Spark详解(04) - Spark项目开发环境搭建
类别 [随笔分类]Spark
Spark详解(04) - Spark项目开发环境搭建
Spark Shell仅在测试和验证程序时使用的较多,在生产环境中,通常会在IDEA中编制程序,然后打成Jar包,提交到集群,最常用的是创建一个Maven项目,利用Maven来管理Jar包的依赖。
新建项目
在idea中file — new project,选择Maven
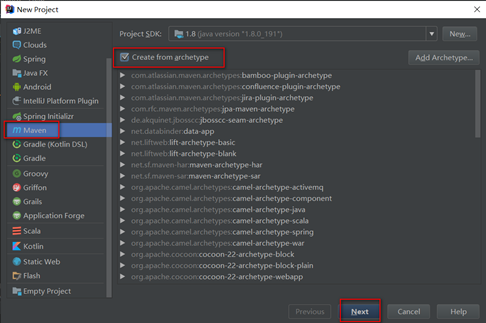
填写gid和aid
下一步点击next
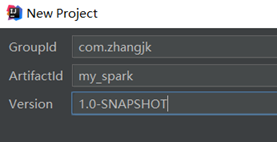
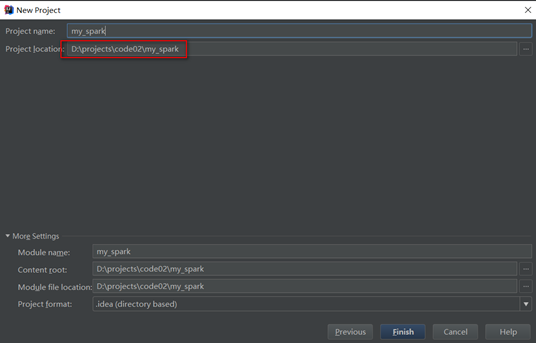
选择项目名以及项目源码储存路径,点击Finish
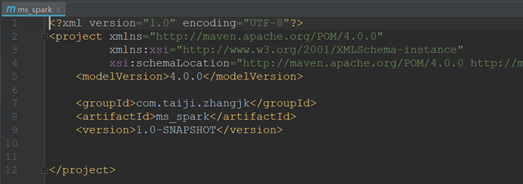
创建完成后会自动打开pom.xml页面
配置环境
配置Maven
选择本地maven路径:file – settings

添加scala的lib和SDK:file – project structure
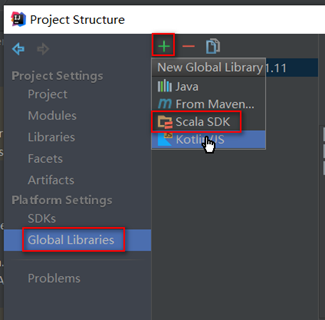


