使用Elasticsearch的processors来对csv格式数据进行解析
来源数据是一个csv文件,具体内容如下图所示:
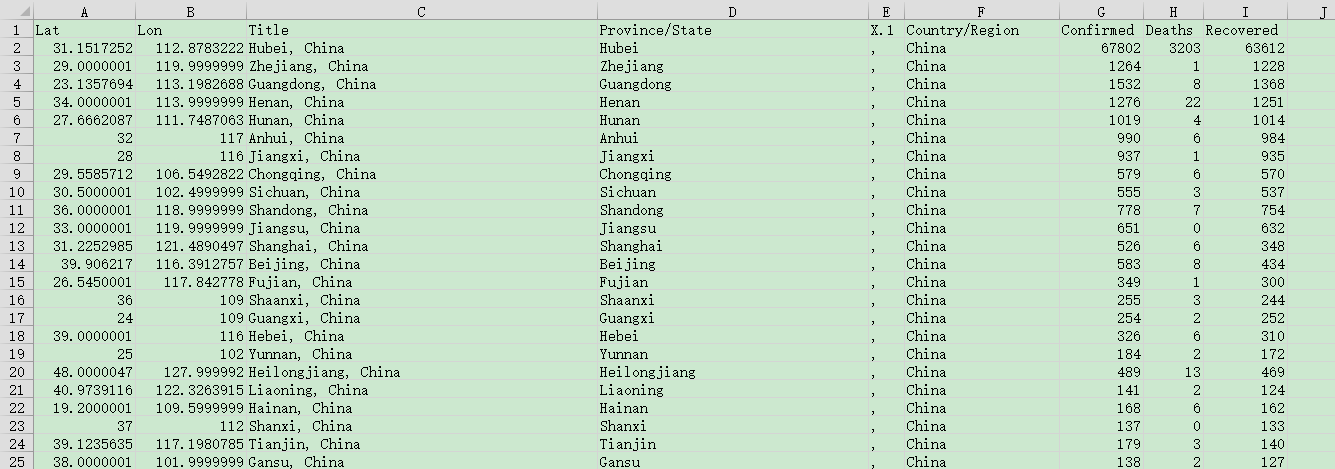
导入数据到es中
有两种办法,第一种是在kibana界面直接上传文件导入
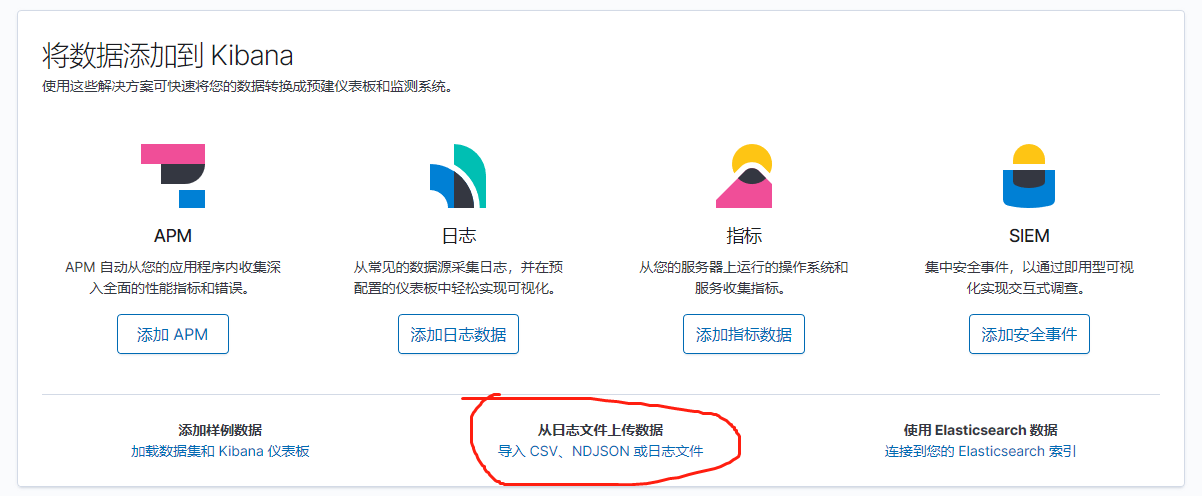
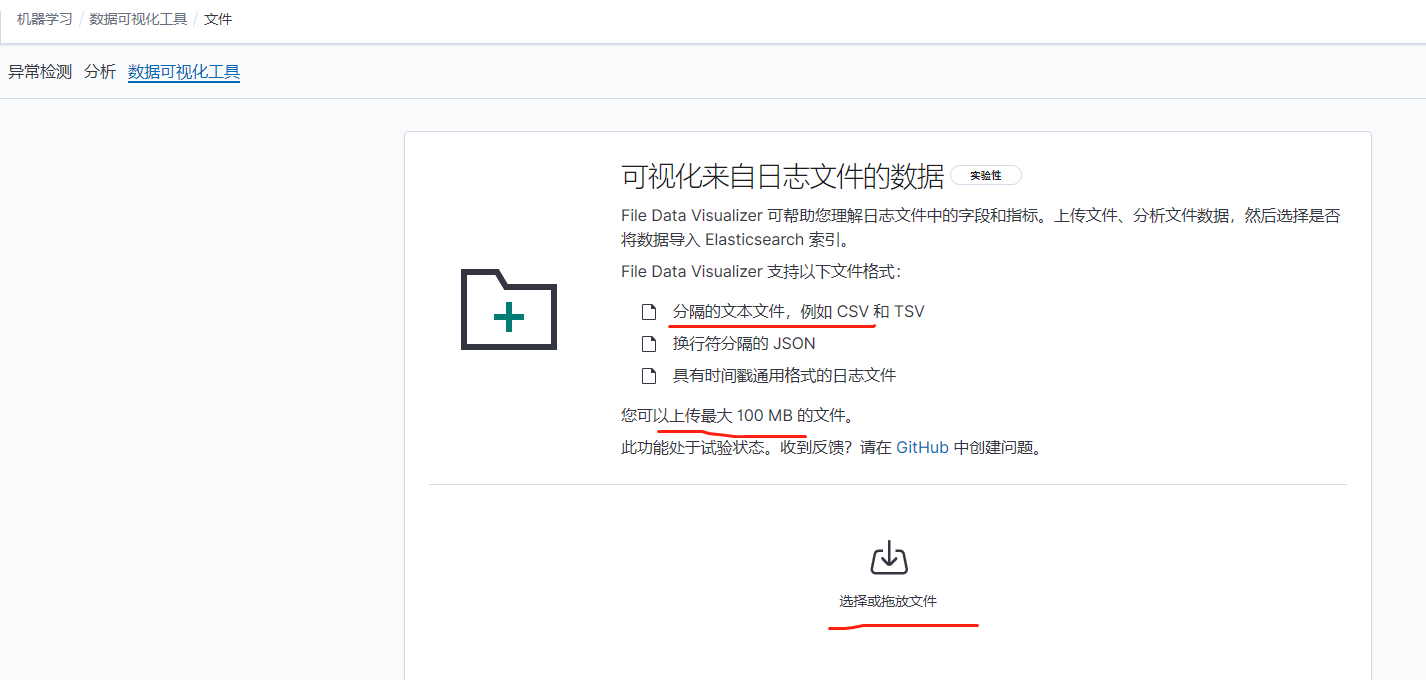
第二种方法是使用filebeat读取文件导入
这里采用第二种办法
配置文件名:filebeat_covid19.yml
filebeat.inputs:
- type: log
paths:
- /covid19/covid19.csv # 文件路径根据实际情况修改
exclude_lines: ['^Lat'] # 去掉csv文件的第一行数据header
output.elasticsearch:
hosts: ["http://localhost:9200"]
index: covid19 # 设置索引名
setup.ilm.enabled: false # 不使用索引生命周期管理
setup.template.name: covid19
setup.template.pattern: covid19
注意:csv文件的第一行是数据的header,需要去掉这一行。为此,采用了exclude_lines: ['^Lat']来去掉第一行。
执行如下命令导入数据:./filebeat -e -c filebeat_covid19.yml
Filebeat的registry文件存储Filebeat用于跟踪上次读取位置的状态和位置信息。如果由于某种原因,我们想重复对这个csv文件的处理,我们可以删除如下的目录:
- data/registry 针对 .tar.gz and .tgz 归档文件安装
- /var/lib/filebeat/registry 针对 DEB 及 RPM 安装包
- c:\ProgramData\filebeat\registry 针对 Windows zip 文件
对数据进行查询:GET covid19/_search
其中一条数据格式:
{
"_index" : "covid19",
"_type" : "_doc",
"_id" : "udJG93EB9vfbZvWY2eEV",
"_score" : 1.0,
"_source" : {
"@timestamp" : "2020-05-09T02:32:26.345Z",
"log" : {
"file" : {
"path" : "/usr/local/src/covid19.csv"
},
"offset" : 3308
},
"message" : """37.1232245,-78.4927721,"Virginia, US",Virginia,",",US,2640,0,0""",
"input" : {
"type" : "log"
},
"ecs" : {
"version" : "1.1.0"
},
"host" : {
"os" : {
"codename" : "Core",
