PCA降维的原理及实现
PCA可以将数据从原来的向量空间映射到新的空间中。由于每次选择的都是方差最大的方向,所以往往经过前几个维度的划分后,之后的数据排列都非常紧密了, 我们可以舍弃这些维度从而实现降维
原理
内积
两个向量的乘积满足:\(ab= |a|\cdot |b|\cdot cos(\theta)\).如果\(|b|=1\)的话,\(ab=|a| \cdot cos(\theta)\). 而这个式子的含义就是a在b方向上的投影长度。pca用投影的长度的方差来衡量一个向量基的好坏。
基变换的矩阵表示
如果我想要把M个N维向量变换到M的R维向量。那么我需要:
- 把每条数据当成行向量X。即m行n列,共m条数据, \(A=(x_1, x_2,...,x_m)^T\)
- 每个基当成一个列向量,按列排成矩阵P, \(P=(p_1, p_2, .., p_k)\)
- XP就是变换的结果
比如有两个基 \((1/\sqrt2, 1/\sqrt2)^T\), \((-1/\sqrt2, 1/\sqrt2)^T\).这是两个正交的基。一个向量\((3, 2)^T\).
3 & 2
\end{pmatrix}
\begin{bmatrix}
1/\sqrt2 & -1/\sqrt2 \\\\
1/\sqrt2 & 1/\sqrt2 \\\\
\end{bmatrix}
= \begin{pmatrix}
5/\sqrt2 & -1/\sqrt2
\end{pmatrix}
\]
- R个P表示R个基,即新空间有R维,因此 R<=m
- Pi* aj 表示 ai投影到pi上的投影的大小
这里也可以将新空间中的坐标转换回来,先看看他们的关系
\]
所以要求X需要计算P的逆矩阵:
\]
由于 \(P \cdot P^T =1\), 故P是一个可逆矩阵,且模为1,\(P^{-1} = P^T\)。所以最后可以这样计算X:
\]
最大化方差理论
每个向量投影到新的空间后,计算所有向量的投影的方差。方差越大,表示数据分布的越"散"。因为数据过于集中就不好处理,数据越散就越容易分开。实际上经过多次投影后,最后几个维度数据往往都集中在一起,这时这些维度就可以舍弃,这就是pca降维的思路。
pca降维的第一步是,让所有向量减去每个特征的平均值。这样会给后面的处理带来非常大的方便。比如计算一个向量的方差:
\]
而减去均值后,每个向量的均值都为0,所以可以简化为:
\]
注意!!!
这里的均值指的是同一个特征,不同的向量的均值。先通过每一个向量计算出各个特征的均值。再把每个向量的每个特征减去对应的均值。
PCA希望使用相关度最低的基来构建新的向量空间。也就是尽量寻找线性无关的向量(当然最好是正交),这样重合的信息会很少。在pca中,使用协方差来衡量各个特征之间的相关性。
- cov > 0 正相关
- cov == 0 不相关
- cov < 0 负相关
也就是说各个基向量之间满足cov==0就可以了。下面介绍协方差
协方差
协方差的计算公式如下(这里的\(a_i, b_i\)都是数字):
\]
那么,要使协方差为0,也是ab=0,也就是向量正交!
一般情况下,a,b表示的是两个特征的列向量。并不是一条数据。而是各个数据的两个特征的一个列向量。
协方差矩阵
顾名思义,用矩阵来保存各个特征之前的协方差。如果数据有n个维度(n个特征),那么,他的协方差矩阵\(\sum\)是一个n*n的矩阵。\(\sum_{ij}\) 表示第i和第j个特征的相关度(协方差).
