java进阶篇——Stream流编程
Stream流
函数式接口
1.消费型接口——Consumer
@FunctionalInterface
public interface Consumer<T> {
/**
* 对给定的参数执行此操作。
*
* @param t 输入参数
*/
void accept(T t);
/**
* 返回一个组合的Consumer , Consumer执行该操作,后跟after操作。 如果执行任一操作会抛出异常,
* 它将被转发到组合操作的调用者。 如果执行此操作抛出一个异常, after操作将不被执行。
*
* @param after 此操作后执行的操作
* @return 一个组合的 Consumer按顺序执行该操作,后跟 after操作
* @throws NullPointerException if {@code after} is null
*/
default Consumer<T> andThen(Consumer<? super T> after) {
Objects.requireNonNull(after);
return (T t) -> { accept(t); after.accept(t); };
}
}
2.供给型接口——Supplier
@FunctionalInterface
public interface Supplier<T> {
/**
* 获取一个结果
*
* @return 返回一个结果
*/
T get();
}
3.函数型接口——Function
@FunctionalInterface
public interface Function<T, R> {
/**
* 将此函数应用于给定的参数。
*
* @param t 函数参数
* @return 功能结果
*/
R apply(T t);
/**
* 返回一个组合函数,首先将before函数应用于其输入,然后将此函数应用于结果。
* 如果任一函数的评估引发异常,则将其转发给组合函数的调用者。
*
* @param <V> 输入到 before函数的类型,并且组合函数
* @param before 应用此功能之前应用的功能
* @return 一个组合函数首先应用 before函数,然后应用此功能异常
* @throws NullPointerException if before is null
*
* @see #andThen(Function)
*/
default <V> Function<V, R> compose(Function<? super V, ? extends T> before) {
Objects.requireNonNull(before);
return (V v) -> apply(before.apply(v));
}
/**
* 返回一个组合函数,首先将此函数应用于其输入,然后将after函数应用于结果。
* 如果任一函数的评估引发异常,则将其转发给组合函数的调用者。
*
* @param <V> after功能的输出类型,以及组合功能
* @param 应用此函数后应用的功能
* @return 一个组合函数首先应用此函数,然后应用 after函数
* @throws NullPointerException if after is null
*
* @see #compose(Function)
*/
default <V> Function<T, V> andThen(Function<? super R, ? extends V> after) {
Objects.requireNonNull(after);
return (T t) -> after.apply(apply(t));
}
/**
* 返回一个总是返回其输入参数的函数。
*
* @param <T> 函数的输入和输出对象的类型
* @return 一个总是返回其输入参数的函数
*/
static <T> Function<T, T> identity() {
return t -> t;
}
}
4.断言型接口——Predicate
@FunctionalInterface
public interface Predicate<T> {
/**
* 在给定的参数上评估这个谓词。
*
* @param t 输入参数
* @return true如果输入参数匹配该谓词,否则为 false
* otherwise {@code false}
*/
boolean test(T t);
/**
* 返回一个组合的谓词,表示该谓词与另一个谓词的短路逻辑AND。
* 当评估组合谓词时,如果此谓词为false ,则不other other谓词。
* 在评估任一谓词期间抛出的任何异常被中继到调用者;
* 如果此断言的评价抛出一个异常, other断言不会被评估。
*
* @param other 将与此谓词进行逻辑与AND的谓词
* @return 一个代表该谓词和other谓词的短路逻辑AND的 other谓词
* AND of this predicate and the {@code other} predicate
* @throws NullPointerException if other is null
*/
default Predicate<T> and(Predicate<? super T> other) {
Objects.requireNonNull(other);
return (t) -> test(t) && other.test(t);
}
/**
* 返回表示此谓词的逻辑否定的谓词。
*
* 一个表示该谓词的逻辑否定的谓词
*/
default Predicate<T> negate() {
return (t) -> !test(t);
}
/**
* 返回一个组合的谓词,表示该谓词与另一个谓词的短路逻辑或。
* 当评估组合谓词时,如果此谓词为true ,则不other other谓词。
* 在评估任一谓词期间抛出的任何异常被中继到调用者;
* 如果此断言的评价抛出一个异常, other断言不会被评估。
*
* @param other 将与此谓词进行逻辑关系的谓词
* @return 表示短路逻辑这个谓词的或组成谓词和 other谓词
* @throws NullPointerException if other is null
*/
