基于深度学习的车辆检测系统(MATLAB代码,含GUI界面)
摘要:当前深度学习在目标检测领域的影响日益显著,本文主要基于深度学习的目标检测算法实现车辆检测,为大家介绍如何利用\(\color{#4285f4}{M}\color{#ea4335}{A}\color{#fbbc05}{T}\color{#4285f4}{L}\color{#34a853}{A}\color{#ea4335}{B}\)设计一个车辆检测系统的软件,通过自行搭建YOLO网络并利用自定义的数据集进行训练、验证模型,最终实现系统可选取图片或视频进行检测、标注,以及结果的实时显示和保存。其中,GUI界面利用最新的MATLAB APP设计工具开发设计完成,算法部分选择时下实用的YOLO v2/v3网络,通过BDD100K数据集进行训练、测试检测器效果。本文提供项目所有涉及到的程序代码、数据集等文件,完整资源文件请转至文末的下载链接,本博文目录如下:
完整资源下载链接:https://mianbaoduo.com/o/bread/YZaal55t
介绍及演示视频链接:https://www.bilibili.com/video/BV1oh411k7q7/(欢迎关注博主B站视频)
代码使用介绍及演示视频链接:https://www.bilibili.com/video/BV1No4y197rW/
前言
如今机器视觉领域深度学习算法已经大行其道,也让人工智能的实现不再那么遥不可及,但是在目标检测领域,让计算机超越人类还需让更多的人参与进来继续努力。如今众多的高校,甚至中小学已经将人工智能纳入了学习科目,这确实能让人感受到AI的魅力以及社会对其重视程度。研究、学习及从事AI技术已近5年,博主自认为对其中的基本知识也算学到点皮毛,因此这里开一个目标检测专栏,根据自己的经验提供点实例帮助大家入门了。
印象中玩深度学习仿佛用的都是Python,但其实现在MATLAB也是可以的,并且玩得也不赖。由于高校几乎普遍青睐MATLAB,恐怕很多人最熟悉的编程语言要属它了。在网上查阅了很久,利用MATLAB实现的这类程序属实不多,因此用它来写一个Demo就有必要了。
1. 效果演示
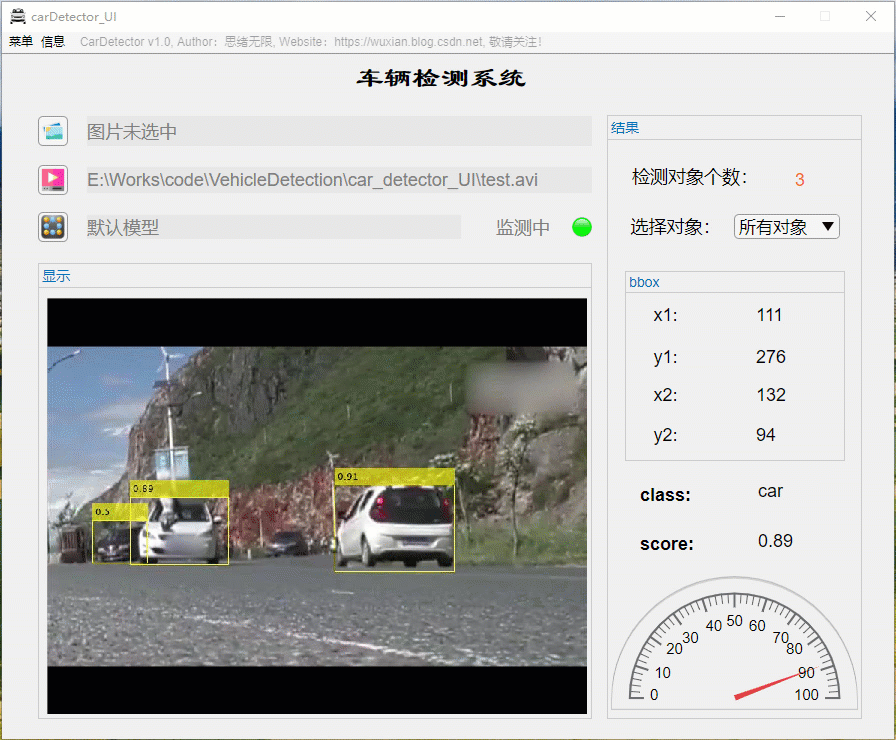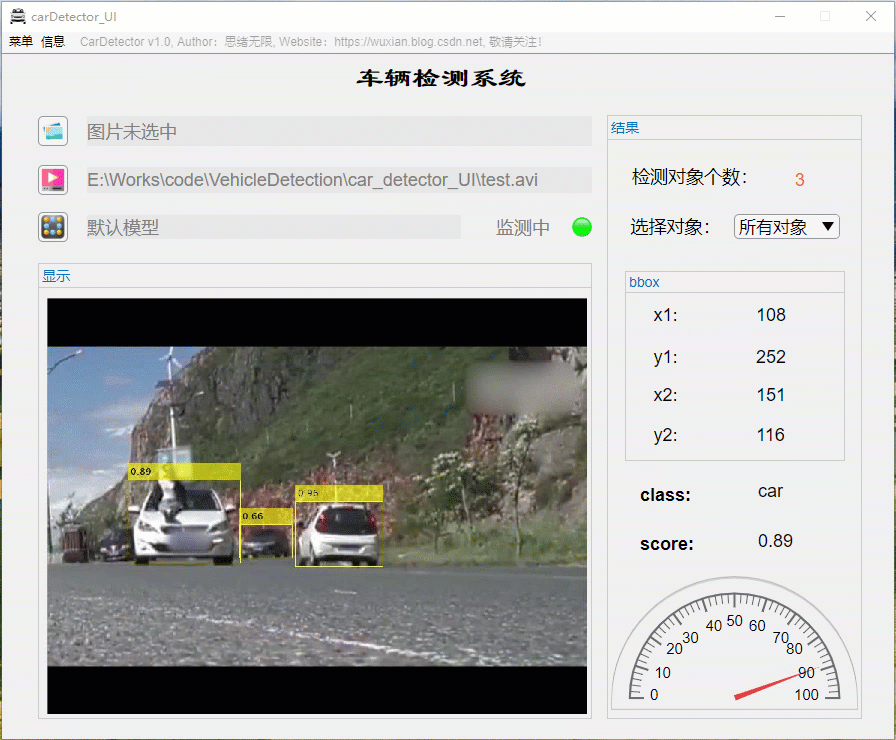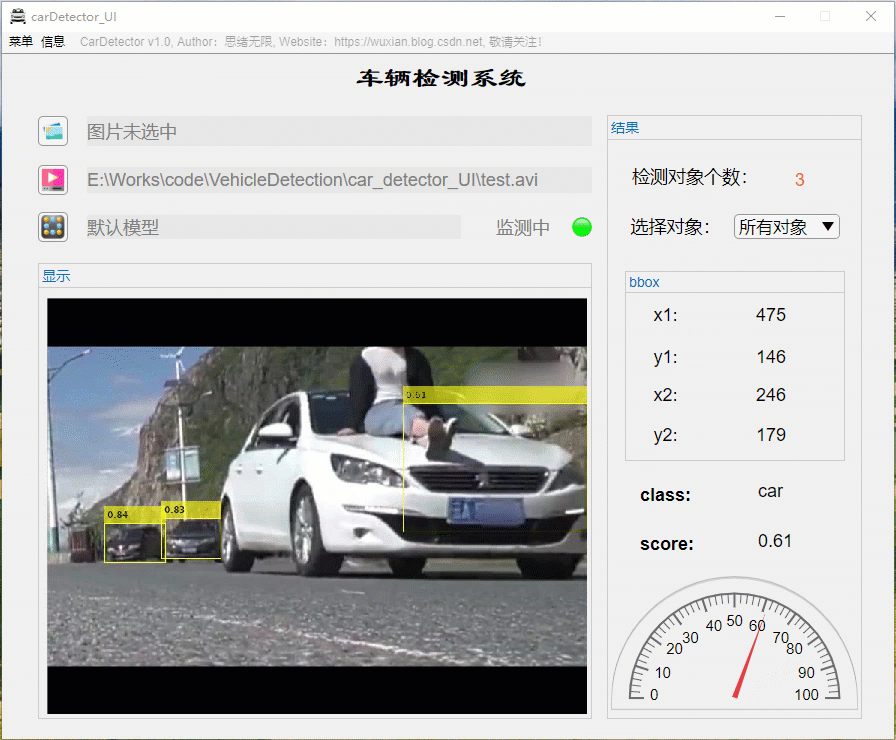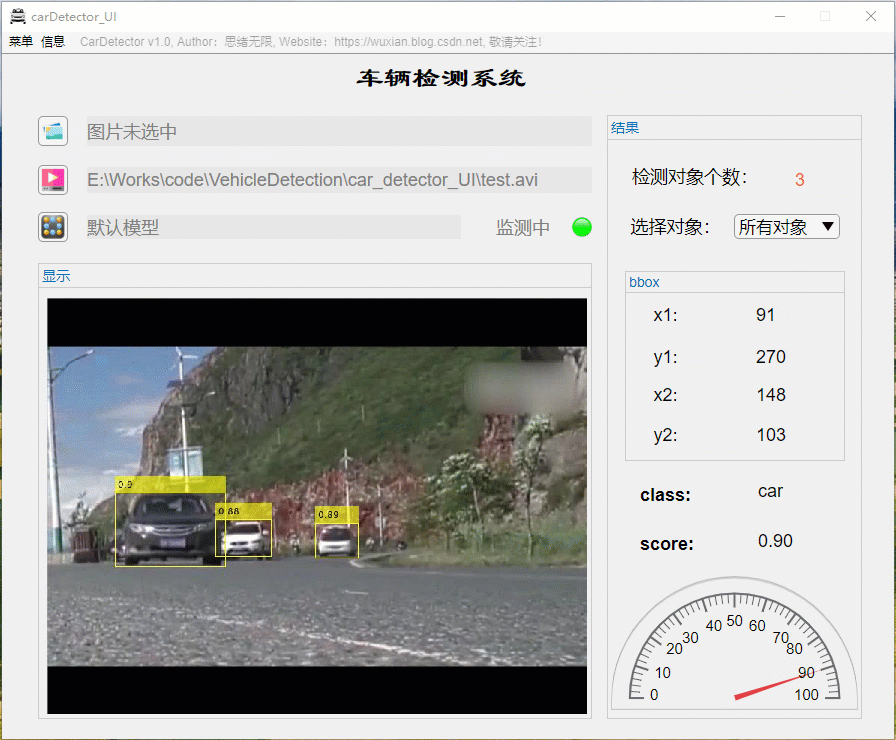
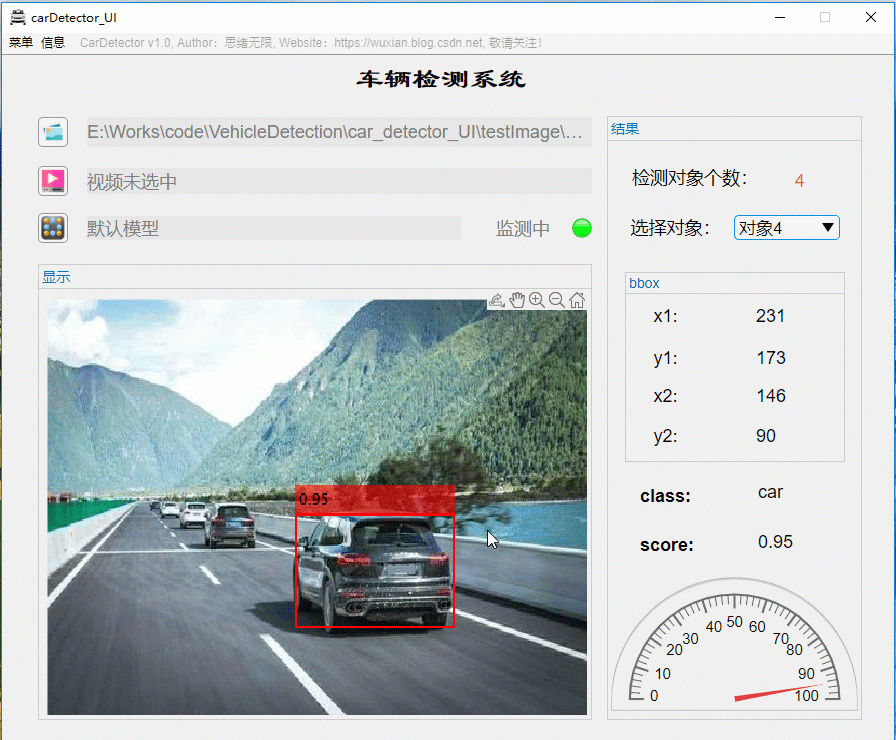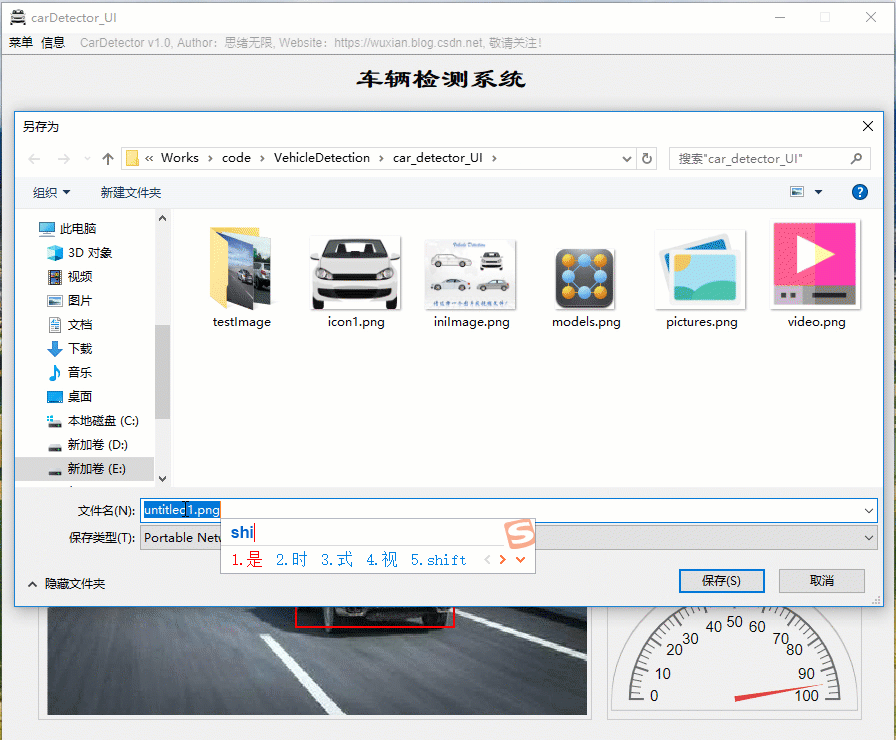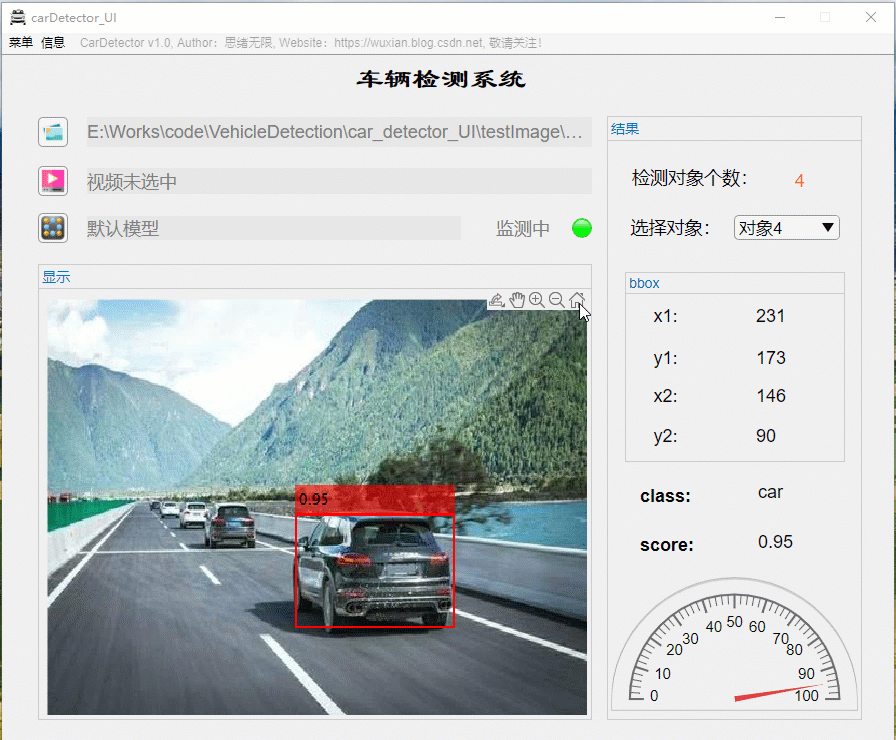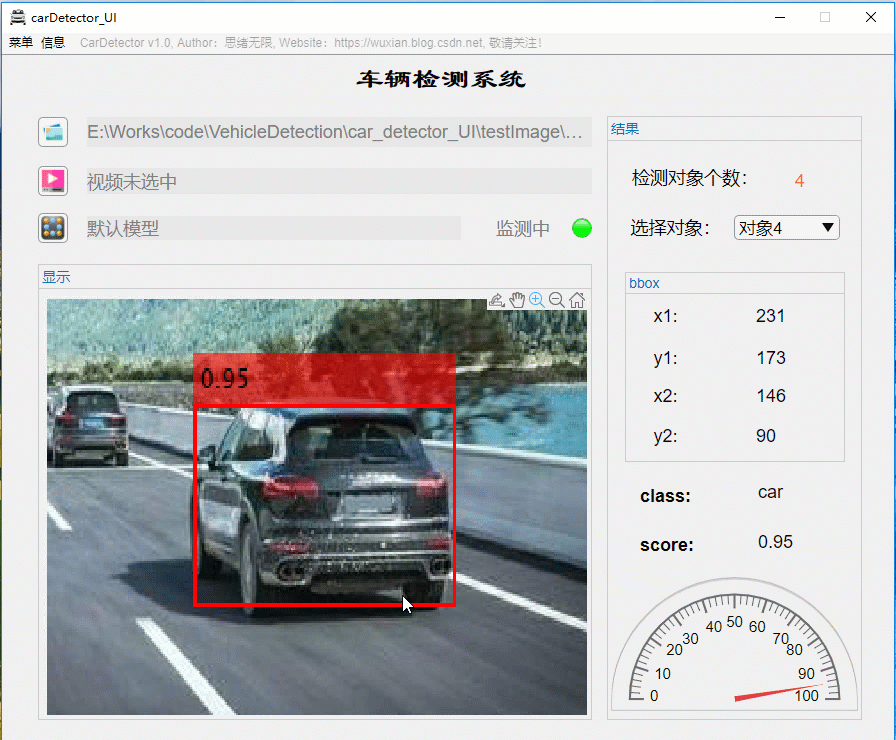
详细介绍前还是先看看整体效果吧,毕竟质量不高的资源网上多得是,没啥吸引力的恐怕大家看都不想看了。先上几个动图看看界面了,界面中默认装载了博主训练好的模型,选择一张图片可标记出目标并显示标记框位置、识别类型及置信度值,GUI界面如下图所示:
