【实习项目介绍】XXXXX大数据平台介绍
一、技术架构
1、整体介绍及架构
(1)概述
Odeon大数据平台以全图形化Web操作的形式为用户提供一站式的大数据能力:包括数据采集、任务编排、调度及处理、数据展现(BI)等;同时提供完善的权限管理、日志追踪、集群监控等能力
自己描述:一个PAAS平台即服务,全图形web操作构建数据闭环,实现多源数据导入、导出及分析、多源SQL数据查询、元数据和日志管理、工作流调度、快速部署
简述:数据采集(结构数据和日志数据sqoop)、数据开发(oozie工作流调度&仪表盘监控、HBASE使用Phoenix查询)、数据分析(OLAP基于kylin查询,支持kafka、hdfs等多数据源,可以整合BI工具)、数据编程(HUE使用统一的8888端口管理)
(2)组成
Odeon大数据平台主要由以下几部分组成:
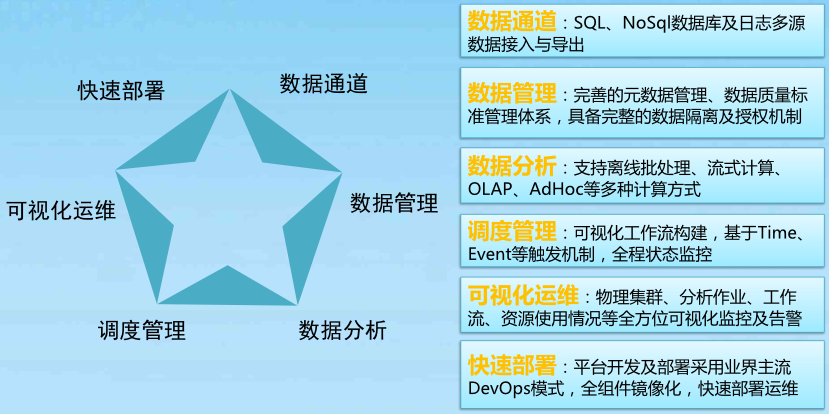
多源头数据通道:SQL、NoSql数据库及日志多源数据接入与导出
元数据和日志数据管理:元数据管理、数据质量标准管理体系,以及完整的数据隔离及授权机制
多源头数据分析:支持离线批处理、流式计算、OLAP、AdHoc等多种计算方式
SQL数据查询服务:基于Greenplum和Kylin的数据服务架构,提供DaaS服务
工作流调度管理与状态监控:可视化工作流构建,基于Time、Event等触发机制,全程状态监控
可视化运维:物理集群、分析作业、工作流、资源使用情况等全方位可视化监控及告警
快速部署:DevOps模式,全组件镜像化,实现快速部署运维
(3)架构图
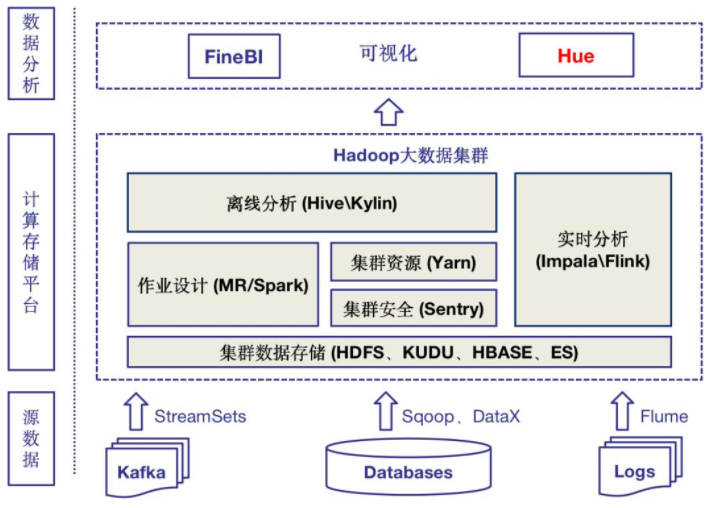
2、使用技术
(1)大数据:Hadoop、Spark、HBASE、Hive
(2)中间件:Kylin、k8s、Druid、Oozie、Impala
二、实现功能
1、功能分类
(1)数据查询:可以对Hive、Spark、Impala进行数据查询,实现编写SQL实现,并打印执行日志
(2)数据开发/仪表盘:可以查看各任务的执行状态
(3)日志数据通道:通过web实现增删改查topic等信息
(4)资源集市:配置业务表,实现资源集市,为用户分配项目、资源
(5)业务运维与告警:查看集群状况、任务数量,并能够添加告警
2、具体细节
0987
三、实际使用
1、kafka的QPS、TPS吞吐量及并发量
(1)吞吐量(Throughput)
系统在单位时间内处理请求的数量、上传下载流量
(2)QPS每秒查询率(Query Per Second)
对应fetches/sec,即每秒的响应请求数,也即是最大吞吐能力。
