MKL库矩阵乘法
此示例是利用Intel 的MKL库函数计算矩阵的乘法,目标为:\(C=\alpha*A*B+\beta*C\),由函数cblas_dgemm实现;
其中\(A\)为\(m\times k\)维矩阵,\(B\)为\(k\times n\)维矩阵,\(C\)为\(m\times n\)维矩阵。
1 cblas_dgemm参数详解
fun cblas_dgemm(Layout, //指定行优先(CblasRowMajor,C)或列优先(CblasColMajor,Fortran)数据排序
TransA, //指定是否转置矩阵A
TransB, //指定是否转置矩阵B
M, //矩阵A和C的行数
N, //矩阵B和C的列数
K, //矩阵A的列,B的行
alpha, //矩阵A和B乘积的比例因子
A, //A矩阵
lda, //矩阵A的第一维的大小
B, //B矩阵
ldb, //矩阵B的第一维的大小
beta, //矩阵C的比例因子
C, //(input/output) 矩阵C
ldc //矩阵C的第一维的大小
)
cblas_dgemm矩阵乘法默认的算法就是\(C=\alpha*A*B+\beta*C\),若只需矩阵\(A\)与\(B\)的乘积,设置\(\alpha=1,\beta=0\)即可。
2 定义待处理矩阵
#include <stdio.h>
#include <stdlib.h>
#include "mkl.h" // 调用mkl头文件
#define min(x,y) (((x) < (y)) ? (x) : (y))
double* A, * B, * C; //声明三个矩阵变量,并分配内存
int m, n, k, i, j; //声明矩阵的维度,其中
double alpha, beta;
m = 2000, k = 200, n = 1000;
alpha = 1.0; beta = 0.0;
A = (double*)mkl_malloc(m * k * sizeof(double), 64); //按照矩阵维度分配内存
B = (double*)mkl_malloc(k * n * sizeof(double), 64); //mkl_malloc用法与malloc相似,64表示64位
C = (double*)mkl_malloc(m * n * sizeof(double), 64);
if (A == NULL || B == NULL || C == NULL) { //判空
mkl_free(A);
mkl_free(B);
mkl_free(C);
return 1;
}
for (i = 0; i < (m * k); i++) { //赋值
A[i] = (double)(i + 1);
}
for (i = 0; i < (k * n); i++) {
B[i] = (double)(-i - 1);
}
for (i = 0; i < (m * n); i++) {
C[i] = 0.0;
}
其中\(A\)和\(B\)矩阵设置为:
A = \left[ {\begin{array}{*{20}{c}}
{1.0}&{2.0}& \cdots &{1000.0}\\
{1001.0}&{1002.0}& \cdots &{2000.0}\\
\vdots & \vdots & \ddots & \cdots \\
{999001.0}&{999002.0}& \cdots &{1000000.0}
\end{array}} \right] \space
B = \left[ {\begin{array}{*{20}{c}}
{-1.0}&{-2.0}& \cdots &{-1000.0}\\
{-1001.0}&{-1002.0}& \cdots &{-2000.0}\\
\vdots & \vdots & \ddots & \cdots \\
{-999001.0}&{-999002.0}& \cdots &{-1000000.0}
