ChCore Lab4 多核处理 实验笔记
本文为上海交大 ipads 研究所陈海波老师等人所著的《现代操作系统:原理与实现》的课程实验(LAB)的学习笔记的第四篇:多核处理。所有章节的笔记可在此处查看:chcore | 康宇PL's Blog
踩坑总结
本着早看见少踩坑的原则,我先说一些在实践中总结的一点玄学经验,如果你能搞清楚这种现象的真实原因请务必在博客底端评论区赐教一下。
薛定谔的评测结果
你可能会遇到手动 make run-xxx 样例时可以正确运行,但 make grade 有时候莫名其妙就过不了的情况。或者干脆手动 make run 时就遇到概率过不了的情况。我的猜测是因为 qemu 跑的太快导致跟时钟中断处理那部分相关的代码没有很好的运行。总之你在项目根目录的 CMakeLists.txt 里把 CMAKE_BUILD_TYPE 改成 Debug 模式,这样编译的时候优化等级会低一点,就会跑的慢一点了,此时再测试大部分情况下就能正常了。考虑部分用于调试的输出语句可能影响评测程序的运行,所以保险起见可以在同个文件中将下面代码里的 DLOG_LEVEL 赋值为 1 。
if (CMAKE_BUILD_TYPE STREQUAL "Debug")
add_definitions("-DLOG_LEVEL=2")
记得 commit 代码前把这些选项都还原回去。
但薛定谔的诡异之处在于它的不可预测性,当我在虚拟机里跑的时候情况又反过来了,Debug 模式容易出错,Release 模式很少出错。这还真是神奇呐......
2021/07/03 补记
今天得到网友 james_ling 的提醒,ChCore 里的 printf() 是线程不安全的。源代码中也有提到这一点:
/*
* NOTE: this function is not thread safe. Use it at your own risk when multi threading
*/
void printf(char *fmt, ...);
而在我的实现中部分代码用到了 kwarn() 这个宏,它间接调用了 printf(),因此也是线程不安全的。原先我只是看见 ChCore 原始代码里部分地方用到了它也学着用了。现在想来需要保证使用 kwarn() 的地方都得保证拿到大内核锁才行。我粗暴的把所有 kwarn() 都换成 kdebug() 后再在 Release 模式下 make grade 就没有再遇到薛定谔现象了
多线程调试
这节需要用到多线程调试,如果你还没有了解的话请立即去搜索下“gdb 怎么调试多线程”。
多核支持
多核启动
在源码里看到 BSP、 AP、SMP 时我是非常疑惑的,因为整个讲义里完全没说这是啥。搜了下才知道这是说主 CPU(Boot Strap Processor)、副 CPU(Application Processor)、对称多处理器(Symmetrical Multi-Processing)。
分析一下最新版的 boot/start.S 里的 _start 函数。可知其逻辑:
1)当前 CPU 为主 CPU:正常初始化
2)当前 CPU 为副 CPU:设置好栈后循环等待直到 secondary_boot_flag[cpuid] != 0,跳转到 secondary_init_c
BEGIN_FUNC(_start)
/* 当前 cpuid 放在 X8 寄存器里 */
mrs x8, mpidr_el1
and x8, x8, #0xFF
cbz x8, primary
/* Wait for bss clear */
wait_for_bss_clear:
adr x0, clear_bss_flag
ldr x1, [x0]
cmp x1, #0
bne wait_for_bss_clear
/* Turn to el1 from other exception levels. */
bl arm64_elX_to_el1
/* Prepare stack pointer and jump to C. */
/* 设置当前栈为 boot_cpu_stack[cpuid] */
mov x1, #0x1000
mul x1, x8, x1
adr x0, boot_cpu_stack
add x0, x0, x1
add x0, x0, #0x1000
mov sp, x0
wait_until_smp_enabled:
/* CPU ID should be stored in x8 from the first line */
/* while( secondary_boot_flag[cpuid] == 0 ); */
mov x1, #8
mul x2, x8, x1
ldr x1, =secondary_boot_flag
add x1, x1, x2
ldr x3, [x1]
cbz x3, wait_until_smp_enabled
/* Set CPU id */
mov x0, x8
bl secondary_init_c
primary:
/* Turn to el1 from other exception levels. */
bl arm64_elX_to_el1
/* Prepare stack pointer and jump to C. */
adr x0, boot_cpu_stack
add x0, x0, #0x1000
mov sp, x0
bl init_c
/* Should never be here */
b .