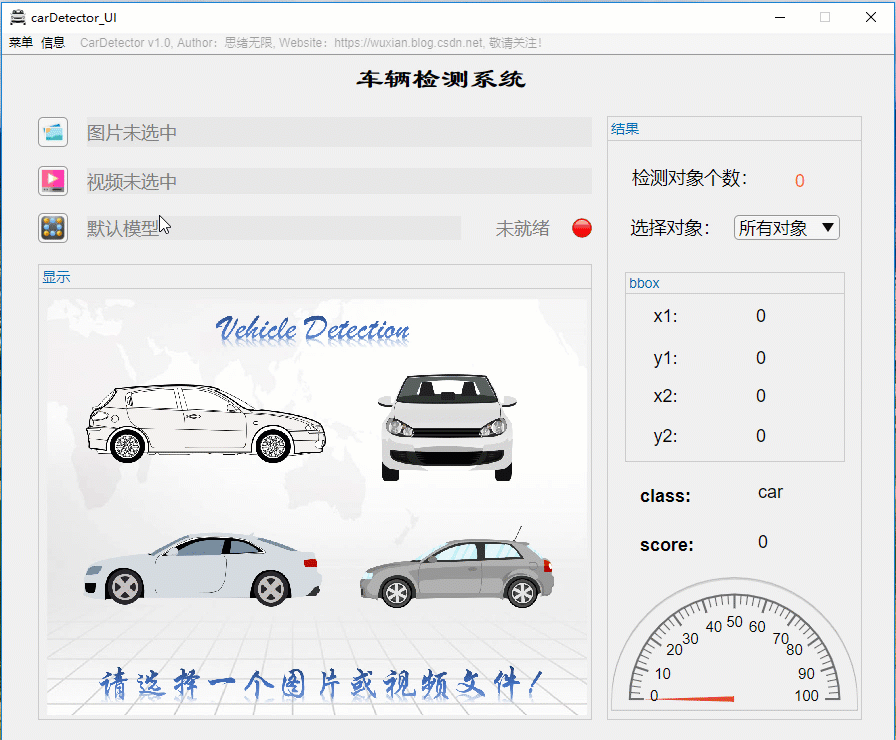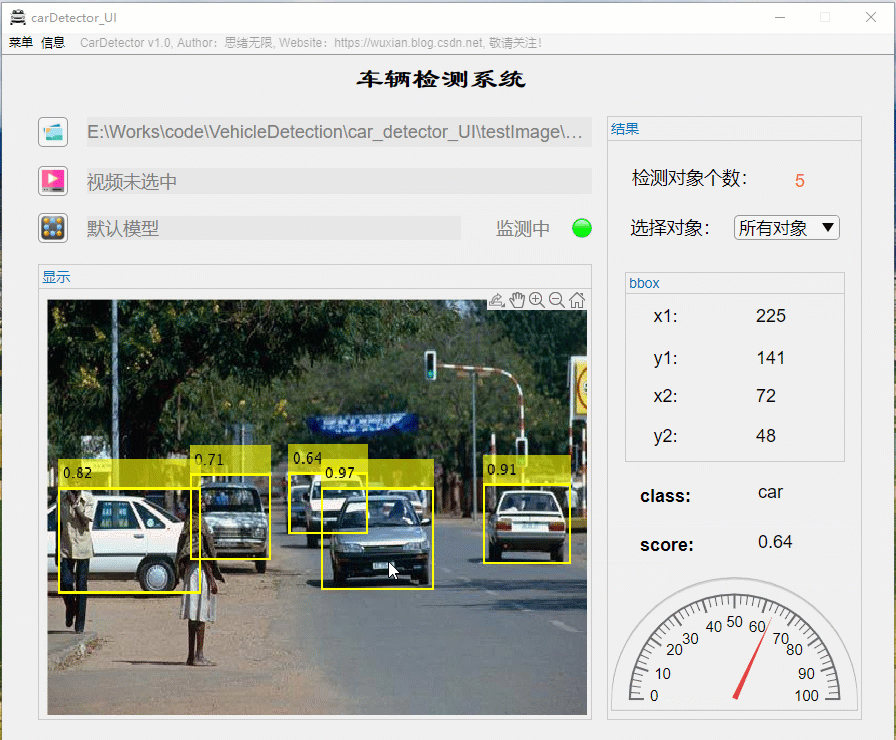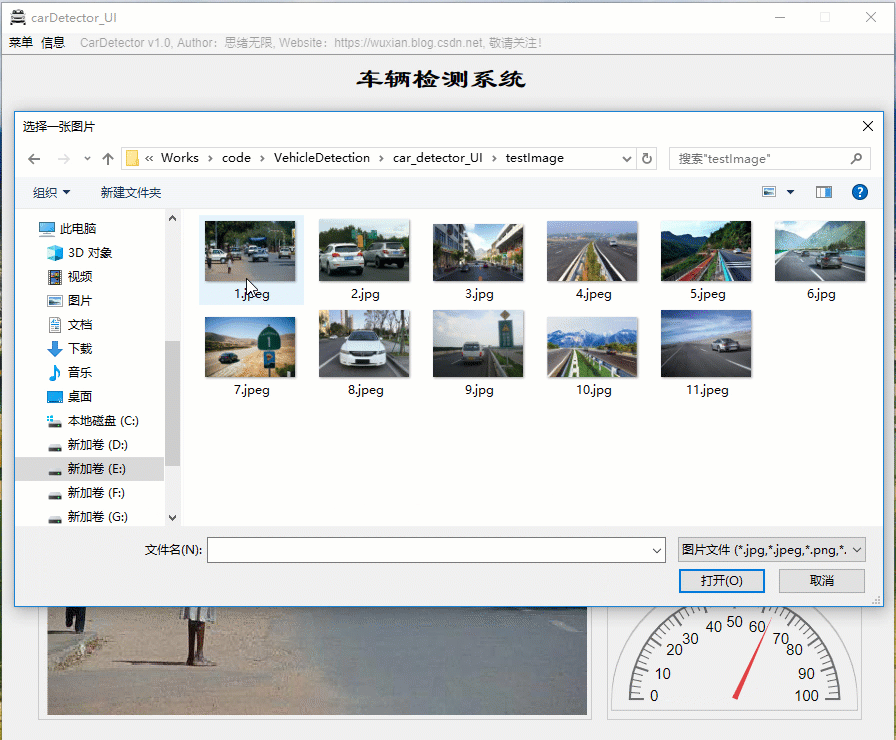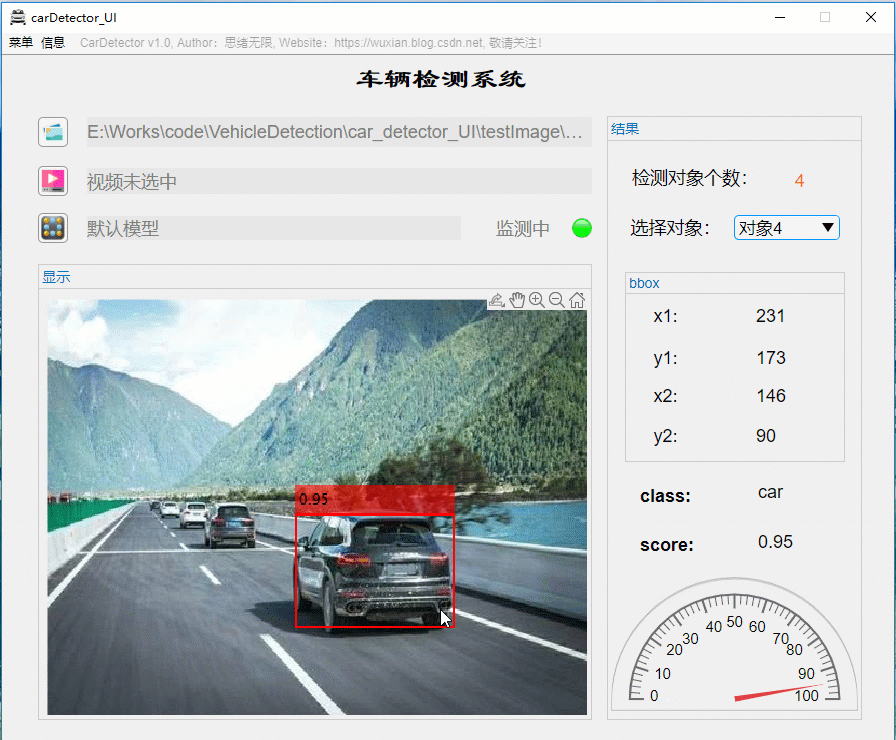
识别出的图片结果可通过显示界面右上角上的菜单栏选择另存为图片文件,将带有识别框的图片保存到自己的电脑上。另外界面可实现缩放、拖动等常见图片处理功能,展示界面如下:
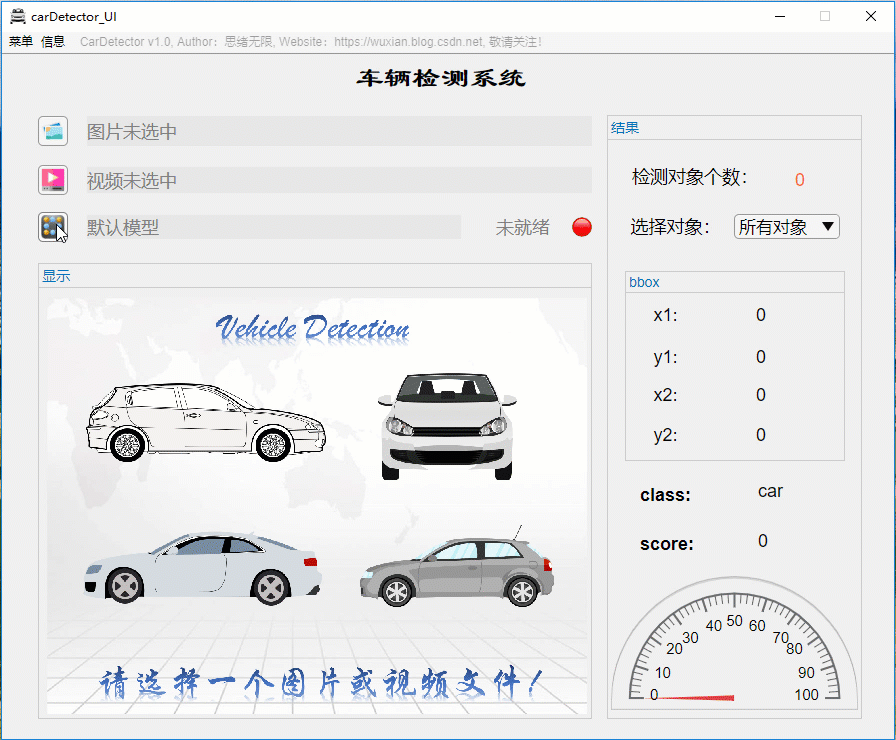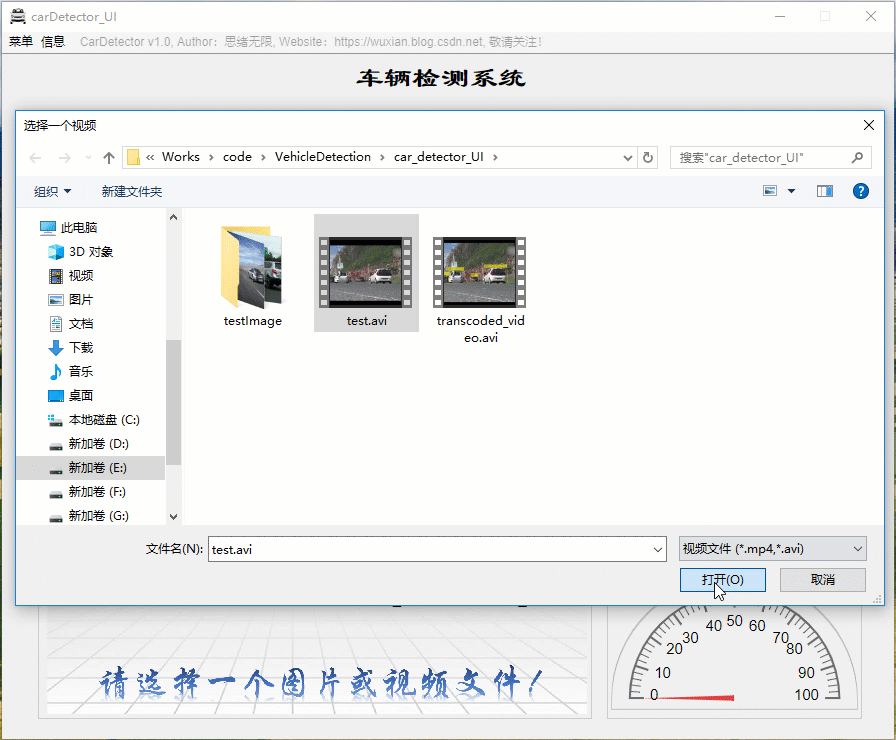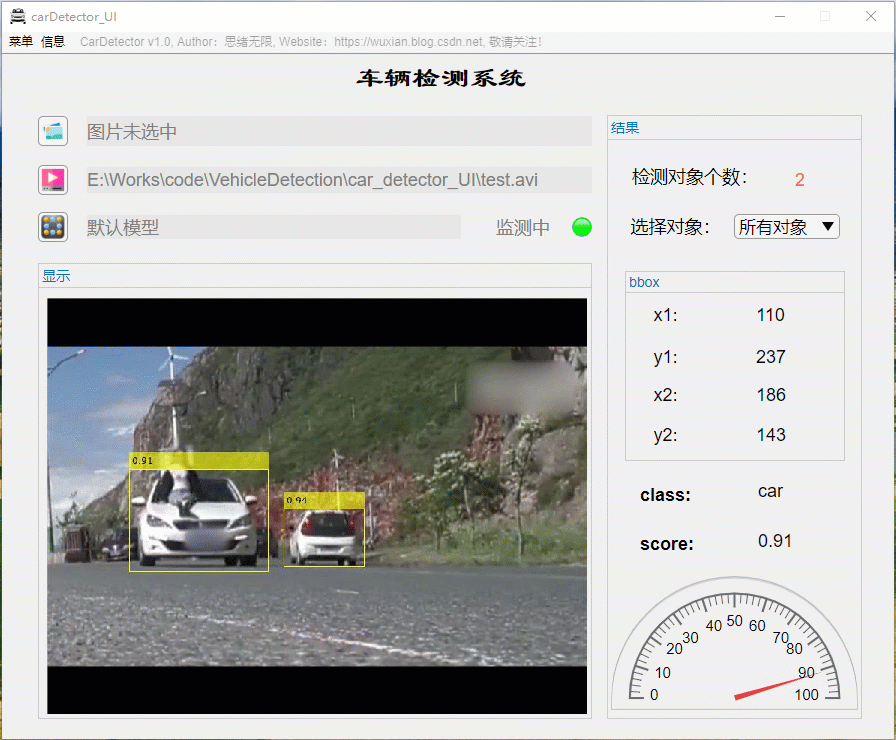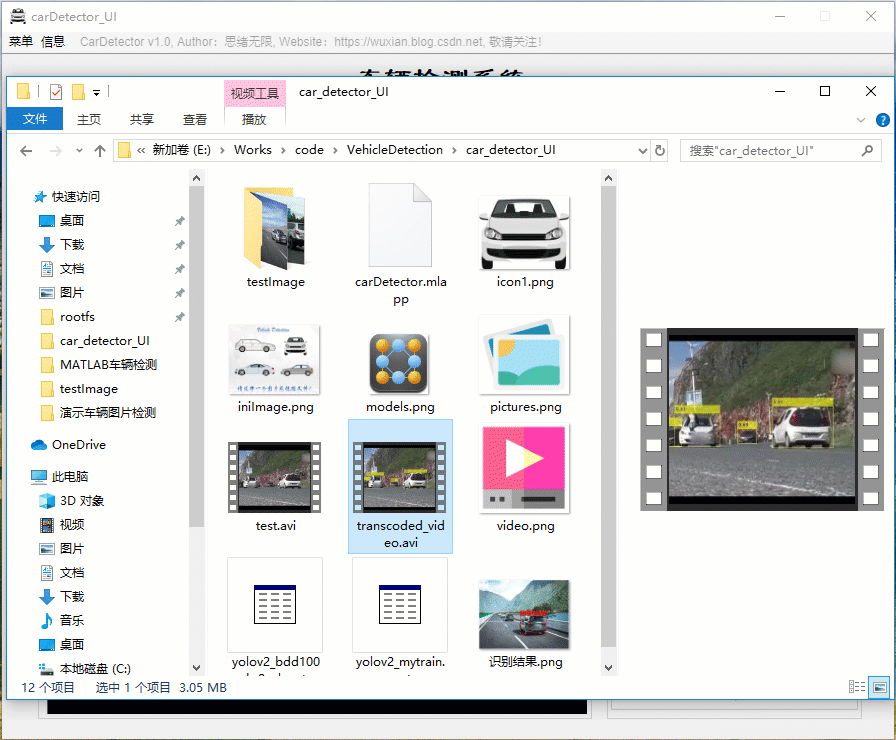
选择一个视频格式的文件可对视频进行逐帧检测,在视频中标注出检测结果显示在界面上,最终检测完成的视频文件默认保存在当前文件夹下,该功能的展示界面如下:
本项目所有功能在MATLAB R2020b中已测试通过,想要更多详细展示信息的朋友可以去博主的B站视频中查看,在下面的章节中将介绍如何实现以上展示的功能。
2. 车辆数据集
2.1 BDD 100k数据集
车辆检测的数据集目前有很多,常见的大型开源数据集当属BDD 100K十分好用了,作为自动驾驶常用大型多样化数据集,其标注超过100,000张图像,类别包含公共汽车,行人,自行车,卡车,小汽车,火车和骑手等,用于目标检测、全帧分割等。该数据集的截图如下:

若要下载该数据集,可访问它的官网地址下载,但官网国内的下载速度较慢,这里已将其整理至百度网盘,需要下载的朋友也可通过博主的博文《深度学习常见数据集介绍与下载》获取下载链接。下载后的文件目录如下:
这个数据集确实很大(约10G),训练的时间实在太长了,因此这个项目里面不使用全部的数据,而是选择其中的验证集“bdd100k_val”文件夹下的文件用于训练。要使用全部数据集的朋友可将程序中的路径修改为完整数据集文件夹。
为了使得该数据集能够方便用MATLAB处理,从原数据集的标注文件“bdd100k_labels_images_val.json”文件中抽取了小汽车的类别,并重新写入到mat文件中。筛选和处理部分图片后,标注文件的信息包括图片路径和标注框的坐标,其数据文件的信息如下:
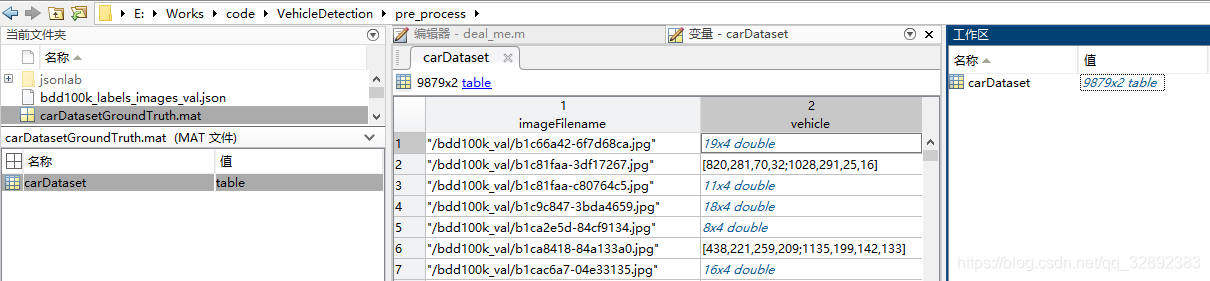
2.2 自定义数据集
若要使用自行定义的数据集可按照以上的格式进行处理,通过脚本将标注文件保存为mat格式,如下图所示为自定义的数据集的图片文件截图和标注文件:
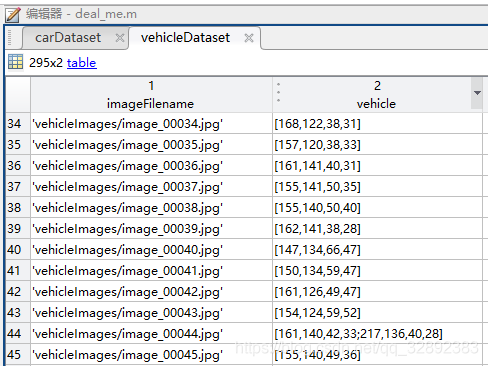
这两个数据集都已放在文件夹中,后者只有几百张图片,因此对于想要学习和调试代码的朋友会很方便。如果不是特别注重准确率,建议使用第二个数据集,在训练和测试的时候速度会快很多,最后的结果其实也还可以,不妨一试。
3. 搭建并训练网络
3.1 加载数据集
首先载入准备好的数据集,查看并显示数据信息。其次,对于图片数据集需要为训练器指定好每张图片的绝对路径,以方便读取:
