大数据 - DWM层 业务实现
DWM 建表,需要看 DWS 需求。
DWS 来自维度(访客、商品、地区、关键词),为了出最终的指标
ADS 需求指标
DWT 为什么实时数仓没有DWT,因为它是历史的聚集,累积结果,实时数仓中不需要
DWD 不需要加工
DWM 需要加工的数据
| 统计主题 | 需求指标【ADS】 | 输出方式 | 计算来源 | 来源层级 |
|---|---|---|---|---|
| 访客【DWS】 | pv | 可视化大屏 | page_log 直接可求 | dwd |
| UV(DAU) | 可视化大屏 | 需要用 page_log 过滤去重 | dwm | |
| 跳出率 | 可视化大屏 | 需要通过 page_log 行为判断 | dwm | |
| 进入页面数 | 可视化大屏 | 需要识别开始访问标识 | dwd | |
| 连续访问时长 | 可视化大屏 | page_log 直接可求 | dwd | |
| 商品 | 点击 | 多维分析 | page_log 直接可求 | dwd |
| 收藏 | 多维分析 | 收藏表 | dwd | |
| 加入购物车 | 多维分析 | 购物车表 | dwd | |
| 下单 | 可视化大屏 | 订单宽表 | dwm | |
| 支付 | 多维分析 | 支付宽表 | dwm | |
| 退款 | 多维分析 | 退款表 | dwd | |
| 评论 | 多维分析 | 评论表 | dwd | |
| 地区 | PV | 多维分析 | page_log 直接可求 | dwd |
| UV | 多维分析 | 需要用 page_log 过滤去重 | dwm | |
| 下单 | 可视化大屏 | 订单宽表 | dwm | |
| 关键词 | 搜索关键词 | 可视化大屏 | 页面访问日志 直接可求 | dwd |
| 点击商品关键词 | 可视化大屏 | 商品主题下单再次聚合 | dws | |
| 下单商品关键词 | 可视化大屏 | 商品主题下单再次聚合 | dws |
独立访客UV
UV,全称是 Unique Visitor,即独立访客,对于实时计算中,也可以称为 DAU(Daily Active User),即每日活跃用户,因为实时计算中的 UV 通常是指当日的访客数。
那么如何从用户行为日志中识别出当日的访客,那么有两点:
- 是识别出该访客打开的第一个页面,表示这个访客开始进入我们的应用
- 由于访客可以在一天中多次进入应用,所以我们要在一天的范围内进行去重(状态去重)
KeyState min -> state (存日期)
- 获取执行环境
- 读取Kafka dwd_page_log 主题的数据
- 将每行数据转换为JSON对象
- 过滤数据,状态编程 只保留每个 mid 每天第一次登录的数据
- 将数据写入kafka
- 启动任务
过滤思路
- 首先用 keyby 按照 mid 进行分组,每组表示当前设备的访问情况
- 分组后使用 keystate 状态,记录用户进入时间,实现 RichFilterFunction 完成过滤
- 重写 open 方法用来初始化状态
- 重写 filter 方法进行过滤
可以直接筛掉 last_page_id 不为空的字段,因为只要有上一页,说明这条不是这个用户进入的首个页面。
状态用来记录用户的进入时间,只要这个 lastVisitDate 是今天,就说明用户今天已经访问过了所以筛除掉。如果为空或者不是今天,说明今天还没访问过,则保留。
因为状态值主要用于筛选是否今天来过,所以这个记录过了今天基本上没有用了,这里 enableTimeToLive 设定了 1 天的过期时间,避免状态过大。
跳出明细
跳出就是用户成功访问了网站的一个页面后就退出,不在继续访问网站的其它页面。
跳出率就是用跳出次数除以访问次数。
关注跳出率,可以看出引流过来的访客是否能很快的被吸引,渠道引流过来的用户之间的质量对比,对于应用优化前后跳出率的对比也能看出优化改进的成果。
跳出率高不是好事、留存率高是好事
计算跳出行为的思路
首先要识别哪些是跳出行为,要把这些跳出的访客最后一个访问的页面识别出来。那么要抓住几个特征:
- 该页面是用户近期访问的第一个页面
这个可以通过该页面是否有上一个页面(last_page_id)来判断,如果这个表示为空,就说明这是这个访客这次访问的第一个页面。 - 首次访问之后很长一段时间(自己设定),用户没继续再有其他页面的访问。
这第一个特征的识别很简单,保留 last_page_id 为空的就可以了。但是第二个访问的判断,其实有点麻烦,首先这不是用一条数据就能得出结论的,需要组合判断,要用一条存在的数据和不存在的数据进行组合判断。而且要通过一个不存在的数据求得一条存在的数据。更麻烦的他并不是永远不存在,而是在一定时间范围内不存在。那么如何识别有一定失效的组合行为呢?