对于\(m \cdot n\)的数据集X(m条数据集,每条数据n个特征),他的协方差可以通过下面的公式简单的计算出来:
\]
也有人写成这种形式, \(x^{(i)}\)表示第i个向量:
\]
推理如下。(打公式太慢了)
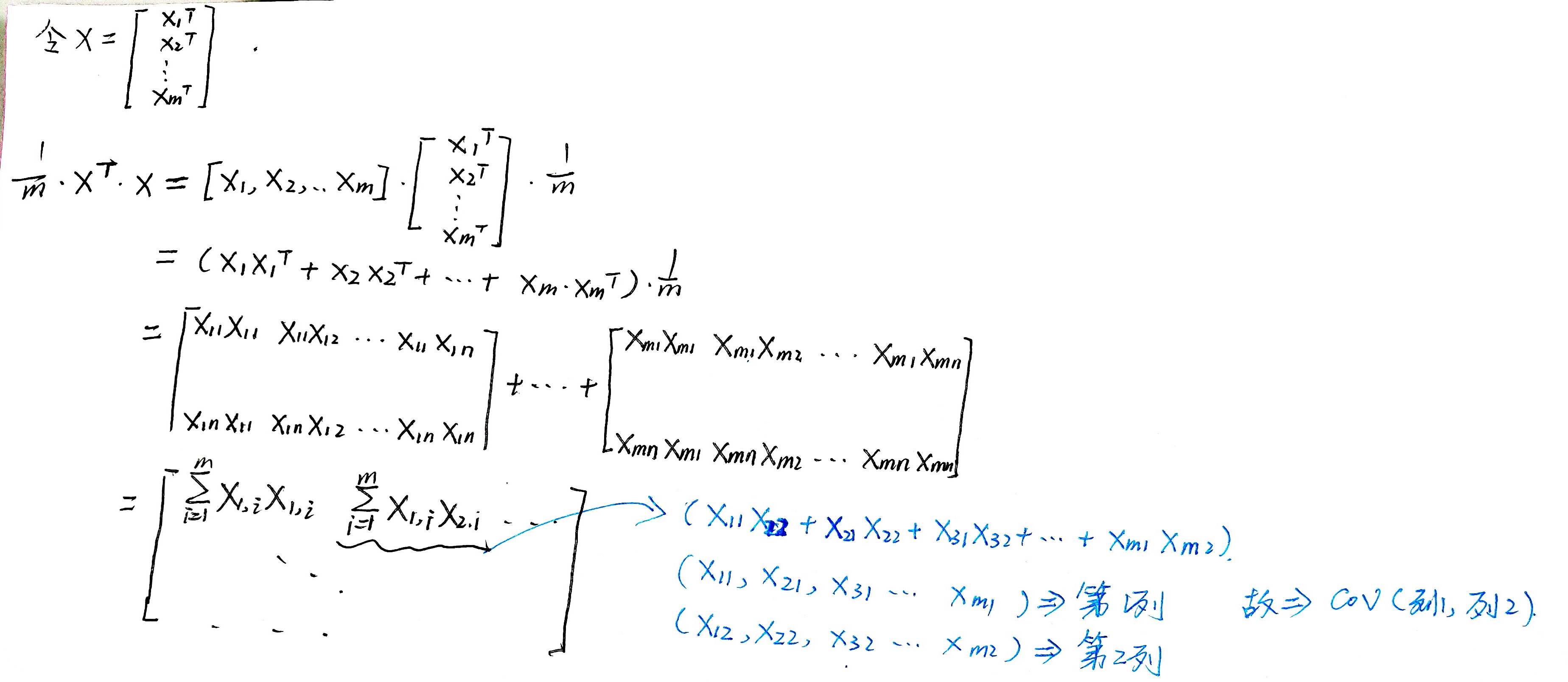
协方差矩阵和PCA
假设有m行n列的数据集 X(这里的X是1.2的X的转置),X 映射到新的向量空间后的坐标Y, Y的协方差矩阵为D。那么有以下关系:
\]
\]
这里的P是\(n*k\)的矩阵,由k的列向量组成,当k小于n时就是降维了。
所以,映射到新的坐标系后的协方差矩阵就是D这里有几点需要注意:
- 1、因为我们希望新的向量基是线性无关的,也就是不同的基之间的协方差应该为0。所以我们要让这个D变成对角矩阵(对角元其实就是方差)
- 2、n维实对称矩阵的性质:一定存在n的线性无关的特征向量。
- 3、通过\(\Lambda = P^TAP\)的方式将实对称矩阵转换维对角矩阵。此时P是用n个线性无关的特征向量(列向量)组成的单位矩阵。\(\Lambda\)是新的向量基对每个维度上的向量对应的方差。
- 4、选择最大的k个 \(\lambda\) 对应的k个特征向量就是我们要求的向量基
实现
linalg.eig(covMat)是numpy的线性代数模块的函数。该函数的api的描述是,返回一个:
归一化(单位“长度”)特征向量,使得列v[:,i]是对应于特征值w[i]
pca的实现真的好简单啊,但是他的原理我花了好久才看明白。心累。
def pca(data, k):
# DeMean
dataMean = np.mean(data, axis=0)
data_demean = data - dataMean
# 计算协方差矩阵
covMat = data_demean.T.dot(data_demean) / len(data)
# 计算cov的特征值和特征向量
eigVals, eigVects = linalg.eig(covMat)
# 找到前k大的lambda对应的特征向量
eigVals_index = np.argsort(-eigVals) # 前k特征值的索引
eigVal_wanted = eigVals_index[:k] # 前k个特征值
eigVect_wanted = eigVects[:, eigVal_wanted] # 前k个特征向量
low_dim_data = data_demean.dot(eigVect_wanted) # 转换坐标
recon = low_dim_data.dot(eigVect_wanted.T) + dataMean # 还原坐标
return low_dim_data, recon
