【Spark】Day04-Spark Streaming:与离线批量比较、架构特点、入门案例、创建(队列、数据源)、转换(有状态、无状态)、输出方式、进阶(累加、转换为DF、缓存持久化)、实战(窗口统计)
一、概述
1、离线和实时计算
离线:数据量大,数据不会变化,MapReduce
实时:数据量小,计算过程要短
2、批量和流式处理
批量:冷数据,数据量大,速度慢
流:在线、实时产生的数据(快速持续到达)
3、Spark Streaming介绍
支持大量输入输出数据源的流式处理
数据输入后可以使用spark算子进行运算
处理一批流式数据,设置批处理间隔,实现汇总到一定量后再操作
使用了离散化流(discretized stream)称为DStreams,是由RDD组成的数据序列
4、Spark Streaming的特点
优点:易用、容错、易整合到Spark体系
缺陷:微量批处理、延迟高
5、Spark Streaming架构
(1)架构图
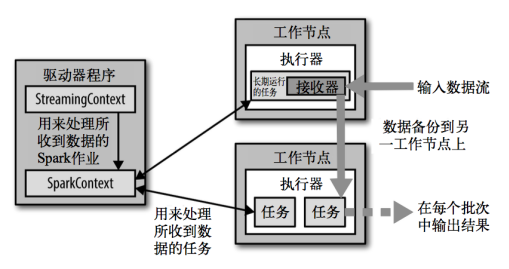
输入后备份数据到另一节点,并通过sparkcontext在另一个节点上处理并输出节点
(2)背压机制
spark.streaming.receiver.maxRate可以限制接收速率,但会导致资源利用率下降
使用背压机制(即Spark Streaming Backpressure)可以根据作业执行信息动态调整数据Receiver接收率
spark.streaming.backpressure.enabled配置背压机制是否开启
二、DStream入门
1、WordCount案例实操
netcat工具向9999端口不断的发送数据nc -lk 9999,spark读取并统计单词出现的次数
object Spark01_WordCount {
def main(args: Array[String]): Unit = {
//创建配置文件对象 注意:Streaming程序至少不能设置为local,至少需要2个线程
val conf: SparkConf = new SparkConf().setAppName("Spark01_W").setMaster("local[*]")
//创建Spark Streaming上下文环境对象
val ssc = new StreamingContext(conf,Seconds(3))
//操作数据源-从端口中获取一行数据
val socketDS: ReceiverInputDStream[String] = ssc.socketTextStream("hadoop202",9999)
//对获取的一行数据进行扁平化操作
val flatMapDS: DStream[String] = socketDS.flatMap(_.split(" "))
//结构转换
val mapDS: DStream[(String, Int)] = flatMapDS.map((_,1))
//对数据进行聚合
val reduceDS: DStream[(String, Int)] = mapDS.reduceByKey(_+_)
//输出结果 注意:调用的是DS的print函数
reduceDS.print()
//启动采集器
ssc.start()
//默认情况下,上下文对象不能关闭
//ssc.stop()
//等待采集结束,终止上下文环境对象
ssc.awaitTermination()
}
}
2、WordCount解析
DStream是持续性的数据流和经过各种Spark算子操作后的结果数据流
内部是一系列连续的RDD
3、几点注意
一个SparkContext可以重用多个StreamingContext
stop() 的方式停止StreamingContext, 也会把SparkContext停掉
仅想停止StreamingContext, 则应该这样: stop(false)
三、DStream创建
1、RDD队列
使用ssc.queueStream(queueOfRDDs)创建DStream
每一个RDD都被作为一个DStream
object Spark02_DStreamCreate_RDDQueue {
def main(args: Array[String]): Unit = {
// 创建Spark配置信息对象
val conf = new SparkConf().setMaster("local[*]").setAppName("RDDStream")
// 创建SparkStreamingContext
val ssc = new StreamingContext(conf, Seconds(3))
// 创建RDD队列
val rddQueue = new mutable.Queue[RDD[Int]]()
// 创建QueueInputDStream
