K8S群集调度器
调度约束
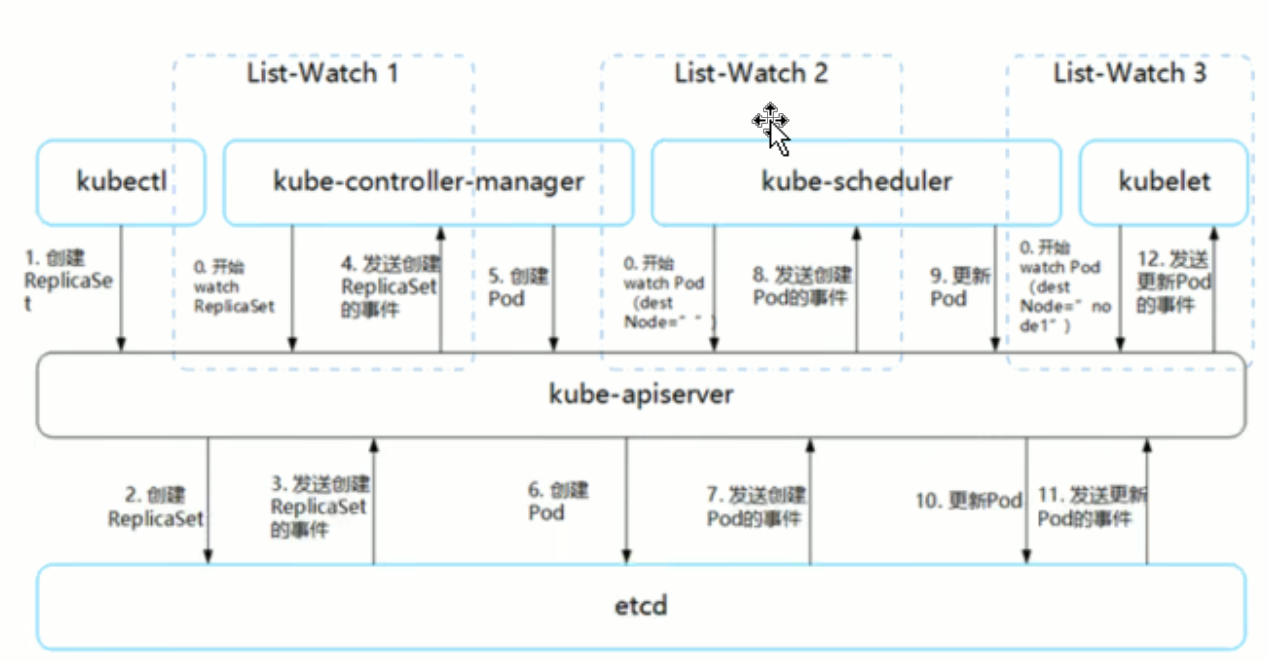
Pod 启动典型创建过程:
调度过程

Predicate 常见的算法:
常见的优先级选项:
指定调度节点:
1 vim myapp.yaml
2 apiVersion: apps/v1
3 kind: Deployment
4 metadata:
5 name: myapp
6 spec:
7 replicas: 3
8 selector:
9 matchLabels:
10 app: myapp
11 template:
12 metadata:
13 labels:
14 app: myapp
15 spec:
16 nodeName: node01
17 containers:
18 - name: myapp
19 image: soscscs/myapp:v1
20 ports:
21 - containerPort: 80
22
23 kubectl apply -f myapp.yaml
24
25 kubectl get pods -o wide
26 NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
27 myapp-6bc58d7775-6wlpp 1/1 Running 0 14s 10.244.1.25 node01 <none> <none>
28 myapp-6bc58d7775-szcvp 1/1 Running 0 14s 10.244.1.26 node01 <none> <none>
29 myapp-6bc58d7775-vnxlp 1/1 Running 0 14s 10.244.1.24 node01 <none> <none>
30
31 //查看详细事件(发现未经过 scheduler 调度分配)
32 kubectl describe pod myapp-6bc58d7775-6wlpp
33 ......
