent;
parent = parent->_parent;
}
}
// p为红 b一定为黑
else
{
Node* bL = brother->_left;
Node* bR = brother->_right;
if (bL && bR && bL->_color == BLACK && bR->_color == BLACK)// b的孩子全为黑 情况c p变黑,b变红 结束
{
brother->_color = RED;
parent->_color = BLACK;
break;
}
// 右孩子存在且为红,但左孩子不存在或为黑 情况e 右旋后变色转为情况d
else if (bR && bR->_color == RED && (!bL || (bL && bL->_color == BLACK)))
{
RotateL(brother);
brother->_color = RED;
bR->_color = BLACK;
}
else if (bL && bL->_color == RED) // 左孩子为红,进行一个右旋,然后把左孩子的颜色改成黑色 情况d
{
RotateR(parent);
// swap(brother->_color, parent->_color);
brother->_color = parent->_color;
parent->_color = BLACK;
bL->_color = BLACK;
break;
}
else// cur 为黑,p为红,b为黑 调整颜色,结束
{
parent->_color = BLACK;
brother->_color = RED;
break;
}
}
}
}
}
}
delNodeParent = delNode->_parent;
// 删除
if (delNode->_left == nullptr)
{
if (delNodeParent->_left == delNode)
delNodeParent->_left = delNode->_right;
else
delNodeParent->_right = delNode->_right;
if (delNode->_right)// 右不为空,就让右节点的父指针指向delNodeParent
delNode->_right->_parent = delNodeParent;
}
else
{
if (delNodeParent->_left == delNode)
delNodeParent->_left = delNode->_left;
else
delNodeParent->_right = delNode->_left;
if (delNode->_left)// 右不为空,就让右节点的父指针指向delNodeParent
delNode->_left->_parent = delNodeParent;
}
delete delNode;
delNode = nullptr;
return true;
}
iterator Find(const K& key)
{
if (_root == nullptr)
return iterator(nullptr);
KOFV kofv;
Node* cur = _root;
while (cur)
{
// 小于往左走
if (key < kofv(cur->_data))
{
cur = cur->_left;
}
// 大于往右走
else if (key > kofv(cur->_data))
{
cur = cur->_right;
}
else
{
// 找到了
return iterator(cur);
}
}
return iterator(nullptr);
}
bool IsValidRBTree()
{
// 空树也是红黑树
if (_root == nullptr)
return true;
// 判断根节点的颜色是否为黑色
if (_root->_color != BLACK)
{
cout << "违反红黑树的根节点为黑色的规则" << endl;
return false;
}
// 计算出任意一条路径的黑色节点个数
size_t blackCount = 0;
Node* cur = _root;
while (cur)
{
if (cur->_color == BLACK)
++blackCount;
cur = cur->_left;
}
// 检测每条路径黑节点个数是否相同 第二个参数记录路径中黑节点的个数
return _IsValidRBTree(_root, 0, blackCount);
}
int Height()
{
return _Height(_root);
}
private:
// 左单旋
void RotateL(Node* parent)
{
Node* subR = parent->_right;
Node* subRL = subR->_left;
// parent的右指向subR的左
parent->_right = subRL;
if (subRL) subRL->_parent = parent;
Node* ppNode = parent->_parent;
parent->_parent = subR;
subR->_left = parent;
if (ppNode == nullptr)
{
_root = subR;
subR->_parent = nullptr;
}
else
{
if (ppNode->_left == parent)
ppNode->_left = subR;
else
ppNode->_right = subR;
subR->_parent = ppNode;
}
}
// 右单旋
void RotateR(Node* parent)
{
Node* subL = parent->_left;
Node* subLR = subL->_right;
// parent的左指向subL的右
parent->_left = subLR;
if (subLR) subLR->_parent = parent;
Node* ppNode = parent->_parent;
parent->_parent = subL;
subL->_right = parent;
if (ppNode == nullptr)
{
_root = subL;
subL->_parent = nullptr;
}
else
{
if (ppNode->_left == parent)
ppNode->_left = subL;
