学习Redis(一)
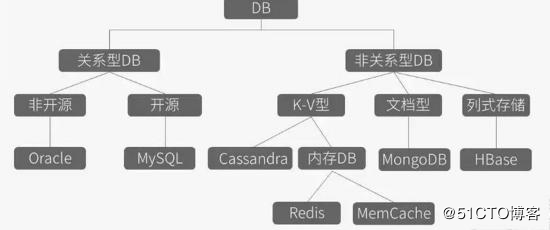
一、NoSQL
1、NoSql介绍
1、not only SQL,非关系型数据库,它能解决常规数据库的并发、IO与性能的瓶颈
2、解决以下问题:
① 对数据库的高并发读写需求
② 大数据的高效存储和访问需求
③ 高可扩展性和高可用性的需求
2、Nosql数据库的应用环境
1) 数据模型比较简单
2) 需要灵活性更强的IT系统
3) 对数据库的性能要求较高
4) 不需要高度数据一致性
5) 对于给定KEY,比较容易映射复杂值的环境
3、Nosql软件的分类与特点
1、key-value键值存储数据库
1) 介绍
① 键值对存储,可通过key来添加、查询、删除数据
② 用于内容缓存,适合负载并扩展大的数据集
③ 数据类型是一系列的键值对
④ 有快速查询功能,但存储数据少结构化
⑤ 对事务的支持不好,数据库故障产生时不可进行回滚
2) 常见数据库产品
redis、memcached、ttserver
3) 应用场景
存储用户信息,如会话、配置文件、参数、购物车、计数(统计粉丝关注)等 2、列存储数据库
1) 介绍
① 查询多个列
② 用于分布式的文件系统
③ 以列簇式存储,将同一列数据存在一起
④ 查找速度快,可扩展强,更容易进行分布式扩展
⑤ 功能相对局限
2) 常见数据库产品
HBase
3) 适用场景
日志(将信息写入自己的column family中)
blog平台(存储到不同的column family中,如标签、类别、文章等) 3、面向文件的数据库
1) 介绍
① 版本化的文档,半结构化的文档
② 用于WEB应用较多
③ 数据类型是一系列键值对
④ 查询性能不高,没有统一的查询语法
2) 常见数据库产品
mongoDB
3) 适用场景
日志(程序有不同的日志)
无固定的模式,存储不同的信息
分析(不改变模式,就可存储不同的度量方法,及添加新的度量) 4、图形数据库
1) 介绍
① 数据已图的方式存储
② 社交网络应用较多
③ 不容易做分布式的集群方案
2) 常见数据库产品
Graph
3) 适用场景
在关系型强的数据中,推荐引擎,社交网络,推荐系统等
4、常用的Nosql数据库介绍
1、memcached
1) 介绍
一个开源高性能的,具有分布式内存对象的缓存系统
2) 特点
① 安装布署简单
② 支持高并发、高性能
③ 通过程序或负载均衡可以实现分布式
④ 仅为内存缓存,重启服务数据丢失 2、memcacheDB
1) 介绍
新浪基于memcached开发的一个开源项目,具备了事务恢复功能
2) 特点
① 高并发读写
② 高效存储
③ 高可用数据存储 3、ttserver(tokyo tyrant/tokyocabinet)
1) 介绍
日本开发的DBM数据库,读写非常快,是BDB的几倍
2) 特点
① 支持内存缓存,可持久化存储
② 故障转移,tokyo tyrant支持主从模式,双机互为主从模式,主从库均可读写
③ 5千万条数据,级别内的访问相当快
④ 兼容memcached协议,客户端不需更改任何代码 4、mongoDB(document-oriented)
1) 介绍
一个基于分布式文件存储的数据库,由C++语言编写
2) 特点
易部署、高性能、易使用、存储数据非常方便 5、redis(key-value)
1) 介绍
用ANSIC语言编写(代码3W多行),基于内存及持久化日志型、Key-Value数据库,提供多种语言的API
2) 特点
① 支持内存缓存,相当于memcached
② 持久化,相当于memcachedb,ttserver
③ 数据类型更丰富
④ 支持集群,分布式
5、生产环境如何选择Nosql数据库
1、最常规的缓存应用,memcached最合适
2、持久化存储方案,用memcacheDB
3、2000万以内数据量的小数据,用memcached
4、大数据量,用redis
二、redis
1、redis网站
http://www.redis.cn/
http://www.redis.io/topics/introduction
2、redis特点
1、key-value键值类型存储
2、支持数据可靠存储
3、单进程单线程高性能服务器
4、恢复比较慢
5、单机qps(秒并发)可以达到10W
6、适合小数据量高速读写访问
3、redis持久化
1、介绍
redis将数据存储内存中,通过快照、日志两种方式实现持久化存储
2、持久化对比
snapshot(快照): 一次性将内存中的数据写入到磁盘,会导致数据的丢失
aof : 类似MySQL的binlog日志,记录每次更新的日志,不用于主从同步,仅能保存数据
3、配置文件对比
Snapshot(快照)
save 900 1 #900秒有1个key,则触发快照写入磁盘
save 300 10
save 60 10000
AOF(更新日志)
appendfsync always #总是记录更新内容
appendfsync everysec #每秒记录更新内容
appendfsync no #不记录更新内容
4、 redis的数据类型
String 字符串
Hash 哈希表
List 列表
Set 集合
Sorted set 有序集合
5、redis应用场景
1、计数器、好友关系、cache服务
2、微博(评论、转发、阅读、赞等),用户(粉丝、关注、收藏等)
3、用户最近访问记录、最热,点击率最高,活跃度最高的视频或帖子
6、redis的生产经验
1、要配置主从同步,在出现故障时可以切换
2、master禁用持久化,slave配置数据持久化
3、物理内存 + 虚拟内存不足,这时dump一直死着,时间久了机器会挂掉
4、当redis物理内存,使用超过内存总容量的3/5时,就开始做swap,比较危险,内存碎片大
5、当达到最大内存时,会清空带有过期时间的key,即使key未到过期时间
6、redis与db同步写的问题,先写db,后写redis
三、redis部署
1、安装redis
# wget http://download.redis.io/releases/redis-2.8.24.tar.gz
# tar zxf redis-2.8.24.tar.gz
# cd redis-2.8.24
# make
# make PREFIX=/application/redis-2.8.24 install
2、相关命令
redis-server #服务器命令
redis-cli #客户端命令,也可以用telnet连接
redis-benchmark #性能测试工具,测试读写性能
redis-check-aof #检查aof日志文件
redis-check-dump #检查本地rdb快照文件
3、启动服务
1、查看命令帮助
# redis-server -h 2、复制配置文件
# cp redis-2.8.24/redis.conf /application/redis/conf/ 3、启动服务
# redis-server /application/redis/conf/redis.conf 4、关闭服务
# redis-cli shutdown
# redis-cli shutdown save 5、警告处理
1) 参数说明(vm.overcommit_memory)
0: 应用请求更多内存时,内核检查是否有足够的内存,若有,分配应用,若无,不分配,返回错误给应用
1: 内核允许分配所有的内存,不管内存状态(主要用于科学计算)
2: 内核绝不过量使用内存,即系统整个内存不能超过swap+50%的RAM值,50%在overcommit_ratio中设定
2) 永久生效
# echo "vm.overcommit_memory = 1" >> /etc/sysctl.conf
# sysctl -p
3) 临时生效
# sysctl vm.overcommit_memory=1
# echo '1' > /proc/sys/vm/overcommit_memory
4、相关命令
# redis-cli #连接本地redis
6379> set id 001 #设置key和value
6379> get id #取key的值
6379> del id #删除key
6379> exists id #验证key是否存在
6379> keys * #查看所有的key
6379> select 1 #切换到库1模式(默认有16个库,可在配置文件设置)
5、redis远程连接和非交互式操作
1、远程连接
# redis-cli -h 10.0.0.135 -p 6379 2、远程连接并执行命令
# redis-cli -h 10.0.0.135 -p 6379 set aaa 111
# redis-cli -h 10.0.0.135 -p 6379 get aaa 3、其他命令连接方式
# telnet 10.0.0.135 6379
# echo "set no004 zsq" |nc 127.0.0.1 6379
# echo "get no004 " |nc 127.0.0.1 6379
6、redis命令帮助