default Predicate<T> or(Predicate<? super T> other) {
Objects.requireNonNull(other);
return (t) -> test(t) || other.test(t);
}
/**
* 返回测试,如果两个参数按照相等谓词 Objects.equals(Object, Object) 。
*
* @param <T> T的参数类型
* @param 用于比较相等的对象引用,可能是 null
* @return 根据 Objects.equals(Object, Object)测试两个参数是否相等的 谓词
*/
static <T> Predicate<T> isEqual(Object targetRef) {
return (null == targetRef)
? Objects::isNull
: object -> targetRef.equals(object);
}
}
Stream流
1.创建流
集合创建
List<User> list = getList();
//直接使用集合的stream方法获取stream流
Stream<User> stream = list.stream();
数组创建
int[] array = {1,2,3,4,5,6};
//使用数组工具类的stream方法转化
IntStream stream1 = Arrays.stream(array);
//使用Stream接口的of方法转换
Stream<int[]> stream2 = Stream.of(array);
2.流中间操作
filter
filter中传入了一个参数——断言型接口,意味着实际调用中可以使用匿名内部类(lanbda)的方式将过滤的实现细节定义出来。
/**
* 返回由与此给定谓词匹配的此流的元素组成的流。
*
* 这是一个intermediate operation 。
*
* @param predicate 一个 non-interfering , stateless谓词应用到每个元素,以确定是否它应包含
* @return 新的流
*/
Stream<T> filter(Predicate<? super T> predicate);
应用:
//筛选年龄大于20的用户
stream.filter(new Predicate<User>() {
@Override
public boolean test(User user) {
return user.getAge() > 20;
}
});
//lambda使用,后续一律使用lambda表达式举例
//筛选用户姓名为小黑子的用户
stream.filter(user->user.getName().equals("小黑子"));
map
map中传入一个函数型接口,旨在将T类型的对象转换为R型的对象。在实际使用中定义具体转化细节,可以是属性提取、类型转换或者计算逻辑等。在lambda表达式中,参数R可省略,在返回值中体现即可。
/**
* 返回由给定函数应用于此流的元素的结果组成的流。
*
* 这是一个intermediate operation 。
*
* @param <R> 新流的元素类型
* @param mapper 一个 non-interfering , stateless函数应用到每个元件
* @return 新的流
*/
<R> Stream<R> map(Function<? super T, ? extends R> mapper);
应用:
//返回每个对象中的用户名
stream.map(user -> user.getName());
//对于一些纯功能性的定义,比如输出、get方法,可以进一步省略
stream.map(User::getName);
//批量将数字转化为字符串
stream.map(num -> String.valueOf(num));
distinct
流元素去重
distinct依赖Object中的equals方法,如果需要自定义判重逻辑,需要重写equals方法
/**
* 返回由该流的不同元素(根据Object.equals(Object) )组成的流。
* 对于有序流,选择不同的元素是稳定的(对于重复的元素
* 首先在遇到顺序中出现的元素被保留。)
* 对于无序流,不能保证稳定性。 * 这是一个stateful intermediate operation 。
*
* @apiNote
* 保存稳定性为distinct()在并行管线是相对昂贵的
* (要求操作充当一个完整屏障,具有大量缓冲的开销),并且稳定性通常是不需要的。
* 使用无序流源(如generate(Supplier) )或具有除去排序约束
* BaseStream.unordered()可相比distinct()更加更高效,如果语法允许的话
* 如果需要与遇到顺序一致, distinct()在并行流水线中使用distinct()您的性能或内存利用率不佳,
* 则使用BaseStream.sequential()切换到顺序执行可能会提高性能。
*
* @return the new stream
*/
Stream<T> distinct();
sorted
对流元素进行排序
流元素如果为复杂类型,需要实现comparable接口重写compareTo方法或者传入一个comparable匿名内部类重写compareTo方法。
/**
* 返回由此流的元素组成的流,根据自然顺序排序。
* 如果该流的元件不是Comparable ,一个java.lang.ClassCastException执行终端操作时,可以抛出。
* 对于有序流,排序稳定。 对于无序的流,不能保证稳定性。
* 这是一个stateful intermediate operation 。
*
* @return 新的流
*/
Stream<T> sorted();
/**
* @param comparator 一个 non-interfering,stateless Comparator被用于比较流元素
* @return the new stream
*/
Stream<T> sorted(Comparator<? super T> comparator);
使用:
//实现Comparable接口
public class User implements Comparable{
...