"platform" : "centos",
"version" : "7 (Core)",
"family" : "redhat",
"name" : "CentOS Linux",
"kernel" : "4.4.196-1.el7.elrepo.x86_64"
},
"id" : "8e40a96218dc4a3db226ae44244c0b26",
"containerized" : false,
"name" : "bogon",
"hostname" : "bogon",
"architecture" : "x86_64"
},
"agent" : {
"ephemeral_id" : "4d3cb998-1a1c-4545-8c60-ab0ddd135d86",
"hostname" : "bogon",
"id" : "147d9456-23f4-470e-94cb-fdddab45f5a6",
"version" : "7.5.0",
"type" : "filebeat"
}
}
}
利用Processors来加工数据
去掉无用的字段
PUT _ingest/pipeline/covid19_parser
{
"processors": [
{
"remove": {
"field": ["log", "input", "ecs", "host", "agent"],
"if": "ctx.log != null && ctx.input != null && ctx.ecs != null && ctx.host != null && ctx.agent != null"
}
}
]
}
上面的pipeline定义了一个叫做remove的processor。它检查log,input, ecs, host及agent都不为空的情况下,删除字段log, input,ecs, host及agent。
应用pipleline,执行如下命令:POST covid19/_update_by_query?pipeline=covid19_parser
替换引号
导入的message数据为:
"""37.1232245,-78.4927721,"Virginia, US",Virginia,",",US,221,0,0"""
这里的数据有很多的引号"字符,想把这些字符替换为符号'。为此,需要gsub processors来帮我们处理。重新修改我们的pipeline:
PUT _ingest/pipeline/covid19_parser
{
"processors": [
{
"remove": {
"field": ["log", "input", "ecs", "host", "agent"],
"if": "ctx.log != null && ctx.input != null && ctx.ecs != null && ctx.host != null && ctx.agent != null"
}
},
{
"gsub": {
"field": "message",
"pattern": "\"",
"replacement": "'"
}
}
]
}