1、客户端命令帮助:
6379> ? #查看帮助命令用法
6379> help #查看帮助命令用法
6379> help set #查看set命令用法 2、通过help命令来查找命令
6379> help @generic #需要多次按Tab键
help + 空格 + 多次<Tab>键来切换所有命令
7、redis安全
1、设置密码
redis没有用户概念,1秒可尝试上万次的密码登陆,要设置复杂的密码,来防止暴力破解
1) 方法一:
# vim redis.conf
requirepass "123456" #设置密码
2) 方法二:
# redis-cli
6379> config set requirepass 123456
6379> config rewrite
3) 登陆方法一:
# redis-cli
6379> auth 123456
4) 登陆方法二:
# redis-cli -a 123456 2、屏蔽危险命令(命令改名)
# vim redis.conf
rename-command set "sset" #将set修改为sset
rename-command keys "" #屏蔽掉keys命令
8、安装redis客户端(php环境)
1、获取源码包
# wget https://github.com/nicolasff/phpredis/archive/master.zip 2、安装
# unzip phpredis-master.zip
# cd phpredis-master
# /application/php/bin/phpize
# ./configure --with-php-config=/application/php/bin/php-config
# make && make install 3、检查
# ls /application/php-5.6.8/lib/php/extensions/no-debug-non-zts-20131226/
memcache.so opcache.a opcache.so redis.so 4、修改设置
# vim /application/php/lib/php.ini
extension = redis.so
extension_dir = "/application/php-5.6.8/lib/php/extensions/no-debug-non-zts-20131226/" 5、重启php
# killall php-fpm
# /application/php/sbin/php-fpm 6、php操作redis
# cat redis.php
<?php
$redis = new Redis();
$redis ->connect('10.0.0.135',6379);
$redis ->auth('123456');
$redis ->set('name','zhang3');
$var = $redis ->get('name');
echo "$var\n";
?>
9、安装redis客户端(Python)
1、安装
# wget https://pypi.python.org/packages/source/r/redis/redis-2.10.1.tar.gz
# tar xf redis-2.10.1.tar.gz
# cd redis-2.10.1
# python setup.py install 2、python操作redis
# python
>>> import redis #导入redis库
>>> r = redis.Redis(host='10.0.0.135',port='6379',password='123456') #连接redis(面向对象)
>>> r.set('name','benet') #写入数据
>>> r.get('name') #读取数据
>>> r.dbsize() #查看数据数
>>> r.keys() #查看所有的key
>>> exit() #退出 3、Web界面Python连接Redis
1) 编写脚本
# cat python-redis.py
#/usr/bin/python
from wsgiref.simple_server import make_server
import redis def get_redis():
r = redis.Redis(host='10.0.0.135',port='6379',password='123456',db=0)
r.set('name','zhang3')
return r.get('name') def hello_world_app(environ,start_response):
status = '200 OK'
headers = [('Content-type','text/plain')]
start_response(status,headers) return get_redis() httpd = make_server('',8000,hello_world_app)
print "Serving on port 8000..." httpd.serve_forever()
2) 启动python脚本
# python python-redis.py
3) 访问
http://127.0.0.1:8000
10、解读redis配置文件
# vim redis.conf
include /path/to/local.conf #redis支持include功能
daemonize no #是否后台运行
pidfile /var/run/redis.pid #pid文件的位置
port 6379 #监听端口
tcp-backlog 511 #tcp监听队列
bind 10.0.0.135 #监听地址
timeout 0 #客户端超时时间
tcp-keepalive 0 #tcp的会话保持时间
loglevel notice #日志级别
logfile "" #日志记录位置,默认打印到屏幕上
syslog-facility local0 #是否启用syslog接收日志(日志集中收集)
databases 16 #库的数量(默认为0到15)
save "" #不保存快照
save 900 1 #900秒有1个key,触发快照
save 300 10 #300秒有10个key,触发快照
save 60 10000 #60秒有10000个key,触发快照
stop-writes-on-bgsave-error yes #bgsave出错是否停止写入
dbfilename dump.rdb #持久化文件名
dir ./ #持久化文件位置(默认当前路径)
rdbcompression no #是否压缩rdb文件,会消耗cpu
rdbchecksum yes #检查rdb数据
requirepass 123456 #redis的密码
rename-command CONFIG "" #屏蔽命令
rename=command get wk #命令改名
maxmemory 2G #限制redis内存
maxmemory-policy volatile-lru #内存清理的算法
appendonly no #是否启用AOF持久化
appendfilename "appendonly.aof" #AOF文件名
appendfsync everysec #每秒记录
auto-aof-rewrite-percentage 100 #自动重写(rewrite)的百分比
auto-aof-rewrite-min-size 64mb #自动重写(rewrite)aof的文件大小
lua-time-limit 5000 #lua脚本最大运行时间
hash-max-ziplist-entries 512 #hash优化参数(数量512以下,数据压缩)
hash-max-ziplist-value 64 #hash优化参数(长度小于64字节,数据压缩)
slaveof 10.0.0.135 6379 #设置主从复制
masterauth 123456 #主库密码
requirepass 123456 #本身密码
maxclients 128 #最大连接数
vm-enabled no #是否启用虚拟内存
vm-swap-file /tmp/redis.swap #虚拟内存文件路径
vm-max-memory 0 #所有大于vm-max-memory的数据,存入虚拟内存
vm-page-size 32 #虚拟内存数据页的大小
vm-pages 134217728 #虚拟内存数据页的数量
vm-max-threads 4 #访问虚拟内存文件的线程数
glueoutputbuf yes #应答客户端时,是否合并较小的包