clear
clc
doTraining = true; % 是否进行训练
% 解压数据
% data = load('./data/carDatasetGroundTruth.mat');
% vehicleDataset = data.carDataset; % table型,包含文件路径和groundTruth
data = load('./data/vehicleDatasetGroundTruth.mat');
vehicleDataset = data.vehicleDataset; % table型,包含文件路径和groundTruth
% 添加绝对路径至vehicleDataset中
vehicleDataset.imageFilename = fullfile([pwd, '/data/'],vehicleDataset.imageFilename);
% 显示数据集中的一个图像,以了解它包含的图像的类型。
vehicleDataset(1:4,:) % 显示部分数据情况
以上代码首先载入了标注文件,然后通过fullfile函数将当前文件夹位置添加到图片路径中,运行可以查看到部分标注信息如下:
ans =
4×2 table
imageFilename vehicle
___________________________________________________________________________ ____________
{'E:\Works\code\VehicleDetection\train\data\vehicleImages\image_00001.jpg'} {1×4 double}
{'E:\Works\code\VehicleDetection\train\data\vehicleImages\image_00002.jpg'} {1×4 double}
{'E:\Works\code\VehicleDetection\train\data\vehicleImages\image_00003.jpg'} {1×4 double}
{'E:\Works\code\VehicleDetection\train\data\vehicleImages\image_00004.jpg'} {1×4 double}
将数据集分成两部分:一个是用于训练检测器的训练集,一个是用于评估检测器的测试集,这里选择70%的数据进行训练,其余数据用于评估。该部分代码如下:
% 将数据集分成两部分:一个是用于训练检测器的训练集,一个是用于评估检测器的测试集。
% 选择70%的数据进行训练,其余数据用于评估。
rng(0); % 控制随机数生成
shuffledIndices = randperm(height(vehicleDataset));
idx = floor(0.7 * length(shuffledIndices) );
trainingDataTbl = vehicleDataset(shuffledIndices(1:idx),:);
testDataTbl = vehicleDataset(shuffledIndices(idx+1:end),:);