END_FUNC(_start)
主 CPU 在完成自己的初始化后调用 enable_smp_cores,在此设置 secondary_boot_flag[cpuid] = 1,让副 CPU 可以继续执行完成初始化。
为了保证并发安全,故要求副 CPU 有序的、逐个的初始化,每个副 CPU 初始化完应设置 cpu_status[cpuid] = cpu_run,只有在上个设置好后才可以设置下个副 CPU 的 secondary_boot_flag[cpuid]
void enable_smp_cores(void *addr)
{
int i = 0;
long *secondary_boot_flag;
/* Set current cpu status */
cpu_status[smp_get_cpu_id()] = cpu_run;
secondary_boot_flag = (long *)phys_to_virt(addr);
for (i = 0; i < PLAT_CPU_NUM; i++) {
*(secondary_boot_flag + i) = 1;
while(cpu_status[i] != cpu_run);
}
kinfo("All %d CPUs are active\n", PLAT_CPU_NUM);
}
副 CPU 设置 cpu_status[cpuid] 的代码则在 secondary_start 中。
void secondary_init_c(int cpuid)
{
el1_mmu_activate();
secondary_cpu_boot(cpuid);
}
BEGIN_FUNC(secondary_cpu_boot)
/* We store the logical cpuid in TPIDR_EL1 */
msr TPIDR_EL1, x0
mov x1, #KERNEL_STACK_SIZE
mul x2, x0, x1
ldr x3, =kernel_stack
add x2, x2, x3
add x2, x2, KERNEL_STACK_SIZE
mov sp, x2
bl secondary_start
END_FUNC(secondary_cpu_boot)
void secondary_start(void)
{
kinfo("AP %u is activated!\n", smp_get_cpu_id());
exception_init_per_cpu();
cpu_status[smp_get_cpu_id()] = cpu_run;
/* Where the AP first returns to the user mode */
sched();
eret_to_thread(switch_context());
}
排号自旋锁
下面展示了一种排号自旋锁的实现。排号锁结构体包括 next 和 owner 成员,owner 表示锁的当前持有者的序号,next 表示下一个可分发的序号。当尝试获取排号锁时会通过原子操作分配一个 next 表示当前的序号,并同时将锁的 next 自增一。拿到序号后一直等到 ower 和当前序号相等时便算是拿到了锁,可以继续执行,否则一直忙等待。解锁操作则只需要将 owner++,相当于将锁传给了下一个序号的等待者。
struct lock {
volatile int owner;
volatile int next;
};
void lock_init(struct lock *lock) {
lock->owner = 0;
lock->next = 0;
}
void lock(struct lock *lock) {
/* 原子操作,相当于 my_ticket = lock->next; lock->next++; */
volatile int my_ticket = atomic_FAA(&lock->next, 1);
while(lock->owner != my_ticker);
}
void unlock(struct lock *lock) {
lock->owner++;
}
int is_lock(struct lock *lock) {
return lock->owner != lock->next;
}
ChCore 里已经实现好了 lock() 函数,我们只要写两行 unlock() 和 is_lock() 就行。
大内核锁
ChCore 使用最简单的方法解决内核态间多核的并发控制问题:只要操作内核数据就得获得大内核锁,并在退出内核态前释放掉。保证了同时只有一个 CPU 执行内核代码、访问内核数据。
大内核锁的本体就是排号自旋锁的简单封装
struct lock big_kernel_lock;
void kernel_lock_init(void) {
lock_init(&big_kernel_lock);
}
void lock_kernel(void) {
lock(&big_kernel_lock);
}
void unlock_kernel(void) {
// 解锁前要保证锁处于上锁状态,部分样例会检测这一点
if (is_locked(&big_kernel_lock))
unlock(&big_kernel_lock);
}
ChCore 中上锁的地方比较零散,包括中断处理时、系统调用时、激活副 CPU 前等等。对于涉及中断的地方要特别考虑下该中断是在发生自内核态还是在发生自用户态,对于发生自内核态的(所有 EL1t 和 EL1h 后缀的)都不要加锁,因为同处内核态不能重复加锁。
解锁的地方只有一处 exception_return,因为只要想从内核态返回用户态,都得经过此处。
调度
ChCore 中先实现协作式线程调度,再在此基础上实现抢占式调度。
协作式调度需要线程主动使用 sys_yield() 将 CPU 控制权让位给其他线程,抢占式调度则是由内核给每个线程分配一定的 CPU 时间片,当线程的时间片用完后由内核强制的将 CPU 控制权移交给另一个线程。
协作式调度
ChCore 中将调度算法封装为了包含若干函数指针的结构体 sched_ops,选用不同的调度算法时只要切换下 sched_ops 就行。
/* Indirect function call may downgrade performance */
struct sched_ops {
int (*sched_init) (void);
int (*sched) (void);
int (*sched_enqueue) (struct thread * thread);
int (*sched_dequeue) (struct thread * thread);
struct thread *(*sched_choose_thread) (void);
void (*sched_handle_timer_irq) (void);
/* Debug tools */
void (*sched_top) (void);
};
// 时间片轮转调度策略
struct sched_ops rr = {
.sched_init = rr_sched_init,
.sched = rr_sched,
.sched_enqueue = rr_sched_enqueue,
.sched_dequeue = rr_sched_dequeue,
.sched_choose_thread = rr_sched_choose_thread,
.sched_handle_timer_irq = rr_sched_handle_timer_irq,
};
当前 Lab 中 ChCore 使用 Round Robin (时间片轮转)调度策略。每个 CPU 都有自己的就绪队列,表示已经准备好的、可以调度的线程。另外每个 CPU 还有一个空闲进程 idle,用于在没有线程就绪时上去顶位。如果不这样做那 CPU 发现没有能调度的线程时就会卡在内核态,而我们进入内核态时都是持有大内核锁的,你这个 CPU 在内核态干等着不出来,那其他 CPU 就拿不到大内核锁,无法进入内核态了。
rr_sched_init 为已经实现好的初始化函数,会将就绪队列 rr_ready_queue 和空闲线程 idle_threads 初始化。它只在主 CPU 初始时被调用一次。
rr_sched_enqueue 表示将线程插入就绪队列,并设置进程状态为就绪态,关联到当前 CPU 上。需要注意下合法性判断(指针为空、是否为 idle 线程、是否已经处于就绪态)。
rr_sched_dequeue 为出队列操作。弹出的线程被标记为处于 TS_INTER 这个特殊的中间态。依旧是要注意合法性检测。
rr_sched_choose_thread 负责从就绪队列中选择一个线程。就绪队列为空时就选择 idle 线程。
rr_sched 为调度操作的核心函数。先将当前线程插入就绪队列,然后通过 rr_sched_choose_thread 取出下一个就绪的线程,然后用 switch_to_thread 将其设为运行态,并让当前线程指针指向它。
实际实现的时候容易在诸多的小细节上出错,多用用 make qemu 根据最新的 BUG 信息来面向样例编程吧。
下面代码中涉及 budget 和 affinity的操作将在抢占式调度中讲解
int rr_sched_enqueue(struct thread *thread)
{
if (thread == NULL || thread->thread_ctx == NULL)