activerehashing yes #是否激活重置哈希
四、redis数据类型
1、String (字符串)
1、介绍
string类型是二进制,很安全的,一个key对应一个value,包含任何数据,但值的长度不能超过1GB
key: 长度10到20
value: 不要超过2k 2、字符串对数字的加减
6379> set id 1 #设置key是id,值是1
6379> get id #查看key
6379> incr id #自增1
6379> incrby id 5 #自增指定数
6379> decr id #自减1
6379> decrby id 5 #自减指定数 3、其他操作
6379> getset user01 wangwu #设置新数据并返回旧数据
6379> get user01 #查看key的值
6379> mset name zhangsan age 44 #设置多个key
6379> mget name age #查看多个key的值
6379> append images .jpg #追加字符串
6379> strlen images #计算字符串长度
6379> substr images 0 6 #取0到6的值
6379> help set #查看单个命令帮助
6379> help @string #查看字符串所有命令的帮助
2、List(列表)
list是简单的字符串列表,按照插入顺序排序,可实现聊天系统和消息的队列
6379> help @list #列表帮助
6379> lpush students "zhang3" #插入元素到列表的最左边
6379> lrange students 0 1 #查看列表0到1元素的值
6379> rpush students "wang5" #将插入元素到列表的最右边
6379> llen students #查看列表元素的个数
6379> lpop students #移除最左边的元素值
6379> rpop students #移除最右边的元素值
6379> lrem students 2 "zhangsan" #删除两次指定的元素(从左向右删)
6379> lrem students 1 "zhangsan" #删除一次指定的元素
6379> lrem students 0 "zhangsan" #清空所有指定的元素
6379> linsert students before b xxxx #在元素b的前边插入新元素
6379> linsert students after b xxxx #在元素b的后边插入新元素
3、集合(Sets)类型
1、Set(无序集合)
集合通过哈希表实现的,集合内的元素具有唯一性
6379> help @set #无序集合帮助
6379> sadd users laoda #添加一个元素
6379> sadd users laoer laosan #添加两个元素
6379> smembers users #查看集合里的所有元素(集合里的元素是无序的)
6379> sismember users laoda #查看元素是否在集合中 2、zset(有序集合)
6379> help @sorted_set #有序集合帮助
6379> ZADD days 0 mon #days:有序集合名,0:序号,mon:值
6379> zrange days 0 6 #查看集合0到6元素的值(正序)
6379> zrevrange days 0 -1 #查看集合所有元素的值(倒序)
6379> zscore days mon #查看集合里值的排序
6379> zrangebyscore days -inf 8 #查看负无穷到5之间元素的值(区间查询)
6379> zremrangebyscore days 1 7 #删除1到7之间的元素(删除之间的元素)
4、Hash类型
哈希可存储多个属性的数据(如user,name passwd)
6379> hset k1 name zhang3 age 23 #k1:哈希名,name:属性1,age:属性1
6379> hvals k1 #查看所有属性
6379> hgetall k1 #查看所有属性和值
五、redis多实例
1、创建多实例目录和配置文件
1、创建redis多实例目录
# mkdir -p /data/redis/638{0..1}/{conf,logs,pid} 2、创建redis多实例配置文件
# cp redis.conf /data/6380/conf/redis_6380.conf
# cp redis.conf /data/6381/conf/redis_6381.conf
# vim redis_6380.conf
bind 10.0.0.135
port 6380
daemonize yes
dir /data/redis/6380/
pidfile /data/6380/redis_6380.pid
logfile /data/6380/logs/redis_6380.log
dbfilename redis_6380.rdb
appendonly yes
appendfilename redis.aof
# sed -i 's#6380#6381#g' /data/6381/conf/redis_6381.conf
2、启动redis多实例
1、启动
# redis-server /data/redis/6380/conf/redis_6380.conf
# redis-server /data/redis/6381/conf/redis_6381.conf 2、查看端口和进程
# netstat -antup | grep redis
# ps -ef | grep redis
六、 Redis主从同步
1、Redis主从同步特点
1、一个master可以拥有多个slave
2、多个slave可以连接同一个master,还可以连接到其他slave
3、主从复制不会阻塞master,在同步数据时,master可以继续处理客户端的请求
4、提高系统的伸缩性
2、Redis主从同步的过程
1、Slave连接到Master服务器
2、Slave发送SYNC命令
3、Master备份数据到rdb文件
4、Master把rdb文件传输给Slave
5、Slave把rdb文件导入到数据库中
3、Redis的主从同步的应用
1、一个master可有多个slave,一个slave还可以有多个slave
2、主从同步不会阻塞master,但是会阻塞slave(初次同步数据,会阻塞客户端的请求)
3、主从同步提高系统的伸缩,用多个slave处理客户端的读请求
4)master不做持久化,在slave上做,可提高集群的性能,也可在slave上做数据的备份
5)对于老版本的redis,每次重连都会重新发送所有数据
4、配置主从同步
1、方法1(临时生效) # redis-cli slaveof 10.0.0.135 6380 #启动主从同步
# redis-cli slaveof no one #停止主从同步 2、方法2(永久生效)
# vim redis_6381.conf
slaveof 10.0.0.135 6380 #主库的IP和端口
masterauth 123456 #主库的密码
5、同步过程
* Connecting to MASTER 192.168.0.135:6379 #连接master
* MASTER <-> SLAVE sync started #开始发送sync
* Non blocking connect for SYNC fired the event. #这是一个不阻塞事件
* Master replied to PING, replication can continue... #master应答了ping,同步开始
* Partial resynchronization not possible (no cached master) #部分重新同步不可能(master无缓存内容)
* Full resync from master: #从master同步全部数据
* MASTER <-> SLAVE sync: receiving 49 bytes from master #从master接收到49字节数据
* MASTER <-> SLAVE sync: Flushing old data #刷新旧数据
* MASTER <-> SLAVE sync: Loading DB in memory #数据放到内存
* MASTER <-> SLAVE sync: Finished with success #同步完成
* Background append only file rewriting started by pid 3620 #AOF重写
* Background AOF rewrite terminated with success #AOF重写成功