添加成功后在External Libraries下显示scala-sdk
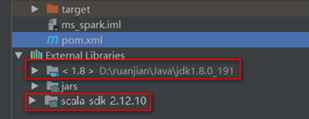
使用maven添加依赖包
本地添加方式和maven方式二者选一即可
在pom中添加spark依赖
- <dependencies>
- <dependency>
- <groupId>org.apache.spark</groupId>
- <artifactId>spark-core_2.12</artifactId>
- <version>3.0.0</version>
- </dependency>
- </dependencies>
Pom中添加打包插件
- <build>
- <finalName>WordCount</finalName>
- <plugins>
- <plugin>
- <groupId>org.apache.maven.plugins</groupId>
- <artifactId>maven-assembly-plugin</artifactId>
- <version>3.0.0</version>
- <configuration>
- <archive>
- <manifest>
- <mainClass>com.zhangjk.WordCount</mainClass>
- </manifest>
- </archive>
- <descriptorRefs>
- <descriptorRef>jar-with-dependencies</descriptorRef>
- </descriptorRefs>
- </configuration>
- <executions>
- <execution>
- <id>make-assembly</id>
- <phase>package</phase>
- <goals>
- <goal>single</goal>
- </goals>
- </execution>
- </executions>
- </plugin>
- </plugins>
- </build>
离线添加本地spark的依赖jar包:file – project structure
本地添加方式和maven方式二者选一即可
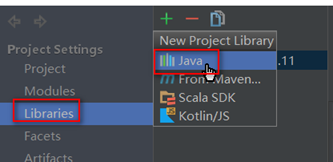
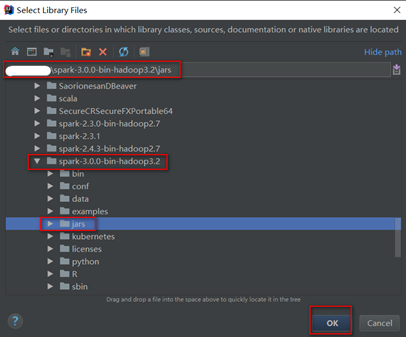
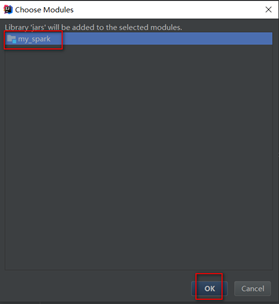
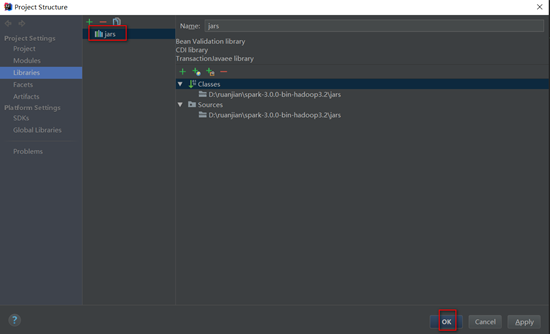
这里添加spark jar包是为了方便本地开发环境运行saprk任务方便调试,可以从本地安装的spark环境中选择,也可以使用maven添加,选择本地文件更方便管理,因为在提交spark任务到yarn集群时由于yarn集群中已经有spark相关依赖,所以在项目打包时需要将spark依赖去掉(不去掉spark任务会运行失败),同时spark之外的其他依赖打包时又不能去掉。本地spark jar包添加完成后会在External Libraries下显示。
除了spark依赖的jar,项目需要的其他依赖可以在pom中添加其他依赖通过maven管理
- 添加其他依赖包
Spark项目中除了spark相关依赖包外的其他依赖包还是需要在打包时放到jar包中的,
在pom.xml中添加相关依赖
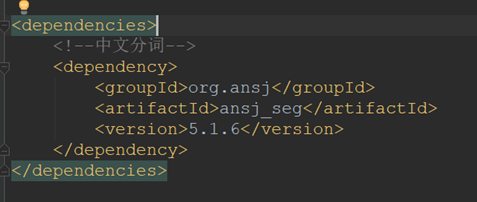
file – project structure
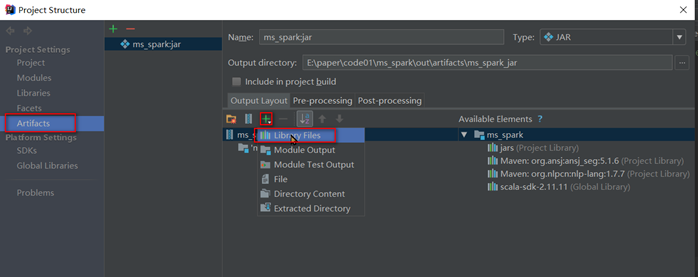
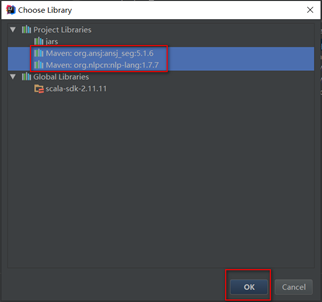
从这里可以看到,spark相关依赖包都在jars目录中,而maven管理的jar包都直接显示出来,所以spark的相关依赖可以选择不使用maven管理