它可以将高维的数据转换到低维,也可以将转换过的坐标再还原。但是如果是从高维到低维,转换的过程已经损失了一部分数据了,再还原回去时,就和原来不一样了。这样有好也有坏,因为有时候,他还可以去除一些噪音数据。
随机使用一个数据:
X = np.empty((100,2))
X[:, 0] = np.random.uniform(0, 100, 100)
X[:, 1] = 0.75 * X[:, 0] + 3. + np.random.normal(0, 10, 100)
plt.scatter(X[:, 0], X[:, 1])
# 2维降1维
low, rec = pca(X, 1)
plt.scatter(rec[:, 0], rec[:,1])
如果,k的维度和原来一样,就可以无损的还原回来。但是如果降低了维度,再还原就会损失数据:

sklearn中的PCA
sklearn中的PCA在 sklearn.decomposition下的PCA中:
from sklearn.decomposition import PCA
pca = PCA(n_components=2)
pca.fit(X_train)
X_train_reduction = pca.transform(X_train)
X_test_reduction = pca.transform(X_test)
pca可以直接写浮点数,可以手动少选方差和大于阈值的维度
pca3 = PCA(0.9)
pca3.fit(X_train)
一些参数:
pca2.explained_variance_ # 在各个主成分上的方差
pca2.explained_variance_ratio_ # 各个主成分方差占总方差的比例
PCA降维的原理及实现的更多相关文章
- PCA降维的原理、方法、以及python实现。
PCA(主成分分析法) 1. PCA(最大化方差定义或者最小化投影误差定义)是一种无监督算法,也就是我们不需要标签也能对数据做降维,这就使得其应用范围更加广泛了.那么PCA的核心思想是什么呢? 例如D ...
- LDA和PCA降维的原理和区别
LDA算法的主要优点有: 在降维过程中可以使用类别的先验知识经验,而像PCA这样的无监督学习则无法使用类别先验知识. LDA在样本分类信息依赖均值而不是方差的时候,比PCA之类的算法较优. LDA算 ...
- sklearn pca降维
PCA降维 一.原理 这篇文章总结的不错PCA的数学原理. PCA主成分分析是将原始数据以线性形式映射到维度互不相关的子空间.主要就是寻找方差最大的不相关维度.数据的最大方差给出了数据的最重要信息. ...
- 数据降维技术(1)—PCA的数据原理
PCA(Principal Component Analysis)是一种常用的数据分析方法.PCA通过线性变换将原始数据变换为一组各维度线性无关的表示,可用于提取数据的主要特征分量,常用于高维数据的降 ...
