Pytorch实战学习(四):加载数据集
《PyTorch深度学习实践》完结合集_哔哩哔哩_bilibili
Dataset & Dataloader
1、Dataset & Dataloader作用
※Dataset—加载数据集,用索引的方式取数
※DataLoader—Mini-Batch
通过获得DataSet的索引以及数据集大小,来自动得生成小批量训练集
DataLoader先对数据集进行Shuffle,再将数据集按照Batch_Size的长度划分为小的Batch,并按照Iterations进行加载,以方便通过循环对每个Batch进行操作
Shuffle=True:随机打乱顺序
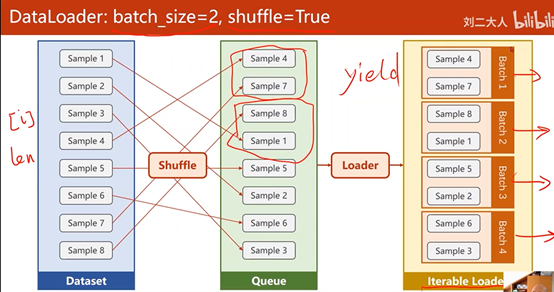
2、Mini-Batch:
利用Mini-Batch均衡训练性能和时间
在外层循环中,每一层是一个epoch(训练周期),在内层循环中,每一次是一个Mini-Batch(Batch的迭代)
for epoch in range(training_epochs):
for i in range(total_batch):
3、相关术语
※Epoch:所有样本都参与了一次训练
※Batch-size:进行一次训练(前馈、反馈、更新)的样本数
※Iteration:有多少个Batch,每次
Epoch = Batch-size * Iteration

4、代码部分
在构造数据集时,两种对数据加载到内存中的处理方式如下:
①加载所有数据到dataset,每次使用getitem()读索引,适用于数据量小的情况
②只对dataset进行初始化,仅存文件名到列表,每次使用时再通过索引到内存中去读取,适用于数据量大(图像、语音…)的情况
import torch
import numpy as np
## Dataset为抽象类,不能被实例化,只能被其他子类继承
from torch.utils.data import Dataset
## 实例化DataLoader,用于加载数据
from torch.utils.data import DataLoader ## Prepare Data
class DiabetesDataset(Dataset):
def __init__(self, filepath):
xy = np.loadtxt(filepath, delimiter=',', dtype=np.float32)
## 获取数据集长度
self.len = xy.shape[0]
self.x_data = torch.from_numpy(xy[:, :-1])
self.y_data = torch.from_numpy(xy[:, [-1]]) ## 索引:下标操作
def __getitem__(self, index):
return self.x_data[index], self.y_data[index] ## 返回数据量
def __len__(self):
return self.len dataset = DiabetesDataset('diabetes.csv.gz') ##num_workers多线程
train_loader = DataLoader(dataset = dataset,
batch_size = 32,
shuffle = True,
num_workers = 0) ##Design Model ##构造类,继承torch.nn.Module类
class Model(torch.nn.Module):
## 构造函数,初始化对象
def __init__(self):
##super调用父类
super(Model, self).__init__()
##构造三层神经网络
self.linear1 = torch.nn.Linear(8, 6)
self.linear2 = torch.nn.Linear(6, 4)
self.linear3 = torch.nn.Linear(4, 1)
##激活函数,进行非线性变换
self.sigmoid = torch.nn.Sigmoid() ## 构造函数,前馈运算
def forward(self, x):
x = self.sigmoid(self.linear1(x))
x = self.sigmoid(self.linear2(x))
x = self.sigmoid(self.linear3(x))
return x model = Model() ##Construct Loss and Optimizer ##损失函数,传入y和y_pred,size_average--是否取平均
criterion = torch.nn.BCELoss(size_average = True) ##优化器,model.parameters()找出模型所有的参数,Lr--学习率
optimizer = torch.optim.SGD(model.parameters(), lr=0.01) ## Training cycle
## windows环境下DataLoader的num_workers设置为多线程,需要将主程序(对数据操作的程序)封装到函数中
if __name__ =='__main__':
for epoch in range(100):
#enumerate:可获得当前迭代的次数
for i, data in enumerate(train_loader, 0):
## 准备数据
inputs, lables = data
##前向传播
y_pred = model(inputs)
loss = criterion(y_pred, lables)
print(epoch, i, loss.item()) ##梯度归零
optimizer.zero_grad()
##反向传播
loss.backward()
##更新
optimizer.step()
!!两个问题!!
①DataLoader的参数num_workers设置 >0
在windows中利用多线程读取,需要将主程序(对数据操作的程序)封装到函数中
## Training cycle
## windows环境下DataLoader的num_workers设置为多线程,需要将主程序(对数据操作的程序)封装到函数中
if __name__ =='__main__':
for epoch in range(100):
#enumerate:可获得当前迭代的次数
for i, data in enumerate(train_loader, 0):
但是运行还是报错,只能把num_workers = 0
②运行结果:损失不会一直下降,改小了学习率也不行
Pytorch实战学习(四):加载数据集的更多相关文章
- pytorch 加载数据集
pytorch初学者,想加载自己的数据,了解了一下数据类型.维度等信息,方便以后加载其他数据. 1 torchvision.transforms实现数据预处理 transforms.Totensor( ...