return -1;
if (thread->thread_ctx->type == TYPE_IDLE) {
return 0;
}
if (thread->thread_ctx->state == TS_READY) {
return -1;
}
s32 aff = thread->thread_ctx->affinity;
if (aff == NO_AFF)
thread->thread_ctx->cpuid = smp_get_cpu_id();
else if (aff < PLAT_CPU_NUM)
thread->thread_ctx->cpuid = aff;
else {
//kwarn("thread->thread_ctx->affinity >= PLAT_CPU_NUM\n");
return -1;
}
thread->thread_ctx->state = TS_READY;
list_append(&thread->ready_queue_node, &rr_ready_queue[thread->thread_ctx->cpuid]);
return 0;
}
int rr_sched_dequeue(struct thread *thread)
{
if (thread == NULL
|| thread->thread_ctx == NULL
|| list_empty(&thread->ready_queue_node)
|| thread->thread_ctx->affinity >= PLAT_CPU_NUM
|| thread->thread_ctx->type == TYPE_IDLE
|| thread->thread_ctx->state != TS_READY) {
return -1;
}
thread->thread_ctx->state = TS_INTER;
list_del(&thread->ready_queue_node);
return 0;
}
struct thread *rr_sched_choose_thread(void)
{
u32 cpu_id = smp_get_cpu_id();
if (list_empty(&rr_ready_queue[cpu_id]))
goto ret_idle;
struct thread *ret = list_entry(rr_ready_queue[cpu_id].next, struct thread, ready_queue_node);
if (rr_sched_dequeue(ret)) {
goto ret_idle;
}
return ret;
ret_idle:
return &idle_threads[cpu_id];
}
int rr_sched(void)
{
if (current_thread != NULL
&& current_thread->thread_ctx->type != TYPE_IDLE) {
if (current_thread->thread_ctx->sc->budget > 0) {
return -1;
}
if (rr_sched_enqueue(current_thread)) {
return -1;
}
}
struct thread *target = rr_sched_choose_thread();
rr_sched_refill_budget(target, DEFAULT_BUDGET);
switch_to_thread(target);
return 0;
}
线程切换流程
目前 ChCore 的线程切换过程步骤有:
1)当前线程主动(协作式调度)或者被动(抢占式调度)的引发中断,陷入内核态,在中断程序入口处调用 exception_enter 保存上下文。
2)调用 sched 函数。切换 current_thread
3)eret_to_thread(switch_context()),恢复 current_thread 的上下文到寄存器中。
为了用户态能够主动让出 CPU,我们提供了 sys_yield 系统调用。
void sys_yield(void)
{
sched();
eret_to_thread(switch_context());
}
此时 make run-yield_single 可以观察到在单 CPU 下两个线程可以通过 sys_yield 来交替的运行。
Hello, I am thread 0
Hello, I am thread 1
Iteration 0, thread 0, cpu 0
Iteration 0, thread 1, cpu 0
Iteration 1, thread 0, cpu 0
Iteration 1, thread 1, cpu 0
抢占式调度
时钟中断与抢占
为了支持内核抢占 CPU,我们需要启用时钟中断。每个一小段时间触发一个硬件定时器中断。
void exception_init_per_cpu(void)
{
timer_init();
set_exception_vector();
disable_irq();
}
相应的给每个线程分配一个整形变量调度预算 budget。每次触发时钟中断都会让 budget 减一。当且仅当 budget 变成零时该线程才可以被抢占。所以需要在 rr_sched 里加点验证操作。
static inline void rr_sched_refill_budget(struct thread *target, u32 budget)
{
if(target && target->thread_ctx && target->thread_ctx->type != TYPE_IDLE)
target->thread_ctx->sc->budget = budget;
}
int rr_sched(void)
{
// ......
if (rr_sched_enqueue(current_thread)) {
return -1;
}
// ......
}
时钟中断发生时将沿着 handle_irq -> plat_handle_irq -> handle_timer_irq -> sched_handle_timer_irq -> rr_sched_handle_timer_irq 的顺序逐级调用,最终我们要在 rr_sched_handle_timer_irq 对 budget 做一下变更操作。
void rr_sched_handle_timer_irq(void)
{
// 各种判断不能少,部分样例会针对这一点
if (current_thread == NULL
|| current_thread->thread_ctx->type == TYPE_IDLE)
return;
if (current_thread->thread_ctx->sc->budget > 0)
current_thread->thread_ctx->sc->budget--;
}
在时钟中断返回前也要检查下能不能进行调度。
void handle_irq(int type)
{
if (type > ERROR_EL1h)
lock_kernel();
plat_handle_irq();
sched();
eret_to_thread(switch_context());
}
系统调用 sys_yield 是立刻进行切换,所以我们也要对 budget 做一下清零操作。
void sys_yield(void)
{
current_thread->thread_ctx->sc->budget = 0;
sched();
eret_to_thread(switch_context());
}
处理器亲和性
目前 ChCore 创建的线程与父线程都在同一个 CPU 上,没有办法分发到其他的 CPU 上。为了解决这一问题我们给每个线程引入一个亲和性 affinity 标识。当将线程插入就绪队列时,如果它的 affinity 为 NO_AFF,那就插到当前 CPU 的就绪队列里;否则插到 affinity 号 CPU 的就绪队列里。如此变成了将线程分发到其他 CPU 上的操作。
int rr_sched_enqueue(struct thread *thread)
{
// ......
s32 aff = thread->thread_ctx->affinity;
if (aff == NO_AFF)
thread->thread_ctx->cpuid = smp_get_cpu_id();
else if (aff < PLAT_CPU_NUM)
thread->thread_ctx->cpuid = aff;
else {
//kwarn("thread->thread_ctx->affinity >= PLAT_CPU_NUM\n");
return -1;
}
thread->thread_ctx->state = TS_READY;
list_append(&thread->ready_queue_node, &rr_ready_queue[thread->thread_ctx->cpuid]);
return 0;
}
int rr_sched_dequeue(struct thread *thread)
{
if ( // ......
|| thread->thread_ctx->affinity >= PLAT_CPU_NUM)
return -1;
// ......