重新bulid项目即可
如果jar包在yarn平台中运行时报 java.lang.ClassNotFoundException: org.ansj.recognition.impl.StopRecognition
意思是程序找不到maven引入的依赖,使用压缩软件打开jar包如下
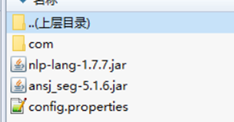
发现只有自己编写的代码是以文件加在jar包中,而引入的jar包则是以jar文件的方式在压缩包中
解决方法如下
使用压缩软件将jar包解压
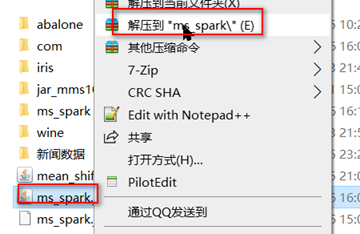
然后将不是依赖包的目录文件删除

然后将所有依赖的jar包再次解压到当前文件夹
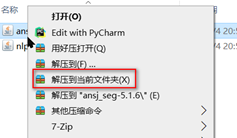
最有将解压后的依赖jar包在压缩到原有的jar包文件中
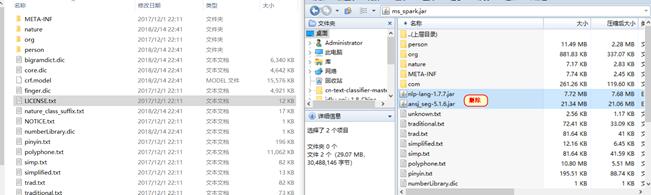
这样在重新提交任务就不会出现找不到类的错误了
这是一种解决方案,ieda在打包时应该可以设置依赖包的打包方式,若有知道的请告知
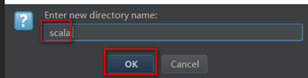
创建scala源码包
Main目录下创建scala目录:在main目录上右键单击

将创建的scala目录转成根目录,在上一步创建的scala目录右键单击
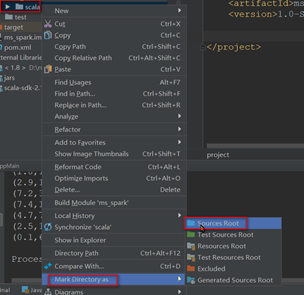
编写wordcount测试程序
在scala目录下新建包名:com.zhangjk
创建伴生对象(Object)WordCount
编写代码
- package com.zhangjk
- import org.apache.spark.rdd.RDD
- import org.apache.spark.{SparkConf, SparkContext}
- object WordCount {
- def main(args: Array[String]): Unit = {
- val conf: SparkConf = new SparkConf()
- //TODO 设置线程数,在本地idea中运行需要设置此参数,打成jar包在yarn集群中运行需要注释该参数设置,
- .setMaster("local[*]")
- .setAppName("WC")
- val sc = new SparkContext(conf)
- sc.setLogLevel("WARN")
- val data = Array("hello scala", "hello word", "hello java", "hello python", "word count")
- val inputRDD = sc.parallelize(data)
- val resultRDD: RDD[(String, Int)] = inputRDD.filter(line => null != line && line.trim.length > 0)
- .flatMap(_.split(" "))
- .mapPartitions(iter => iter.map(_ -> 1))
- .reduceByKey(_ + _)
- resultRDD.coalesce(1)
- .foreachPartition(
- iter=>iter.foreach(println)
- )
- sc.stop()
- }
- }
本地运行调试spark代码
- 检查Spark版本和scala版本是否一致
使用IDEA工具运行运行spark项目时必须保证spark依赖的scala版本和本地安装的版本保持一致,如果不一致会报如下错误
Exception in thread "main" java.lang.NoSuchMethodError: scala.Product.$init$(Lscala/Product;)V