注意:上述语句在kibana的Dev Tools中不能执行“自动缩进”命令,否则“gsub”中的“pattern”,会由"pattern": "\"",变成"pattern": """"""",
应用pipleline,执行如下命令:POST covid19/_update_by_query?pipeline=covid19_parser
看出来我们已经成功都去掉了引号。我们的message的信息如下:
"37.1232245,-78.4927721,'Virginia, US',Virginia,',',US,221,0,0"
解析信息
这一步的操作具体来说是把message的信息,由一行信息转换成json样式的键值对数据
首先使用Kibana所提供的Grok Debugger来帮助我们分析数据。我们将使用如下的grok pattern来解析我们的message:
%{NUMBER:lat:float},%{NUMBER:lon:float},'%{DATA:address}',%{DATA:city},',',%{DATA:country},%{NUMBER:infected:int},%{NUMBER:death:int}
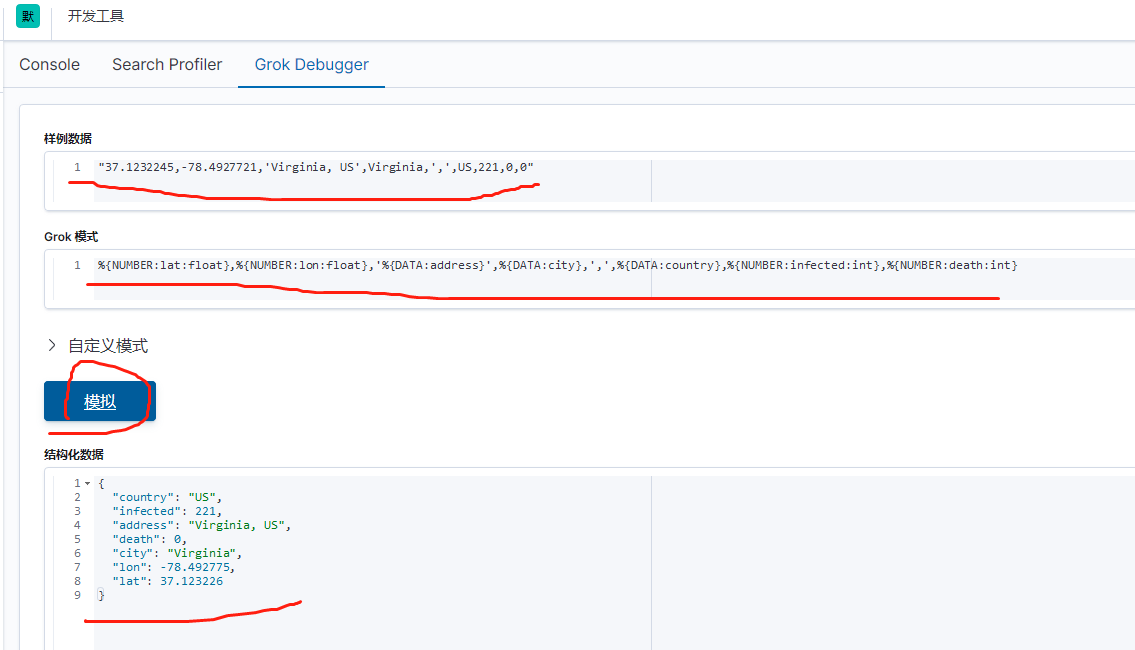
重新修改pipeline:
PUT _ingest/pipeline/covid19_parser
{
"processors": [
{
"remove": {
"field": ["log", "input", "ecs", "host", "agent"],
"if": "ctx.log != null && ctx.input != null && ctx.ecs != null && ctx.host != null && ctx.agent != null"
}
},
{
"gsub": {
"field": "message",
"pattern": "\"",
"replacement": "'"
}
},
{
"grok": {
"field": "message",
"patterns": [
"%{NUMBER:lat:float},%{NUMBER:lon:float},'%{DATA:address}',%{DATA:city},',',%{DATA:country},%{NUMBER:infected:int},%{NUMBER:death:int}"
]
}
}
]
}
使用如下的命令来重新对数据进行分析:
POST covid19/_update_by_query?pipeline=covid19_parser
可以看到新增加的country,infected,address等等的字段。
添加location字段
需要创建一个新的location字段,把原先表示经纬度的lon及lat字段给概括进去
更新pipeline为:
PUT _ingest/pipeline/covid19_parser
{
"processors": [
{
"remove": {
"field": ["log", "input", "ecs", "host", "agent"],