@Override
public int compareTo(Object o) {
//比较逻辑
}
}
//传入Comparable参数
stream.sorted((o1, o2) -> {//判断逻辑
});
limit
限制输出流元素个数,超出limit的元素将会被抛弃。
/**
* 返回由该流的元素组成的流,截断长度不能超过maxSize 。
* 这是一个short-circuiting stateful intermediate operation 。
*
* @apiNote
* 虽然limit()通常是在连续的流管道的廉价的操作,它可是并行管道中相当昂贵的,
* 特别是对于大的值maxSize ,由于limit(n)被约束返回不是任何n个元素,但在遭遇顺序中的第n个元素。
* 使用无序流源(如generate(Supplier) )或去除所述排序约束与BaseStream.unordered()
* 可相比limit()在并行管道获得显著加速,如果语法允许的话。
* 如果需要与遇到顺序一致, limit()在并行流水线中遇到limit()的性能下降或内存利用率下降,
* 则使用BaseStream.sequential()切换到顺序执行可能会提高性能。
*
* @param maxSize 流应该限制的元素数量
* @return 新的流
* @throws IllegalArgumentException 如果 maxSize为负数
*/
Stream<T> limit(long maxSize);
使用:
//限制最大长度为2
stream.limit(2);
skip
跳过前n个元素,通常是在排序后使用
使用:
//打印除了年龄最大用户之外的其他用户
stream.sorted()
.skip(1)
flatMap
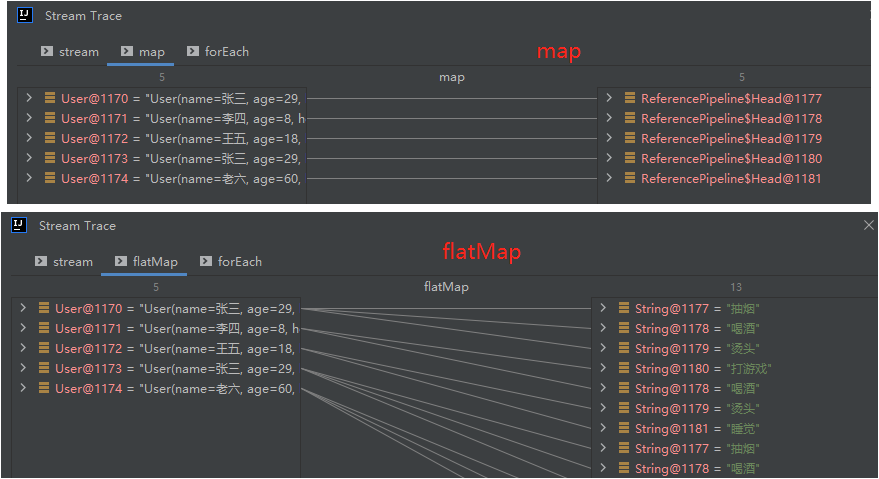
相比map方法,flatMap可以将一个元素转化为多个流中的元素。比如需要从一个用户列表中获取到用户的爱好列表。map取出来的是一个List元素的stream流。如果需要取出以爱好对象为元素的stream流,就可以使用flatMap。
/**
* 返回由通过将提供的映射函数应用于每个元素而产生的映射流的内容来替换该流的每个元素的结果的流。
* 每个映射的流在其内容被放入此流之后是closed 。 (如果映射的流是null则使用空的流)。
*
* 这是一个intermediate operation 。
*
* @apiNote
* flatMap()操作具有对流的元素应用一对多变换,然后将所得到的元素平坦化为新流的效果。
*/
<R> Stream<R> flatMap(Function<? super T, ? extends Stream<? extends R>> mapper);
可以发现,flatMap和map很像,所以map理论上也可以实现flatMap一对多的效果。
stream.map(user -> user.getHobby().stream());
stream.flatMap(user -> user.getHobby().stream());
实际上是这样吗,不是的,我们通过调试可以发现,map返回的是stream的嵌套流,而flatMap返回的是hobby对象流
也就是说,flatMap帮我们自动做了流拼接,在实际使用中需要注意区分使用场景。
3.流终结操作
forEach
遍历一些属性,输出打印或者操作计算等。
/**
* 对此流的每个元素执行操作。
*
* 这是一个终端操作 。
*
* 这个操作的行为显然是不确定的。 对于并行流管道,此操作不保证遵守流的遇到顺序,因为这样做将牺牲并行性的好处。
* 对于任何给定的元素,动作可以在图书馆选择的任何时间和任何线索中执行。 如果操作访问共享状态,则负责提供所需的同步。
*
* @param action 一个对元素执行的无干扰的动作
*/
void forEach(Consumer<? super T> action);
使用:
//遍历输出流元素
stream.forEach(System.out::println);
stream.forEach(user -> System.out.println(user.getName()));
count
流元素个数求值,返回流元素的个数,以long类型返回。
/**
* 返回此流中的元素数。
*
* 这是一个终端操作
*
* @return 这个流中元素的数量
*/
long count();
long count = stream.count();
max&min
求流元素中的最大(最小)值,以最大值为例。
/**
* 根据提供的Comparator返回此流的最大元素。