如果确定spark版本和scala版本是否一致
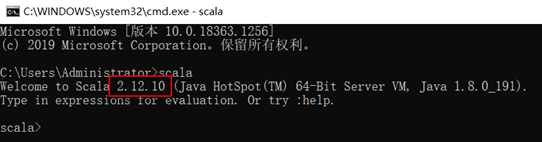
在cmd中运行spark-shell,可以看到spark-3.0.0版本使用的scala版本是2.12.10
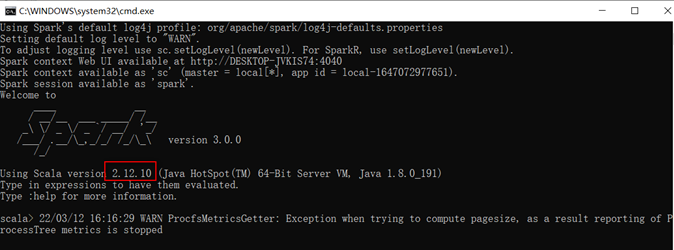
在另一个cmd中输入scala命令可以看到当前使用的scala运行环境是2.12.10,和spark要求的一致,如果不一致,则需要下载对应版本的scala环境安装包重新安装
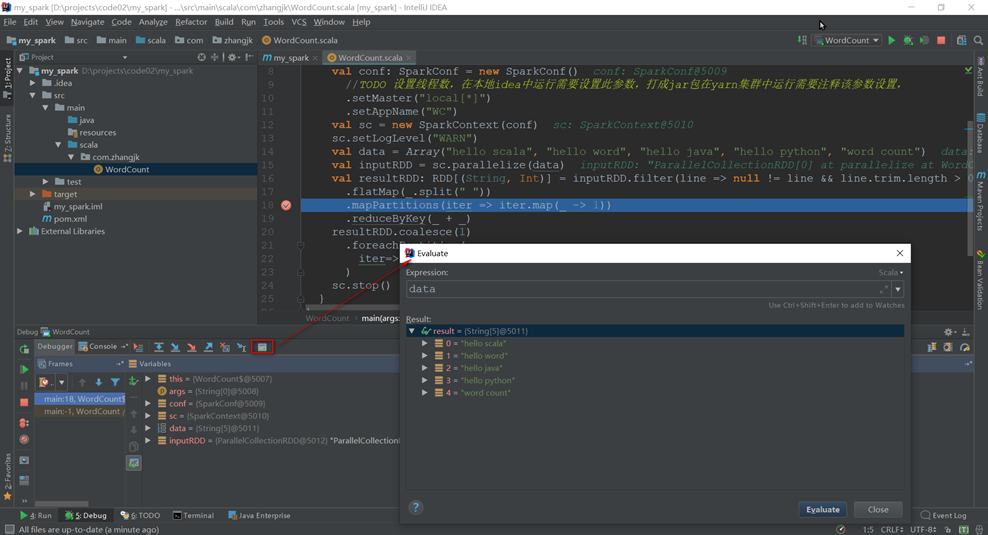
- 本地运行调试
本地Spark程序调试需要使用Local提交模式,即将本机当做运行环境,Master和Worker都为本机。运行时直接加断点调试即可
本地调试流程
打包并提交到yarn平台运行
打包
- 使用artifacts打包
新建build

