C++ struct结构体内存对齐
•小试牛刀
我们自定义两个结构体 A 和 B:
struct A
{
char c1;
char c2;
int i;
double d;
};
struct B
{
char c1;
int i;
char c2;
double d;
};通过定义我们可以看出,结构体 A 和 B 拥有相同的成员,只不过在排列顺序上有所不同;
众所周知,char 类型占 1 个字节,int 类型占 4 个字节,double 类型占 8 个字节;
那么,这两个结构体所占内存空间大小为多少呢?占用的空间是否相同?
空口无凭,让我们通过编译器告诉我们答案(我使用的是 VS2022,X86)。
在 main() 函数中输出如下语句:
int main()
{
printf("结构体A所占内存大小为:%d\n", sizeof(A));
printf("结构体B所占内存大小为:%d\n", sizeof(B)); return 0;
}运行之前,先盲猜一个结果:
sizeof(A) = sizeof(B) = sizeof(c1)+sizeof(c2)+sizeof(i)+sizeof(d) = 1+1+4+8 = 14
到底对不对呢?让我们来看看运行结果:
amazing~~
竟然一个都没猜对,这究竟是怎么回事呢?
下面开始进入今天的主题——struct 内存对齐。

•内存对齐
一种提高内存访问速度的策略,CPU 在访问未对齐的内存可能需要经过两次的内存访问,而经过内存对齐一次就可以了。
假定现在有一个 32 位处理器,那这个处理器一次性读取或写入都是四字节。
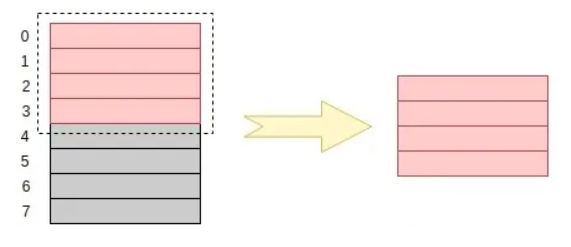
假设现在有一个 32 位处理器要读取一个 int 类型的变量,在内存对齐的情况下,处理器是这样进行读取的:
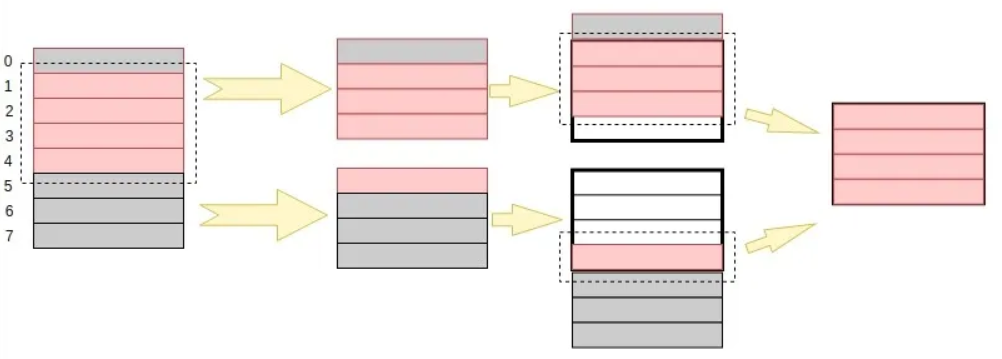
那如果数据存储没有按照内存对齐的方式进行的话,处理器就会这样进行读取:
对比内存对齐和内存没有对齐两种情况我们可以明显地看到,在内存对齐的情况下,取得这个 int型 变量只需要经过一次寻址(0~3);
但在内存没有对齐的情况下,取得这个 int型 变量需要经过两次的寻址(0~3 和 4~7),然后再合并数据。
通过上述的分析,我们可以知道内存对齐能够提升性能,这也是我们要进行内存对齐的原因之一。
•内存对齐的原则
- 对于结构体的各个成员,除了第一个成员的偏移量为 0 外,其余成员的偏移量是 其实际长度 的整数倍,如果不是,则在前一个成员后面补充字节。
- 结构体内所有数据成员各自内存对齐后,结构体本身还要进行一次内存对齐,保证整个结构体占用内存大小是结构体内最大数据成员的最小整数倍。
- 如程序中有 #pragma pack(n) 预编译指令,则所有成员对齐以 n字节 为准(即偏移量是n的整数倍),不再考虑当前类型以及最大结构体内类型。
下面通过样例来分享一下我的见解,为方便理解,声明如下:
- 定义的结构体包含 char , short , int , double类型各一个,并通过不同的组合构造出不同的结构体 Test01 , Test02 , Test03 , Test04
- 内存地址的编号设置为 0~24
- char 类型占1 个 字节,并用橙色填充
- short 类型占 2个 字节,并用黄色填充
- int 类型占 4个 字节,并用绿色填充
- double 类型占 8个 字节,并用蓝色填充
- 补充字节用黑色填充
Test01