*
* 这是一个终端操作
*
* @param comparator 一个无干扰、无状态的操作,Comparator用来比较该流的元素
*
* @return 一个 Optional用来描述此流的最大元素,如果流为空, Optional为空
* @throws NullPointerException 如果最大元素为空
*/
Optional<T> max(Comparator<? super T> comparator);
使用方法和sorted比较像,流元素实现比较接口或者向max方法传入一个匿名内部类。需要注意的是,方法返回值并不是一个对象,而是一个带泛型的Optional对象,需要使用Optional的get方法才能获取到结果。
collect
将结果转化为集合。
转化为list集合
List<User> list = stream.collect(Collectors.toList());
转化为set集合
Set<User> set = stream.collect(Collectors.toSet());
转化为map集合
Set<User> set = stream.collect(Collectors.toMap());
//toMap方法传入了两个function参数,一个用来转化key值一个转化value值
public static <T, K, U>
Collector<T, ?, Map<K,U>> toMap(Function<? super T, ? extends K> keyMapper,
Function<? super T, ? extends U> valueMapper) {
return toMap(keyMapper, valueMapper, throwingMerger(), HashMap::new);
}
使用:
stream.collect(Collectors.toMap(user -> user.getName(),user -> user.getHobby()));
anyMatch
anyMatch传入一个匹配逻辑进行匹配,相比filter的匹配结果,anyMatch作为一个终结操作,他的匹配结果是一个bool类型。true代表匹配成功,false代表匹配失败。
anymatch是一个短路操作,意味着只要一个元素匹配成功则直接返回true,不进行后面的匹配。
/**
* 返回此流的任何元素是否与提供的谓词匹配。
* 如果不需要确定结果,则不能评估所有元素上的谓词。
* 如果流为空,则false返回和谓语不评估。
*
* 这是一个短路的终端操作
*
* @apiNote
* 该方法评估了流的元素(对于某些x P(x))的 谓词的存在量化。
*
* @param predicate 一个 non-interfering , stateless谓词适用于该流的元素
* @return true如果流的任何元素匹配提供的谓词,否则为 false
*/
boolean anyMatch(Predicate<? super T> predicate);
使用:
boolean b = stream.anyMatch(user -> user.getAge() > 50);
allMatch
相比anyMatch,该方法必须所有流元素都匹配成功才会返回true。
allMatch同样为一个短路操作,即只要有一条元素匹配失败,则返回false。
noneMatch
相比allMatch,该方法必须所有流元素都匹配不成功才会返回true。
allMatch同样为一个短路操作,即只要有一条元素匹配成功,则返回false。
findAny
获取任意的一个元素(不保证是第一个元素),返回的同样为optional对象,由于存在不存在都会返回该对象,所以需要先进行存在判断,而后通过getValue获取到结果。
可以搭配filter组合为条件匹配获取
findFirst
获取到流元素中第一个元素。可以搭配sorted取最值或者通过filter条件匹配查询。和findAny返回值类似,需要判断存在性。
reduce
reduce方法定义了对元素流的聚合操作。最简单的形式通过一个BinaryOperator accumulator接口来定义聚合方案。
/**
* 使用associative累积函数对此流的元素执行reduction ,
* 并返回描述减小值(如果有的话)的Optional 。
* 类似于
*/
* boolean foundAny = false;
* T result = null;
* for (T element : this stream) {
* if (!foundAny) {
* foundAny = true;