最简单的办法就是 Flink 自带的 CEP 技术。这个 CEP 非常适合通过多条数据组合来识别某个事件。
用户跳出事件,本质上就是一个条件事件加一个超时事件的组合。
- 获取执行环境
- 读取 Kafka dwd_page_log 主题的数据
- 将每行数据转换为JSON对象,并提取时间戳生成 Watermark
- 定义模式序列
- 将模式序列作用到流上 CEP
- 提取匹配上的和超时事件
- UNION 两种事件
- 将数据写入kafka
- 启动任务
订单宽表
需求分析与思路
订单是统计分析的重要的对象,围绕订单有很多的维度统计需求,比如用户、地区、商品、品类、品牌等等。
为了之后统计计算更加方便,减少大表之间的关联,所以在实时计算过程中将围绕订单的相关数据整合成为一张订单的宽表。
那究竟哪些数据需要和订单整合在一起?
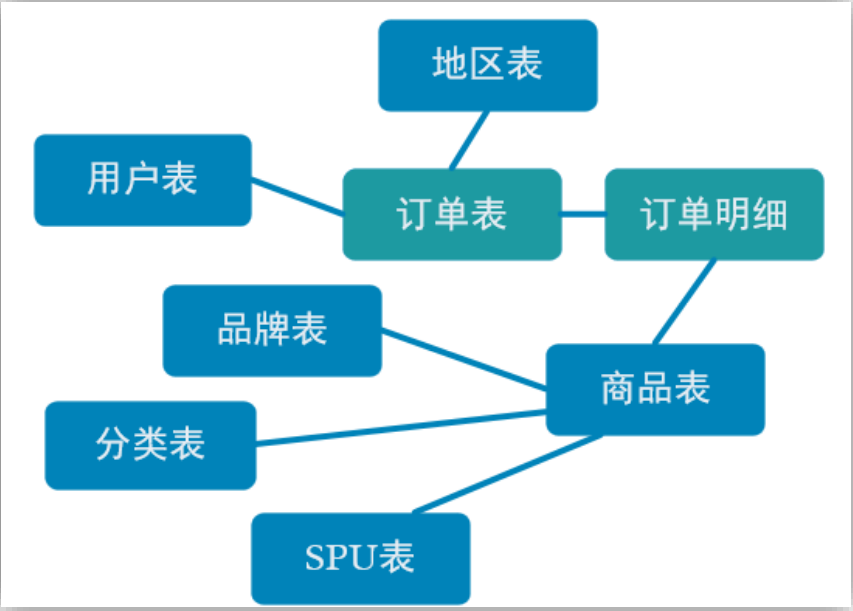
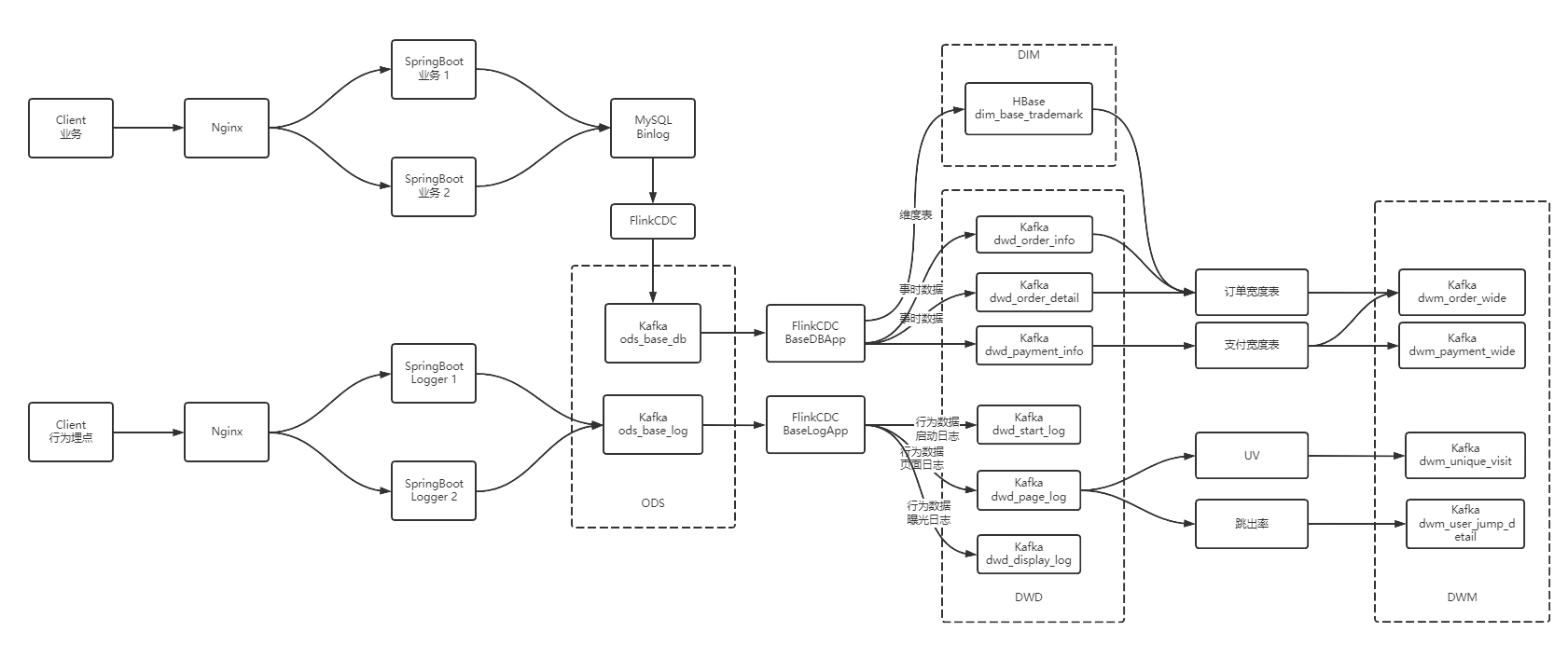
如上图,由于在之前的操作我们已经把数据分拆成了事实数据和维度数据,事实数据(绿色)进入 kafka 数据流(DWD 层)中,维度数据(蓝色)进入 hbase 中长期保存。那么我们在 DWM 层中要把实时和维度数据进行整合关联在一起,形成宽表。那么这里就要处理有两种关联,事实数据和事实数据关联、事实数据和维度数据关联。
- 事实数据和事实数据关联,其实就是流与流之间的关联。
- 事实数据与维度数据关联,其实就是流计算中查询外部数据源。
订单和订单明细关联(双流 join)
https://ci.apache.org/projects/flink/flink-docs-release-1.12/dev/stream/operators/joining.html