34 Type Reason Age From Message
35 ---- ------ ---- ---- -------
36 Normal Pulled 95s kubelet, node01 Container image "soscscs/myapp:v1" already present on machine
37 Normal Created 99s kubelet, node01 Created container nginx
38 Normal Started 99s kubelet, node01 Started container nginx
1 kubectl label --help
2 Usage:
3 kubectl label [--overwrite] (-f FILENAME | TYPE NAME) KEY_1=VAL_1 ... KEY_N=VAL_N [--resource-version=version] [options]
4
5 //需要获取 node 上的 NAME 名称
6 kubectl get node
7 NAME STATUS ROLES AGE VERSION
8 master Ready master 30h v1.20.11
9 node01 Ready <none> 30h v1.20.11
10 node02 Ready <none> 30h v1.20.11
11
12 //给对应的 node 设置标签分别为 kgc=a 和 kgc=b
13 kubectl label nodes node01 kgc=a
14
15 kubectl label nodes node02 kgc=b
16
17 //查看标签
18 kubectl get nodes --show-labels
19 NAME STATUS ROLES AGE VERSION LABELS
20 master Ready master 30h v1.20.11 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=master,kubernetes.io/os=linux,node-role.kubernetes.io/master=
21 node01 Ready <none> 30h v1.20.11 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kgc=a,kubernetes.io/arch=amd64,kubernetes.io/hostname=node01,kubernetes.io/os=linux
22 node02 Ready <none> 30h v1.20.11 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kgc=b,kubernetes.io/arch=amd64,kubernetes.io/hostname=node02,kubernetes.io/os=linux
1 vim myapp1.yaml
2 apiVersion: apps/v1
3 kind: Deployment
4 metadata:
5 name: myapp1
6 spec:
7 replicas: 3
8 selector:
9 matchLabels:
10 app: myapp1
11 template:
12 metadata:
13 labels:
14 app: myapp1
15 spec:
16 nodeSelector:
17 kgc: a
18 containers:
19 - name: myapp1
20 image: soscscs/myapp:v1
21 ports:
22 - containerPort: 80
23
24
25 kubectl apply -f myapp1.yaml
26
27 kubectl get pods -o wide
28 NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
29 myapp1-58cff4d75-52xm5 1/1 Running 0 24s 10.244.1.29 node01 <none> <none>
30 myapp1-58cff4d75-f747q 1/1 Running 0 24s 10.244.1.27 node01 <none> <none>
31 myapp1-58cff4d75-kn8gk 1/1 Running 0 24s 10.244.1.28 node01 <none> <none>
32
33 //查看详细事件(通过事件可以发现要先经过 scheduler 调度分配)
34 kubectl describe pod myapp1-58cff4d75-52xm5
35 Events:
36 Type Reason Age From Message
37 ---- ------ ---- ---- -------
38 Normal Scheduled 57s default-scheduler Successfully assigned default/myapp1-58cff4d75-52xm5 to node01
39 Normal Pulled 57s kubelet, node01 Container image "soscscs/myapp:v1" already present on machine
40 Normal Created 56s kubelet, node01 Created container myapp1
41 Normal Started 56s kubelet, node01 Started container myapp1
42
43
44 //修改一个 label 的值,需要加上 --overwrite 参数
45 kubectl label nodes node02 kgc=a --overwrite
46
47 //删除一个 label,只需在命令行最后指定 label 的 key 名并与一个减号相连即可:
48 kubectl label nodes node02 kgc-
49
50 //指定标签查询 node 节点
51 kubectl get node -l kgc=a
亲和性
键值运算关系
1 kubectl get nodes --show-labels
2 NAME STATUS ROLES AGE VERSION LABELS
3 master Ready master 11d v1.20.11 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=master,kubernetes.io/os=linux,node-role.kubernetes.io/master=
4 node01 Ready <none> 11d v1.20.11 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=node01,kubernetes.io/os=linux
5 node02 Ready <none> 11d v1.20.11 beta.kubernetes.io/arch=amd64,beta.kubernetes.io/os=linux,kubernetes.io/arch=amd64,kubernetes.io/hostname=node02,kubernetes.io/os=linux
6
7 //requiredDuringSchedulingIgnoredDuringExecution:硬策略
8 mkdir /opt/affinity
9 cd /opt/affinity
10
11 vim pod1.yaml
12 apiVersion: v1
13 kind: Pod
14 metadata:
15 name: affinity
16 labels:
17 app: node-affinity-pod
18 spec:
19 containers:
20 - name: with-node-affinity
21 image: soscscs/myapp:v1
22 affinity:
23 nodeAffinity:
24 requiredDuringSchedulingIgnoredDuringExecution:
25 nodeSelectorTerms:
26 - matchExpressions:
27 - key: kubernetes.io/hostname #指定node的标签
