基于 Apache Hudi 和DBT 构建开放的Lakehouse
本博客的重点展示如何利用增量数据处理和执行字段级更新来构建一个开放式 Lakehouse。 我们很高兴地宣布,用户现在可以使用 Apache Hudi + dbt 来构建开放Lakehouse。
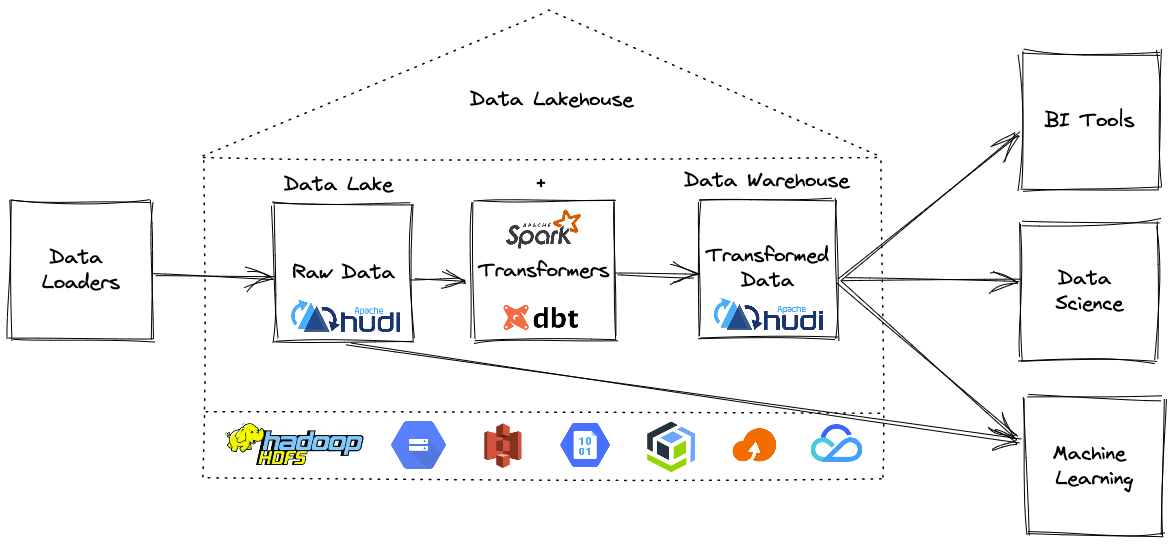
在深入了解细节之前,让我们先澄清一下本博客中使用的一些术语。
什么是 Apache Hudi?
Apache Hudi 为Lakehouse带来了 ACID 事务、记录级更新/删除和变更流。
Apache Hudi 是一个开源数据管理框架,用于简化增量数据处理和数据管道开发。该框架更有效地管理数据生命周期等业务需求并提高数据质量。
什么是dbt?
dbt(数据构建工具)是一种数据转换工具,使数据分析师和工程师能够在云数据仓库中转换、测试和记录数据。
dbt 使分析工程师能够通过简单地编写select语句来转换其仓库中的数据。 dbt 处理将这些select语句转换为表和视图。
dbt 在 ELT(提取、加载、转换)过程中执行 T——它不提取或加载数据,但它非常擅长转换已经加载到仓库中的数据。
什么是Lakehouse?
Lakehouse 是一种新的开放式架构,它结合了数据湖和数据仓库的最佳元素。 Lakehouses 是通过一种新的系统设计实现的:在开放格式的低成本云存储之上直接实施类似于数据仓库中的事务管理和数据管理功能。如果必须在现代世界中重新设计数据仓库,Lakehouse便是首选,因为现在可以使用廉价且高度可靠的存储(以对象存储的形式)。
换句话说,虽然数据湖历来被视为添加到云存储文件夹中的一堆文件,但 Lakehouse 表支持事务、更新、删除,在 Apache Hudi 的情况下,甚至支持索引或更改捕获等类似数据库的功能。
如何建造一个开放的Lakehouse?
现在我们知道什么是Lakehouse了,所以让我们建造一个开放的Lakehouse,你需要几个组件:
- 支持 ACID 事务的开放表格式
- Apache Hudi(与 dbt 集成)
- Delta Lake(锁定到 Databricks 运行时的专有功能)
- Apache Iceberg(目前未与 dbt 集成)
- 数据转换工具
- 开源 dbt 是转换层事实上的流行选择
- 分布式数据处理引擎
- Apache Spark 是计算引擎事实上的流行选择
- 云储存
- 可以选择任何具有成本效益的云存储或 HDFS
- 选择最心仪的查询引擎
构建 Lakehouse需要一种方法来提取数据并将其加载为 Hudi 表格式,然后使用 dbt 就地转换。
DBT 通过 dbt-spark 适配器包支持开箱即用的 Hudi。使用 dbt 创建建模数据集时,您可以选择 Hudi 作为表的格式。
可以按照此页面上的说明学习如何安装和配置 dbt+hudi。
第 1 步:如何提取和加载原始数据集?