在 flink 中的流 join 大体分为两种,一种是基于时间窗口的 join(Time Windowed Join),比如 join、coGroup 等。另一种是基于状态缓存的 join(Temporal Table Join),比如 Interval Join。
这里选用 Interval Join,因为相比较窗口 join,Interval Join 使用更简单,而且避免了应匹配的数据处于不同窗口的问题。Interval Join 目前只有一个问题,就是还不支持 left join。
但是我们这里是订单主表与订单从表之间的关联不需要 left join,所以 intervalJoin 是较好的选择。
- 设定事件时间水位线
- 创建合并后的宽表实体类
- 订单和订单明细关联 intervalJoin
- 获取执行环境
- 读取两个端口数据创建流,并提取时间戳生成 Watermark
- 双流join
- 打印
- 启动任务
维表关联代码实现
维度关联实际上就是在流中查询存储在 HBase 中的数据表。但是即使通过主键的方式查询,HBase 速度的查询也是不及流之间的 join。外部数据源的查询常常是流式计算的性能瓶颈,所以咱们再这个基础上还有进行一定的优化。
- 获取执行环境
- 读取 Kafka dwd_page_log 主题的数据
- 将每行数据转换为JavaBean对象,并提取时间戳生成 Watermark
- 双流join
- 关联维度信息
- 将数据写入kafka
- 启动任务
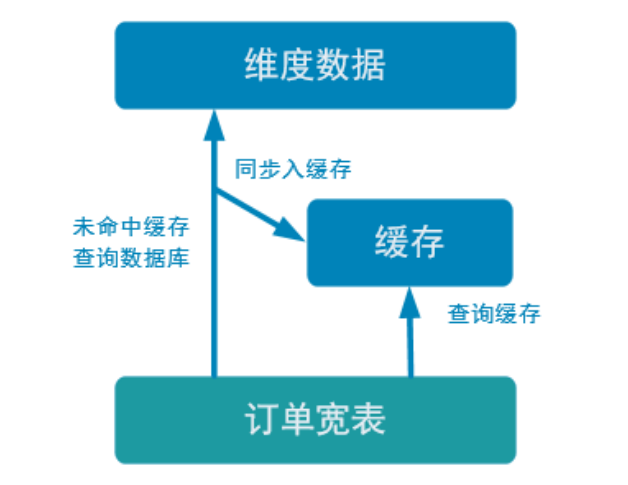
优化-加入旁路缓存模式 (cache-aside-pattern)
我们在上面实现的功能中,直接查询的 HBase。外部数据源的查询常常是流式计算的性能瓶颈,所以我们需要在上面实现的基础上进行一定的优化。我们这里使用旁路缓存。