}
同时我们还对用户提供了 get 和 set 亲和性的系统调用。
int sys_set_affinity(u64 thread_cap, s32 aff)
{
// ......
if (thread == NULL || thread->thread_ctx == NULL)
return -1;
thread->thread_ctx->affinity = aff;
return 0;
}
int sys_get_affinity(u64 thread_cap)
{
// ......
if (thread == NULL || thread->thread_ctx == NULL)
return -1;
return thread->thread_ctx->affinity;
}
spawn()
Linux 里使用 fork() 和 exec() 两个步骤来执行一个程序文件。 但还存在 spawn() 这个接口实现了前两者组合后的功能。在 Linux 下查阅 posix_spawn() 的 manpage 可知, spawn() 是为了在某些没有 MMU 的小型机上用来在一定范围内替代 fork() 的。
对于 ChCore 来说 spawn() 的流程与 Lab 3 里的 process_create_root() 比较相似,Lab 3 分析好了这一部分做起来还是蛮简单的。
spawn() 中的用户栈
先来分析下讲义里的这张图:
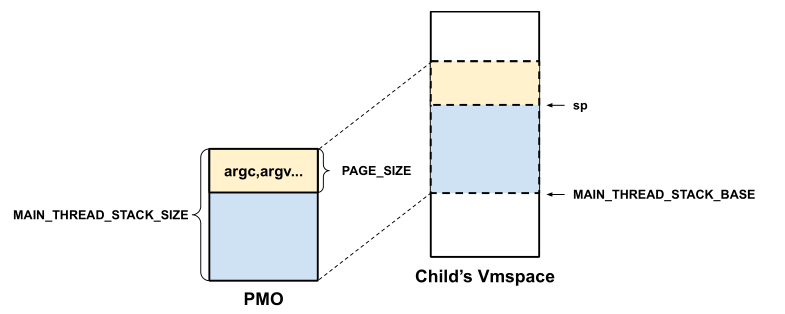
从中我们可以提取出的信息有:
子进程的用户栈基地址为 MAIN_THREAD_STACK_BASE,大小为 MAIN_THREAD_STACK_SIZE,这几个宏都在 def.h 有定义。
用户栈顶部的一个 PAGE_SIZE 的空间用来存放用户程序的各种启动参数,程序开始运行时栈顶指针 SP 应该指向这个页的末尾处,即 MAIN_THREAD_STACK_BASE + MAIN_THREAD_STACK_SIZE - PAGE_SIZE 。
spawn() 的流程
下面分析下 spawn() 的源码,为了节约篇幅删掉了异常处理的代码。建议对比着 Lab 3 里对 process_create_root() 的分析来看。
int spawn(char *path, int *new_process_cap, int *new_thread_cap,
struct pmo_map_request *pmo_map_reqs, int nr_pmo_map_reqs, int caps[],
int nr_caps, int aff)
{
struct user_elf user_elf;
int ret;
// 将 ELF 文件整个读入内存中
ret = readelf_from_kernel_cpio(path, &user_elf);
// 创建子进程并解析 ELF 文件
return launch_process_with_pmos_caps(&user_elf, new_process_cap,
new_thread_cap, pmo_map_reqs,
nr_pmo_map_reqs, caps, nr_caps,
aff);
}
int launch_process_with_pmos_caps(struct user_elf *user_elf,
int *child_process_cap,
int *child_main_thread_cap,
struct pmo_map_request *pmo_map_reqs,
int nr_pmo_map_reqs, int caps[], int nr_caps,
s32 aff)
{
// 创建新进程作为子进程
new_process_cap = usys_create_process();
// 将 ELF 文件的各个程序段映射到子进程的对应位置处
// 类似于 load_binary
for (i = 0; i < 2; ++i) {
p_vaddr = user_elf->user_elf_seg[i].p_vaddr;
ret = usys_map_pmo(new_process_cap,
user_elf->user_elf_seg[i].elf_pmo,
ROUND_DOWN(p_vaddr, PAGE_SIZE),
user_elf->user_elf_seg[i].flags);
}
pc = user_elf->elf_meta.entry;
// 创建一个大小为 MAIN_THREAD_STACK_SIZE 的 PMO 作为用户栈
// PMO 类型取 PMO_DATA 原因参考 thread_create_main 中对 PMO 的处理
pmo_requests[0].size = MAIN_THREAD_STACK_SIZE;
pmo_requests[0].type = PMO_DATA;
ret = usys_create_pmos((void *)pmo_requests, 1);
// 创建好的 cap 就是用户栈的 cap
main_stack_cap = pmo_requests[0].ret_cap;
// 为了实现共享内存机制,将父进程制定的 capability 传递给子进程
if (nr_caps > 0) {
/* usys_transfer_caps is used during process creation */
ret = usys_transfer_caps(new_process_cap, caps, nr_caps,
transfer_caps);
}
// 还是为了支持共享内存,把传递过来的 PMO 挨个映射一遍
if (nr_pmo_map_reqs) {
ret =
usys_map_pmos(new_process_cap, (void *)pmo_map_reqs,
nr_pmo_map_reqs);
}
// 类似于 thread_create_main 里的 prepare_env
// 把子进程要用的各种参数存放到用户栈最顶上的那一个初始页中
stack_top = MAIN_THREAD_STACK_BASE + MAIN_THREAD_STACK_SIZE;
stack_offset = MAIN_THREAD_STACK_SIZE - PAGE_SIZE;
construct_init_env(init_env, stack_top, &user_elf->elf_meta,
user_elf->path, pmo_map_reqs,
nr_pmo_map_reqs, transfer_caps, nr_caps);
// 把做好的初始页写到用户栈顶部
ret = usys_write_pmo(main_stack_cap, stack_offset, init_env,
PAGE_SIZE);
// 把做好的用户栈映射到子进程的地址空间中
pmo_map_requests[0].pmo_cap = main_stack_cap;
pmo_map_requests[0].addr = MAIN_THREAD_STACK_BASE;
pmo_map_requests[0].perm = VM_READ | VM_WRITE;
ret =
usys_map_pmos(new_process_cap, (void *)pmo_map_requests, 1);
// 创建子进程的主线程,指定 SP 的地址
stack_va = MAIN_THREAD_STACK_BASE + MAIN_THREAD_STACK_SIZE - PAGE_SIZE;