将划分出的训练和验证数据集数据和标签进行转存,实现代码如下:
% 保存数据和标签
imdsTrain = imageDatastore(trainingDataTbl{:,'imageFilename'}); % 路径
bldsTrain = boxLabelDatastore(trainingDataTbl(:,'vehicle')); % 真实框和类别
imdsTest = imageDatastore(testDataTbl{:,'imageFilename'});
bldsTest = boxLabelDatastore(testDataTbl(:,'vehicle'));
联合文件路径和真实框,整理训练和测试集,这部分实现代码如下:
% 整理训练测试集
trainingData = combine(imdsTrain,bldsTrain); % 联合文件路径和真实框
testData = combine(imdsTest,bldsTest);
为了帮助了解标注信息的使用,可读取trainingData中的图片数据及真实框,通过insertShape函数在图像中进行标注并显示:
% 显示数据
data = read(trainingData); % data包括图片数据、真实框坐标、类别
I = data{1};
bbox = data{2};
annotatedImage = insertShape(I,'Rectangle',bbox); % 在数据矩阵中标出真实框
annotatedImage = imresize(annotatedImage,2);
figure
imshow(annotatedImage) % 显示图像
显示标注图像如下图所示:

3.2 创建YOLO目标检测器
搭建YOLO v2目标检测网络:YOLO v2由特征提取网络和检测网络两个子网络组成。特征提取网络通常是预训练的CNN,这里特征提取网络使用的是ResNet-50,当然还可以使用其他经过预训练的网络,例如MobileNet v2或ResNet-18,一般根据应用场景和问题的复杂程度选择合适的网络。与特征提取网络相比,检测网络是一个小的CNN,它由一些卷积层和YOLO v2特有的层组成。MATLAB中提供了yolov2Layers函数,其中给定了预训练的ResNet-50特征提取网络,可使用该功能自动创建YOLO v2对象检测网络。
yolov2Layers要求指定几个输入来参数化YOLO v2网络,详细使用方法可参考其官方文档,其参数主要有:
- 网络输入大小
- 锚框
- 特征提取网络
在目标检测中网络的输入尺寸一定程度上会影响检测结果,因此需要评估网络输入大小和数据的类别数选定。在选择网络输入大小时,应先考虑网络本身所需的最小尺寸、训练图像的大小以及在选定大小下处理数据所产生的计算量。一般情况下,倾向于选择一个接近于训练图像大小且大于网络所需输入大小的网络输入,这里为了减少运行程序的计算成本,指定网络输入大小为[224 224 3](运行网络所需的最小尺寸)。
% 创建yolo网络
inputSize = [448 448 3];