* Background AOF rewrite finished successfully #AOF重写完毕
6、主从相关参数
1、主从同步测试
# redis-cli -a 123456 -p 6381 monitor #监听主服务写入操作
# redis-cli -a 123456 -p 6380 get name #查看key
# redis-cli -a 123456 -p 6380 set name tom #设置一个key和value 2、主从同步相关参数
slave-serve-stale-data yes #yes:从不能连接主,从可正常提供服务,数据是旧的,no:不提供服务,返回错误信息
slave-read-only yes #设置从库只读模式
repl-ping-slave-period 10 #每10秒发送ping到master
repl-backlog-size 1mb #backlog大小(主通过backlog实现从的增量同步)
repl-backlog-ttl 3600 #主从断开时,backlog的生存周期
slave-priority 100 #slave的优先级 3、查看redis各项参数的方法
6379> info #查看所有的信息
6379> info cpu #查看CPU的信息
6379> info clients #查看客户端信息
6379> info replication #查看同步信息
role:master #角色是主
connected_slaves:1 #连接从的数量
slave0:ip="",port="",state=online,offset=11972,lag=1 #从库ip,端口,状态,偏移量等
七、redis的高级特性
1、redis的订阅功能
1、介绍
pub(发布)/sub(订阅)是一种消息通信模式,主要目的解耦发布者和订阅者之间的耦合
redis可将数据推到消息队列中,其它人可通过队列获取消息 2、开启的订阅功能
6379> subscribe first #开启并订阅频道(一个窗口)
6379> subscribe first second #可订阅多个频道 3、对频道推送
6379> publish first 'welcome' #向频道推送
6379> (integer) 2 #推送成功的人数(只要推送端推送,订阅端就能看到)
6379> help @pubsub #更多获取帮助
2、redis数据过期设置及过期机制
1、过期机制
1) 定时删除
设置key的过期时间的同时,创建一个定时器,到期时触发,对key删除
2) 惰性删除
key过期不删除,每次访问时检查是否过期,若过期,则删除key,并返回空(null)
3) 定期删除
每隔一段时间,检查有过期时间的key,删除已过期的key 2、过期设置
6379> expire name 5 #设置key5秒后过期
6379> TTL name #查看key过期时间(-1:永不过期,-2:已过期)
6379> get name #过期后的key,无法获取value的
6379> help @generic
3、事务性
1、组合型的命令
redis支持简单的组合型的命令,例如以nx结尾的命令,key不存在时,为key设置指定的值
6379> exists name #查询key是否存在
6379> setnx name tom #当key不存在时,设置key的值
6379> setnx name zhang3 #当key存在时,不执行任何操作
6379> get name #没有被覆盖 2、事务
6379> set name tom #设置一个key
6379> get name #查看key的值
6379> multi #开始一个事务
6379> set name a #当事务中有错误时,将都不执行
6379> set name b
6379> exec #提交事务(discard:取消事务)
4、redis持久化
1、快照(Snapshotting)
1) 介绍
将内存中数据,以快照的方式写入到文件中,redis宕机会丢失最后一次快照的数据
2) 配置
方法一
# vim redis.conf
dir /data/redis/ #rdb存储的路径
dbfilename dump.rdb #rdb文件名
save 900 1 #900秒内1个key被修改,触发快照
save 300 10 #300秒内10个key被修改,触发快照
save 60 10000 60秒内10000个key被修改,触发快照
rdbcompression no #关闭rdb压缩,影响cpu
save "" #关闭rdb
方法二
6379> redis-cli config set save "180 1 120 10 60 10000" #开启rdb
6379> redis-cli config rewrite #配置保存到文件
6379> redis-cli config set save "" #关闭rdb
3) 快照原理
① redis调用fork,产生一个子进程
② 父进程处理client请求,子进程将内存内容写入到临时文件,由于Linux的写时复制机制,子进程的数据是fork时的一个快照
③ 当子进程将快照写入临时文件后,把临时文件替换快照文件,然后子进程退出
4) 命令快照
save: 主线程保存快照,会阻塞所有client请求(不推荐)
bgsave: 开启一个子进程保存快照,不会阻塞客户端请求(推荐)
5) 其他
每次快照都是将内存数据完整写入到磁盘,如果数据量大,写操作多,会引起大量的磁盘io,严重影响性能
redis关闭时,会自动后台保存并退出,启动时,会读取RDB文件,若找不到RDB文件,则认为数据丢失 2、aof(日志方式)
1) 介绍
redis将收到的写操作,通过write函数追加到文件中,类似MySQL的binlog日志方式
2) 配置
# vim redis.conf
appendonly yes #启用aof
3) aof文件更新策略
appendfsync always #收到写命令就立即写入磁盘,最慢,但数据不会丢失
appendfsync everysec #默认方式,每秒写入磁盘一次,会丢失前1秒的数据
appendfsync no #完全依赖os,性能最好,数据会丢失
4) aof文件的自动重写
auto-aof-rewrite-percentage 100 #当aof文件增长比例100%时,触发自动重写
auto-aof-rewrite-min-size 64mb #当aof文件大小到64m,触发自动重写
6379> bgrewriteaof #手动触发自动重写
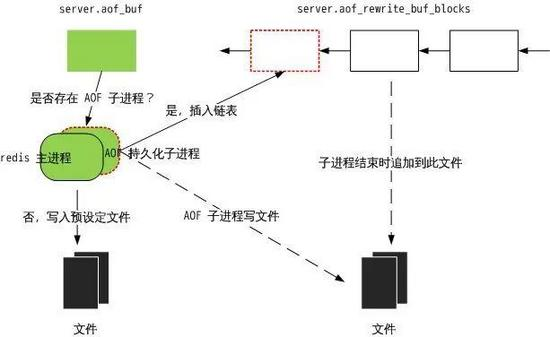
5) aof保存过程
① redis调用fork,产生一个子进程
② 子进程会根据内存中的快照,往临时文件中写人数据变化的命令
③ 父进程处理client请求,并把收到的写操作缓存
④ 当子进程把快照内容写完后,发信号通知父进程,父进程把缓存的写命令,写入到临时文件中
⑤ 父进程用临时文件,替换老的aof文件,并重命名,后面收到的写命令,往新的aof文件中追加
备注: 重写aof文件,并没有读取旧的aof文件,而是重写一个新的aof文件,当redis启动会加载aof文件,用命令重建整个数据库
八、redis的优化
1、常用命令
6379> flushdb #清空当前库的数据
6379> flushall #清空所有库的数据
6379> config get * #查看当前配置信息
6379> config set appendonly yes #在线修改
# redis-benchmark -h 127.0.0.1 -p 6379 -c 100 -n 10000 #100个并发,一万次请求 2、系统参数优化
1) 系统文件描述符
# echo "* - nofile 10240" >> /etc/security/limits.conf
# bash && ulimit -n
2) TCP连接数
# echo "net.core.somaxconn = 10240" >> /etc/sysctl.conf
# sysctl -p
3) 系统内存分配策略
# echo "vm.overcommit_memory = 1" >> /etc/sysctl.conf
# sysctl -p
4) 关闭系统大页内存
# echo never > /sys/kernel/mm/transparent_hugepage/enabled
# echo never > /sys/kernel/mm/transparent_hugepage/defrag 3、内存清理算法
volatile-lru #LRU算法删除过期的key
volatile-random #随机删除过期的key
volatile-ttl #删除即将过期的key