* result = element;
* }
* else
* result = accumulator.apply(result, element);
* }
* return foundAny ? Optional.of(result) : Optional.empty();
/*
* 但不限于顺序执行。
* accumulator功能必须是结合性功能。
*
* 这是一个终端操作
*
* @param accumulator 一个结合性的、无干扰的、无状态的功能接口
* @return 一个Optional描述了聚合的结果
* @throws NullPointerException 如果减少的结果为空
*/
Optional<T> reduce(BinaryOperator<T> accumulator);
使用:
Optional<User> user = stream.reduce(new BinaryOperator<User>() {
//user为初始值,默认为第一个流元素,他将作为一个结果循环地和其他元素交互
@Override
public User apply(User user, User user2) {
user.setAge(user.getAge()+user2.getAge());
return user;
}
});
//reduce同样提供了一个参数供开发者去指定结果的初始值,但该初始值的类型要和流元素保持一致
User user = stream.reduce(new User("王五",18, Arrays.asList("烫头","睡觉")),new BinaryOperator<User>() {
@Override
public User apply(User user, User user2) {
user.setAge(user.getAge()+user2.getAge());
return user;
}
});
4.Optional
对一些有空指针隐患的结果获取进行包装。
optional对象的创建
//ofNullable()方法(底层进行了判空)
Optional<User> optional = Optional.ofNullable(new User());
//of方法(确定对象不为空)
Optional<User> optional = Optional.of(new User());
对象的消费
//通过一个消费接口进行消费,只有非空的对象才会执行逻辑
user.ifPresent(new Consumer<User>() {
@Override
public void accept(User user) {
...
}
});
//通过get方法直接获取包装的对象
User user2 = user.get();
//但是get方法获取到的值是有安全隐患的,optional提供了几种解决方案
//在对象为空时返回指定的默认值
user.orElseGet(new Supplier<User>() {
@Override
public User get() {
return new User();
}
});
//在对象为空时抛出指定的异常
user.orElseThrow(new Supplier<Throwable>() {
@Override
public Throwable get() {
return new RuntimeException();
}
});
java进阶篇——Stream流编程的更多相关文章
- Java 8创建Stream流的5种方法
不知不觉间,Java已经发展到13了,来不及感慨时间过得真的太快了,来不及学习日新月异的技术更新,目前大多数公司还是使用的JDK8版本,一方面是版本的稳定,另一方面是熟悉,所以很多公司都觉得不升级也挺 ...
- java中的Stream流
java中的Stream流 说到Stream便容易想到I/O Stream,而实际上,谁规定"流"就一定是"IO流"呢?在Java 8中,得益于Lambda所带 ...
- Java进阶篇之十五 ----- JDK1.8的Lambda、Stream和日期的使用详解(很详细)
前言 本篇主要讲述是Java中JDK1.8的一些新语法特性使用,主要是Lambda.Stream和LocalDate日期的一些使用讲解. Lambda Lambda介绍 Lambda 表达式(lamb ...
- Java进阶篇(六)——Swing程序设计(下)
三.布局管理器 Swing中,每个组件在容器中都有一个具体的位置和大小,在容器中摆放各自组件时很难判断其具体位置和大小,这里我们就要引入布局管理器了,它提供了基本的布局功能,可以有效的处理整个窗体的布 ...