numClasses = width(vehicleDataset)-1; % 通过table的列数计算类别数
开始训练之前需要估算锚框,这要考虑图像的调整大小,调整训练数据的大小以估计锚框。好在MATLAB中提供了estimateAnchorBoxes函数,根据训练数据中对象的大小来估计锚框。根据transform函数预处理的训练数据,然后确定锚框个数并估计锚框。使用内置的函数preprocessData将训练图像数据调整为网络规定的输入大小。
% 用于评估锚框个数
trainingDataForEstimation = transform(trainingData,@(data)preprocessData(data,inputSize));
numAnchors = 7;
[anchorBoxes, meanIoU] = estimateAnchorBoxes(trainingDataForEstimation, numAnchors)
输出结果如下:
inputSize = [448 448 3];
anchorBoxes =
14 10
34 25
226 176
218 114
124 75
132 122
65 53
meanIoU =
0.6960
设置特征提取层网络为resnet50,选择‘activation_40_relu’作为特征提取层。该特征提取层输出的特征图经过16倍下采样,这样的下采样量算是空间分辨率与所提取特征强度之间的一个折中,因为经过网络提取的特征可能会在网络上显示出更强的图像特征。一般地,空间分辨率的成本以及选择最佳特征提取层需要依据经验分析。搭建网络的代码如下:
% 特征提取层采用resnet50
featureExtractionNetwork = resnet50;
featureLayer = 'activation_40_relu';
% 设置yolo网络
lgraph = yolov2Layers(inputSize,numClasses,anchorBoxes,featureExtractionNetwork,featureLayer);
3.3 数据增强
数据扩充通过在训练过程中随机转换原始数据来提高网络训练的准确性。通过使用数据增强,我们可以大大扩充训练集的大小,而无需增加实际标记的训练样本的数量。可使用transform通过随机水平翻转图像和关联的框标签来增强训练数据。值得注意的是,理想情况下测试和验证数据应尽可能代表原始数据,未作修改的数据可以较好地评估模型,因此数据扩充不适用于测试和验证数据。进行数据增强的代码如下:
% 进行数据增强
augmentedTrainingData = transform(trainingData,@augmentData);
% 可视化增强后的图片
augmentedData = cell(4,1);
for k = 1:4
data = read(augmentedTrainingData);
augmentedData{k} = insertShape(data{1},'Rectangle',data{2});
reset(augmentedTrainingData);
end
figure
