ViT简述【Transformer】
Transformer在NLP任务中表现很好,但是在CV任务中应用还很有限,基本都是作为CNN的一个辅助,Vit尝试使用纯Transformer结构解决CV的任务,并成功将其应用到了CV的基本任务--图像分类中。
因此,简单而言,这篇论文的主旨就是,用Transformer结构完成图像分类任务。
结构概述
基本结构如下:
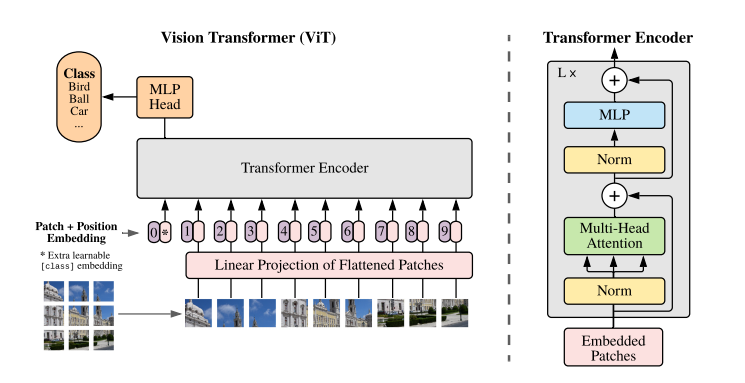
核心要点:
- 图像切patch
- Patch0
- Position Embedding
- Multi-Head Attention
图像切patch
在NLP任务中,将自然语言使用Word2Vec转为向量(Embedding)送入模型进行处理,在CV中没有对应的序列化token,因此作者采用将原始图像切分为多个小块,然后将每个小块儿内的信息展平的方式。
假设输入的shape为:(1, 3, 288, 288)
切分为9个小块,则每个小块的shape为:(1, 3, 32, 32)
然后将每个小块展平,则每个小块为(1, 3072),有9个小块,所以Linear Projection of Flattened Patched的shape为:(1, 9, 3072)输出shape为(1, 9, 1024),再加上Position Embedding,Transformer Encoder的输入shape为(1, 10, 1024),也就是图中Embedded Patches的shape。
Patch0
为什么需要有Patch0?
这是因为需要对1-9个patches信息的整合,最后送入MLP Head的只有Patch0。
Position Embedding
图像被切分和展开后,丢失了位置信息,对于图像处理任务来说,这是很怪异的,因此,作者这里采用在每个Patch上增加一个位置信息的方式,将位置信息纳入考虑。
Multi-Head Attention
参考Attention的基本结构。[Todo, Link]
代码[Pytorch]
import torch
from vit_pytorch import ViT
v = ViT(
image_size = 256,
patch_size = 32,
num_classes = 1000,
dim = 1024,
depth = 6,
heads = 16,
mlp_dim = 2048,
dropout = 0.1,
emb_dropout = 0.1
)
img = torch.randn(1, 3, 256, 256)
preds = v(img)
print(preds.shape) # 1000,与ViT定义的num_classes一致
ViT类参数解析:
- dim:Linear Projection的输出维度:1024
- depth:有多少个Transformer Blocks
- heads:Multi-Head的Head数
- mlp_dim:Transformer Encoder内部的MLP的维度
- dropout
- ......
ViT的forward函数:
def forward(self, img):
x = self.to_patch_embedding(img)
b, n, _ = x.shape
cls_tokens = repeat(self.cls_token, '1 1 d -> b 1 d', b = b)
x = torch.cat((cls_tokens, x), dim=1)
x += self.pos_embedding[:, :(n + 1)]
x = self.dropout(x)
x = self.transformer(x)
x = x.mean(dim = 1) if self.pool == 'mean' else x[:, 0]
x = self.to_latent(x)
return self.mlp_head(x)
输入端的切分主要由下面这句话完成:
x = self.to_patch_embedding(img)
==>
self.to_patch_embedding = nn.Sequential(
Rearrange('b c (h p1) (w p2) -> b (h w) (p1 p2 c)', p1 = patch_height, p2 = patch_width),
nn.LayerNorm(patch_dim),
nn.Linear(patch_dim, dim),
nn.LayerNorm(dim),
)
#由传入参数: image_size = 256, patch_size = 32
# Rearrange完成的shape变换为(b, c, 256, 256) -> (b, 64, 1024*c)
# nn.LayerNorm
# nn.Linear: (b, 64, 1024*c) --> (b, 64, 1024)
Rearrange用更加可理解的方式实现transpose的功能:
We don't write:
y = x.transpose(0, 2, 3, 1)
We write comprehensible code:
y = rearrange(x, 'b c h w -> b h w c')
ViT简述【Transformer】的更多相关文章
- VIT Vision Transformer | 先从PyTorch代码了解
文章原创自:微信公众号「机器学习炼丹术」 作者:炼丹兄 联系方式:微信cyx645016617 代码来自github [前言]:看代码的时候,也许会不理解VIT中各种组件的含义,但是这个文章的目的是了 ...