val inputStream = ssc.queueStream(rddQueue,oneAtATime = false)
// 处理队列中的RDD数据
val mappedStream = inputStream.map((_,1))
val reducedStream = mappedStream.reduceByKey(_ + _)
// 打印结果
reducedStream.print()
// 启动任务
ssc.start()
// 循环创建并向RDD队列中放入RDD
for (i <- 1 to 5) {
rddQueue += ssc.sparkContext.makeRDD(1 to 5, 10)
Thread.sleep(2000)
}
ssc.awaitTermination()
}
}
2、自定义数据源
继承Receiver,并实现onStart、onStop方法,从而自定义数据源采集
实现监控某个端口号,获取该端口号内容
3、Kafka数据源
KafkaUtils对象以Kafka消息创建出 DStream。
核心类:KafkaUtils(高级API)、KafkaCluster(低级API)
分别使用高级API和低级API方式实现wordcount
四、DStream转换
操作分为分为Transformations(转换,包含一些特殊算子)和Output(输出)
1、无状态转化操作【每个批次内部转化】
RDD转化操作应用到每个批次,归约每个时间区间中的数据
转化DStream中的每一个RDD
Transform:RDD-RDD
val wordAndCountDStream: DStream[(String, Int)] = lineDStream.transform(rdd => {
val words: RDD[String] = rdd.flatMap(_.split(" "))
val wordAndOne: RDD[(String, Int)] = words.map((_, 1))
val value: RDD[(String, Int)] = wordAndOne.reduceByKey(_ + _)
value
})
2、有状态转化操作
(1)UpdateStateByKey:将历史结果应用到当前批次,更新并保留状态,结果会是一个新的DStream
跨批次维护状态,由每个时间区间对应的(键,状态)对组成,可以访问状态变量
步骤:定义状态、定义状态更新函数,使用检查点保存状态
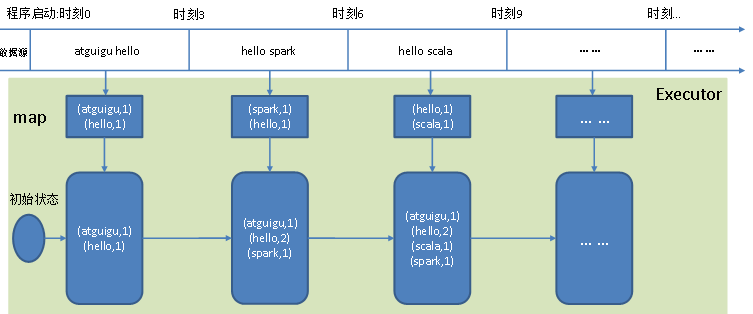
例子:每隔一段时间景点人流量变化
object Spark07_State_updateStateByKey {
def main(args: Array[String]): Unit = {
//创建SparkConf
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("WordCount")
//创建StreamingContext
val ssc = new StreamingContext(conf, Seconds(3))
//设置检查点路径 用于保存状态
ssc.checkpoint("D:\\dev\\workspace\\my-bak\\spark-bak\\cp")
//创建DStream
val lineDStream: ReceiverInputDStream[String] = ssc.socketTextStream("hadoop202", 9999)
//扁平映射
val flatMapDS: DStream[String] = lineDStream.flatMap(_.split(" "))
//结构转换
val mapDS: DStream[(String, Int)] = flatMapDS.map((_,1))
//聚合
// 注意:DStreasm中reduceByKey只能对当前采集周期(窗口)进行聚合操作,没有状态
//val reduceDS: DStream[(String, Int)] = mapDS.reduceByKey(_+_)
val stateDS: DStream[(String, Int)] = mapDS.updateStateByKey(
(seq: Seq[Int], state: Option[Int]) => {
Option(seq.sum + state.getOrElse(0))
}
)
//打印输出
stateDS.print()
//启动
ssc.start()
ssc.awaitTermination()
}
}
(2)Window Operations(窗口操作):将计算应用到一个指定的窗口内的所有 RDD,需要两个参数,分别为窗口时长(计算内容的时间范围)以及滑动步长(多久触发一次计算)。
两个参数需要为采集周期的整数倍