else
ppNode->_right = subL;
subL->_parent = ppNode;
}
}
bool _IsValidRBTree(Node* root, size_t k, size_t blackCount)
{
// 走到空就判断该条路径的黑节点是否等于blackCount
if (root == nullptr)
{
if (k != blackCount)
{
cout << "违反每条路径黑节点个数相同的规则" << endl;
return false;
}
return true;
}
if (root->_color == BLACK)
++k;
// 判断是否出现了连续两个红色节点
Node* parent = root->_parent;
if (parent && root->_color == RED && parent->_color == RED)
{
cout << "违反了不能出现连续两个红色节点的规则" << endl;
return false;
}
return _IsValidRBTree(root->_left, k, blackCount)
&& _IsValidRBTree(root->_right, k, blackCount);
}
int _Height(Node* root)
{
if (root == nullptr)
return 0;
int leftHeight = _Height(root->_left);
int rightHeight = _Height(root->_right);
return 1 + max(leftHeight, rightHeight);
}
private:
Node* _root = nullptr;
};
总结(改造的几个点):
- 把类模板参数的value存放K或pair<K, V>
- 第三个类模板参数是仿函数,可以获取第二个类模板参数中的key
- 增加了迭代器,重载了operator[],具有STL中map中的operator[]一样的特性
封装map和set
template<class K, class V>
class map
{
struct MAPOFV
{
const K& operator()(const pair<K, V>& kv)
{
return kv.first;
}
};
typedef RBTree<K, pair<K, V>, MAPOFV> RBTree;
public:
// typename 告诉编译器这只是一个名字,暂时不用对模板进行实例化
typedef typename RBTree::iterator iterator;
typedef typename RBTree::const_iterator const_iterator;
iterator begin()
{
return _rbt.begin();
}
iterator end()
{
return _rbt.end();
}
const_iterator begin() const
{
return _rbt.begin();
}
const_iterator end() const
{
return _rbt.end();
}
pair<iterator, bool> insert(const pair<K, V>& kv)
{
return _rbt.Insert(kv);
}
bool erase(const K& key)
{
return _rbt.Erase(key);
}
V& operator[](const K& key)
{
pair<iterator, bool> ret = insert(make_pair(key, V()));
return ret.first->second;
}
private:
RBTree _rbt;
};
---------------------------------------------------------------------------
template<class K>
class set
{
struct SETOFV
{
const K& operator()(const K& key)
{
return key;
}
};
typedef RBTree<K, K, SETOFV> RBTree;
public:
// typename 告诉编译器这只是一个名字,暂时不用堆模板进行实例化
typedef typename RBTree::iterator iterator;
typedef typename RBTree::const_iterator const_iterator;
iterator begin()
{
return _rbt.begin();
}
iterator end()
{
return _rbt.end();
}
const_iterator begin() const
{
return _rbt.begin();
}
const_iterator end() const
{
return _rbt.end();
}
pair<iterator, bool> insert(const K& key)
{
return _rbt.Insert(key);
}
bool erase(const K& key)
{
return _rbt.Erase(key);
}
private:
RBTree _rbt;
};
C++进阶(map+set容器模拟实现)的更多相关文章
- C++进阶-3-6-map/multimap容器
C++进阶-3-6-map/multimap容器 1 #include<iostream> 2 #include<map> 3 using namespace std; 4 5 ...
- C++ map 映照容器
map映照容器的元素数据是一个键值和一个映照数据组成的,键值与映照数据之间具有一一映照的关系. map映照容器的数据结构是采用红黑树来实现的,插入键值的元素不允许重复,比较函数只对元素的键值进行比较, ...
- map映照容器的使用
map映照容器可以实现各种不同类型数据的对应关系,有着类似学号表的功能. 今天在做并查集的训练时,就用上了map映照容器. 题目就不上了,直接讲一下用法.顺便说一下,实现过程是在C++的条件下. #i ...
- map映照容器
//map映照容器是由一个键值和一个映照数据组成的,键值与映照数据之间具有一一映照的关系 //map映照容器的键值不允许重复 ,比较函数值对元素 //的键值进行比较,元素的各项数据可通过键值检索出来 ...