- ICCV2021 | Tokens-to-Token ViT:在ImageNet上从零训练Vision Transformer
前言 本文介绍一种新的tokens-to-token Vision Transformer(T2T-ViT),T2T-ViT将原始ViT的参数数量和MAC减少了一半,同时在ImageNet上从 ...
- Transformer详解
0 简述 Transformer改进了RNN最被人诟病的训练慢的缺点,利用self-attention机制实现快速并行. 并且Transformer可以增加到非常深的深度,充分发掘DNN模型的特性,提 ...
- 从零搭建Pytorch模型教程(三)搭建Transformer网络
前言 本文介绍了Transformer的基本流程,分块的两种实现方式,Position Emebdding的几种实现方式,Encoder的实现方式,最后分类的两种方式,以及最重要的数据格式的介绍. ...
- 论文阅读 | Transformer-XL: Attentive Language Models beyond a Fixed-Length Context
0 简述 Transformer最大的问题:在语言建模时的设置受到固定长度上下文的限制. 本文提出的Transformer-XL,使学习不再仅仅依赖于定长,且不破坏时间的相关性. Transforme ...
- attention、self-attention、transformer和bert模型基本原理简述笔记
attention 以google神经机器翻译(NMT)为例 无attention: encoder-decoder在无attention机制时,由encoder将输入序列转化为最后一层输出state ...
- ICCV2021 | TransFER:使用Transformer学习关系感知的面部表情表征
前言 人脸表情识别(FER)在计算机视觉领域受到越来越多的关注.本文介绍了一篇在人脸表情识别方向上使用Transformer来学习关系感知的ICCV2021论文,论文提出了一个TransFER ...
- ICCV2021 | PnP-DETR:用Transformer进行高效的视觉分析
前言 DETR首创了使用transformer解决视觉任务的方法,它直接将图像特征图转化为目标检测结果.尽管很有效,但由于在某些区域(如背景)上进行冗余计算,输入完整的feature maps ...
- pycaffe︱caffe中fine-tuning模型三重天(函数详解、框架简述)
本文主要参考caffe官方文档[<Fine-tuning a Pretrained Network for Style Recognition>](http://nbviewer.jupy ...
- 带你读Paper丨分析ViT尚存问题和相对应的解决方案
摘要:针对ViT现状,分析ViT尚存问题和相对应的解决方案,和相关论文idea汇总. 本文分享自华为云社区<[ViT]目前Vision Transformer遇到的问题和克服方法的相关论文汇总& ...
随机推荐
- 【Java SE进阶】Day08 File类、递归
一.File类 1.概述java.io.File 文件和路径的抽象表示 用于文件和目录的创建.查找和删除等 分类 file--文件 directory--文件夹/目录 path--路径 2.静态成员变 ...
- git cherry-pick 同步修改到另一个分支
我们在开发中有时会遇到,需要将另一个分支部分修改同步到当前分支. 如下图,想把 devA 分支中 commit E 和 F,同步到下面绿色的 devB 分支中. 这时候就可以使用 git cherry ...
- js逆向到加密解密入口的多种方法
一.hook hook又称钩子. 可以在调用系统函数之前, 先执行我们的函数. 例如, hook eval eval_ = eval; // 先保存系统的eval函数 eval = function( ...
- nuxt.js中引入lib-flexible 和 postcss-px2rem 实现pc自适应
最近一个需要用nuxt框架实现的pc自适应项目,从网上找了很多资料,最终完美实现 一.下载相关插件 npm i lib-flexible -Snpm i px2rem-loader -Dnpm ins ...
- 推荐给Amy的书单
目录 皮囊 推荐等级 ※ ※ ※ ※ ※ 白夜行 推荐等级 ※ ※ ※ ※ ※ 人生 推荐等级 ※ ※ ※ ※ 活着 推荐等级 ※ ※ ※ ※ 许三观卖血记 推荐等级 ※ ※ ※ ※ 皮囊 推荐等级 ...
- (三)elasticsearch 源码之启动流程分析
1.前面我们在<(一)elasticsearch 编译和启动>和 <(二)elasticsearch 源码目录 >简单了解下es(elasticsearch,下同),现在我们来 ...
- SSM框架——Spring
Spring 轻量级.非侵入式的框架 支持控制反转(IOC).面向切面编程(AOP) 支持事务的处理和声明.框架整合 1.HelloSpring(入门) 1.1导入依赖 <!-- https:/ ...
- ClickHouse(11)ClickHouse合并树MergeTree家族表引擎之SummingMergeTree详细解析
目录 建表语法 数据处理 汇总的通用规则 AggregateFunction 列中的汇总 嵌套结构数据的处理 资料分享 参考文章 SummingMergeTree引擎继承自MergeTree.区别在于 ...
- 解决Java.awt设计GUI程序时Label标签中文乱码解决(idea)
未修改时对话框里边无法显示Label的文本内容,显示的都是方框!网上都是Run--Edit Configurations--VM options:填入-Dfile.encoding=gbk 但是我实际 ...
- Feign远程调用 (介绍与使用)
Feign远程调用 Feign是代替RestTemplate进行远程调用的组件,避免了RestTemplate手写复杂的url容易出错的问题,并提高代码的可读性 使用Feign步骤 1)引入依赖 哪个 ...