allkeys-lru #LRU算法删除所有key
allkeys-random #随机删除所有key
noeviction #不删除key,只返回错误
6379> config get maxmemory-policy #查看内存清理算法
6379> config get maxmemory-policy volatile-lru #设置内存清理算法 4、内存优化
hash-max-zipmap-entries 64 #hash的最大元素数,当超过时,采用特殊hash算法
hash-max-zipmap-value 512 #hash的最大元素值,当超过时,采用特殊hash算法
list-max-ziplist-value 64 #列表的最大元素值,当超过时,采用压缩列表
list-max-ziplist-entries 512 #列表的最大元素数,当超过时,采用压缩列表
set-max-intset-entries 512 #限制集合中member个数,超出则不采取intset存储
activerehashing yes #是否激活重置哈希 5、redis优化总结
① 根据业务需要,选择合适的数据类型,并为不同的应用场景,设置相应的紧凑存储参数
② 当业务场景不需要数据持久化时,关闭持久化,可获得最佳的性能和最大的内存使用量
③ 若使用持久化,根据是否容忍丢失部分数据,选择持久化方式,不要用虚拟内存vm及disk store方式,每秒实时写入AOF文件
④ 尽量不要让redis的内存,超过总内存的60%
⑤ 设置参数maxmemory,限制redis不会过多,使用物理内存而导致swap,设置参数vm-enabled no(不用虚拟内存)
⑥ 大数据量尽量按业务,用多个redis instance把数据分散开 6、批量插入数据
for i in `seq -w 50`;do redis-cli set name_$i value_$i;done
九、redis的状态信息
1、服务器的信息
# Server
redis_version:4.0.10 #redis服务器版本
redis_mode:standalone #运行模式(单机或集群)
multiplexing_api:epoll #使用的事件处理模型
uptime_in_days:0 #服务器启动总时间,单位是天
hz:10 #redis内部调度(关闭timeout客户端,删除过期key)
lru_clock:8197344 #自增时间,用于LRU管理 2、客户端信息
# Clients
connected_clients:1 #当前客户端连接数(不包括slave的连接)
blocked_clients:0 #被阻塞的客户端数 3、内存信息
# Memory
used_memory:2995728 #已用的内存,单位为字节(byte)
used_memory_human:2.86M #易读方式显示
used_memory_rss:4636672 #系统给redis分配的内存(和top、ps显示的一致)
used_memory_rss_human:4.42M #易读方式显示
used_memory_peak:15517016 #内存使用的峰值大小
used_memory_peak_human:14.80M #易读方式显示
used_memory_peak_perc:19.31% #峰值内存超出分配内存(used_memory)的百分比
used_memory_startup:786608 #Redis启动时的初始内存
total_system_memory:2229866496 #系统内存总量
total_system_memory_human:2.08G #易读方式显示
used_memory_lua:37888 #lua引擎使用的内存
used_memory_lua_human:37.00K #易读方式显示
maxmemory:0 #最大内存(0不限制)
maxmemory_human:0B #易读方式显示
mem_fragmentation_ratio:1.55 #内存碎片率(used_memory_rss和used_memory的比率,小于1:使用swap,大于1:碎片多,增删操作增加碎片)
mem_allocator:jemalloc-4.0.3 #内存分配器 4、持久化信息
# Persistence
loading:0 #是否正在加载持久化文件
rdb_changes_since_last_save:0 #自上次rdb后,数据的改动
rdb_bgsave_in_progress:0 #bgsave是否操作
rdb_last_save_time:1534918159 #上次bgsave的时间戳
rdb_last_bgsave_status:ok #上次bgsave的状态
rdb_last_bgsave_time_sec:0 #上次bgsave的使用的时间
rdb_current_bgsave_time_sec:-1 #当前bgsave已耗费的时间(如果有)
rdb_last_cow_size:438272 #上次rbd写时复制分配的字节大小
aof_enabled:1 #是否开启AOF
aof_rewrite_in_progress:0 #AOF是否正在自动重写(rewrite)
aof_rewrite_scheduled:0 #是否要在rdb的bgsave结束后执行rewrite
aof_last_rewrite_time_sec:1 #上次rewrite使用的时间(单位s)
aof_current_rewrite_time_sec:-1 #当前rewrite已耗费的时间(如果有)
aof_last_bgrewrite_status:ok #上次bgrewrite的状态
aof_last_write_status:ok #上次AOF文件写入状态
aof_last_cow_size:581632 #上次重写写时复制分配的字节大小
aof_current_size:2634673 #AOF当前大小
aof_base_size:2473591 #AOF上次启动或rewrite的大小
aof_pending_rewrite:0 #同上面的aof_rewrite_scheduled
aof_buffer_length:0 #AOF buffer的大小
aof_rewrite_buffer_length:0 #AOF rewrite buffer的大小
aof_pending_bio_fsync:0 #后台IO队列中等待fsync执行的个数
aof_delayed_fsync:0 #被延迟fsync调用数量
5、统计信息
# Stats
total_connections_received:220209 #连接过的客户端总数
total_commands_processed:447805 #执行过的命令总数
instantaneous_ops_per_sec:0 #每秒处理命令数
total_net_input_bytes:13682780 #输入网络流量总数
total_net_output_bytes:10737650 #输出网络流量总数
instantaneous_input_kbps:0.02 #网络读取速率
instantaneous_output_kbps:0.00 #网络写入速率
rejected_connections:0 #拒绝的连接个数(已达到maxclients限制)
sync_full:1 #主从完全同步成功次数
sync_partial_ok:0 #主从部分同步成功次数
sync_partial_err:1 #主从部分同步失败次数
expired_keys:0 #过期key的数量
evicted_keys:0 #剔除(超过maxmemory)的key的数量
keyspace_hits:0 #命中key次数
keyspace_misses:0 #没命中key次数
pubsub_channels:0 #当前使用中的频道数量
pubsub_patterns:0 #当前使用中的模式数量
latest_fork_usec:401 #上次fork消耗的时间 6、主从信息
# Replication
role:master #角色(主从)
connected_slaves:1 #连接的从库数量
slave0:ip="",port="",state=online,offset=123,lag=0 #从库信息
master_replid:2757c33a #复制ID
master_replid2:0000000 #第二个复制ID(用于failover的PSYNC)
master_repl_offset:7672755 #主从同步偏移量
repl_backlog_active:1 #复制缓冲区的状态
repl_backlog_size:1048576 #复制缓冲区的大小
repl_backlog_first_byte_offset:6624180 #复制缓冲区的主偏移量