main_thread_cap =
usys_create_thread(new_process_cap, stack_va, pc,
(u64) NULL, MAIN_THREAD_PRIO, aff);
// 返回子进程和其主线程的 cap
if (child_process_cap != NULL)
*child_process_cap = new_process_cap;
if (child_main_thread_cap != NULL)
*child_main_thread_cap = main_thread_cap;
进程间通信
IPC 实例
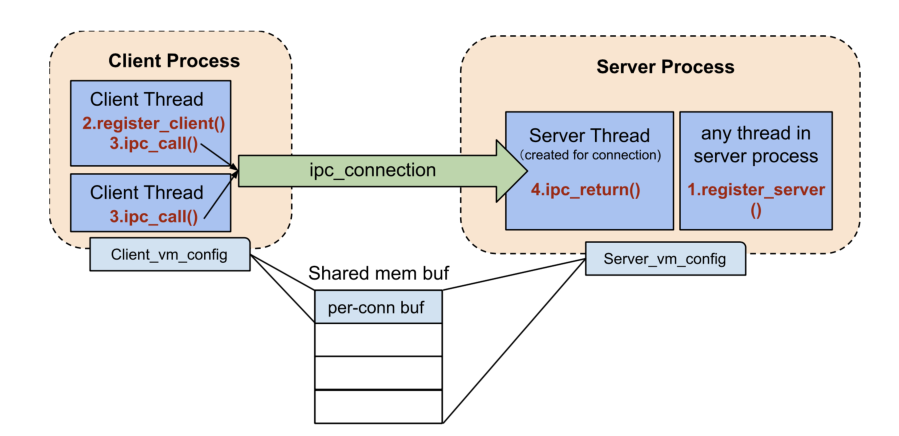
ChCore 里的进程间通信(IPC,Inter-Process Communication)类似于网络编程中的客户端—服务端模型。我们直接通过讲义里的例子来研究下用户眼里的 IPC 长啥样:

正常状态下进程间通信分为三步:
1)服务端调用 ipc_register_server() 登记自己的消息处理函数,上图里该函数为 ipc_dispatcher()
2)客户端调用 ipc_register_client() 登记自己的相关信息到指定的服务端上。
3)客户端调用 ipc_call() 向服务端发送信息,服务端在自己的消息处理函数里以函数参数的形式捕获到消息来进行后续的逻辑处理,最后使用 ipc_return() 返回处理的结果。
那客户端是如何标记自己要找的那个服务端的呢?下面引用一小段 ipc_data.c 中的代码:
ret = spawn("/ipc_data_server.bin", &new_process_cap, &new_thread_cap,
pmo_map_reqs, 1, NULL, 0, 1);
// ...
ret = ipc_register_client(new_thread_cap, &client_ipc_struct);
可以发现客户端是通过 spawn() 得到子进程的主线程的 cap,并以此来向该进程建立连接的。
IPC 原理图
接下来的部分将逐一分析 ChCore 是如何实现 IPC 的各个系统调用的。这里先放一张讲义中的图,后面不理解流程的话可以回头过来看看。
ipc_register_server()
ipc_register_server() 为 ChCore 提供的系统调用,用户只需要指定一个信号处理函数即可将当前进程等记为 IPC 的服务端进程。
该函数会创建一个 ipc_vm_config 结构体,分别用宏来指定了服务端线程里的运行时栈的和缓冲区起始地址和大小。这里请留意下目前只是地址,并未分配内存。至于它们的作用后面再讲。
struct ipc_vm_config vm_config = {
.stack_base_addr = SERVER_STACK_BASE,
.stack_size = SERVER_STACK_SIZE,
.buf_base_addr = SERVER_BUF_BASE,
.buf_size = SERVER_BUF_SIZE,
};
同时为了支持 IPC,每个线程的 thread 结构体都增加了 active_conn 和 server_ipc_config 这两个条目。server_ipc_config 中的各项含义请见注释。
#define IPC_MAX_CONN_PER_SERVER 32
struct server_ipc_config {
u64 callback; // 消息处理函数的地址
u64 max_client; // 线程支持的最大客户数量
/* bitmap for shared buffer and stack allocation */
// conn_bmp 是一个按二进制位使用的位图,在后面分配缓存区和栈时用到
unsigned long *conn_bmp;
struct ipc_vm_config vm_config; // 每个服务端都有一个 vm_config
};
前面用宏定义好的 vm_config 将被转发到 register_server() 中。在这里面设置好了 server_icp_config 的每一项,并绑定到进程的 thread 结构体中。注意此时还是未给 vm_config 的栈和缓冲区分配内存。
static int register_server(struct thread *server, u64 callback, u64 max_client,
u64 vm_config_ptr)
{
int r;
struct server_ipc_config *server_ipc_config;
struct ipc_vm_config *vm_config;
BUG_ON(server == NULL);
// Create the server ipc_config
server_ipc_config = kmalloc(sizeof(struct server_ipc_config));
server->server_ipc_config = server_ipc_config;
// Init the server ipc_config
server_ipc_config->callback = callback;
server_ipc_config->max_client = max_client;
server_ipc_config->conn_bmp =
kzalloc(BITS_TO_LONGS(max_client) * sizeof(long));
// Get and check the parameter vm_config
vm_config = &server_ipc_config->vm_config;
r = copy_from_user((char *)vm_config, (char *)vm_config_ptr,
sizeof(*vm_config));
return r;
}
ipc_register_client()
ipc_register_client(int server_thread_cap, ipc_struct_t * ipc_struct);
typedef struct ipc_struct {
u64 conn_cap; // ICP 连接的 cap,类似于 Linux 下每个管道都有一个 fd
u64 shared_buf; // 共享缓冲区的地址
u64 shared_buf_len; // 长度
} ipc_struct_t;
客户端登记时调用上面的函数,其中 server_thread_cap 可以通过 spawn() 获得,不过这也造成了因为 cap 只能在父子进程间传递,所以目前 ChCore 只能在父子间通信。ipc_struct 则是用来向客户端返回 ipc_register_client() 使用的,返回的参数见注释。
再往深处到达 ipc_register_client,在这里客户端也被创建了一个 vm_config。同服务端做下对比可发现这里并未设置栈的起始地址和长度,原因下个函数就会揭晓。
struct ipc_vm_config vm_config = {
.buf_base_addr = CLIENT_BUF_BASE,
.buf_size = CLIENT_BUF_SIZE,
};
到了 create_connection() 函数中,在这里将构建用于通信的 ipc_connection。
struct ipc_connection {