struct Test01
{
char c;
short s;
int i;
double d;
}t1;内存分布情况:
- 第一个成员 c 的偏移量为 0,所以成员 c 的内存空间的首地址为 0
- 第二个成员 s 的内存空间的首地址为 2 号地址,偏移量为 2 - 0 = 2
- 第三个成员 i 的内存空间的首地址为 4 号地址,偏移量为 4 - 0 = 4
- 第三个成员 d 的内存空间的首地址为 8 号地址,偏移量为 8 - 0 = 8
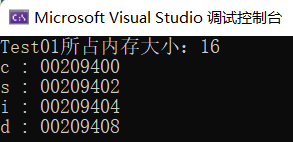
- Test01 所占内存大小为 16 个字节
让我们通过输出来验证一下:
void showTest01()
{
printf("Test01所占内存大小:%d\n",sizeof(Test01));
//并按照声明顺序输出 Test01 中的成员变量地址对应的十六进制
printf("%p\n", &t1.c);
printf("%p\n", &t1.s);
printf("%p\n", &t1.i);
printf("%p\n", &t1.d);
}输出结果:
我们将输出的十六进制地址转化为十进制:
00209400 -> 2135040
00209402 -> 2135042
00209404 -> 2135044
00209408 -> 2135048
- 以第一个成员 c 的起始地址为起点
- 第二个成员 s 的偏移量为 2
- 第三个成员 i 的偏移量为 4
- 第四个成员 d 的偏移量为 8
- 所占内存大小为 16
验证成功!
Test02
调换一下成员顺序,再次测试:
struct Test02
{
char c;
double d;
int i;
short s;
}t2;内存分布情况:
- 第一个成员 c 的偏移量为 0,所以成员 c 的内存空间的首地址为 0
- 第二个成员 d 的内存空间的首地址为 8 号地址,偏移量为 8 - 0 = 8(double 类型的整倍数)
- 第三个成员 i 的内存空间的首地址为 16 号地址,偏移量为 16 - 0 = 16(int 类型的整倍数)
- 第三个成员 s 的内存空间的首地址为 20 号地址,偏移量为 20 - 0 = 20(short 类型的整倍数)
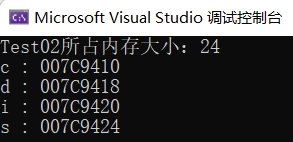
- Test02 所占内存大小为 24 个字节(结构体占用内存大小是结构体内最大数据成员 double 的最小整数倍:24 / 8 = 4)
接着通过输出来验证一下:
我们将输出的十六进制地址转化为十进制:
007C9410 -> 8164368
007C9418 -> 8164376
007C9420 -> 8164384
007C9424 -> 8164388
- 以第一个成员 c 的起始地址为起点
- 第二个成员 d 的偏移量为 8164376 - 8164368 = 8
- 第三个成员 i 的偏移量为 8164384 - 8164368 = 16
- 第四个成员 d 的偏移量为 8164388 - 8164368 = 20
- 所占内存大小为 24
验证成功!
Test03 & Test04
struct Test03
{
short s;
double d;
char c;
int i;
}t3;
struct Test04
{
double d;
char c;
int i;
short s;
}t4;内存分布情况:
可自行输出验证!!!