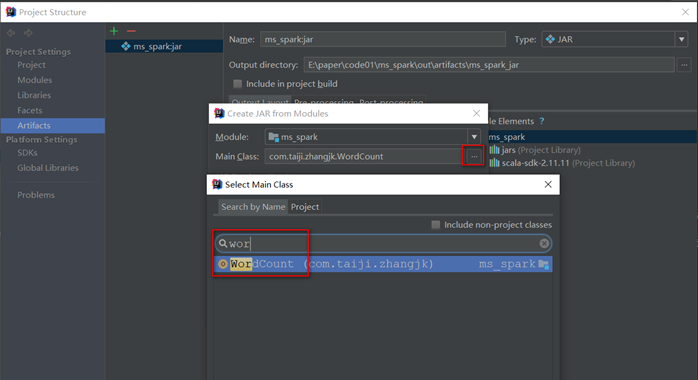
选择运行的主类
无论是否指定都需要在提交spark任务时使用--class com.taiji. WordCount参数设置jar包运行的主类
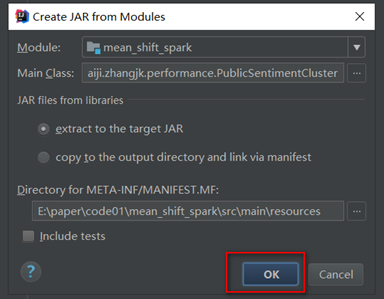
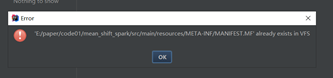
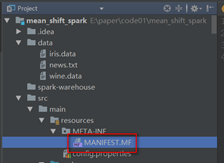
若出现下面的错误,删除MANIFEST.MF
由于spark程序部分依赖包服务器上已有,需要手工将spark的相关依赖jar包删除。
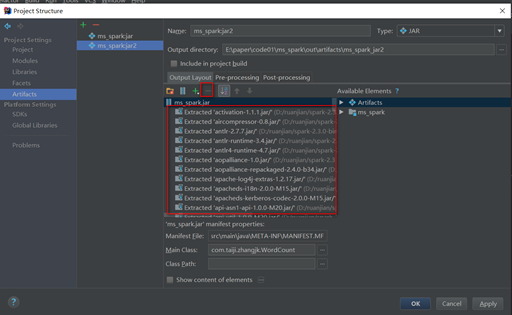
如果是新建项目,并且按照上面的方式添加的spark依赖,把所有的都删除,只保留最后一个,然后再按照项目需要再pom中添加其他依赖

保存配置
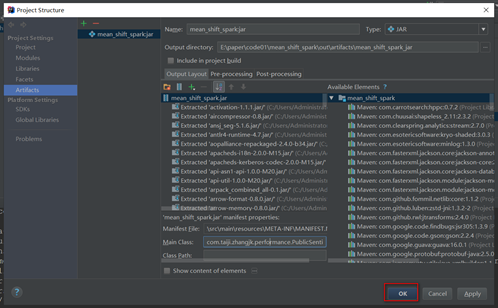
编译打包

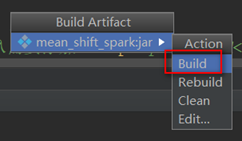
最终生产的jar包

- 使用maven打包
在maven控制台点击package打包,
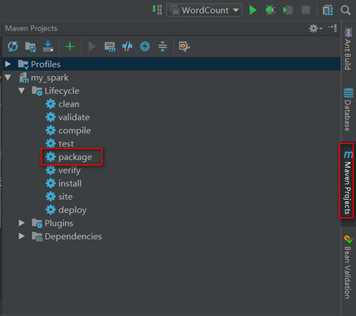
然后,查看打完后的jar包