一天有10万pv(访问量),
公式 (100000 * 80%) / (86400*20%) = 4.62 QPS(峰值时间的每秒请求)
(3)并发量
并发用户数是指系统可以同时承载的正常使用系统功能的用户的数量。
(4)指标值
吞吐量:60-70M/s
qps查询率:10以内/s
并发量:峰值1-2w条数据/s
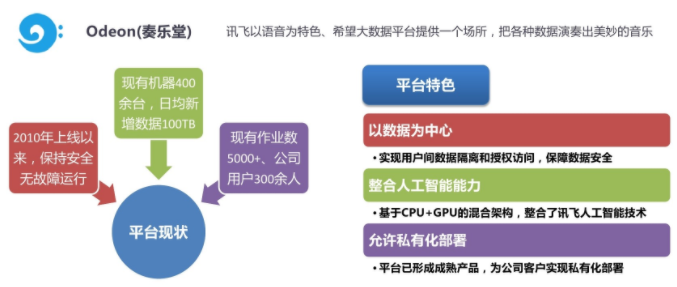
2、占用多大空间
每日新增数据100TB,共有400多台机器
四、完成工作
234
五、项目资料和截图
567
【实习项目介绍】XXXXX大数据平台介绍的更多相关文章
- GreenPlum 大数据平台--介绍
一,GreenPlum 01,介绍: Greenplum是一种基于PostgreSQL的分布式数据库,其采用shared-nothing架构,主机.操作系统.内存.存储都是自我控制的,不存在共享. 官 ...
- Apache Kylin在4399大数据平台的应用
来自:AI前线(微信号:ai-front),作者:林兴财,编辑:Natalie作者介绍:林兴财,毕业于厦门大学计算机科学与技术专业.有多年的嵌入式开发.系统运维经验,现就职于四三九九网络股份有限公司, ...
- 百亿级别数据量,又需要秒级响应的案例,需要什么系统支持呢?下面介绍下大数据实时分析工具Yonghong Z-Suite
Yonghong Z-Suite 除了提供优秀的前端BI工具之外,Yonghong Z-Suite让用户可以选购分布式数据集市来支持实时大数据分析. 对于这种百亿级的大数据案例,Yonghong Z- ...
- Spark大型项目实战:电商用户行为分析大数据平台
本项目主要讲解了一套应用于互联网电商企业中,使用Java.Spark等技术开发的大数据统计分析平台,对电商网站的各种用户行为(访问行为.页面跳转行为.购物行为.广告点击行为等)进行复杂的分析.用统计分 ...
- MaxCompute 最新特性介绍 | 2019大数据技术公开课第三季
摘要:距离上一次MaxCompute新功能的线上发布已经过去了大约一个季度的时间,而在这一段时间里,MaxCompute不断地在增加新的功能和特性,比如参数化视图.UDF支持动态参数.支持分区裁剪.生 ...
- 时间序列大数据平台建设(Time Series Data,简称TSD)
来源:https://blog.csdn.net/bluishglc/article/details/79277455 引言在大数据的生态系统里,时间序列数据(Time Series Data,简称T ...