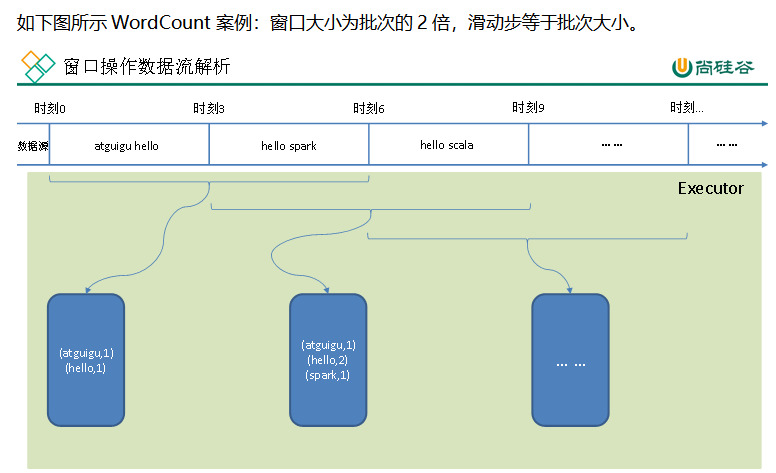
需求:3秒统计一次一小时人流量的变化
/**
* Author: Felix
* Date: 2020/2/21
* Desc: 有状态转换-window相关操作
*/
object Spark08_State_window {
def main(args: Array[String]): Unit = {
//创建SparkConf
val sparkConf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("WordCount")
//创建StreamingContext
val ssc = new StreamingContext(sparkConf, Seconds(3))
//设置检查点路径 用于保存状态
ssc.checkpoint("D:\\dev\\workspace\\my-bak\\spark-bak\\cp")
//创建DStream
val lineDStream: ReceiverInputDStream[String] = ssc.socketTextStream("hadoop202", 9999)
//扁平映射
val flatMapDS: DStream[String] = lineDStream.flatMap(_.split(" "))
//设置窗口大小,滑动的步长
val windowDS: DStream[String] = flatMapDS.window(Seconds(6),Seconds(3))
//结构转换
val mapDS: DStream[(String, Int)] = windowDS.map((_,1))
//聚合
val reduceDS: DStream[(String, Int)] = mapDS.reduceByKey(_+_)
reduceDS.print()
//启动
ssc.start()
ssc.awaitTermination()
}
}
(3)其他方法

五、DStream输出
1、常用输出操作
print()
saveAsTextFiles(prefix, [suffix])
saveAsObjectFiles(prefix, [suffix])
saveAsHadoopFiles(prefix, [suffix])
foreachRDD(func)
六、编程进阶
1、累加器和广播变量
同RDD的累加器
2、DataFrame and SQL Operations
RDD被转换为DataFrame,以临时表格配置并用SQL进行查询
val spark = SparkSession.builder.config(conf).getOrCreate()
import spark.implicits._
mapDS.foreachRDD(rdd =>{
val df: DataFrame = rdd.toDF("word", "count")
df.createOrReplaceTempView("words")
spark.sql("select * from words").show
})
3、Caching / Persistence【缓存和持久化】
使用使用persist()方法将RDD保存到内存中
基于状态的操作,隐含默认保存
七、Spark Streaming项目实战
1、准备数据
用户对广告点击的行为数据
时间戳, 地区, 城市, 用户id, 广告id
1566035129449, 华南, 深圳, 101, 2
模拟生成数据并从kafka中读取数据【将数据输出到kafka】
2、每天每地区热门广告Top3
原始数据结构化,并进行批次累加【聚合、结构转换、按天和地区分组】
val mapDS = dataDS.map {
line => {
val fields = line.split(",")
//格式化时间戳
val timeStamp = fields(0).toLong
val day = new Date(timeStamp)
val sdf = new SimpleDateFormat("yyyy-MM-dd")
val dayStr = sdf.format(day)
val area = fields(1)
val adv = fields(4)
((dayStr + "_" + area + "_" + adv), 1)
}
}
//3.将转换结构后的数据进行聚合处理 (天_地区_广告,点击次数sum)
//注意:这里要统计每天数据,所有要把每个采集周期的数据都统计,需要保存状态,使用updateStateByKey
val updateDS = mapDS.updateStateByKey(
(seq: Seq[Int], buffer: Option[Int]) => {