- Java9系列第6篇-Stream流API的增强
我计划在后续的一段时间内,写一系列关于java 9的文章,虽然java 9 不像Java 8或者Java 11那样的核心java版本,但是还是有很多的特性值得关注.期待您能关注我,我将把java 9 ...
- Java进阶篇(六)——Swing程序设计(上)
Swing是GUI(图形用户界面)开发工具包,内容有很多,这里会分块编写,但在进阶篇中只编写Swing中的基本要素,包括容器.组件和布局等,更深入的内容会在高级篇中出现.想深入学习的朋友们可查阅有关资 ...
- Java进阶篇(一)——接口、继承与多态
前几篇是Java的入门篇,主要是了解一下Java语言的相关知识,从本篇开始是Java的进阶篇,这部分内容可以帮助大家用Java开发一些小型应用程序,或者一些小游戏等等. 本篇的主题是接口.继承与多态, ...
- Java进阶篇设计模式之六 ----- 组合模式和过滤器模式
前言 在上一篇中我们学习了结构型模式的外观模式和装饰器模式.本篇则来学习下组合模式和过滤器模式. 组合模式 简介 组合模式是用于把一组相似的对象当作一个单一的对象.组合模式依据树形结构来组合对象,用来 ...
- Java 8 (3) Stream 流 - 简介
什么是流? 流是Java API的新成员,它允许你以声明性方式处理数据集合(通过查询语言来表达,而不是临时编写一个实现).就现在来说你可以先把它当做是一个遍历数据集的高级迭代器.此外,流还支持并行,你 ...
随机推荐
- 16.MongoDB系列之分片管理
1. 查看当前状态 1.1 查看配置信息 mongos> use config // 查看分片 mongos> db.shards.find() { "_id" : & ...
- 齐博x1给表单某个字段设置初始值
自定义表单虽然后台可以设置默认初始值,但是有时候想在前台动态设置初始值的话,可以在URL中添加该字段名,给他动态赋值即可.比如下面的price字段就是动态赋值的.
- VS使用正则表达式删除程序中的空行
Ctrl+H; 需要替换的正则表达式 ^(?([^\r\n])\s)*\r?$\r?\n
- 转载:Python 实现百度翻译
来源: https://blog.csdn.net/qq_44814439/article/details/105642066 作者: Chloemxc 功能: Python 实现百度翻译 from ...
- Unity坐标系入门
一.坐标系的概念 Unity 世界坐标系采用左手坐标系,大拇指指向X轴(红色),食指指向Y轴(黄色),中指向手心方向歪曲90度表示Z轴(蓝色),同时Z轴也是物体前进方向,下图表示Unity的四种坐标系 ...
- python的一些运算符
# 1.算术运算符 print('1.算术运算符') # 1.1 + 求和 a = 10 b = 20 c = a + b print(c) print('a+b={}'.format(c)) pri ...
- windows10熄屏断网问题解决
以前用windowsserver的操作系统可以随时随地的远程,最近因工作需要安装了一个windows10的远程设备,发现windows10系统长时间未使用便连不上了,远程不了,ping不通,本地连接断 ...
- 云原生之旅 - 14)遵循 GitOps 实践的好工具 ArgoCD
前言 Argo CD 是一款基于 kubernetes 的声明式的Gitops 持续部署工具. 应用程序定义.配置和环境都是声明式的,并受版本控制 应用程序部署和生命周期管理都是自动化的.可审计的,并 ...
- vscode 更新后重启恢复旧版
vscode的自动更新自动安装在C:\Users\admin\AppData\Local\,如果之前的vscode不在默认位置,就会更新出两个版本,如果还用了固定在开始屏幕或者任务栏,则一直在打开旧版 ...
- 第1章-Spring的模块与应用场景
目录 一.Spring模块 1. 核心模块 2. AOP模块 3. 消息模块 4. 数据访问模块 5. Web模块 6. 测试模块 二.集成功能 1. 目标原则 2. 支持组件 三.应用场景 1. 典 ...