- PyTorch保存模型与加载模型+Finetune预训练模型使用
Pytorch 保存模型与加载模型 PyTorch之保存加载模型 参数初始化参 数的初始化其实就是对参数赋值.而我们需要学习的参数其实都是Variable,它其实是对Tensor的封装,同时提供了da ...
- [源码解析] PyTorch 分布式(1) --- 数据加载之DistributedSampler
[源码解析] PyTorch 分布式(1) --- 数据加载之DistributedSampler 目录 [源码解析] PyTorch 分布式(1) --- 数据加载之DistributedSampl ...
- [源码解析] PyTorch 分布式(2) --- 数据加载之DataLoader
[源码解析] PyTorch 分布式(2) --- 数据加载之DataLoader 目录 [源码解析] PyTorch 分布式(2) --- 数据加载之DataLoader 0x00 摘要 0x01 ...
- cesium 学习(五) 加载场景模型
cesium 学习(五) 加载场景模型 一.前言 现在开始实际的看看效果,目前我所接触到基本上都是使用Cesium加载模型这个内容,以及在模型上进行操作.So,现在进行一些加载模型的学习,数据的话可以 ...
- SciKit-Learn 加载数据集
章节 SciKit-Learn 加载数据集 SciKit-Learn 数据集基本信息 SciKit-Learn 使用matplotlib可视化数据 SciKit-Learn 可视化数据:主成分分析(P ...
- 【 js 模块加载 】深入学习模块化加载(node.js 模块源码)
一.模块规范 说到模块化加载,就不得先说一说模块规范.模块规范是用来约束每个模块,让其必须按照一定的格式编写.AMD,CMD,CommonJS 是目前最常用的三种模块化书写规范. 1.AMD(Asy ...
- 【 js 模块加载 】【源码学习】深入学习模块化加载(node.js 模块源码)
文章提纲: 第一部分:介绍模块规范及之间区别 第二部分:以 node.js 实现模块化规范 源码,深入学习. 一.模块规范 说到模块化加载,就不得先说一说模块规范.模块规范是用来约束每个模块,让其必须 ...
- WebGL three.js学习笔记 加载外部模型以及Tween.js动画
WebGL three.js学习笔记 加载外部模型以及Tween.js动画 本文的程序实现了加载外部stl格式的模型,以及学习了如何把加载的模型变为一个粒子系统,并使用Tween.js对该粒子系统进行 ...
- Springboot学习01- 配置文件加载优先顺序和本地配置加载
Springboot学习01-配置文件加载优先顺序和本地配置加载 1-项目内部配置文件加载优先顺序 spring boot 启动会扫描以下位置的application.properties或者appl ...
随机推荐
- Springboot返回数据给前端-参数为null处理
转:https://www.pianshen.com/article/950119559/ 1.返回对象参数为null时,该参数选择显示或者不显示 在返回参数给前端的时候,有些参数的值为null的时候 ...
- mysql03-默认的几个数据库
https://blog.csdn.net/dj673344908/article/details/80482844 1.查看mysql默认的数据库 在安装好mysql后,登录mysql,执行语句:s ...
- 推荐一款新的自动化测试框架:DrissionPage!
今天给大家推荐一款基于Python的网页自动化工具:DrissionPage.这款工具既能控制浏览器,也能收发数据包,甚至能把两者合而为一,简单来说:集合了WEB浏览器自动化的便利性和 request ...
- C# HttpClient使用和注意事项,.NET Framework连接池并发限制
System.Net.Http.HttpClient 类用于发送 HTTP 请求以及从 URI 所标识的资源接收 HTTP 响应. HttpClient 实例是应用于该实例执行的所有请求的设置集合,每 ...
- Ubuntu20.04桌面系统快速上手教程
转载csdn:ChunKai93 https://blog.csdn.net/iamzhoujunjia/article/details/105349441
- php pdo如何查询记录条数
转载php中文网:https://www.php.cn/php-ask-457710.html php pdo查询记录条数的方法:1.使用fetchAll函数查询,其语法如"$rows=$q ...
- VSCode 自定义代码片段
Ctrl+Shift+P 输入"代码片段:配置用户代码片段": 搜索你想要设置的语言代码片段,比如,我设置 .vue 文件的代码片段,选择 vue.json: 可以配置多个代码片段 ...
- torch.nn.Embedding使用详解
torch.nn.Embedding: 随机初始化词向量,词向量值在正态分布N(0,1)中随机取值.输入:torch.nn.Embedding(num_embeddings, – 词典的大小尺寸,比如 ...
- k8s-分布式系统架构master-worker
K8S系列一:概念入门 - 知乎 (zhihu.com) 大白话先了解k8s. k8s是为容器服务而生的一个可移植容器的编排管理工具 概述 Master-Workers 架构(粗译为主从架构)是分布式 ...
- Vulnhub:recon靶机
kali:192.168.111.111 靶机:192.168.111.188 信息收集 端口扫描 nmap -A -v -sV -T5 -p- --script=http-enum 192.168. ...