repl_backlog_histlen:1048576 #复制缓冲区数据的大小 7、cpu信息
# CPU
used_cpu_sys:23.63 #主进程内核态消耗cpu的时间
used_cpu_user:13.16 #主进程用户态消耗cpu的时间
used_cpu_sys_children:0.31 #子进程内核态消耗cpu的时间
used_cpu_user_children:0.14 #子进程用户态消耗cpu的时间 8、集群信息
# Cluster
cluster_enabled:0 #集群未开启 9、数据库的键值信息
# Keyspace
db0:keys=1,expires=0,avg_ttl=0 #key总数,带有过期时间的key的总数,平均存活时间
十、redis的高可用(哨兵+vip)
1、环境
redis-server sentinel(哨兵)
主节点 192.168.1.11:8000 192.168.1.11:7000
从节点 192.168.1.12:8000 192.168.1.12:7000
从节点 192.168.1.13:8000 192.168.1.13:7000
2、配置主从复制(sentinel基于主从)
1、创建master配置文件(主节点)
# vim redis.conf
port 8000
daemonize yes
bind 0.0.0.0
pidfile /var/run/redis-8000.pid
logfile /var/log/redis/redis-8000.log
requirepass 123456 2、创建slave配置文件(2个从节点)
# vim redis.conf
port 8000
daemonize yes
bind 0.0.0.0
pidfile /var/run/redis-8000.pid
logfile /var/log/redis/redis-8000.log
slaveof 192.168.1.11 8000
masterauth 123456 3、启动redis(所有节点)
# redis-server redis.conf
3、安装部署redis-sentinel(所有节点)
1、创建sentinel配置文件
# vim sentinel.conf
port 7000
sentinel monitor mymaster 192.168.1.11 8000 2 #监控,别名,主库ip和端口,投票数2
sentinel down-after-milliseconds mymaster 5000 #主库宕机5秒,切库
sentinel parallel-syncs mymaster 1 #切库后,向主库同步数据的个数,1:轮询,2:并发
sentinel failover-timeout mymaster 15000 #故障转移的超时时间
sentinel auth-pass mymaster 123456 #主库密码 2、启动sentinel
# redis-sentinel sentinel.conf 3、查看sentinel信息
# redis-cli -h 192.168.1.11 -p 7000 info sentinel
4、部署redis-sentinel的VIP
1、修改配置文件(所有节点)
# vim sentinel.conf
port 7000
sentinel monitor mymaster 192.168.1.11 8000 2
sentinel down-after-milliseconds mymaster 5000
sentinel parallel-syncs mymaster 1
sentinel failover-timeout mymaster 15000
sentinel auth-pass mymaster 123456
sentinel client-reconfig-script mymaster /data/redis/redis_vip.sh 2、编写vip脚本(所有节点)
sentinel在failover的时会执行client-reconfig-script脚本,
并传递6个参数(<master-name>,<role>,<state>,<from-ip>,<from-port>,<to-ip>,<to-port>)
# vim /data/redis/redis_vip.sh
#!/bin/bash
MASTER_IP=$6 #传第六个参数(新master的IP==<to-ip>)
LOCAL_IP="192.168.1.12" #本地IP
VIP="192.168.1.20" #VIP
NETMASK="24"
INTERFACE="eth0"
if [[ "${MASTER_IP}" == "${LOCAL_IP}" ]];then
/usr/sbin/ip addr add ${VIP}/${NETMASK} dev ${INTERFACE}
/usr/sbin/arping -q -c 3 -A ${VIP} -I ${INTERFACE}
exit 0
else
/usr/sbin/ip addr del ${VIP}/${NETMASK} dev ${INTERFACE}
exit 0
fi
exit 1
# chmod +x /data/redis/redis_vip.sh 3、重启服务(所有节点)
# redis-cli -h 192.168.1.11 -p 7000 shutdown
# redis-sentinel sentinel.conf
# ip addr add 192.168.1.20/24 dev eth0 #第一次时手动给master添加VIP
# arping -q -c 3 -A 192.168.1.20 -I eth0 #让ip地址即刻生效
十一、Redis Cluster集群
1、介绍
Redis集群使用数据分片来实现,一个集群有16384个哈希槽,支持主从自动切换,无中心化,不支持多库,只有一个db0
2、环境(3节点)
主节点 db01: 10.0.0.11:7000 db02: 10.0.0.12:7000 db03: 10.0.0.13:7000
从节点 db02: 10.0.0.12:8000 db03: 10.0.0.13:8000 db01: 10.0.0.11:8000
3、redis部署和调优
1、安装redis
# yum -y install wget gcc gcc-c++ make tar openssl openssl-devel cmake
# tar xf redis-4.0.10.tar.gz -C /usr/src/
# cd /usr/src/redis-4.0.10/
# make
# make MALLOC=jemalloc
# make PREFIX=/usr/local/redis install
2、系统调优
# echo "* - nofile 10240" >> /etc/security/limits.conf
# echo "net.core.somaxconn = 10240" >> /etc/sysctl.conf
# echo "vm.overcommit_memory = 1" >> /etc/sysctl.conf
# sysctl -p
# echo never > /sys/kernel/mm/transparent_hugepage/enabled
# echo never > /sys/kernel/mm/transparent_hugepage/defrag
# echo 'echo never > /sys/kernel/mm/transparent_hugepage/enabled' >> /etc/rc.local
# echo 'echo never > /sys/kernel/mm/transparent_hugepage/defrag' >> /etc/rc.local
4、安装部署redis集群
1、创建目录(所有节点)
# mkdir -p /data/redis-cluster/{7000,8000}
2、创建配置文件(所有节点)
① master配置文件
# vim /data/redis-cluster/7000/redis_7000.conf
bind 0.0.0.0
protected-mode yes
port 7000
tcp-backlog 1024
timeout 0
tcp-keepalive 0
daemonize yes
supervised no
pidfile /data/redis-cluster/7000/redis_7000.pid
loglevel notice
logfile /data/redis-cluster/7000/redis_7000.log
databases 16
always-show-logo yes