旁路缓存模式是一种非常常见的按需分配缓存的模式。如下图,任何请求优先访问缓存,缓存命中,直接获得数据返回请求。如果未命中则,查询数据库,同时把结果写入缓存以备后续请求使用。
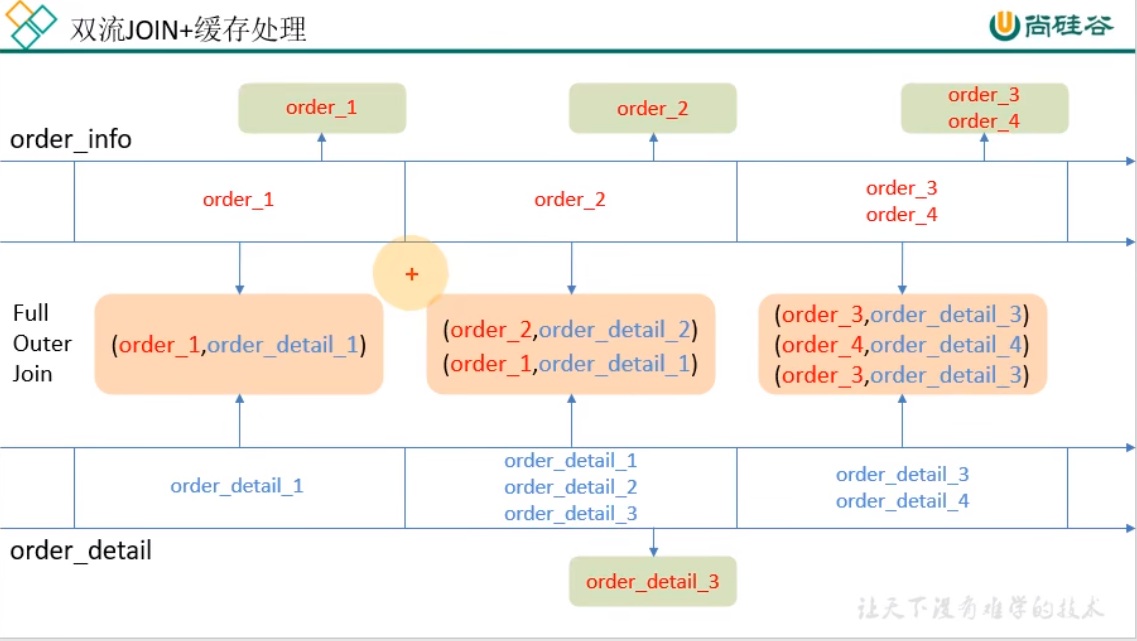
这种缓存策略有几个注意点
缓存要设过期时间,不然冷数据会常驻缓存浪费资源。
要考虑维度数据是否会发生变化,如果发生变化要主动清除缓存。
缓存的选型
一般两种:堆缓存或者独立缓存服务(redis,memcache),
堆缓存,从性能角度看更好,毕竟访问数据路径更短,减少过程消耗。但是管理性差,其他进程无法维护缓存中的数据。
独立缓存服务(redis,memcache)本事性能也不错,不过会有创建连接、网络 IO 等消耗。但是考虑到数据如果会发生变化,那还是独立缓存服务管理性更强,而且如果数据量特别大,独立缓存更容易扩展。
因为咱们的维度数据都是可变数据,所以这里还是采用 Redis 管理缓存。
优化-异步查询
在 Flink 流处理过程中,经常需要和外部系统进行交互,用维度表补全事实表中的字段。例如:在电商场景中,需要一个商品的 skuid 去关联商品的一些属性,例如商品所属行业、商品的生产厂家、生产厂家的一些情况;在物流场景中,知道包裹 id,需要去关联包裹的行业属性、发货信息、收货信息等等。
默认情况下,在 Flink 的 MapFunction 中,单个并行只能用同步方式去交互: 将请求发送到外部存储,IO 阻塞,等待请求返回,然后继续发送下一个请求。这种同步交互的方式往往在网络等待上就耗费了大量时间。为了提高处理效率,可以增加 MapFunction 的并行度,但增加并行度就意味着更多的资源,并不是一种非常好的解决方式。