montage(augmentedData,'BorderSize',10)
可视化增强后的图片如下:
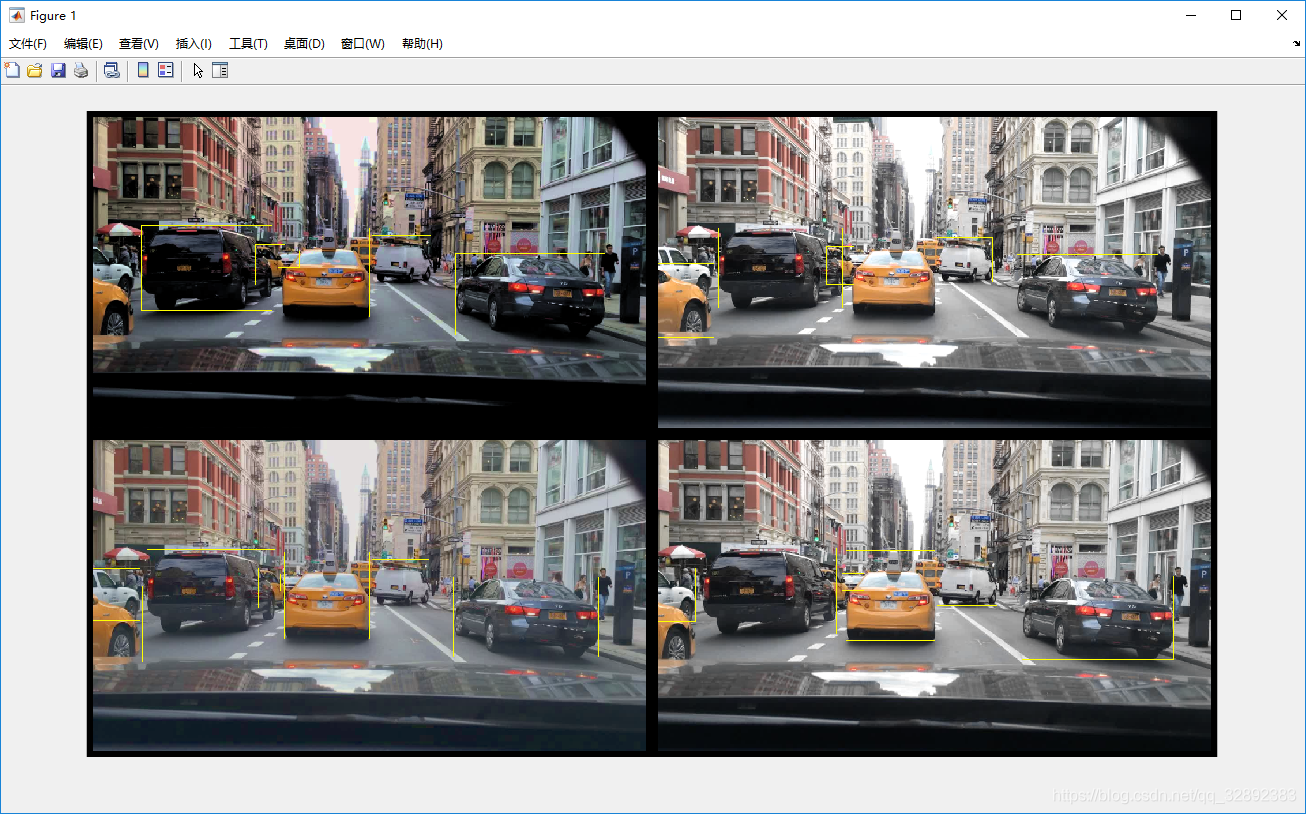
预处理训练数据:对增强后的训练数据和验证数据进行预处理,准备进行训练。然后读取预处理的训练数据,这里显示一张处理后的图像并标注边界框,帮助我们瞧一下喂给训练器的是何方神圣:
% 对增强数据进行预处理
preprocessedTrainingData = transform(augmentedTrainingData,@(data)preprocessData(data,inputSize));
data = read(preprocessedTrainingData);
% 显示一下
I = data{1};
bbox = data{2};
annotatedImage = insertShape(I,'Rectangle',bbox);
annotatedImage = imresize(annotatedImage,2);
figure
imshow(annotatedImage)
显示图像如下:
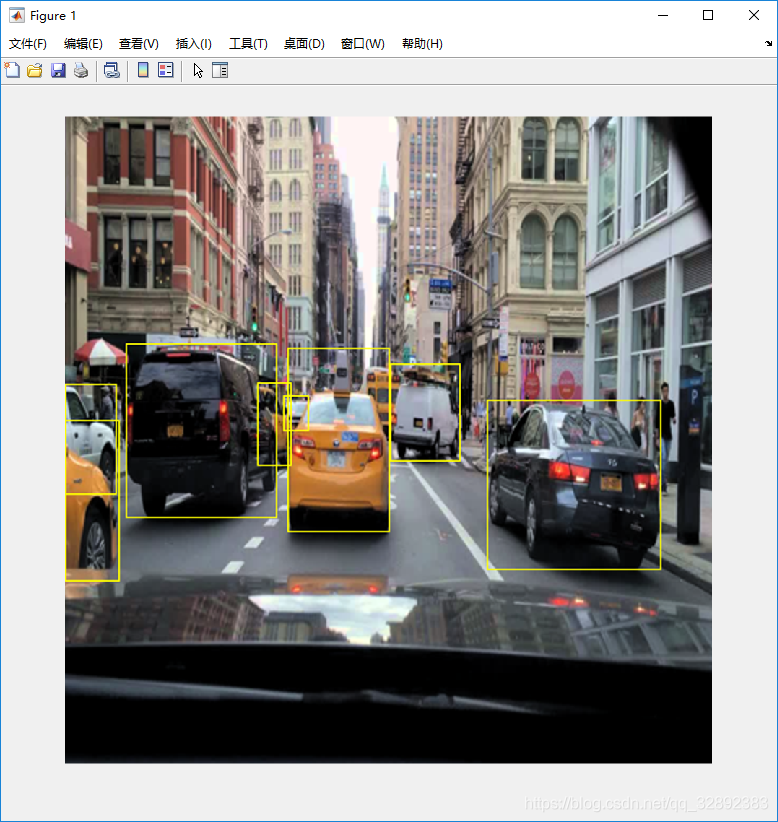
3.4 训练目标检测网络
训练目标检测器:这里可以使用trainingOptions容器指定网络的训练参数,设置‘ValidationData’作为预处理的验证数据;设置‘CheckpointPath’为一个临时位置,这样能够保证在训练过程中及时保存训练的结果,如果培训因电源中断或系统故障而中断,则可以从保存的检查点恢复训练。训练部分的代码如下:
% 训练参数
options = trainingOptions('sgdm', ...
'MiniBatchSize', 100, ....
'InitialLearnRate',1e-3, ...
'MaxEpochs',30,...
'CheckpointPath', tempdir, ...
'Shuffle','never');
if doTraining
% 训练YOLOv2检测器
[detector,info] = trainYOLOv2ObjectDetector(preprocessedTrainingData,lgraph,options);
else
% 载入预训练模型
pretrained = load('yolov2ResNet50.mat');
detector = pretrained.detector;
end
以上代码设置了doTraining决定是否执行训练,当该值为true时开始进行训练,反之则开始进行测试评估。接下来测试训练好的模型并显示测试结果:
% 测试训练好的模型并显示
I = imread(testDataTbl.imageFilename{4});
I = imresize(I,inputSize(1:2));
[bboxes,scores] = detect(detector,I);
I = insertObjectAnnotation(I,'rectangle',bboxes,scores);
figure
imshow(I)
显示检测结果如下:

3.5 评估网络性能