这是构建Lakehouse的第一步,这里有很多选择可以将数据加载到我们的开放Lakehouse中。可以使用 Hudi 的 Delta Streamer工具,因为所有摄取功能都是预先构建的,并在大规模生产中经过实战测试。
Hudi 的 DeltaStreamer 在 ELT(提取、加载、转换)过程中执行 EL——它非常擅长提取、加载和可选地转换已经加载到 Lakehouse 中的数据。
第二步:如何用dbt项目配置Hudi?
要将 Hudi 与 dbt 项目一起使用,需要选择文件格式为 Hudi。文件格式配置可以在特定模型中指定,也可以为 dbt_project.yml 文件中的所有模型指定:
models:
+file_format: hudi
或者
{{ config(
materialized = 'incremental',
incremental_strategy = 'merge',
file_format = 'hudi',
unique_key = 'id',
…
) }}
选择 Hudi 作为 file_format 后,可以使用 dbt 创建物化数据集,这提供了 Hudi 表格式独有的额外好处,例如字段级更新/删除。
第三步:如何增量读取原始数据?
在我们学习如何构建增量物化视图之前,让我们快速了解一下,什么是 dbt 中的物化?物化是在 Lakehouse 中持久化 dbt 模型的策略。 dbt 中内置了四种类型的物化:
- table
- view
- incremental
- ephemeral
在所有物化类型中,只有增量模型允许 dbt 自上次运行 dbt 以来将记录插入或更新到表中,这释放了 Hudi 的能力,我们将深入了解细节。
使用增量模型需要执行以下两个步骤:
- 告诉 dbt 如何过滤增量执行的行
- 定义模型的唯一性约束(使用>= Hudi 0.10.1版本时需要)
如何在增量运行中应用过滤器?
dbt 提供了一个宏 is_incremental(),它对于专门为增量实现定义过滤器非常有用。
通常需要过滤“新”行,例如自上次 dbt 运行此模型以来已创建的行。查找此模型最近运行的时间戳的最佳方法是检查目标表中的最新时间戳。 dbt 通过使用“{{ this }}”变量可以轻松查询目标表。
{{
config(
materialized='incremental',
file_format='hudi',
)
}}
select
*
from raw_app_data.events
{% if is_incremental() %}
-- this filter will only be applied on an incremental run
where event_time > (select max(event_time) from {{ this }})
{% endif %}
如何定义唯一性约束?
unique_key 是数据集的主键,它确定记录是否具有新值,是否应该更新/删除或插入。
可以在模型顶部的配置块中定义 unique_key。 这个 unique_key 将作为 Hudi 表上的主键(hoodie.datasource.write.recordkey.field)。
第 4 步:如何在编写数据集时使用 upsert 功能?
dbt 在加载转换后的数据集时提供了多种加载策略,例如:
- append(默认)
- insert_overwrite(可选)
- merge(可选,仅适用于 Hudi 和 Delta 格式)
默认情况下dbt 使用 append 策略,当在同一有效负载上多次执行 dbt run 命令时,可能会导致重复行。
当你选择insert_overwrite策略时,dbt每次运行dbt都会覆盖整个分区或者全表加载,这样会造成不必要的开销,而且非常昂贵。
除了所有现有的加载数据的策略外,使用增量物化时还可以使用Hudi独占合并策略。使用合并策略可以对Lakehouse执行字段级更新/删除,这既高效又经济,因此可以获得更新鲜的数据和更快的洞察力。
如何执行字段级更新?
如果使用合并策略并指定了 unique_key,默认情况下dbt 将使用新值完全覆盖匹配的行。
由于 Apache Spark 适配器支持合并策略,因此可以选择将列名列表传递给 merge_update_columns 配置。在这种情况下dbt 将仅更新配置指定的列,并保留其他列的先前值。
{{ config(
materialized = 'incremental',
incremental_strategy = 'merge',
file_format = 'hudi',
unique_key = 'id',
merge_update_columns = ['msg', 'updated_ts'],
) }}
如何配置额外的Hudi自定义配置?
如果想指定额外的 Hudi 配置时,可以使用选项配置来做到这一点:
{{ config(
materialized='incremental',
file_format='hudi',
incremental_strategy='merge',
options={
'type': 'mor',
'primaryKey': 'id',
'precombineKey': 'ts',
},
unique_key='id',
partition_by='datestr',
pre_hook=["set spark.sql.datetime.java8API.enabled=false;"],
)
}}
总结
希望本篇博文可以助力基于Apache Hudi 与 dbt构建开放的 Lakehouse !
基于 Apache Hudi 和DBT 构建开放的Lakehouse的更多相关文章
- 基于Apache Hudi和Debezium构建CDC入湖管道
从 Hudi v0.10.0 开始,我们很高兴地宣布推出适用于 Deltastreamer 的 Debezium 源,它提供从 Postgres 和 MySQL 数据库到数据湖的变更捕获数据 (CDC ...
- 基于 Apache Hudi + Presto + AWS S3 构建开放Lakehouse
认识Lakehouse 数据仓库被认为是对结构化数据执行分析的标准,但它不能处理非结构化数据. 包括诸如文本.图像.音频.视频和其他格式的信息. 此外机器学习和人工智能在业务的各个方面变得越来越普遍, ...