Flink 在 1.2 中引入了 Async I/O,在异步模式下,将 IO 操作异步化,单个并行可以连续发送多个请求,哪个请求先返回就先处理,从而在连续的请求间不需要阻塞式等待,大大提高了流处理效率。
Async I/O 是阿里巴巴贡献给社区的一个呼声非常高的特性,解决与外部系统交互时网络延迟成为了系统瓶颈的问题。
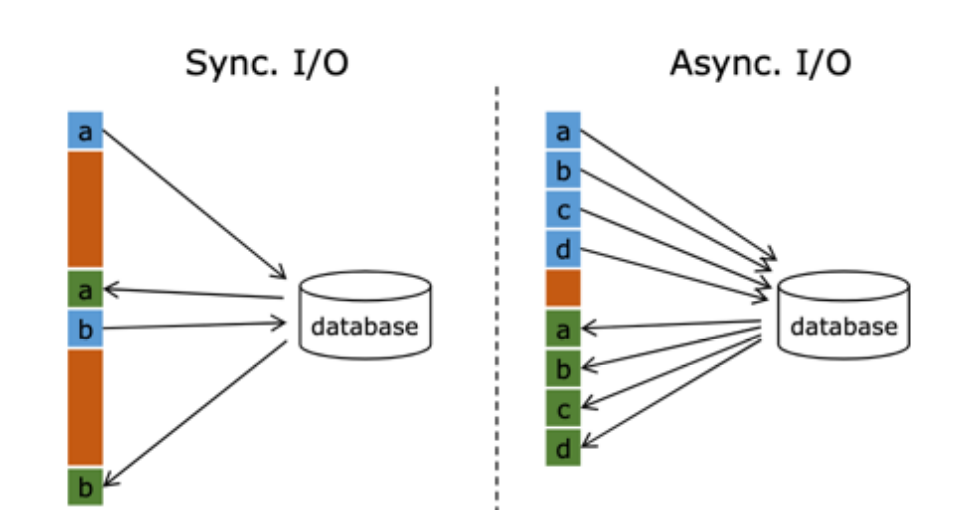
异步查询实际上是把维表的查询操作托管给单独的线程池完成,这样不会因为某一个查询造成阻塞,单个并行可以连续发送多个请求,提高并发效率。
这种方式特别针对涉及网络 IO 的操作,减少因为请求等待带来的消耗。
支付宽表
支付宽表的目的,最主要的原因是支付表没有到订单明细,支付金额没有细分到商品上,没有办法统计商品级的支付状况。
所以本次宽表的核心就是要把支付表的信息与订单宽表关联上。
解决方案有两个
- 一个是把订单宽表输出到 HBase 上,在支付宽表计算时查询 HBase,这相当于把订单宽表作为一种维度进行管理。
- 一个是用流的方式接收订单宽表,然后用双流 join 方式进行合并。因为订单与支付产生有一定的时差。所以必须用 Interval Join 来管理流的状态时间,保证当支付到达时订单宽表还保存在状态中。
订单宽表不需要永久保存,数据本身要写Kafka所以没必要再写一份到 HBase,还要从里面查,综合考虑,采用第2种方案。
https://www.bilibili.com/video/BV1Ju411o7f8/?p=73
大数据-数据仓库-实时数仓架构分析
大数据-业务数据采集-FlinkCDC
大数据 - DWD&DIM 行为数据
大数据 - DWD&DIM 业务数据
大数据 DWM层 业务实现
大数据 - DWM层 业务实现的更多相关文章