利用测试集对检测器进行评估:对于训练好的目标检测器有必要在大量图像上进行评估以测试其性能。MATLAB中的Computer Vision Toolbox提供了目标检测器的评估功能,可以测量一些通用指标,例如平均精度(evaluateDetectionPrecision)和对数平均未命中率(evaluateDetectionMissRate)。在本项目中,我们使用平均精度来评估性能,平均精度中包含了检测器做出正确分类的能力(精度)和检测器找到所有相关目标的能力(召回率)。我们将测试数据进行和训练数据相同的预处理操作,最终用来评估检测器,这部分代码如下:
% 预处理测试集
preprocessedTestData = transform(testData,@(data)preprocessData(data,inputSize));
% 对测试集数据进行测试
detectionResults = detect(detector, preprocessedTestData);
% 评估准确率
[ap,recall,precision] = evaluateDetectionPrecision(detectionResults, preprocessedTestData);
figure
plot(recall,precision)
xlabel('Recall')
ylabel('Precision')
grid on
title(sprintf('Average Precision = %.2f',ap))
精度/召回率(PR)曲线突出显示了在不同召回水平下检测器的精确度,最理想的情况是每处的精度均为1。要想提高平均精度,可以使用更多的训练数据来提高训练效果,但这也需要更多的训练时间。这里使用的是一个数据量较小的数据集,通过以上代码绘制的PR曲线如下图所示:
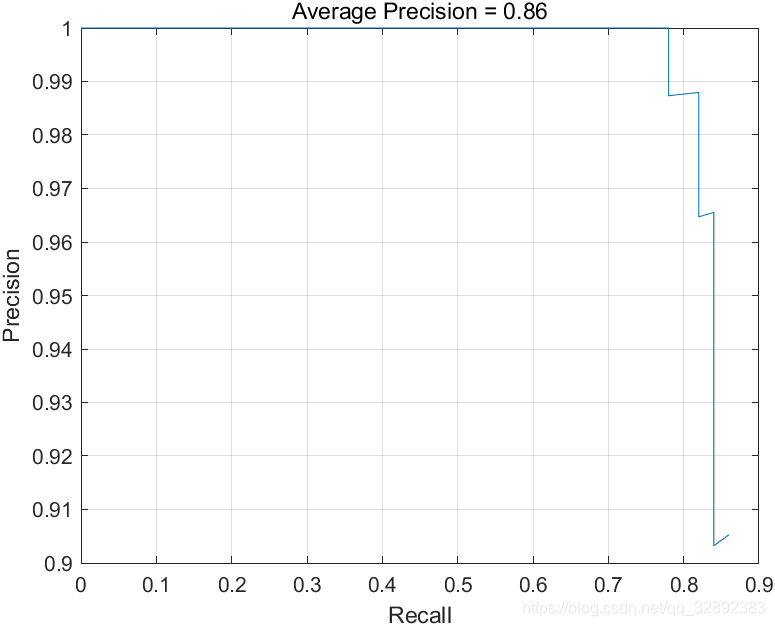
作为一个演示项目以上的平均精度还算可以了,可以提升的地方首当是训练数据量了,因为只选取了一部分数据这使得模型的泛化性能不高,对于拟合效果也没有作太多的优化,建议大家多做调整优化了。另外,前面代码中涉及到的调用函数这里列出一下:。
% 图像预处理
function data = preprocessData(data,targetSize)
% 调整图片和Bbox大小至targetSize
scale = targetSize(1:2)./size(data{1},[1 2]);
data{1} = imresize(data{1},targetSize(1:2));
% disp(data{2})
data{2} = bboxresize(data{2},scale);
end
% 图像增强
function B = augmentData(A)
% 应用随机水平翻转和随机X/Y缩放图像;
% 如果重叠大于0.25,则在边界外缩放的框将被裁减;
% 变换图像颜色
B = cell(size(A));
I = A{1};
sz = size(I);
if numel(sz)==3 && sz(3) == 3
I = jitterColorHSV(I,...