struct thread *source; /* Source Thread */
struct thread *target; /* Target Thread */
u64 server_conn_cap; /* Conn cap in server */
u64 callback; /* Target function */
u64 server_stack_top; /* Shadow server stack top */
u64 server_stack_size;
struct shared_buf buf; /* Shared buffer */
};
上面的 source 为客户端的当前线程,target 为我们在服务端进程下创建的一个新线程,作用将在 ipc_call() 中分析 。
static int create_connection(struct thread *source, struct thread *target,
struct ipc_vm_config *client_vm_config)
{
struct ipc_connection *conn = NULL;
// Get the ipc_connection
conn = obj_alloc(TYPE_CONNECTION, sizeof(*conn));
conn->target = create_server_thread(target);
栈的处理方法就比较特别了:我们前面知道了服务端的 stack_base_addr 和 stack_size,还有一个位图 conn_bmp 。接下来我们寻找到位图中首个未使用的标志位,是第几位就把临时变量 idx 记为几。
// Get the server's ipc config
server_ipc_config = target->server_ipc_config;
vm_config = &server_ipc_config->vm_config;
conn_idx = find_next_zero_bit(server_ipc_config->conn_bmp,
server_ipc_config->max_client, 0);
set_bit(conn_idx, server_ipc_config->conn_bmp);
然后通过 stack_base_addr + conn_idx * vm_config->stack_size 计算出当前这个连接使用的栈基地址,并分配一个 PMO 作为栈的内存块,然后挂载到服务端的地址空间里。为什么只挂载到服务端我们将在 ipc_call() 中分析。
// Create the server thread's stack
server_stack_base =
vm_config->stack_base_addr + conn_idx * vm_config->stack_size;
stack_size = vm_config->stack_size;
stack_pmo = kmalloc(sizeof(struct pmobject));
pmo_init(stack_pmo, PMO_DATA, stack_size, 0);
vmspace_map_range(target->vmspace, server_stack_base, stack_size,
VMR_READ | VMR_WRITE, stack_pmo);
conn->server_stack_top = server_stack_base + stack_size;
缓冲区的处理类似于栈但又不大相同。因为缓冲区算是客户端和服务端间的共享内存,所以要分别计算在客户端和服务端的虚拟地址。
// Create and map the shared buffer for client and server
server_buf_base =
vm_config->buf_base_addr + conn_idx * vm_config->buf_size;
client_buf_base = client_vm_config->buf_base_addr;
buf_size = MIN(vm_config->buf_size, client_vm_config->buf_size);
client_vm_config->buf_size = buf_size;
但分配只要分配一个 PMO 就行,把它分别挂载到客户端地址空间和服务端地址空间中。
buf_pmo = kmalloc(sizeof(struct pmobject));
pmo_init(buf_pmo, PMO_DATA, buf_size, 0);
vmspace_map_range(current_thread->vmspace, client_buf_base, buf_size,
VMR_READ | VMR_WRITE, buf_pmo);
vmspace_map_range(target->vmspace, server_buf_base, buf_size,
VMR_READ | VMR_WRITE, buf_pmo);
创建好的共享缓冲区将作为一个 shared_buf 结构体挂载到 ipc_connection 中。
/*
struct shared_buf {
u64 client_user_addr;
u64 server_user_addr;
u64 size;
};
*/
conn->buf.client_user_addr = client_buf_base;
conn->buf.server_user_addr = server_buf_base;
server_conn_cap 是将当前的 ipc_connection 挂载到服务端的 cap 列表里得出的。
conn_cap = cap_alloc(current_process, conn, 0);
server_conn_cap =
cap_copy(current_process, target->process, conn_cap, 0, 0);
conn->server_conn_cap = server_conn_cap;
return conn_cap;
out_free_stack_pmo:
}
ipc_call()
IPC 中传递消息的单位为 ipc_msg。消息的本体将写在共享缓冲区里,这里记录的是消息的相对于缓冲区起始地址的偏移和长度。如果消息比较短,那就作为一种 data 直接写到缓冲区里。如果消息比较长,那就申请一块 PMO 然后把它的 cap 写入到缓冲区里。
typedef struct ipc_msg {
u64 server_conn_cap;
u64 data_len;
u64 cap_slot_number;
u64 data_offset;
u64 cap_slots_offset;
} ipc_msg_t;
ipc_msg 的构建是在 ipc_create_msg 中完成的,这里面有个有趣的点是 ipc_msg 的本体是放在 icp_conn 的共享缓冲区开头处的。
ipc_msg_t *ipc_create_msg(ipc_struct_t * icb, u64 data_len, u64 cap_slot_number)
{
ipc_msg_t *ipc_msg;
ipc_msg = (ipc_msg_t *) icb->shared_buf;
ipc_msg->data_len = data_len;
ipc_msg->cap_slot_number = cap_slot_number;
// ......