save 900 1
save 300 10
save 60 10000
stop-writes-on-bgsave-error yes
rdbcompression yes
rdbchecksum yes
dbfilename redis_7000.rdb
dir /data/redis-cluster/7000/
slave-serve-stale-data yes
slave-read-only yes
repl-diskless-sync no
repl-diskless-sync-delay 5
repl-disable-tcp-nodelay no
slave-priority 100
lazyfree-lazy-eviction no
lazyfree-lazy-expire no
lazyfree-lazy-server-del no
slave-lazy-flush no
appendonly no
appendfilename "appendonly.aof"
appendfsync everysec
no-appendfsync-on-rewrite no
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
aof-load-truncated yes
aof-use-rdb-preamble no
lua-time-limit 5000
slowlog-log-slower-than 10000
slowlog-max-len 128
latency-monitor-threshold 0
notify-keyspace-events ""
hash-max-ziplist-entries 512
hash-max-ziplist-value 64
list-max-ziplist-size -2
list-compress-depth 0
set-max-intset-entries 512
zset-max-ziplist-entries 128
zset-max-ziplist-value 64
hll-sparse-max-bytes 3000
activerehashing yes
client-output-buffer-limit normal 0 0 0
client-output-buffer-limit slave 256mb 64mb 60
client-output-buffer-limit pubsub 32mb 8mb 60
hz 10
aof-rewrite-incremental-fsync yes
cluster-enabled yes #开启集群模式
cluster-config-file nodes_7000.conf #集群node配置文件(动态更新)
cluster-node-timeout 5000 #集群的超时时间
② slave配置文件
# cp redis_7000.conf /data/redis-cluster/8000/redis_8000.conf
# sed -i 's#7000#8000#g' redis_8000.conf 3、启动集群(所有节点)
# redis-server /data/redis-cluster/7000/redis_7000.conf
# redis-server /data/redis-cluster/8000/redis_8000.conf
5、使用工具自动部署集群
1、安装ruby环境(编译安装高版本ruby,版本大于2.2)
# wget --no-check-certificate 'https://cache.ruby-lang.org/pub/ruby/2.2/ruby-2.2.7.tar.gz'
# tar xf ruby-2.2.7.tar.gz -C /usr/src/
# cd /usr/src/ruby-2.2.7/
# ./configure && make && make install
# ruby --version
2、在线安装ruby的redis扩展
# gem install redis #版本要和redis差不多,大版本号一直
# gem install redis -v 3.3.5 #可指定版本安装
3、使用工具部署集群(master上操作)
# redis-trib.rb create 10.0.0.11:7000 10.0.0.12:7000 10.0.0.13:7000
4、查看集群的信息
# redis-cli -p 7000 cluster nodes
5、操作集群
# redis-cli -c -p 7000 set name zhang3
# redis-cli -c -p 7000 get name
6、集群的重建(所有节点)
1、删除cluster集群配置文件
# rm -rf /data/redis-cluster/7000/nodes_7000.conf 2、关闭集群
# redis-cli -p 7000 shutdown 3、启动集群
# redis-server /data/redis-cluster/7000/redis_7000.conf 4、重新创建redis-cluster集群
# redis-trib.rb create 10.0.0.11:7000 10.0.0.12:7000 10.0.0.13:7000 5、查看进程
# ps -ef | grep cluster | grep -v grep
7、集群添加从库
# redis-trib.rb add-node --slave 10.0.0.12:8000 10.0.0.11:7000 #添加从8000,主7000
# redis-trib.rb add-node --slave 10.0.0.13:8000 10.0.0.12:7000
# redis-trib.rb add-node --slave 10.0.0.11:8000 10.0.0.13:7000
# redis-cli -p 7000 cluster nodes #查看集群所有节点的信息
8、其他
1、集群的主从自动切换
# redis-cli -p 7000 shutdown #手动宕掉主
# redis-cli -p 8000 cluster nodes #查看状态(从库变新主库)
# redis-server /data/redis-cluster/7000/redis_7000.conf #启动主
# redis-cli -p 8000 cluster nodes #查看状态(主库变新从库)
# redis-cli -p 7000 cluster failover #手动切换主从(主从角色切换)
# redis-cli -p 8000 cluster nodes #查看状态(新从库变旧主库) 2、Python操作集群
# yum install python2-pip
# pip install redis-py-cluster
# vim redis_cluster.py
# -*- coding:utf-8 -*-
from rediscluster import StrictRedisCluster
redis_nodes = [
{'host':'10.0.0.11','port':7000},
{'host':'10.0.0.12','port':7000},
{'host':'10.0.0.13','port':7000},
{'host':'10.0.0.11','port':8000},
{'host':'10.0.0.12','port':8000},
{'host':'10.0.0.13','port':8000}
]
redis_conn = StrictRedisCluster(startup_nodes=redis_nodes)
redis_conn.set('key_test','values_test')
print(redis_conn.get('key_test'))
# python redis_cluster.py #执行Python脚本
# redis-cli -c -p 7000 get key_test #查看key
备注: 若其中一个节点挂了,不影响使用 3、分析Redis的所有key和key的大小
# pip install rdbtools #pip安装rdbtools分析工具
# rdb -c memory redis_7000.rdb > /tmp/rdb.csv
# cat /tmp/rdb.csv | head
学习Redis(一)的更多相关文章
- 学习Redis从这里开始
本文主要内容 Redis与其他软件的相同之处和不同之处 Redis的用法 使用Python示例代码与Redis进行简单的互动 使用Redis解决实际问题 Redis是一个远程内存数据库,它不仅性能强劲 ...