28 operator: NotIn #设置Pod安装到kubernetes.io/hostname的标签值不在values列表中的node上
29 values::
30 - node02
31
32
33 kubectl apply -f pod1.yaml
34
35 kubectl get pods -o wide
36 NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
37 affinity 1/1 Running 0 13s 10.244.1.30 node01 <none> <none>
38
39 kubectl delete pod --all && kubectl apply -f pod1.yaml && kubectl get pods -o wide
40
41 #如果硬策略不满足条件,Pod 状态一直会处于 Pending 状态。
1 preferredDuringSchedulingIgnoredDuringExecution:软策略
2 vim pod2.yaml
3 apiVersion: v1
4 kind: Pod
5 metadata:
6 name: affinity
7 labels:
8 app: node-affinity-pod
9 spec:
10 containers:
11 - name: with-node-affinity
12 image: soscscs/myapp:v1
13 affinity:
14 nodeAffinity:
15 preferredDuringSchedulingIgnoredDuringExecution:
16 - weight: 1 #如果有多个软策略选项的话,权重越大,优先级越高
17 preference:
18 matchExpressions:
19 - key: kubernetes.io/hostname
20 operator: In
21 values:
22 - node03
23
24
25 kubectl apply -f pod2.yaml
26
27 kubectl get pods -o wide
28 NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
29 affinity 1/1 Running 0 5s 10.244.2.35 node02 <none> <none>
30
31 //把values:的值改成node01,则会优先在node01上创建Pod
32 kubectl delete pod --all && kubectl apply -f pod2.yaml && kubectl get pods -o wide
1 //示例:
2 apiVersion: v1
3 kind: Pod
4 metadata:
5 name: affinity
6 labels:
7 app: node-affinity-pod
8 spec:
9 containers:
10 - name: with-node-affinity
11 image: soscscs/myapp:v1
12 affinity:
13 nodeAffinity:
14 requiredDuringSchedulingIgnoredDuringExecution: #先满足硬策略,排除有kubernetes.io/hostname=node02标签的节点
15 nodeSelectorTerms:
16 - matchExpressions:
17 - key: kubernetes.io/hostname
18 operator: NotIn
19 values:
20 - node02
21 preferredDuringSchedulingIgnoredDuringExecution: #再满足软策略,优先选择有kgc=a标签的节点
22 - weight: 1
23 preference:
24 matchExpressions:
25 - key: kgc
26 operator: In
27 values:
28 - a
Pod亲和性与反亲和性
1 //创建一个标签为 app=myapp01 的 Pod
2 vim pod3.yaml
3 apiVersion: v1
4 kind: Pod
5 metadata:
6 name: myapp01
7 labels:
8 app: myapp01
9 spec:
10 containers:
11 - name: with-node-affinity
12 image: soscscs/myapp:v1
13
14
15 kubectl apply -f pod3.yaml
16
17 kubectl get pods --show-labels -o wide
18 NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES LABELS
19 myapp01 1/1 Running 0 37s 10.244.2.3 node01 <none> <none> app=myapp01
1 vim pod4.yaml
2 apiVersion: v1
3 kind: Pod
4 metadata:
5 name: myapp02
6 labels:
7 app: myapp02
8 spec:
9 containers:
10 - name: myapp02
11 image: soscscs/myapp:v1
12 affinity:
13 podAffinity:
14 requiredDuringSchedulingIgnoredDuringExecution:
15 - labelSelector:
16 matchExpressions:
17 - key: app
18 operator: In
19 values:
20 - myapp01
21 topologyKey: kgc
1 示例1:
2 vim pod5.yaml
3 apiVersion: v1
4 kind: Pod
5 metadata:
6 name: myapp10
7 labels:
8 app: myapp10
9 spec:
10 containers:
11 - name: myapp10
12 image: soscscs/myapp:v1
13 affinity:
14 podAntiAffinity:
15 preferredDuringSchedulingIgnoredDuringExecution:
16 - weight: 100
17 podAffinityTerm:
18 labelSelector:
19 matchExpressions:
20 - key: app
21 operator: In
22 values:
23 - myapp01
24 topologyKey: kubernetes.io/hostname
1 示例2:
2 vim pod6.yaml
3 apiVersion: v1
4 kind: Pod
5 metadata:
6 name: myapp20
7 labels:
8 app: myapp20
9 spec:
10 containers:
11 - name: myapp20
12 image: soscscs/myapp:v1
13 affinity:
14 podAntiAffinity:
15 requiredDuringSchedulingIgnoredDuringExecution:
16 - labelSelector:
17 matchExpressions:
18 - key: app
19 operator: In
20 values:
21 - myapp01
22 topologyKey: kgc
污点(Taint) 和 容忍(Tolerations)
污点(Taint)
1 kubectl get nodes
2 NAME STATUS ROLES AGE VERSION
3 master Ready master 11d v1.20.11
4 node01 Ready <none> 11d v1.20.11
5 node02 Ready <none> 11d v1.20.11
6
7 //master 就是因为有 NoSchedule 污点,k8s 才不会将 Pod 调度到 master 节点上
8 kubectl describe node master
9 ......