- 【定义及安装】Ambari——大数据平台的搭建利器
Ambari 是什么 Ambari 跟 Hadoop 等开源软件一样,也是 Apache Software Foundation 中的一个项目,并且是顶级项目.目前最新的发布版本是 2.0.1,未来不 ...
- 电竞大数据平台 FunData 的系统架构演进
电竞大数据时代,数据对比赛的观赏性和专业性都起到了至关重要的作用.同样的,这也对电竞数据的丰富性与实时性提出了越来越高的要求. 电竞数据的丰富性从受众角度来看,可分为赛事.战队和玩家数据:从游戏角 ...
- 携程实时大数据平台演进:1/3 Storm应用已迁到JStorm
携程大数据平台负责人张翼分享携程的实时大数据平台的迭代,按照时间线介绍采用的技术以及踩过的坑.携程最初基于稳定和成熟度选择了Storm+Kafka,解决了数据共享.资源控制.监控告警.依赖管理等问题之 ...
- 基于Ambari构建自己的大数据平台产品
目前市场上常见的企业级大数据平台型的产品主流的有两个,一个是Cloudera公司推出的CDH,一个是Hortonworks公司推出的一套HDP,其中HDP是以开源的Ambari作为一个管理监控工具,C ...
随机推荐
- 9. Fluentd部署:日志
Fluentd是用来处理其他系统产生的日志的,它本身也会产生一些运行时日志.Fluentd包含两个日志层:全局日志和插件级日志.每个层次的日志都可以进行单独配置. 日志级别 Fluentd的日志包含6 ...
- C++自学笔记 构造与析构;
构造与析构 类不是实体:对象属于类:函数属于类 : 用不同的对象调用同一个类里面的函数的时候,函数知道是哪一个对象在调用它 关键字 this this是一个指针 Point a; a.print(); ...
- Application保存作用域
Application保存作用域,作用范围:一次应用程序范围有效.Application属性范围值,只要设置一次,则所有的网页窗口都可以取得数据. ServletContext在服务器启动时创建,在服 ...
- CompareTest
一.说明:Java中的对象,正常情况下,只能进行比较:== 或 != .不能使用 > 或 < 的 但是在开发场景中,我们需要对多个对象进行排序,言外之意,就需要比较对象的大小. 如何实现? ...
- super关键字的使用
1.super理解为:父类的 2.super可以用来调用:属性.方法.构造器 3.super的使用:调用属性和方法 3.1 我们可以在子类的方法或构造器中.通过使用"super.属性&quo ...
- 前端无法渲染CSS文件
问题描述: 启动前端后,发现前端的页面渲染不符合预期,看情况应该是css文件没有生效. 排查步骤: 查看有无报错信息. 查看后台输出,没有可用的提示信息,如图: 确认 css 的路径没错. 前端打包后 ...
- 1.轮询、长轮询、websocket简介
一.轮询 前端每隔固定时间向后台发送一次请求,询问服务器是否有新数据 缺点: 延迟,需要固定的轮询时间,不一定是实时数据 大量耗费服务器内存和宽带资源,因为不停的请求服务器,很多时候 并没有新的数 ...
- 【神经网络】丢弃法(dropout)
丢弃法是一种降低过拟合的方法,具体过程是在神经网络传播的过程中,随机"沉默"一些节点.这个行为让模型过度贴合训练集的难度更高. 添加丢弃层后,训练速度明显上升,在同样的轮数下测试集 ...
- [苹果APP上架]ios App Store上架详细教程-一条龙顺滑上架-适合小白
如何在 2022 年将您的应用提交到 App Store 您正在启动您的第一个应用程序,或者距离上次已经有一段时间了.作者纸飞机@cheng716051来给你讲讲将应用程序提交到 App Store ...
- ABAP 调用HTTP上传附件
1.需求说明 在SAP中调用第三方文件服务器的HTTP请求,将文件保存在文件服务器上,并返回保存的文件地址.SAP保存返回的文件地址,通过浏览器进行访问. 2.需求实现 2.1.POSTMAN测试 通 ...