- [深入学习Redis]RedisAPI的原子性分析
在学习Redis的常用操作时,经常看到介绍说,Redis的set.get以及hset等等命令的执行都是原子性的,但是令自己百思不得其解的是,为什么这些操作是原子性的? 原子性 原子性是数据库的事务中的 ...
- Redis学习——Redis事务
Redis和传统的关系型数据库一样,因为具有持久化的功能,所以也有事务的功能! 有关事务相关的概念和介绍,这里就不做介绍. 在学习Redis的事务之前,首先抛出一个面试的问题. 面试官:请问Redis ...
- Redis学习——Redis持久化之AOF备份方式保存数据
新技术的出现一定是在老技术的基础之上,并且完善了老技术的某一些不足的地方,新技术和老技术就如同JAVA中的继承关系.子类(新技术)比父类(老技术)更加的强大! 在前面介绍了Redis学习--Redis ...
- 深入学习Redis(1):Redis内存模型
前言 Redis是目前最火爆的内存数据库之一,通过在内存中读写数据,大大提高了读写速度,可以说Redis是实现网站高并发不可或缺的一部分. 我们使用Redis时,会接触Redis的5种对象类型(字符串 ...
- 深入学习Redis(5):集群
前言 在前面的文章中,已经介绍了Redis的几种高可用技术:持久化.主从复制和哨兵,但这些方案仍有不足,其中最主要的问题是存储能力受单机限制,以及无法实现写操作的负载均衡. Redis集群解决了上述问 ...
- 深入学习Redis(4):哨兵
前言 在 深入学习Redis(3):主从复制 中曾提到,Redis主从复制的作用有数据热备.负载均衡.故障恢复等:但主从复制存在的一个问题是故障恢复无法自动化.本文将要介绍的哨兵,它基于Redis主从 ...
- 深入学习Redis(3):主从复制
前言 在前面的两篇文章中,分别介绍了Redis的内存模型和Redis的持久化. 在Redis的持久化中曾提到,Redis高可用的方案包括持久化.主从复制(及读写分离).哨兵和集群.其中持久化侧重解决的 ...
- 深入学习Redis(2):持久化
前言 在上一篇文章中,介绍了Redis的内存模型,从这篇文章开始,将依次介绍Redis高可用相关的知识——持久化.复制(及读写分离).哨兵.以及集群. 本文将先说明上述几种技术分别解决了Redis高可 ...
- Redis学习---Redis操作之Python连接
PyCharm下的Redis连接 连接方式: 1. 操作模式 redis-py提供两个类Redis和StrictRedis用于实现Redis的命令,StrictRedis用于实现大部分官方的命令,并使 ...
随机推荐
- json系列(三)cjson,rapidjson,yyjson解析性能对比
前言 本篇对cjson,rapidjson,yyjson三种json反序列化工具的性能进行对比. 有json样本数据如下: 实验环境: cpu:Xeon cpu主频:2.20GHz 以下示例均未对字段 ...
- 【C#反射】动态创建类型实例
转载自:https://www.cnblogs.com/dytes/archive/2012/06/29/2569488.html .NET中除了构造函数外,还有多种方式可以创建类型的实例.下面总结了 ...
- SQL Server Cross/Outer Apply
SQL Server2005引入了APPLY运算符,它非常像连接子句,它允许两个表达式直接进行连接,即将左/外部表达式和右/内部表达式连接起来. CROSS APPLY(类比inner join)和O ...
- git问题:gpg failed to sign the data fatal: failed to write commit object问题
今天用版本控制工具git提交时一直出现的问题:gpg failed to sign the data fatal: failed to write commit object, gpg是一个加密软件 ...
- 进程&线程(一)——multiprocessing,threading
本节内容为①进程线程的基础知识:②在Python的实现方法: 学习总结自: 一文看懂Python多进程与多线程编程(工作学习面试必读) - 知乎 multiprocessing 官方文档 1.进程线程 ...
- 04-Eureka服务注册与发现
1.介绍 2.快速开始 父工程的maven 配置文件,如下 <?xml version="1.0" encoding="UTF-8"?> <p ...
- [2022-2-18] OICLASS提高组模拟赛2 A·整数分解为2的幂
题目链接 问题 A: 整数分解为 2 的幂 题目描述 任何正整数都能分解成 2 的幂,给定整数 N,求 N 的此类划分方法的数量!由于方案数量较大,输出 Mod 1000000007 的结果. 比如 ...
- git同步代码到另一分支
将dev分支的代码同步到master 方法一:用git命令 1.git checkout master 2.git merge dev 3.git push --set-upstream origin ...
- DirectX11 With Windows SDK--37 延迟渲染:光源剔除
前言 在上一章,我们主要介绍了如何使用延迟渲染,以及如何对G-Buffer进行一系列优化.而在这一章里,我们将从光源入手,讨论如何对大量的动态光源进行剔除,从而获得显著的性能提升. 在此之前假定读者已 ...
- mysql 锁表
mysql 查看锁表解锁-- 查看那些表锁到了show OPEN TABLES where In_use > 0;-- 查看进程号show processlist;--删除进程 kill 108 ...