Option(buffer.getOrElse(0) + seq.sum)
}
)
//4.将聚合后的数据进行结构的转换 (天_地区,(广告,点击次数sum)))
val mapDS1: DStream[(String, (String, Int))] = updateDS.map {
case (k, sum) => {
val ks: Array[String] = k.split("_")
(ks(0) +"_" +ks(1),(ks(2), sum))
}
}
//5.按照天_地区对数据进行分组 (时间,Iterator[(地区,(广告,点击次数sum))])
val groupDS: DStream[(String, Iterable[(String, Int)])] = mapDS1.groupByKey()
//6.对分组后的数据降序取前三
val resDS: DStream[(String, List[(String, Int)])] = groupDS.mapValues {
datas => {
datas.toList.sortBy(-_._2).take(3)
}
}
3、最近1小时广告点击量实时统计
定义窗口,并将窗口内数据进行聚合
/**
* 需求二:统计各广告最近1小时内的点击量趋势,每6s更新一次(各广告最近1小时内各分钟的点击量)
* 1.最近一个小时 窗口的长度为1小时
* 2.每6s更新一次 窗口的滑动步长是6s
* 3.各个广告每分钟的点击量 ((advId,hhmm),1)
*/
//创建DS
val kafkaDS: InputDStream[(String, String)] = KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder](
ssc, kafkaParams, Set(topic)) //测试Kafka中消费数据 msg = 1584271384370,华南,广州,100,1
val dataDS: DStream[String] = kafkaDS.map(_._2) //定义窗口
val windowDS: DStream[String] = dataDS.window(Seconds(12),Seconds(3)) //转换结构为 ((advId,hhmm),1)
val mapDS: DStream[((String, String), Int)] = windowDS.map {
line => {
val fields: Array[String] = line.split(",")
val ts: Long = fields(0).toLong
val day: Date = new Date(ts)
val sdf: SimpleDateFormat = new SimpleDateFormat("hh:mm")
val time = sdf.format(day)
((fields(4), time), 1)
}
} //对数据进行聚合
val resDS: DStream[((String, String), Int)] = mapDS.reduceByKey(_+_)
resDS.print()
【Spark】Day04-Spark Streaming:与离线批量比较、架构特点、入门案例、创建(队列、数据源)、转换(有状态、无状态)、输出方式、进阶(累加、转换为DF、缓存持久化)、实战(窗口统计)的更多相关文章
- spark教程(16)-Streaming 之 DStream 详解
DStream 其实是 RDD 的序列,它的语法与 RDD 类似,分为 transformation(转换) 和 output(输出) 两种操作: DStream 的转换操作分为 无状态转换 和 有状 ...
- Spark 以及 spark streaming 核心原理及实践
收录待用,修改转载已取得腾讯云授权 作者 | 蒋专 蒋专,现CDG事业群社交与效果广告部微信广告中心业务逻辑组员工,负责广告系统后台开发,2012年上海同济大学软件学院本科毕业,曾在百度凤巢工作三年, ...
- 大数据技术之_27_电商平台数据分析项目_02_预备知识 + Scala + Spark Core + Spark SQL + Spark Streaming + Java 对象池
第0章 预备知识0.1 Scala0.1.1 Scala 操作符0.1.2 拉链操作0.2 Spark Core0.2.1 Spark RDD 持久化0.2.2 Spark 共享变量0.3 Spark ...
- spark教程(15)-Streaming
Spark Streaming 是一个分布式数据流处理框架,它可以近乎实时的处理流数据,它易编程,可以处理大量数据,并且能把实时数据与历史数据结合起来处理. Streaming 使得 spark 具有 ...