- [综] PCA降维
http://blog.json.tw/using-matlab-implementing-pca-dimension-reduction 設有m筆資料, 每筆資料皆為n維, 如此可將他們視為一個mx ...
- PCA的数学原理
PCA(Principal Component Analysis)是一种常用的数据分析方法.PCA通过线性变换将原始数据变换为一组各维度线性无关的表示,可用于提取数据的主要特征分量,常用于高维 数据的 ...
- 【机器学习笔记之七】PCA 的数学原理和可视化效果
PCA 的数学原理和可视化效果 本文结构: 什么是 PCA 数学原理 可视化效果 1. 什么是 PCA PCA (principal component analysis, 主成分分析) 是机器学习中 ...
- PCA的数学原理(转)
PCA(Principal Component Analysis)是一种常用的数据分析方法.PCA通过线性变换将原始数据变换为一组各维度线性无关的表示,可用于提取数据的主要特征分量,常用于高维数据的降 ...
- Python机器学习笔记 使用scikit-learn工具进行PCA降维
之前总结过关于PCA的知识:深入学习主成分分析(PCA)算法原理.这里打算再写一篇笔记,总结一下如何使用scikit-learn工具来进行PCA降维. 在数据处理中,经常会遇到特征维度比样本数量多得多 ...
随机推荐
- [跨数据库、微服务] FreeSql 分布式事务 TCC/Saga 编排重要性
前言 FreeSql 支持 MySql/SqlServer/PostgreSQL/Oracle/Sqlite/Firebird/达梦/Gbase/神通/人大金仓/翰高/Clickhouse/MsAcc ...
- 使用dotnet-monitor分析在Kubernetes的应用程序:Sidecar模式
dotnet-monitor可以在Kubernetes中作为Sidecar运行,Sidecar是一个容器,它与应用程序在同一个Pod中运行,利用Sidecar模式使我们可以诊断及监控应用程序. 如下图 ...
- Python小游戏——外星人入侵(保姆级教程)第一章 07调整飞船速度 08限制飞船活动范围
系列文章目录 第一章:武装飞船 07调整飞船速度 08限制飞船活动范围 一.代码及演示 1.修改settings 修改文件:settings.py 点击查看代码 #渗透小红帽python的学习之路 # ...
- SpringBoot中maven项目Plugins里resources报红
错误原因:刚开始下载依赖时下载错误导致的 参考:解决idea中maven plugins标红的问题 - 走看看 (zoukankan.com) 如果还不行: 就根据上面提示的地址找到maven的配置包 ...
- QtCreator使用AStyle配置VS默认编辑代码风格
基础配置和下载 基础配置和下载,随便找一个教程就行 下面贴出我的配置 --style=allman indent=spaces=4 indent-switches indent-preproc-blo ...
- Flink SQL 子图复用逻辑分析
子图复用优化是为了找到SQL执行计划中重复的节点,将其复用,避免这部分重复计算的逻辑.先回顾SQL执行的主要流程 parser -> validate -> logical optimiz ...
- keycloak~资源的远程授权
17.1远程资源授权准备 17.1.1认证和访问流程图 参考:http://www.zyiz.net/tech/detail-141309.html 17.1.2为用户指定角色 可以使用ROLE_US ...
- Containerd教程
文档是从B站有关视频上对应找到的,具体视频地址是:https://www.bilibili.com/video/BV1XL4y1F7QB?p=21&spm_id_from=333.880.my ...
- SkyWalking 6.x 的架构图
可以看到主要由四部分组成: Agent(也叫Probe):代理或者探针,集成在被监测的应用中(SDK形式或者动态注入),采集应用的数据发送给后端(OAP). UI:自带的Web页面. OAP:后端,接 ...
- Nginx负载均衡设置max_fails和fail_timeout
在Nginx的负载均衡检查模块中,对于负载均衡的节点可以配置如下可选参数: max_fails=1 fail_timeout=10s 这个是Nginx在负载均衡功能中,用于判断后端节点状态,所用到两个 ...