"if": "ctx.log != null && ctx.input != null && ctx.ecs != null && ctx.host != null && ctx.agent != null"
}
},
{
"gsub": {
"field": "message",
"pattern": "\"",
"replacement": "'"
}
},
{
"grok": {
"field": "message",
"patterns": [
"%{NUMBER:lat:float},%{NUMBER:lon:float},'%{DATA:address}',%{DATA:city},',',%{DATA:country},%{NUMBER:infected:int},%{NUMBER:death:int}"
]
}
},
{
"set": {
"field": "location.lat",
"value": "{{lat}}"
}
},
{
"set": {
"field": "location.lon",
"value": "{{lon}}"
}
}
]
}
设置了一个叫做location.lat及location.lon的两个字段。它们的值分别是{{lat}}及{{lon}}
由于location是一个新增加的字段,在默认的情况下,它的两个字段都会被Elasticsearch设置为text的类型。为了能够让我们的数据在地图中进行显示,它必须是一个geo_point的数据类型。为此,我们必须通过如下命令来设置它的数据类型:
PUT covid19/_mapping
{
"properties": {
"location": {
"type": "geo_point"
}
}
}
再使用如下的命令来对我们的数据重新进行处理:
POST covid19/_update_by_query?pipeline=covid19_parser
同时也可以查看covid19的mapping。
GET covid19/_mapping
我们可以发现location的数据类型为:
"location" : {
"type" : "geo_point"
},
它显示location的数据类型是对的。
到目前为止,已经够把数据处理成所需要的数据了,可以用来进一步展示使用。
使用Elasticsearch的processors来对csv格式数据进行解析的更多相关文章
- Highcharts使用CSV格式数据绘制图表
Highcharts使用CSV格式数据绘制图表 CSV(Comma-Separated Values,逗号分隔值文本格式)是採用逗号切割的纯文本数据.通常情况下.每一个数据之间使用逗号切割,几个相关数 ...
- Bash中使用MySQL导入导出CSV格式数据[转]
转自: http://codingstandards.iteye.com/blog/604541 MySQL中导出CSV格式数据的SQL语句样本如下: select * from test_inf ...
- R语言笔记001——读取csv格式数据
读取csv格式数据 数据来源是西南财经大学 司亚卿 老师的课程作业 方法一:read.csv()函数 file.choose() read.csv("C:\\Users\\Administr ...