其中:
WordCount.jar是不带依赖的jar包,在提交任务时,由于服务器上已经安装了spark的相关依赖,一般会使用该jar包
WordCount-jar-with-dependencies.jar是带所有依赖的jar包
如果spark程序中引入的依赖除了spark-core之外还有其他依赖,例如zkclient、kafka-clients等,此时对于不带依赖的jar包,服务器上也没有对于的jar包,而带依赖的jar包服务器上又包含了spark依赖的所有jar包,此时在提交任务是无论提交那个jar包都不能正常运行,这是可以使用<scope>provided</scope>将spark依赖的jar包在打包时忽略,这样在WordCount-jar-with-dependencies.jar的jar包中即不包含saprk依赖又还有其他依赖
提交任务
使用spark-submit提交任务,需要注意用户权限,如果是cdh安装的yarn平台,需要切换到spark或hdfs用户执行submit命令 同时存放jar包的目录尽量具有777的权限
如果使用spark 有时候需要访问hdfs文件系统,spark用户也会受到权限限制,这时可以切换到hdfs用户试试
在命令前面添加nohup是后台方式执行,不加即为前台方式启动,连接终端断开任务即停止运行
- 提交spark任务到yarn平台
把jar包上传到服务器/opt/module/spark-yarn目录
执行submit命令
[hadoop@hadoop102 spark-yarn]$ bin/spark-submit --class com.zhangjk.WordCount --master yarn ./WordCount.jar
- spark-submit 详细参数说明
--master master 的地址,提交任务到哪里执行,例如 spark://host:port, yarn, local
--deploy-mode 在本地 (client) 启动 driver 或在 cluster 上启动,默认是 client
--class 应用程序的主类,仅针对 java 或 scala 应用
--name 应用程序的名称
--jars 用逗号分隔的本地 jar 包,设置后,这些 jar 将包含在 driver 和 executor 的 classpath 下
--packages 包含在driver 和executor 的 classpath 中的 jar 的 maven 坐标
--exclude-packages 为了避免冲突
而指定不包含的 package
--repositories 远程 repository
--conf PROP=VALUE 指定 spark 配置属性的值,例如 -conf spark.executor.extraJavaOptions="-XX:MaxPermSize=256m"
--properties-ile 加载的配置文件,默认为 conf/spark-defaults.conf
--driver-memory Driver内存,默认 1G
--driver-java-options 传给 driver 的额外的 Java 选项
--driver-library-path 传给 driver 的额外的库路径
--driver-class-path 传给 driver 的额外的类路径
--driver-cores Driver 的核数,默认是1。在 yarn 或者 standalone 下使用
--executor-memory 每个 executor 的内存,默认是1G
--total-executor-cores 所有 executor 总共的核数。仅仅在 mesos 或者 standalone 下使用
--num-executors 启动的 executor 数量。默认为2。在 yarn 下使用
--executor-core 每个 executor 的核数。在yarn或者standalone下使用
其他常用
关联源码
按住ctrl键,点击RDD

提示下载或者绑定源码

解压资料包中spark-3.0.0.tgz到非中文路径。
点击Attach Sources…按钮,选择源码路径
创建IDEA快捷键
1)点击File->Settings…->Editor->Live Templates->output->Live Template
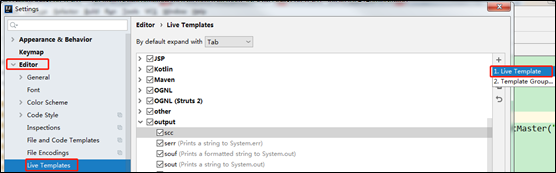
2)点击左下角的Define->选择Scala

3)在Abbreviation中输入快捷键名称scc,在Template text中填写,输入快捷键后生成的内容。
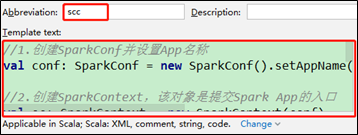
//1.创建SparkConf并设置App名称
val conf: SparkConf =
new SparkConf().setAppName("SparkCoreTest").setMaster("local[*]")
//2.创建SparkContext,该对象是提交Spark App的入口
val sc: SparkContext =
new SparkContext(conf)
//4.关闭连接
sc.stop()
异常处理
idea打jar包缺少class文件(classes目录为空)
将打好的jar包上传到服务器上提交任务时发现报Error: Failed to load class错误,日志如下:
2022-03-13 02:29:38,620 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Error: Failed to load class com.zhangjk.WordCount.
2022-03-13 02:29:38,763 INFO util.ShutdownHookManager: Shutdown hook called
2022-03-13 02:29:38,764 INFO util.ShutdownHookManager: Deleting directory /tmp/spark-35dd8e48-28ec-4ca7-a8ee-45b3eeb0f49e
通过压缩软件打开jar包,发现根本找不到classes目录及class文件
在IDEA中发现打包结果的classes目录也为空:
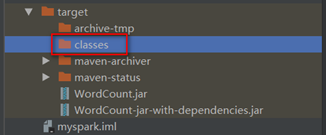
解决方案
现在idea中运行一次项目

