基于二叉树的高效IP检索格式MMDB
一、MMDB简介
二、构造过程
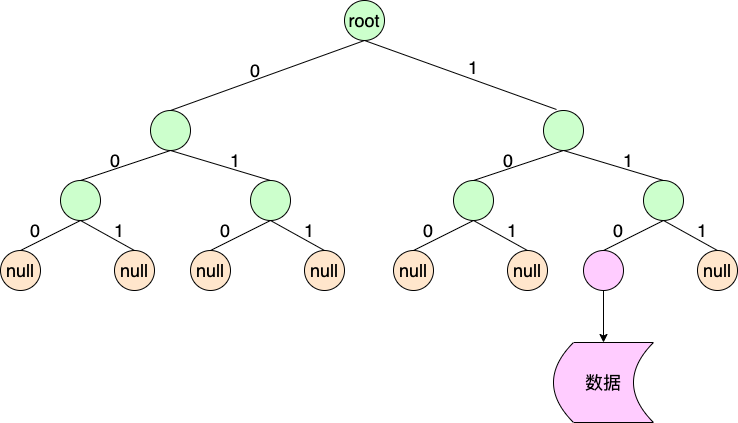
三、MMDB总体格式

四、节点序列说明
节点序列等于一个节点数组,每个节点由两个记录组成,分别对应二叉树的左孩子和右孩子。
在IP检索中,比特0对应第一个记录,比特1对应第二个记录。

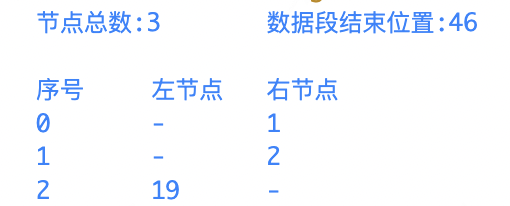
如上图所示,包含3个节点,第一个节点的两个记录为3和1,第二个节点为3和2,第三个节点为19和3。
当记录数等于节点数3时,表示没找到数据。当记录数大于节点数3时,则为数据节点的记录值。
第三个节点记录19表示数据偏移量为0,19-3(节点数)-16。
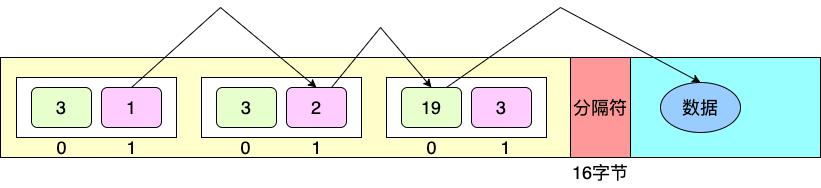
五、检索算法
在一个总节点数为3的mmdb数据库上,网段“110”的检索过程
六、数据段说明
七、实验例子
1、构造一个网段为“192.2.10.0/3”,对应二进制网络“110”的节点,数据为{"iso":156,"country_name":"China"},生成的节点序列为:

可以看到“110”网段根据二叉树检索算法得到数据段的偏移量19,则数据段偏移量为19-3(节点数)-16=0。
2、再加入一个网段为“64.2.10.0/3”,对应二进制网络“010”的节点,数据为{"iso":826,"country_name":"England"},生成的节点序列为:


八、总结
1、生成过程使用二叉树。
2、存储和检索都是序列化字节数组格式。
3、MMDB是内存数据库 。
参考链接
MaxMind DB File Format Specification
Enriching MMDB files with your own data using go
Building your own MMDB database for fun and profit
基于二叉树的高效IP检索格式MMDB的更多相关文章
- 【转】TCP/IP报文格式
1.IP报文格式 IP协议是TCP/IP协议族中最为核心的协议.它提供不可靠.无连接的服务,也即依赖其他层的协议进行差错控制.在局域网环境,IP协议往往被封装在以太网帧(见本章1.3节)中传送.而所有 ...
- TCP,UDP,IP包头格式及说明(zz)
一.MAC帧头定义 /数据帧定义,头14个字节,尾4个字节/ typedef struct _MAC_FRAME_HEADER { ]; //目的mac地址 ]; //源mac地址 short m_c ...
- [大牛翻译系列]Hadoop(19)MapReduce 文件处理:基于压缩的高效存储(二)
5.2 基于压缩的高效存储(续) (仅包括技术27) 技术27 在MapReduce,Hive和Pig中使用可分块的LZOP 如果一个文本文件即使经过压缩后仍然比HDFS的块的大小要大,就需要考虑选择 ...
- [大牛翻译系列]Hadoop(18)MapReduce 文件处理:基于压缩的高效存储(一)
5.2 基于压缩的高效存储 (仅包括技术25,和技术26) 数据压缩可以减小数据的大小,节约空间,提高数据传输的效率.在处理文件中,压缩很重要.在处理Hadoop的文件时,更是如此.为了让Hadoop ...
- 以太网帧、TCP与UDP段以及IP数据报格式总结
传输层及其以下的机制由内核提供,是操作系统的一部分,应⽤层由⽤户进程提供应⽤层数据通过协议栈发到⽹络上时,每层协议都要加上⼀个数据⾸部(header),称为封装.不同的协议层对数据包有不同的称谓,在传 ...
- 计算机网络(3)-----IP数据报格式
IP数据报(IP Datagram) 格式 解析 (1)版本 占4位,指IP协议的版本.通信双方使用的IP协议版本必须一致.目前广泛使用的IP协议版本号为4(即IPv4). (2)首部长度 占4位,可 ...
- TCP/IP包格式详解
文章参考地址:http://blog.chinaunix.net/uid-20698826-id-4700710.html http://blog.csdn.net/mrwangwang/articl ...
- 一种基于重载的高效c#上图片添加文字图形图片的方法
在做图片监控显示的时候,需要在图片上添加文字,如果用graphics类绘制图片上的字体,实现图像上添加自定义标记,这种方法经验证是可行的,并且在visual c#2005 编程技巧大全上有提到,但是, ...
- 基于二叉树和数组实现限制长度的最优Huffman编码
具体介绍详见上篇博客:基于二叉树和双向链表实现限制长度的最优Huffman编码 基于数组和基于链表的实现方式在效率上有明显区别: 编码256个符号,符号权重为1...256,限制长度为16,循环编码1 ...
- 【转】以太网帧、IP报文格式
原文:https://www.cnblogs.com/yongren1zu/p/6274460.html https://blog.csdn.net/gufachongyang02/article/d ...
随机推荐
- Multipass,本地轻量级Linux体验!
Multipass介绍 Multipass 是由Ubuntu官方提供,在Linux,MacOS和Windows上快速生成 Ubuntu虚拟机 的工具.它提供了一个简单但功能强大的CLI,可让我们在本地 ...
- tesseract-orc训练 结合python3图像识别验证码
##前言 其实就是用到tesseract-ocr这个引擎来识别,只不过我们需要做一些在此之前的工作 将图片用pillow进行初步处理,将图片中的验证码显示的清晰一些,关于这些教程可以查看我的另一篇文章 ...
- 关于最新版本listen1 (2.1.6)的修改心得(添加下载功能)
注:本文只作为技术交流 前言 再次感谢 listen1 的作者开发出如此强大的音乐播放器 项目地址 上一篇的文章没有解决跨域问题(命名不能正确命名), 上一篇文章 地址 这次解决了,并简单的美化了下载 ...
- jquery操作class
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- MYSQL快速安装整理
参考教程:https://www.cnblogs.com/brad93/p/16650780.html [检查是否已安装过] find / -name mysql [快速安装开始] groupadd ...
- kali2021.4a安装angr(使用virtualenv)
在Linux中安装各种依赖python的软件时,最头疼的问题之一就是各个软件的python版本不匹配的问题,angr依赖python3,因此考虑使用virtualenv来安装angr Virtuale ...
- python 之定时任务(schedule)
import schedule import time def job(): print("定时通报...") # 定义一个叫job的函数,函数的功能是打印'定时通报...' sc ...
- python 实现AES加解密
AES 只是个基本算法,实现 AES 有几种模式,主要有 ECB.CBC.CFB 和 OFB CTR,直接上代码,此处为AES加密中的CBC模式,EBC模式与CBC模式相比,不需要iv. impor ...
- JavaScript:操作符:空值合并运算符(??)
这是一个新增的运算符,它的功能是: 对于表达式1 ?? 表达式2,如果表达式1的结果是null或者undefined时,返回表达式b的结果:否则返回表达式a的结果: 它与赋值运算符结合使用,即??=, ...
- 中国蚁剑 - AntSword
中国蚁剑 - AntSword 中国蚁剑是一种跨平台操作工具,它主要提供给用户用于有效的网络渗透测试以及进行正常运行的网站. 否则任何人不得将网站用于其无效用途以及可能的等目的.自己承担并追究其相关责 ...