- HighCharts-动态配置csv格式数据
场景: 开发一个大型热力图.官网示例中只有设置静态csv数据的例子.一直没有找到如何给热力图加载动态数据. 无奈,只好把要加载的数据拼接成csv格式后,供热力图加载. 拼接数据js:(dataArr是 ...
- 理解CSV格式规范(解析CSV必备)
什么是CSV逗号分隔值(Comma-Separated Values,CSV),其文件以纯文本形式存储表格数据(数字和文本),文件的每一行都是一个数据记录.每个记录由一个或多个字段组成,用逗号分隔.使 ...
- JSON(三)——java中对于JSON格式数据的解析之json-lib与jackson
java中对于JSON格式数据的操作,主要是json格式字符串与JavaBean之间的相互转换.java中能够解析JSON格式数据的框架有很多,比如json-lib,jackson,阿里巴巴的fast ...
- java后台对json格式数据的解析
Json 和 Jsonlib 的使用 什么是 Json JSON(JvaScript Object Notation)(官网网站:http://www.json.org/)是 一种轻量级的数据交换格式 ...
- Mongodb 导出json 和csv 格式数据
导出到json: $ mongoexport.exe -d TestDB -c TestCollection -o ./test.json 导出到csv: If you want to outpu ...
- mysql导入导出.csv格式数据
window下导入数据: LOAD DATA INFILE "C:\\1.csv" REPLACE INTO TABLE demo CHARACTER SET gb2312 FIE ...
随机推荐
- ShardingSphere 云上实践:开箱即用的 ShardingSphere-Proxy 集群
本次 Apache ShardingSphere 5.1.2 版本更新为大家带来了三大全新功能,其中之一即为使用 ShardingSphere-Proxy chart 在云环境中快速部署一套 Shar ...
- HashMap源码深度剖析,手把手带你分析每一行代码,包会!!!
HashMap源码深度剖析,手把手带你分析每一行代码! 在前面的两篇文章哈希表的原理和200行代码带你写自己的HashMap(如果你阅读这篇文章感觉有点困难,可以先阅读这两篇文章)当中我们仔细谈到了哈 ...
- 记一次react-hooks项目获取图表图片集合并生成pdf的需求
需求: 获取子组件中所有图片的dom元素并生成图片,再把生成的图片转化为pdf下载 难点 众所周知,react是单向数据流,倡导f(data)⇒ UI的哲学, 并不建议过多直接操作dom,但是生成图片 ...
- Webpack干货系列 | Webpack5 怎么处理字体图标、图片资源
程序员优雅哥(youyacoder)简介:十年程序员,呆过央企外企私企,做过前端后端架构.分享vue.Java等前后端技术和架构. 本文摘要:主要讲解在不需要引入额外的loader的条件下运用Webp ...
- Java中修饰符的分类及用法
访问权限修饰符: public 修饰class,方法,变量: 所修饰类的名字必须与文件名相同,文件中最多能有一个pulic修饰的类. private class不可用,方法,变量可以用: 只限于本类成 ...
- CF1706A Another String Minimization Problem 题解
题意 给定一个长度为 \(n\) 的序列 \(a\) 以及一个长度为 \(m\) 的字符串 \(s\),初始 \(s\) 均为 \(\text{B}\),第 \(i\) 次操作可以把 \(s_{a_i ...
- ZJOI2016 小星星 题解
我一生之敌是状压 本文发表于 洛谷博客:https://www.luogu.com.cn/blog/LoveMC/solution-p3349 Cnblogs:https://www.cnblogs. ...
- 在Centos7.3下使用Siege对Django服务进行压力测试
原文转载自「刘悦的技术博客」https://v3u.cn/a_id_87 Siege是linux下的一个web系统的压力测试工具,支持多链接,支持get和post请求,可以对web系统进行多并发下持续 ...
- 基于Docker-compose搭建Redis高可用集群-哨兵模式(Redis-Sentinel)
原文转载自「刘悦的技术博客」https://v3u.cn/a_id_110 我们知道,Redis的集群方案大致有三种:1)redis cluster集群方案:2)master/slave主从方案:3) ...
- 使用.NET简单实现一个Redis的高性能克隆版(三)
译者注 该原文是Ayende Rahien大佬业余自己在使用C# 和 .NET构建一个简单.高性能兼容Redis协议的数据库的经历. 首先这个"Redis"是非常简单的实现,但是他 ...