运行成功后。
此时target目录下的classes目录出现了对应的class文件:
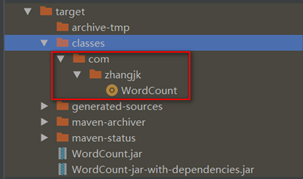
再次点击maven的package命令打包,将打好的jar包再次使用压缩软件打开,可以看到对于的class文件出现了
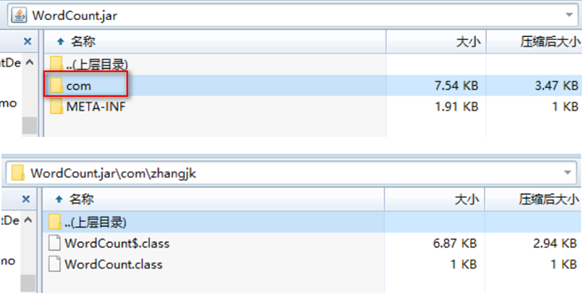
出现这种情况是因为某些原因导致package命令打包不能自动编译。在idea中运行项目会先编译,然后在打包就能把编译后的文件打到jar包中了
缺少Hadoop
如果本机操作系统是Windows,如果在程序中使用了Hadoop相关的东西,比如写入文件到HDFS,则会遇到如下异常:

出现这个问题的原因,并不是程序的错误,而是用到了Hadoop相关的服务,解决办法
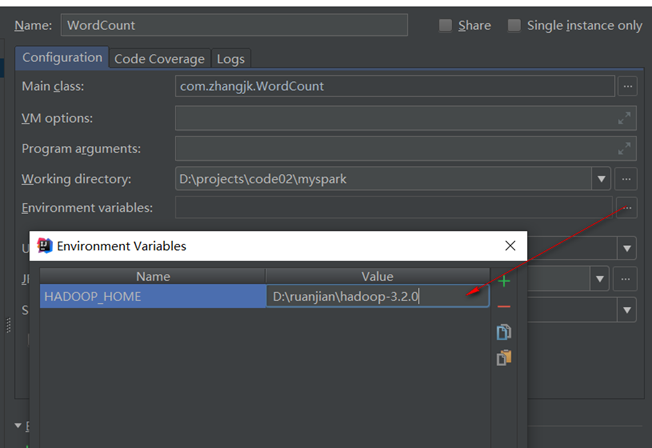
1)配置HADOOP_HOME环境变量
2)在IDEA中配置Run Configuration,添加HADOOP_HOME变量