'Contrast',0.2,...
'Hue',0,...
'Saturation',0.1,...
'Brightness',0.2);
end
% 随机翻转和缩放图像
tform = randomAffine2d('XReflection',true,'Scale',[1 1.1]);
rout = affineOutputView(sz,tform,'BoundsStyle','CenterOutput');
B{1} = imwarp(I,tform,'OutputView',rout);
% 对锚框进行相同的变换
[B{2},indices] = bboxwarp(A{2},tform,rout,'OverlapThreshold',0.25);
B{3} = A{3}(indices);
% 当框的数据不存在时返回原始数据
if isempty(indices)
B = A;
end
end
下载链接
若您想获得博文中涉及的实现完整全部程序文件(包括数据集,m, UI文件等,如下图),这里已打包上传至博主的面包多平台和CSDN下载资源。本资源已上传至面包多网站和CSDN下载资源频道,可以点击以下链接获取,已将所有涉及的文件同时打包到里面,点击即可运行,完整文件截图如下:

说明:本资源已经过调试通过,下载后可通过MATLAB R2020b运行;另外本程序也通过打包APP应用文件,可双击carDetector_UI.mlappinstall文件导入应用,可直接运行所有功能;因为涉及MATLAB部分内置功能,为保证完美运行,请使用MATLAB R2020b及以上版本运行。➷➷➷
完整资源下载链接1:https://mianbaoduo.com/o/bread/YZaal55t
注:以上链接为博主的下载链接,CSDN下载资源频道下载链接稍后上传。博主最新发布的博文:实时车辆行人多目标检测与跟踪系统-上篇(UI界面清新版,Python代码)提供了车辆行人检测与跟踪的Python版本,界面与效果更加优良,欢迎尝鲜!
代码使用介绍及演示视频链接:https://www.bilibili.com/video/BV1No4y197rW/
结束语
由于博主能力有限,博文中提及的方法即使经过试验,也难免会有疏漏之处。希望您能热心指出其中的错误,以便下次修改时能以一个更完美更严谨的样子,呈现在大家面前。同时如果有更好的实现方法也请您不吝赐教。如果本博文反响较好,其界面部分也将在下篇博文中介绍,所有涉及的GUI界面程序也会作细致讲解,敬请期待!
基于深度学习的车辆检测系统(MATLAB代码,含GUI界面)的更多相关文章
- 【OCR技术系列之四】基于深度学习的文字识别(3755个汉字)
上一篇提到文字数据集的合成,现在我们手头上已经得到了3755个汉字(一级字库)的印刷体图像数据集,我们可以利用它们进行接下来的3755个汉字的识别系统的搭建.用深度学习做文字识别,用的网络当然是CNN ...
- 【OCR技术系列之四】基于深度学习的文字识别
上一篇提到文字数据集的合成,现在我们手头上已经得到了3755个汉字(一级字库)的印刷体图像数据集,我们可以利用它们进行接下来的3755个汉字的识别系统的搭建.用深度学习做文字识别,用的网络当然是CNN ...
- 基于深度学习的人脸性别识别系统(含UI界面,Python代码)
摘要:人脸性别识别是人脸识别领域的一个热门方向,本文详细介绍基于深度学习的人脸性别识别系统,在介绍算法原理的同时,给出Python的实现代码以及PyQt的UI界面.在界面中可以选择人脸图片.视频进行检 ...
- 基于深度学习的回声消除系统与Pytorch实现
文章作者:凌逆战 文章代码(pytorch实现):https://github.com/LXP-Never/AEC_DeepModel 文章地址(转载请指明出处):https://www.cnblog ...
- OCR技术浅探:基于深度学习和语言模型的印刷文字OCR系统
作者: 苏剑林 系列博文: 科学空间 OCR技术浅探:1. 全文简述 OCR技术浅探:2. 背景与假设 OCR技术浅探:3. 特征提取(1) OCR技术浅探:3. 特征提取(2) OCR技术浅探:4. ...
- 基于深度学习的人脸识别系统(Caffe+OpenCV+Dlib)【三】VGG网络进行特征提取
前言 基于深度学习的人脸识别系统,一共用到了5个开源库:OpenCV(计算机视觉库).Caffe(深度学习库).Dlib(机器学习库).libfacedetection(人脸检测库).cudnn(gp ...
- 基于深度学习的人脸识别系统(Caffe+OpenCV+Dlib)【二】人脸预处理
前言 基于深度学习的人脸识别系统,一共用到了5个开源库:OpenCV(计算机视觉库).Caffe(深度学习库).Dlib(机器学习库).libfacedetection(人脸检测库).cudnn(gp ...
- 基于深度学习的人脸识别系统系列(Caffe+OpenCV+Dlib)——【四】使用CUBLAS加速计算人脸向量的余弦距离
前言 基于深度学习的人脸识别系统,一共用到了5个开源库:OpenCV(计算机视觉库).Caffe(深度学习库).Dlib(机器学习库).libfacedetection(人脸检测库).cudnn(gp ...
- 一个基于深度学习回环检测模块的简单双目 SLAM 系统
转载请注明出处,谢谢 原创作者:Mingrui 原创链接:https://www.cnblogs.com/MingruiYu/p/12634631.html 写在前面 最近在搞本科毕设,关于基于深度学 ...
随机推荐
- bzoj2989 数列(KDTree)
bzoj2989 数列(KDTree) bzoj 该说不愧是咱,一个月才水一篇题解然后还水的一批 题目描述: 给定一个长度为n的正整数数列a[i]. 定义2个位置的graze值为两者位置差与数值差的和 ...
- ClassNotFoundException: org.springframework.web.context.ContextLoadServlet
web.xml中配置 <!-- 配置spring核心监听器,默认会以 /WEB-INF/applicationContext.xml作为配置文件 --> <listener> ...
- Gradle 使用@Value注册编译报错
报错信息:Expected '$(student - name)' to be an inline constant of type java.lang.String in @org.springfr ...
- Kafka 判断一个节点是否还活着有那两个条件?
(1)节点必须可以维护和 ZooKeeper 的连接,Zookeeper 通过心跳机制检查每 个节点的连接 (2)如果节点是个 follower,他必须能及时的同步 leader 的写操作,延时不能太 ...
- jQuery--基本过滤选择器
1.基本过滤选择器介绍 基本过滤器: :first 获取数组中第一个元素 :last 获取数组中最后一个 :eq(selector) 获取指定索引 :gt(index) 大于 ...
- Java 中的 ReadWriteLock 是什么?
读写锁是用来提升并发程序性能的锁分离技术的成果.
- java-第三方工具去做一些校验
推荐大家使用第三方 jar 的工具类去做判空.比如:从 Map 中取一个 key 的值,可以用 MapUtils 这个类:对字符串判空使用 StringUtils 这个类:对集合进行判空使用 Coll ...
- 在多线程环境下,SimpleDateFormat 是线程安全的吗?
不是,非常不幸,DateFormat 的所有实现,包括 SimpleDateFormat 都不是 线程安全的,因此你不应该在多线程序中使用,除非是在对外线程安全的环境中 使用,如 将 SimpleDa ...
- canvas实现平铺水印
欲实现的水印平铺的效果图如下: 从图上看,应该做到以下几点: 文字在X和Y方向上进行平铺: 文字进行了一定的角度的旋转: 水印作为背景,其z-index位置应位于页面内容底部, 即不能覆盖页面主内容: ...
- Chrome 已经原生支持截图功能,还可以给节点截图!
昨天 Chrome62 稳定版释出,除了常规修复各种安全问题外,还增加很多功能上的支持,比如说今天要介绍的强大的截图功能. 直接截图 打开开发者工具页面,选择左上角的元素选择按钮(Inspect) W ...