\end{array}} \right]
\end{array}
\]
\(C\)矩阵为全0。
3 执行矩阵乘法
回到例子中,对照上面的参数,将C矩阵用A与B的矩阵乘法表示:
cblas_dgemm(CblasRowMajor, CblasNoTrans, CblasNoTrans,
m, n, k, alpha, A, k, B, n, beta, C, n);
//在执行完成后,释放内存
mkl_free(A);
mkl_free(B);
mkl_free(C);
执行后的得到结果如下:
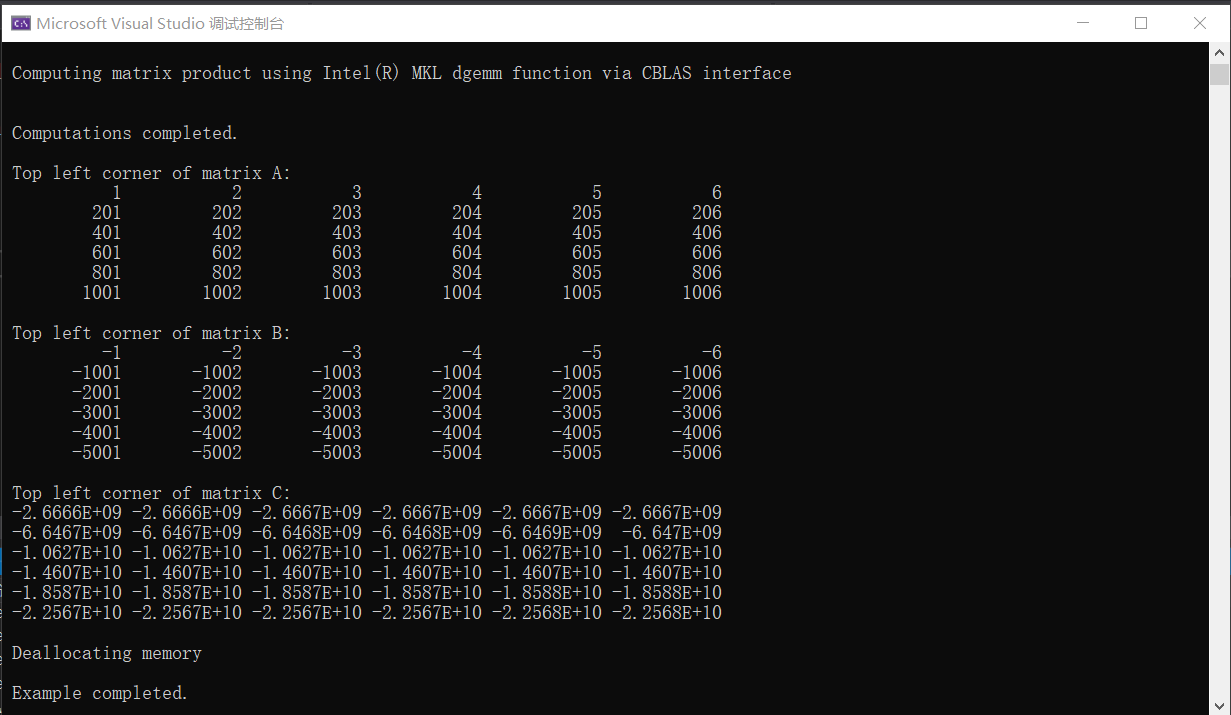
完整代码
#include <stdio.h>
#include <stdlib.h>
#include "mkl.h"
#define min(x,y) (((x) < (y)) ? (x) : (y))
int main()
{
double* A, * B, * C;
int m, n, k, i, j;
double alpha, beta;
m = 2000, k = 200, n = 1000;
alpha = 1.0; beta = 0.0;
A = (double*)mkl_malloc(m * k * sizeof(double), 64);
B = (double*)mkl_malloc(k * n * sizeof(double), 64);
C = (double*)mkl_malloc(m * n * sizeof(double), 64);
if (A == NULL || B == NULL || C == NULL) {
mkl_free(A);
mkl_free(B);
mkl_free(C);
return 1;
}
for (i = 0; i < (m * k); i++) {
A[i] = (double)(i + 1);
}
for (i = 0; i < (k * n); i++) {
B[i] = (double)(-i - 1);
}
for (i = 0; i < (m * n); i++) {
C[i] = 0.0;
}
cblas_dgemm(CblasRowMajor, CblasNoTrans, CblasNoTrans,
m, n, k, alpha, A, k, B, n, beta, C, n);
for (i = 0; i < min(m, 6); i++) {
for (j = 0; j < min(k, 6); j++) {
printf("%12.0f", A[j + i * k]);
}
printf("\n");
}
for (i = 0; i < min(k, 6); i++) {
for (j = 0; j < min(n, 6); j++) {
printf("%12.0f", B[j + i * n]);
}
printf("\n");
}
for (i = 0; i < min(m, 6); i++) {
for (j = 0; j < min(n, 6); j++) {
printf("%12.5G", C[j + i * n]);
}
printf("\n");
}
mkl_free(A);
mkl_free(B);
mkl_free(C);
return 0;
}
MKL库矩阵乘法的更多相关文章
- Eigen ,MKL和 matlab 矩阵乘法速度比较
Eigen 矩阵乘法的速度 < MKL矩阵乘法的速度,MKL矩阵乘法的速度与matlab矩阵乘法的速度相差不大,但matlab GPU版本的矩阵乘法速度是CUP的两倍,在采用float数据类型 ...
- [转]OpenBLAS项目与矩阵乘法优化
课程内容 OpenBLAS项目介绍 矩阵乘法优化算法 一步步调优实现 以下为公开课完整视频,共64分钟: 以下为公开课内容的文字及 PPT 整理. 雷锋网的朋友们大家好,我是张先轶,今天主要介绍一下我 ...