}
之后层层调用来到 sys_ipc_call(),也是我们需要实现的函数。
首先要取出当前进程的活跃连接。
u64 sys_ipc_call(u32 conn_cap, ipc_msg_t * ipc_msg)
{
struct ipc_connection *conn = NULL;
u64 arg;
int r;
conn = obj_get(current_thread->process, conn_cap, TYPE_CONNECTION);
if (!conn) {
r = -ECAPBILITY;
goto out_fail;
}
直接用现成的 ipc_send_cap() 将 ipc_msg 里的 cap 都转移到 conn->target->process 即服务端进程的 cap 列表里。
/**
* Lab4
* Here, you need to transfer all the capbiliies of client thread to
* capbilities in server thread in the ipc_msg.
*/
r = ipc_send_cap(conn, ipc_msg);
if (r < 0)
goto out_obj_put;
r = copy_to_user((char *)&ipc_msg->server_conn_cap,
(char *)&conn->server_conn_cap, sizeof(u64));
if (r < 0)
goto out_obj_put;
讲义提示 arg 为 ipc_dispatcher() 的参数,查阅可知参数为 ipc_msg_t。直接把当前函数的 ipc_msg 放进去是不可以的,因为我们这个地址是要传给服务端的,而当前线程是在客户端的,根本不在一个地址空间里。所以只能通过其他方法搞。想到前面提到 ipc_msg 的本体是放在 icp_conn 的共享缓冲区开头处的,所以参数就是缓冲区在服务端的起始地址,即 conn->buf.server_user_addr
/**
* Lab4
* The arg is actually the 64-bit arg for ipc_dispatcher
* Then what value should the arg be?
* */
// void ipc_dispatcher(ipc_msg_t * ipc_msg)
arg = conn->buf.server_user_addr;
thread_migrate_to_server(conn, arg);
BUG("This function should never\n");
out_obj_put:
obj_put(conn);
out_fail:
return r;
}
接下来到了 thread_migrate_to_server()。在这个函数中我们将从客户端线程迁移到服务端线程,并在它的回调函数处继续执行。
static u64 thread_migrate_to_server(struct ipc_connection *conn, u64 arg)
{
struct thread *target = conn->target;
conn->source = current_thread;
target->active_conn = conn;
current_thread->thread_ctx->state = TS_WAITING;
obj_put(conn);
这时候我们前面设置好的 server_stack_top 终于派上用场了,服务端线程的堆顶就该是它。
/**
* Lab4
* This command set the sp register, read the file to find which field
* of the ipc_connection stores the stack of the server thread?
* */
arch_set_thread_stack(target, conn->server_stack_top);
下一条指令为回调函数的地址。
/**
* Lab4
* This command set the ip register, read the file to find which field
* of the ipc_connection stores the instruction to be called when switch
* to the server?
* */
arch_set_thread_next_ip(target, conn->target->server_ipc_config->callback);
这个变量名都写好了,直接赋值。
/**
* Lab4
* The argument set by sys_ipc_call;
*/
arch_set_thread_arg(target, arg);
最后设置下上下文,然后切换到服务端线程。
/**
* Passing the scheduling context of the current thread to thread of
* connection
*/
target->thread_ctx->sc = current_thread->thread_ctx->sc;
/**
* Switch to the server
*/
switch_to_thread(target);
eret_to_thread(switch_context());
/* Function never return */
BUG_ON(1);
return 0;
}
ipc_return()
ipc_return() 就比较简单了。设置下返回值,然后切换到 conn 的客户端线程,即 conn->source
void sys_ipc_return(u64 ret)
{
struct ipc_connection *conn = current_thread->active_conn;
// ...
thread_migrate_to_client(conn, ret);
// ...
}
static int thread_migrate_to_client(struct ipc_connection *conn, u64 ret_value)
{
struct thread *source = conn->source;
current_thread->active_conn = NULL;
/**
* Lab4
* The return value returned by server thread;
*/
arch_set_thread_return(source, ret_value);
/**
* Switch to the client
*/
switch_to_thread(source);
eret_to_thread(switch_context());
/* Function never return */
BUG_ON(1);
return 0;
}
ipc_reg_call()
这里我们需要实现一个更加轻量级的 ipc_call(),我们不需要向服务端的消息处理函数传递 ipc_msg 的地址,只需要传递一个 64 位的数值作为消息即可。照着 ipc_call() 改一改传给 thread_migrate_to_server 的参数就出来了。
u64 sys_ipc_reg_call(u32 conn_cap, u64 arg0)
{
struct ipc_connection *conn = NULL;
int r;
conn = obj_get(current_thread->process, conn_cap, TYPE_CONNECTION);
if (!conn) {
r = -ECAPBILITY;
goto out_fail;
}
thread_migrate_to_server(conn, arg0);
BUG("This function should never\n");
out_obj_put:
obj_put(conn);
out_fail:
return r;
}
实现好后还需要在系统调用表里登记一下
const void *syscall_table[NR_SYSCALL] = {
[0 ... NR_SYSCALL - 1] = sys_debug,
// .....
/*
* Lab4
* Add syscall
*/
[SYS_ipc_reg_call] = sys_ipc_reg_call,
// ....