- Real Time Credit Card Fraud Detection with Apache Spark and Event Streaming
https://mapr.com/blog/real-time-credit-card-fraud-detection-apache-spark-and-event-streaming/ Editor ...
- WARN deploy.SparkSubmit$$anon$2: Failed to load org.apache.spark.examples.sql.streaming.StructuredNetworkWordCount.
前言 今天运行Spark Structured Streaming官网的如下 ./bin/run-example org.apache.spark.examples.sql.streaming.Str ...
- 【转】科普Spark,Spark是什么,如何使用Spark
本博文是转自如下链接,为了方便自己查阅学习和他人交流.感谢原博主的提供! http://www.aboutyun.com/thread-6849-1-1.html http://www.aboutyu ...
- Spark入门(1-1)什么是spark,spark和hadoop
一.Spark是什么? Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎,可用来构建大型的.低延迟的数据分析应用程序. Spark是UC Berkeley AMP lab (加 ...
- 科普Spark,Spark核心是什么,如何使用Spark(1)
科普Spark,Spark是什么,如何使用Spark(1)转自:http://www.aboutyun.com/thread-6849-1-1.html 阅读本文章可以带着下面问题:1.Spark基于 ...
- Spark之 spark简介、生态圈详解
来源:http://www.cnblogs.com/shishanyuan/p/4700615.html 1.简介 1.1 Spark简介Spark是加州大学伯克利分校AMP实验室(Algorithm ...
随机推荐
- SkyWalking 6.x 的架构图
可以看到主要由四部分组成: Agent(也叫Probe):代理或者探针,集成在被监测的应用中(SDK形式或者动态注入),采集应用的数据发送给后端(OAP). UI:自带的Web页面. OAP:后端,接 ...
- Elasticsearch:Split index API - 把一个大的索引分拆成更多分片
文章转载自:https://blog.csdn.net/UbuntuTouch/article/details/108960950
- PAT (Basic Level) Practice 1004 成绩排名 分数 20
读入 n(>0)名学生的姓名.学号.成绩,分别输出成绩最高和成绩最低学生的姓名和学号. 输入格式: 每个测试输入包含 1 个测试用例,格式为 第 1 行:正整数 n 第 2 行:第 1 个学生的 ...
- 如何优雅的备份MySQL数据?看这篇文章就够了
大家好,我是一灯,今天一块学习一下如何优雅安全的备份MySQL数据? 1. 为什么要备份数据 先说一下为什么需要备份MySQL数据? 一句话总结就是:为了保证数据的安全性. 如果我们把数据只存储在一个 ...
- numba jit加速python程序
numba numba加速循环.numpy的一些运算,大概是将python和numpy的一些代码转化为机器代码,速度飞快! 加速耗时很长的循环时: from numba import jit # 在函 ...
- springboot+thymeleaf+bootstrap 超级无敌简洁的页面展示 商城管理页面
页面效果: <!DOCTYPE html> <html lang="en" xmlns:th="http://www.thymeleaf.org&quo ...
- python字符串的一些操作
# 1.变量的多次赋值 print('1.变量的多次赋值') name = '小明' # 没有意义的 name = '小刚' # 对前面创建的变量名称进行覆盖 # 删除原来的数据,写入新的数据 pri ...
- Python基础之函数:1、函数的介绍及名称空间
目录 一.函数 1.什么是函数 2.函数的语法结构 3.函数的定义与调用 4.函数的分类 5.函数的返回值 6.函数的参数 二.函数参数 1.位置参数 2.默认参数 3.可变长参数 1.一个*号 2. ...
- Docker基础和常用命令
Docker基础和常用命令 一,Docker 简介 1.1,什么是 Docker Docker 使用 Google 公司推出的 Go 语言 进行开发实现,基于 Linux 内核的 cgroup,nam ...
- Oracle pfile与spfile文件参数(转载)
一.pfile与spfile Oracle中的参数文件是一个包含一系列参数以及参数对应值的操作系统文件.它们是在数据库实例启动时候加载的,决定了数据库的物理 结构.内存.数据库的限制及系统大量的默认值 ...