- 有关CUBLAS中的矩阵乘法函数
关于cuBLAS库中矩阵乘法相关的函数及其输入输出进行详细讨论. ▶ 涨姿势: ● cuBLAS中能用于运算矩阵乘法的函数有4个,分别是 cublasSgemm(单精度实数).cublasDgemm( ...
- CPU的自动调度矩阵乘法
CPU的自动调度矩阵乘法 这是一个有关如何对CPU使用自动调度程序的文档. 与依靠手动模板定义搜索空间的基于模板的autotvm不同,自动调度程序不需要任何模板.用户只需要编写计算声明,而无需任何调度 ...
- MKL库奇异值分解(LAPACKE_dgesvd)
对任意一个\(m\times n\)的实矩阵,总可以按照SVD算法对其进行分解.即: \[A = U\Sigma V^T \] 其中\(U.V\)分别为\(m\times m.n\times n\)的 ...
- *HDU2254 矩阵乘法
奥运 Time Limit: 1000/1000 MS (Java/Others) Memory Limit: 65536/65536 K (Java/Others)Total Submissi ...
- *HDU 1757 矩阵乘法
A Simple Math Problem Time Limit: 3000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Ot ...
- CH Round #30 摆花[矩阵乘法]
摆花 CH Round #30 - 清明欢乐赛 背景及描述 艺术馆门前将摆出许多花,一共有n个位置排成一排,每个位置可以摆花也可以不摆花.有些花如果摆在相邻的位置(隔着一个空的位置不算相邻),就不好看 ...
- POJ3070 Fibonacci[矩阵乘法]
Fibonacci Time Limit: 1000MS Memory Limit: 65536K Total Submissions: 13677 Accepted: 9697 Descri ...
随机推荐
- luogu4883 mzf的考验
题目描述: luogu 题解: 当然splay. 区间翻转是基本操作. 区间异或?按套路记录区间内每一位$1$的个数,异或的时候按位取反即可. 区间查询同理. 因为要按位维护,所以复杂度多了个log. ...
- C# XML基础入门(XML文件内容增删改查清)
前言: 最近对接了一个第三方的项目,该项目的数据传输格式是XML.由于工作多年只有之前在医疗行业的时候有接触过少量数据格式是XML的接口,之后就几乎没有接触过了.因此对于XML这块自己感觉还是有很多盲 ...
- 半吊子菜鸟学Web开发 -- PHP学习3-文件
目录 1 PHP文件系统 1.1 PHP文件的读取 1.4 获得文件的大小 1.5 PHP写入文件 1.6 删除文件 1 PHP文件系统 1.1 PHP文件的读取 文件读取的函数是file_get_c ...
- Java中的异常处理机制的简单原理和应用?
程序运行过程中可能出现各种"非预期"情况,这些非预期情况可能导致程序非正常结束. 为了提高程序的健壮性,Java提供了异常处理机制: try { s1... s2... s3... ...
- MySQL 数据库作发布系统的存储,一天五万条以上的增量, 预计运维三年,怎么优化?
1.设计良好的数据库结构,允许部分数据冗余,尽量避免 join 查询,提高效率. 2.选择合适的表字段数据类型和存储引擎,适当的添加索引. 3.MySQL 库主从读写分离. 4.找规律分表,减少单表中 ...
- Gradle 使用@Value注册编译报错
报错信息:Expected '$(student - name)' to be an inline constant of type java.lang.String in @org.springfr ...
- Error和Exception有什么区别?
Error表示系统级的错误和程序不必处理的异常,是恢复不是不可能但很困难的情况下的一种严重问题:比如内存溢出,不可能指望程序能处理这样的情况:Exception表示需要捕捉或者需要程序进行处理的异常, ...
- Zookeeper 的典型应用场景 ?
Zookeeper 是一个典型的发布/订阅模式的分布式数据管理与协调框架,开发人员 可以使用它来进行分布式数据的发布和订阅. 通过对 Zookeeper 中丰富的数据节点进行交叉使用,配合 Watch ...
- 学习Jenkins(二)
一:持续集成的概念: 总体的概括 持续集成Continuous Integration 持续交付Continuous Delivery 持续部署Continuous Deployment 二:安装部署 ...
- 学习RabbitMQ(四)
I. 消息中间件特点: 1,异步处理模式 消息发送者可以发送一个消息而无需等待响应,消息发送者将消息发送到一条虚拟的通道或队列上,消息接收者则订阅或监听该通道,一条消息可能最终转发给一个或多个消息 ...