参考资料
05lover/chcore: 2020 os - github
a-daydream/chcore-lab-mospi-2020 - gitee
后记
本来以为爆肝一天就能把这个 Lab 干出来,没想到在写调度模块时竟然陷进了 bug 的泥潭。自己怼了半天找不出错来,还是用网友的代码挨个替换后运行才发现的问题,一整天的时间只做完了多核支持和调度两大部分。这种自学的东西最怕出错误了,又没人沟通可能自己掉进了牛角尖里都不知道,耗掉大量的时间。所以我把自己捣鼓的过程和思路写成博客发出来也是为了方便后人掉了坑里后能有个大体的参考,最起码来说能向我一样用蛮力替换的方法定位出自己的代码错在哪了。
ChCore Lab4 多核处理 实验笔记的更多相关文章
- ChCore Lab2 内存管理 实验笔记
本文为上海交大 ipads 研究所陈海波老师等人所著的<现代操作系统:原理与实现>的课程实验(LAB)的学习笔记的第二篇.所有章节的笔记可在此处查看:chcore | 康宇PL's Blo ...
- ChCore Lab1 机器启动 实验笔记
本文为上海交大 ipads 研究所陈海波老师等人所著的<现代操作系统:原理与实现>的课程实验(LAB)的学习笔记的第一篇. 书籍官网:现代操作系统:原理与实现,里面有实验的参考指南和代码仓 ...
- ChCore Lab3 用户进程和异常处理 实验笔记
本文为上海交大 ipads 研究所陈海波老师等人所著的<现代操作系统:原理与实现>的课程实验(LAB)的学习笔记的第三篇:用户进程与异常处理.所有章节的笔记可在此处查看:chcore | ...
- SQL*Loader实验笔记【二】
所有SQL*Loader实验笔记 实验案例总结(1-7): SQL*Loader实验笔记[一] 实验案例总结(8-13): SQL*Loader实验笔记[二] 实验案例总结(14-19 ...
- centos救援模式实验笔记
1. 首先在BIOS中把启动选项设置成DVD光驱启动或者USB启动也是可以的 2. 从光盘启动之后再出现的选项中选择“Rescue installed system”然后按回车确认,具体图下图: ...
- 【目标检测大集合】R-FCN、SSD、YOLO2、faster-rcnn和labelImg实验笔记
R-FCN.SSD.YOLO2.faster-rcnn和labelImg实验笔记 转自:https://ask.julyedu.com/question/7490 R-FCNpaper:https:/ ...
- Openstack实验笔记
Openstack实验笔记 制作人:全心全意 Openstack:提供可靠的云部署方案及良好的扩展性 Openstack简单的说就是云操作系统,或者说是云管理平台,自身并不提供云服务,只是提供部署和管 ...
- Huawei-R&S-网络工程师实验笔记20190615-IP基础(AR201上配置IP)
>Huawei-R&S-网络工程师实验笔记20190615-IP基础(AR201上配置IP) >>实验开始,先上拓扑图参考: >>>一般正常配置IP操作如下 ...
- Huawei-R&S-网络工程师实验笔记20190609-VLAN划分综合(Hybrid端口)
>Huawei-R&S-网络工程师实验笔记20190609-VLAN划分综合(Hybrid端口) >>实验开始,先上拓扑图参考: >>>实验目标:分别实现主 ...
随机推荐
- Java中的list和set有什么区别
list与set方法的区别有:list可以允许重复对象和插入多个null值,而set不允许:list容器是有序的,而set容器是无序的等等 Java中的集合共包含三大类,它们分别是Set(集),Lis ...
- JDBC操作数据库的步骤 ?
注册数据库驱动. 建立数据库连接. 创建一个Statement. 执行SQL语句. 处理结果集. 关闭数据库连接.
- Java中自动装箱与拆箱
一.什么是封装类? Java中存在基础数据类型,但是在某些情况下,我们要对基础数据类型进行对象的操作,例如,集合中只能存在对象,而不能存在基础数据类型,于是便出现了包装器类.包装器类型就是对基本数据类 ...
- C语言对源程序处理的四个步骤:预处理、编译、汇编、链接——预处理篇
预处理 1)预处理的基本概念 C语言对源程序处理的四个步骤:预处理.编译.汇编.链接. 预处理是在程序源代码被编译之前,由预处理器(Preprocessor)对程序源代码进行的处理.这个过程并不对程序 ...
- PCB设计常见规则及基本原则
一.PCB基础知识 1.全称:印制电路板或者印制线路板 2.分类 材质分类:硬板(Rigid PCB).软板FPC(Flexible PCB).软硬结合板(Rigid-Flex PCB).HDI板(含 ...
- 在页面未加载完之前显示loading动画
在页面未加载完之前显示loading动画 这里有很多比这篇博客还优秀的loading动画源码 我还参考这篇博客 loading动画代码demo 我的demo预览 <!DOCTYPE html&g ...
- [翻译]Service workers:PWA背后的英雄
原文地址:https://medium.freecodecamp.org/service-workers-the-little-heroes-behind-progressive-web-apps-4 ...
- SimpleDateForma求日期,2008-11月第6周星期日是几号?
题目4: 巧妙利用SimpleDateFormat根据各种信息求日期.2008-11月第6周的星期日是几号? import java.text.ParseException;import java.t ...
- java中的排序除了冒泡以来, 再给出一种方法, 举例说明
9.5 排序: 有一种排序的方法,非常好理解,详见本题的步骤,先找出最大值和最小值,把最小值打印出来后,把它存在另一个数组b当中,再删除此最小值,之后再来一次找出最小值,打印出最小值以后,再把它存 ...
- java读取xml文件并转换成对象,并进行修改
1.首先要写工具类,处理读取和写入xml文件使用的工具.XMLUtil.javaimport java.io.FileInputStream; import java.io.FileWriter; i ...