Spark详解(04) - Spark项目开发环境搭建的更多相关文章
- Hadoop项目开发环境搭建(Eclipse\MyEclipse + Maven)
写在前面的话 可详细参考,一定得去看 HBase 开发环境搭建(Eclipse\MyEclipse + Maven) Zookeeper项目开发环境搭建(Eclipse\MyEclipse + Mav ...
- Hive项目开发环境搭建(Eclipse\MyEclipse + Maven)
写在前面的话 可详细参考,一定得去看 HBase 开发环境搭建(Eclipse\MyEclipse + Maven) Zookeeper项目开发环境搭建(Eclipse\MyEclipse + Mav ...
- unbuntu16.04上python开发环境搭建建议
unbuntu16.04上python开发环境搭建建议 2017-12-20 10:39:27 推荐列表: pycharm: 可以自行破解,但是不推荐,另外也不稳定 pydev+eclipse: ...
- iOS项目——项目开发环境搭建
在开发项目之前,我们需要做一些准备工作,了解iOS扩展--Objective-C开发编程规范是进行开发的必备基础,学习iOS学习--Xcode9上传项目到GitHub是我们进行版本控制和代码管理的选择 ...
- ubuntu16.04 Golang语言开发环境搭建
golang即go语言是跨平台的语言,适用于windows 和linux平台,下面介绍linux平台下ubuntu16.04系统下的开发环境搭建过程. 一.安装开发必备环境 执行下面命令分别安装git ...
- Zookeeper项目开发环境搭建(Eclipse\MyEclipse + Maven)
写在前面的话 可详细参考,一定得去看 HBase 开发环境搭建(Eclipse\MyEclipse + Maven) 我这里,相信,能看此博客的朋友,想必是有一定基础的了.我前期写了大量的基础性博文. ...
- 详解php多人开发环境原理
作为一名php开发人员,有时候一个项目或一个功能我们不能独自完成,就像当一个仓库开发人员大于1,20人的时候,每个人可能开发不同的模块和功能,用代码版本控制工具比如 git 开不同的分支,流程大概是先 ...
- 详解 Webpack+Babel+React 开发环境的搭建
1.认识Webpack 构建应用前我们先来了解一下Webpack, Webpack是一个模块打包工具,能够把各种文件(例如:ReactJS.Babel.Coffeescript.Less/Sass等) ...
- 利用maven开发springMVC项目——开发环境搭建(版本错误解决)
申明:部分内容参见别人的博客,没有任何的商业用途,只是作为自己学习使用.(大佬博客) 一.相关环境 - eclipse :eclipse-jee-oxygen-3-win32-x86_64(下载地址) ...
- Ubuntu 16.04 以太坊开发环境搭建
今天我们来一步一步从搭建以太坊智能合约开发环境. Ubuntu16.04 安装ubuntu16.04.下载链接 //先update一下(或者换国内源再update) sudo apt-get upda ...
随机推荐
- 关于JDK8中stream的用法小总结。
import java.io.Serializable; import java.util.*; import java.util.stream.Collectors; public class Ma ...
- Android自动化测试工具调研
原文地址:Android自动化测试工具调研 - Stars-One的杂货小窝 Android测试按测试方式分类,可分为两种:一种是传统逻辑单元测试(Junit),另外一种则是UI交互页面测试. 这里详 ...
- How to get the return value of the setTimeout inner function in js All In One
How to get the return value of the setTimeout inner function in js All In One 在 js 中如何获取 setTimeout ...
- 基于tauri+vue3.x多开窗口|Tauri创建多窗体实践
最近一种在捣鼓 Tauri 集成 Vue3 技术开发桌面端应用实践,tauri 实现创建多窗口,窗口之间通讯功能. 开始正文之前,先来了解下 tauri 结合 vue3.js 快速创建项目. taur ...
- 微信抢红包小技巧(python模拟100万次)
之前,在网上看到一篇文章,说多人抢红包时,微信红包金额的分配规则是0.01元到当前剩余金额平均数的2倍(最后一个人金额为当前剩下的所有金额),所以写了一个python程序,模拟量一百万次,分析了一下抢 ...
- 13.内建函数eval()
eval函数 eval()函数十分强大 -- 将字符串当成有效的表达式来求值并返回计算结果 例如下图,eval会将字符串的引号去掉并且计算返回结果
- 前后端分离项目(十):实现"改"功能(前后端)
好家伙,本篇介绍如何实现"改" 我们先来看看效果吧 (这可不是假数据哟,这是真数据哟) (忘记录鼠标了,这里是点了一下刷新) First Of All 我们依旧先来理一下思路: ...
- 机器学习中in-domine, out-domine的区别
in-domine 为域内数据,即为训练模型时使用的数据: out-domine 为域外数据,即为检验模型时使用的数据.
- AR空间音频能力,打造沉浸式声音体验
随着元宇宙的兴起,3D虚拟现实广泛引用,让数字化信息和现实世界融合,目前大家的目光主要聚焦于视觉交互层面,为了在虚拟环境中更好的再现真实世界的三维空间体验,引入听觉层面必不可少,空间音频孕育而生. 空 ...
- 洛谷 P4135 作诗 题解
题面. 之前做过一道很类似的题目 洛谷P4168蒲公英 ,然后看到这题很快就想到了解法,做完这题可以对比一下,真的很像. 题目要求区间内出现次数为正偶数的数字的数量. 数据范围1e5,可以分块. 我们 ...