- 统计频率(map映照容器的使用)
问题描述 AOA非常喜欢阅读莎士比亚的诗,莎士比亚的诗中有种无形的魅力吸引着他!他认为莎士比亚的诗中之所以些的如此传神,应该是他的构词非常好!所以AOA想知道,在莎士比亚的书中,每个单词出现的频率各 ...
- POJ 1002 487-3279(map映照容器的使用)
Description Businesses like to have memorable telephone numbers. One way to make a telephone number ...
- zoj 2104 Let the Balloon Rise(map映照容器的应用)
题目链接: http://acm.zju.edu.cn/onlinejudge/showProblem.do?problemCode=2104 题目描述: Contest time again! Ho ...
- zoj 1109 Language of FatMouse(map映照容器的典型应用)
题目连接: acm.zju.edu.cn/onlinejudge/showProblem.do?problemCode=1109 题目描述: We all know that FatMouse doe ...
- map映照容器(常用的使用方法总结)
map映照容器的数据元素是由一个键值和一个映照数据组成的,键值和映照数据之间具有一一对应的关系.map与set集合容器一样,不允许插入的元素的键值重复. /*关于C++STL中map映照容器的学习,看 ...
- C++STL之map映照容器
map映照容器 map映照容器的元素数据是由一个键值和一个映照数据组成的, 键值与映照数据之间具有一一映照关系. map映照容器的数据结构也是采用红黑树来实现的, 插入元素的键值不允许重复, 比较函数 ...
随机推荐
- 分布式存储系统之Ceph集群部署
前文我们了解了Ceph的基础架构和相关组件的介绍,回顾请参考https://www.cnblogs.com/qiuhom-1874/p/16720234.html:今天我们来部署一个ceph集群: 部 ...
- 2022美团Java后端开发春招实习面经
2022美团Java后端开发春招实习面经 一面 1.讲一下计算机网络的五层架构,每层分别有什么协议 五层架构:应用层.运输层.网络层.数据链路层.物理层 2.什么是 Http 协议,各种 Ht ...
- PTA 1126 Eulerian Path
无向连通图,输出每个顶点的度并判断Eulerian.Semi-Eulerian和Non-Eulerian这3种情况,我们直接记录每个点所连接的点,这样直接得到它的度,然后利用深度优先和visit数组来 ...
- 面向对象的照妖镜——UML类图绘制指南
1.前言 感受 在刚接触软件开发工作的时候,每次接到新需求,在分析需求后的第一件事情,就是火急火燎的打开数据库(DBMS),开始进行数据表的创建工作.然而这种方式,总是会让我在编码过程中出现实体类设计 ...
- BigDecimal 用法总结
转载请注明出处: 目录 1.BigDecimal 简介 2.构造BigDecimal的对象 3.常用方法总结 4.divide方法使用 5.setScale 方法使用 6.BigDecimal 数据库 ...
- swoole学习笔记
一.服务端 0. swoole常用的配置项: daemonize = true 守护进程化 worker_num #swoole配置参数 设置启动的Worker进程数: 如 1 个请求耗时 100ms ...
- python深拷贝、浅拷贝
.copy() 浅拷贝 如上图 定义列表A指向一个元素,列表A里面嵌套两层列表分布指向两个元素,定义列表B,列表B=A,列表C浅拷贝列表A 从图上可以看出,列表A和列表B指向的是同一个列表元素,而 ...
- 四、docker容器管理
一.docker容器管理 1.1 容器查看-ps命令 显示本地容器列表,但是默认不显示关闭的容器,只显示运行中的容器,除非加上命令选项 -a 用法:docker ps [-a 显示所有容器,默认只显示 ...
- 一、Django介绍
一.Django介绍 Python下有许多款不同的 Web 框架.Django是重量级选手中最有代表性的一位.许多成功的网站和APP都基于Django.Django 是一个开放源代码的 Web 应用框 ...
- 7.Vue常用属性
1. data:数据属性 在之前的学习中我们已经了解到了data,属性中存放的就是js变量 <script> new Vue({ el: '#app', // data data: { u ...