10 Taints: node-role.kubernetes.io/master:NoSchedule
11
12
13 #设置污点
14 kubectl taint node node01 key1=value1:NoSchedule
15
16 #节点说明中,查找 Taints 字段
17 kubectl describe node node-name
18
19 #去除污点
20 kubectl taint node node01 key1:NoSchedule-
21
22
23 kubectl get pods -o wide
24 NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
25 myapp01 1/1 Running 0 4h28m 10.244.2.3 node02 <none> <none>
26 myapp02 1/1 Running 0 4h13m 10.244.2.4 node02 <none> <none>
27 myapp03 1/1 Running 0 3h45m 10.244.1.4 node01 <none> <none>
28
29 kubectl taint node node02 check=mycheck:NoExecute
30
31 //查看 Pod 状态,会发现 node02 上的 Pod 已经被全部驱逐(注:如果是 Deployment 或者 StatefulSet 资源类型,为了维持副本数量则会在别的 Node 上再创建新的 Pod)
32 kubectl get pods -o wide
33 NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
34 myapp03 1/1 Running 0 3h48m 10.244.1.4 node01 <none> <none>
容忍(Tolerations)
1 vim pod3.yaml
2
3
4 kubectl apply -f pod3.yaml
5
6 //在两个 Node 上都设置了污点后,此时 Pod 将无法创建成功
7 kubectl get pods -o wide
8 NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
9 myapp01 0/1 Pending 0 17s <none> <none> <none> <none>
10
11 vim pod3.yaml
12 apiVersion: v1
13 kind: Pod
14 metadata:
15 name: myapp01
16 labels:
17 app: myapp01
18 spec:
19 containers:
20 - name: with-node-affinity
21 image: soscscs/myapp:v1
22 tolerations:
23 - key: "check"
24 operator: "Equal"
25 value: "mycheck"
26 effect: "NoExecute"
27 tolerationSeconds: 3600
其它注意事项
cordon 和 drain
Pod启动阶段(相位 phase)
##故障排除步骤:
总结:
K8S群集调度器的更多相关文章
- Kubernetes K8S之调度器kube-scheduler详解
Kubernetes K8S之调度器kube-scheduler概述与详解 kube-scheduler调度概述 在 Kubernetes 中,调度是指将 Pod 放置到合适的 Node 节点上,然后 ...
- 9.深入k8s:调度器及其源码分析
转载请声明出处哦~,本篇文章发布于luozhiyun的博客:https://www.luozhiyun.com 源码版本是1.19 这次讲解的是k8s的调度器部分的代码,相对来说比较复杂,慢慢的梳理清 ...
- k8s之调度器、预选策略及优选函数
1.调度器(scheduler) 调度器的功能是调度Pod在哪个Node上运行,这些调度信息存储在master上的etcd里面,能够和etcd打交道的只有apiserver; kubelet运行在no ...
- Kubernetes 学习20调度器,预选策略及优选函数
一.概述 1.k8s集群中能运行pod资源的其实就是我们所谓的节点,也称为工作节点.master从本质上来讲,他其实是运行整个集群的控制平面组件的比如apiserver,scheal,controlm ...
- TKE 用户故事 | 作业帮 Kubernetes 原生调度器优化实践
作者 吕亚霖,2019年加入作业帮,作业帮架构研发负责人,在作业帮期间主导了云原生架构演进.推动实施容器化改造.服务治理.GO微服务框架.DevOps的落地实践. 简介 调度系统的本质是为计算服务/任 ...