- 基于Spring4+Hibernate4的通用数据访问层+业务逻辑层(Dao层+Service层)设计与实现!
基于泛型的依赖注入.当我们的项目中有很多的Model时,相应的Dao(DaoImpl),Service(ServiceImpl)也会增多. 而我们对这些Model的操作很多都是类似的,下面是我举出的一 ...
- 一个大数据平台省了20个IT人力——敦奴数据平台建设案例分享
认识敦奴 敦奴集团创立于1987年,主营服装.酒店.地产,总部位于中国皮都-海宁.浙江敦奴联合实业股份有限公司(以下简称"敦奴")是一家集开发.设计.生产.销售于一体的大型专业服装 ...
- 迎战大数据-Oracle篇
来自:http://www.cnblogs.com/wenllsz/archive/2012/11/16/2774205.html 了解大数据带来的机遇: 透视架构与工具: 开源节流,获得竞争优势. ...
- 大数据篇:一文读懂@数据仓库(PPT文字版)
大数据篇:一文读懂@数据仓库 1 网络词汇总结 1.1 数据中台 数据中台是聚合和治理跨域数据,将数据抽象封装成服务,提供给前台以业务价值的逻辑概念. 数据中台是一套可持续"让企业的数据用起 ...
- 跟上节奏 大数据时代十大必备IT技能(转)
新的想法诞生新的技术,从而造出许多新词,云计算.大数据.BYOD.社交媒体……在互联网时代,各种新词层出不穷,让人应接不暇.这些新的技术,这些新兴应用和对应的IT发展趋势,使得IT人必须了解甚至掌握最 ...
- 跟上节奏 大数据时代十大必备IT技能
跟上节奏 大数据时代十大必备IT技能 新的想法诞生新的技术,从而造出许多新词,云计算.大数据.BYOD.社交媒体……在互联网时代,各种新词层出不穷,让人应接不暇.这些新的技术,这些新兴应用和对应的IT ...
- 大数据时代,IT行业竟有如此多高薪职位!