- 基于Apache Hudi构建数据湖的典型应用场景介绍
1. 传统数据湖存在的问题与挑战 传统数据湖解决方案中,常用Hive来构建T+1级别的数据仓库,通过HDFS存储实现海量数据的存储与水平扩容,通过Hive实现元数据的管理以及数据操作的SQL化.虽然能 ...
- Robinhood基于Apache Hudi的下一代数据湖实践
1. 摘要 Robinhood 的使命是使所有人的金融民主化. Robinhood 内部不同级别的持续数据分析和数据驱动决策是实现这一使命的基础. 我们有各种数据源--OLTP 数据库.事件流和各种第 ...
- 基于 Apache Hudi 极致查询优化的探索实践
摘要:本文主要介绍 Presto 如何更好的利用 Hudi 的数据布局.索引信息来加速点查性能. 本文分享自华为云社区<华为云基于 Apache Hudi 极致查询优化的探索实践!>,作者 ...
- Uber基于Apache Hudi构建PB级数据湖实践
1. 引言 从确保准确预计到达时间到预测最佳交通路线,在Uber平台上提供安全.无缝的运输和交付体验需要可靠.高性能的大规模数据存储和分析.2016年,Uber开发了增量处理框架Apache Hudi ...
- 字节跳动基于Apache Hudi构建EB级数据湖实践
来自字节跳动的管梓越同学一篇关于Apache Hudi在字节跳动推荐系统中EB级数据量实践的分享. 接下来将分为场景需求.设计选型.功能支持.性能调优.未来展望五部分介绍Hudi在字节跳动推荐系统中的 ...
- 基于Apache Hudi在Google云构建数据湖平台
自从计算机出现以来,我们一直在尝试寻找计算机存储一些信息的方法,存储在计算机上的信息(也称为数据)有多种形式,数据变得如此重要,以至于信息现在已成为触手可及的商品.多年来数据以多种方式存储在计算机中, ...
- 基于Apache Hudi构建分析型数据湖
为了有机地发展业务,每个组织都在迅速采用分析. 在分析过程的帮助下,产品团队正在接收来自用户的反馈,并能够以更快的速度交付新功能. 通过分析提供的对用户的更深入了解,营销团队能够调整他们的活动以针对特 ...
随机推荐
- html5手册语义化标签
html5手册语义化标签: article section aside hgroup header footer nav time mark figure figcaption contextmenu ...
- SpringCloud 客户端负载均衡:Ribbon
目录 Ribbon 介绍 开启客户端负载均衡,简化 RestTemplate 调用 负载均衡策略 Ribbon 介绍 Ribbon 是 Netflix 提供的一个基于 Http 和 TCP 的客户端负 ...
- 深入C++03:面向对象
面向对象 类和对象.this指针 不用做太多笔记,都可以看初识C++的笔记: 记住:声明后面都要加":",比如声明方法和变量还有class结束的地方:而实现函数出来的地方是不需要加 ...
- CabloyJS实现了一款基于X6的工作流可视化编辑器
介绍 文档演示:CMS审批工作流演示了如何通过JSON来直接创建一个工作流定义,通常用于为具体的业务数据生成预定义或内置审批工作流的场景 CabloyJS 4.8.0采用X6 图编辑引擎实现了一款工作 ...
- 1. 时序练习(广告渠道vs销量预测)
用散点图来看下sales销量与哪一维度更相关. 和目标销量的关系的话,那么这就是多元线性回归问题了. 上面把所有的200个数据集都用来训练了,现在把数据集拆分一下,分成训练集合测试集,再进行训练. 可 ...
- go-zero微服务实战系列(三、API定义和表结构设计)
前两篇文章分别介绍了本系列文章的背景以及根据业务职能对商城系统做了服务的拆分,其中每个服务又可分为如下三类: api服务 - BFF层,对外提供HTTP接口 rpc服务 - 内部依赖的微服务,实现单一 ...
- Camunda如何配置和使用mysql数据库
Camunda默认使用已预先配置好的H2数据库,数据库模式和所有必需的表将在引擎第一次启动时自动创建.如果你想使用自定义独立数据库,比如mysql,请遵循以下步骤: 一.新建mysql数据库 为Cam ...
- 技术分享 | 想做App测试就一定要了解的App结构
本文节选自霍格沃兹测试开发学社内部教材 app 的结构包含了 APK 结构和 app 页面结构两个部分 APK结构 APK 是 Android Package 的缩写,其实就是 Android 的安装 ...
- 开启网易邮箱客户端授权码-POP/SMTP/IMAP
打开网易邮箱首页 https://mail.163.com/ 登录邮箱. 点击上方设置,选择POP/SMTP/IMAP选项. 选择开启对应的协议,IMAP或者POP3分别为不同的收信协议 在新弹出的弹 ...
- 使用node.js如何简单快速的搭建一个websocket聊天应用
初始化项目 npm init 安装nodejs-websocket npm install nodejs-websocket 创建并编辑启动文件 创建一个名为app.js文件,并且编辑它. var w ...