- k8s调度器、预选策略及调度方式
一.k8s调度流程 1.(预选)先排除完全不符合pod运行要求的节点2.(优先)根据一系列算法,算出node的得分,最高没有相同的,就直接选择3.上一步有相同的话,就随机选一个 二.调度方式 1.no ...
- 7.k8s.调度器scheduler 亲和性、污点
#k8s. 调度器scheduler 亲和性.污点 默认调度过程:预选 Predicates (过滤节点) --> 优选 Priorities(优先级排序) --> 优先级最高节点 实际使 ...
- k8s调度器kube-scheduler
kube-scheduler简介 调度是容器编排的重要环节,需要经过严格的监控和控制,现实生产通常对调度有各类限制,譬如某些服务必须在业务独享的机器上运行,或者从灾备的角度考虑尽量把服务调度到不同机器 ...
- 泡面不好吃,我用了这篇k8s调度器,征服了他
1.1 调度器简介 来个小刘一起 装逼吧 ,今天我们来学习 K8的调度器 Scheduler是 Kubernetes的调度器,主要的任务是把定义的 pod分配到集群的节点上,需要考虑以下问题: 公平: ...
- k8s调度器介绍(调度框架版本)
从一个pod的创建开始 由kubectl解析创建pod的yaml,发送创建pod请求到APIServer. APIServer首先做权限认证,然后检查信息并把数据存储到ETCD里,创建deployme ...
随机推荐
- Error: EPERM: operation not permitted, mkdir ‘C:\Program Files\nodejs‘TypeError: Cannot read proper
出现问题: 问题如题,出现场景:vscode运行npm命令 解决办法: 有的友友说安装nodejs时用管理员身份安装,右键没找到最后删掉了此文件即可. 这个文件缓存了之前的配置与现在安装的nodejs ...
- TCP/IP协议(4): 地址解析协议(ARP) —— 网络地址转换为物理地址的方式
TCP/IP协议(4): 地址解析协议(ARP)--网络地址转换为物理地址的方式 关于地址解析协议(Address Resolution Protocol, ARP) 关于 ARP 地址解析协议(Ad ...
- P2617 Dynamic Rankings 解题报告
link 整体二分是一种东西,比如上面这道题. 先考虑一个不带修版本的,也就是经典问题区间 kth,显然我们可以主席树但是我知道你很想用主席树但是你先别用不用主席树,用一种离线的算法,叫整体二分. 首 ...
- [EULAR文摘] 脊柱放射学持续进展是否显著影响关节功能
脊柱放射学持续进展是否显著影响关节功能 Poddubnyy D, et al. EULAR 2015. Present ID: THU0199. 背景: 强直性脊柱炎(AS)患者的机体功能和脊柱活动性 ...
- 随时代变迁而进化的治疗策略不断提高RA无药缓解机会[EULAR2015_SAT0058]
随时代变迁而进化的治疗策略不断提高RA无药缓解机会 SAT0058 DMARD-FREE SUSTAINED REMISSION IN RHEUMATOID ARTHRITIS: AN OUTCOME ...
- .net webapi+jwt demo
一.新建.net webapi程序 二.nuget包搜索jwt,点击安装 三.在model文件夹下建立三个主要类: public class AuthInfo { /// &l ...
- LRU 居然翻译成最近最少使用?真相原来是这样!(附力扣题解)
前言 相信有很多同学和我一样,第一次碰到 LRU(Least Recently Used) 的这个解释「最近最少使用」都不知道是什么意思,用汤家凤老师的话来说: 我真的感到匪夷所思啊! 最近是表示时间 ...
- rsut 字节数组和字符串转换
一.字符串转换为字节数组 let s = String::from("str"); let v = s.as_bytes(); // &[u8] println!(&quo ...
- WPF 打印界面控件内容
public class PrintDialogHelper { private const string PrintServerName = "DESKTOP-49LV5U6"; ...
- Windows常用快捷键(但我本人不太熟知的)
Shift+Ctrl+ESC: 打开任务管理器 Windows+E: 打开文件资源管理器 Windows+R: 运行文件 Windows+Tab: 切换应用程序 Shift+Delete: 永久删除