近年来云计算.大数据.BYOD.社交媒体.3D打印机.物联网……在互联网时代,各种新词层出不穷,令人应接不暇.这些新的技术.新兴应用和对应的IT发展趋势,使得IT人必须了解甚至掌握最新的IT技能. 另 ...
- 数据访问层 (DAO)
数据持久化 持久化:将程序中的数据在瞬间状态下和持久状态间转换的机制(JDBC) 主要持久化操作:保存.删除.读取.和查找. 采用面向接口编程,可以降低代码间的耦合性,提高代码的可扩展性和可维护性. ...
- 华为云BigData Pro解读: 鲲鹏云容器助力大数据破茧成蝶
华为云鲲鹏云容器 见证BigData Pro蝶变之旅大数据之路顺应人类科技的进步而诞生,一直顺风顺水,不到20年时间,已渗透到社会生产和人们生活的方方面面,.然而,伴随着信息量的指数级增长,大数据也开 ...
- 阿里巴巴大数据产品最新特性介绍--机器学习PAI
以下内容根据演讲视频以及PPT整理而成. 本次分享主要围绕以下五个方面: PAI产品简介 自定义算法上传 数加智能生态市场 AutoML2.0自动调参 AutoLearning自动学习 一.PAI产品 ...
随机推荐
- Vue学习之--------Vue中收集表单数据(使用v-model 实现双向数据绑定、代码实现)(2022/7/18)
文章目录 1.Vue中实现表单数据的收集 1.1 基础知识 1.2 代码实例 1.3 测试效果 1.4 额外插一嘴 1.Vue中实现表单数据的收集 1.1 基础知识 表单中常用的标签:input(输入 ...
- 动词时态=>2.动作的时间状态结合
动作和时间结合 现在的四种时态 现在进行时态 对于 现在这个时间点,这个 动作 还在进行当中 例如:我现在正在喝水 现在完成时态 对于 现在这个时间点,这个 动作 已然完成 例子:我现在已经喝完了水 ...
- [Oracle]复习笔记-SQL部分内容
Oracle笔记--SQL部分 整体框架 语句的执行顺序:from →where →group by→having→select→order by select * from * where * gr ...
- python基础之if条件控制语句
前言 本文主要介绍控制流程中的if条件语句,包括if...:if...else...:if...elif...elif...else...:if...if...if...else...:if嵌套等.内 ...
- 从小白到架构师(4): Feed 流系统实战
「从小白到架构师」系列努力以浅显易懂.图文并茂的方式向各位读者朋友介绍 WEB 服务端从单体架构到今天的大型分布式系统.微服务架构的演进历程.读了三篇万字长文之后各位想必已经累了(主要是我写累了), ...
- 解决pip下载速度慢问题
解决pip下载速度慢的问题 痛点:当我们pip 安装第三方库的时候,由于是访问的国外地址,所以会出现下载很慢!干等..... 解决方案: # 1.在C盘目录-->Users-->用户--& ...
- 【k8s连载系列】k8s介绍
k8s是Kubernetes的缩写,Google 于 2014 年开源了 Kubernetes 项目. 一.k8s的历史演变 k8s的演变过程:首先从传统的服务-->虚拟机部署-->容器部 ...
- LAL v0.32.0发布,更好的支持纯视频流
Go语言流媒体开源项目 LAL 今天发布了v0.32.0版本.距离上个版本刚好一个月时间,LAL 依然保持着高效迭代的状态. LAL 项目地址:https://github.com/q19120177 ...
- EBI、DDD及其演变架构史
一.引子 聊架构总离不开"领域驱动架构",大多能聊到DDD(Domain-Driven Design),实际上早期思想EBI架构 1992年就诞生了.核心价值点在于:关注核心业务领 ...
- i春秋Fuzz
点开只有三个单词plz fuzz parameter 大概意思就是让我们疯狂尝试参数... 我们通过url尝试传入参数 ?user=123 ?name=123 ?username=123 ?id=12 ...