•总结
通过自行模拟,再回过头看看内存对齐的原则,是不是有种恍然大明白的感觉~
通过模拟上述不同情况,你会发现同种类型的成员变量通过不同的组合,所占用的总内存是不相同的;
那么,关于结构体内成员定义的顺序应该遵循这样一个原则:按照长度递增的顺序依次定义各个成员。
•声明
参考资料
C++ struct结构体内存对齐的更多相关文章
- C struct结构体内存对齐问题
在空间看到别人的疑问引起了我的兴趣,刚好是我感兴趣的话题,就写一下.为了别人的疑问,也发表在qq空间里.因为下班比较晚,10点才到家,发表的也晚.其实是个简单的问题. 直接用实例和内存图说明: #i ...
- 【APUE】Chapter17 Advanced IPC & sign extension & 结构体内存对齐
17.1 Introduction 这一章主要讲了UNIX Domain Sockets这样的进程间通讯方式,并列举了具体的几个例子. 17.2 UNIX Domain Sockets 这是一种特殊s ...
- 关于结构体内存对齐方式的总结(#pragma pack()和alignas())
最近闲来无事,翻阅msdn,在预编译指令中,翻阅到#pragma pack这个预处理指令,这个预处理指令为结构体内存对齐指令,偶然发现还有另外的内存对齐指令aligns(C++11),__declsp ...
- struct结构体内存大小
一. 基本原则 1. struct中成员变量的声明顺序,与成员变量对应的内存顺序是一致的: 2. struct本身的起始存储地址必须是成员变量中最长的数据类型的整倍数,注意是最长的数据类型,而不是最长 ...
- [C/C++] 结构体内存对齐用法
一.为什么要内存对齐 经过内存对齐之后,CPU的内存访问速度大大提升; 内存空间按照byte划分,从理论上讲似乎对任何类型的变量的访问可以从任何地址开始,但实际情况是在访问特定变量的时候经常在特定的内 ...
- [C/C++] 结构体内存对齐:alignas alignof pack
简述: alignas(x):指定结构体内某个成员的对齐字节数,指定的对齐字节数不能小于它原本的字节数,且为2^n; #pragma pack(x):指定结构体的对齐方式,只能缩小结构体的对齐数,且为 ...
- C语言-结构体内存对齐
C语言结构体对齐也是老生常谈的话题了.基本上是面试题的必考题.内容虽然很基础,但一不小心就会弄错.写出一个struct,然后sizeof,你会不会经常对结果感到奇怪?sizeof的结果往往都比你声明的 ...
- c 结构体内存对齐详解
0x00简介 首先要知道结构体的对齐规制 1.第一个成员在结构体变量偏移量为0的地址处 2.其他成员变量对齐到某个数字的整数倍的地址处 对齐数=编辑器默认的一个对齐数与该成员大小的较小值 vs中默认的 ...
- go语言结构体内存对齐
cpu要想从内存读取数据,需要通过地址总线,把地址传输给内存,内存准备好数据,输出到数据总线,交给cpu,如果地址总线只有8根,那这个地址就只有8位可以表示[0,255]256个地址,因为表示不了更多 ...
随机推荐
- logback1.3.x配置详解与实践
前提 当前(2022-02前后)日志框架logback的最新版本1.3.0已经更新到1.3.0-alpha14版本,此版本为非stable版本,相对于最新稳定版1.2.10来说,虽然slf4j-api ...
- 第2章 selenium开发环境的搭建
前端技术: html:网页的基础,一种标记语言,显示数据: JS:前端脚本语言,解释型语言,在页面中添加交互行为 xml:扩展标记语言,用来传输和存储数据 css:层叠样式表,用来表现HTML或XML ...
- find+grep+正则表达式
目录 find+grep+正则表达式 1.find 2.grep 3.正则表达式 find+grep+正则表达式 1.find 根据文件的名称或者属性查找文件. # 自己在 /root/adc目录下长 ...
- vc++调试总结
.在debug->windows下,有以下调试窗口 1)Breakpoints管理断点信息 可以新建条件断点,函数断点,以及特定地址改变断点(用于检测数据发生改变时机点) 在断点处,可以进入汇编 ...
- 【Kotlin】初识Kotlin(二)
[Kotlin]初识Kotlin(二) 1.Kotlin的流程控制 流程控制是一门语言中最重要的部分之一,从最经典的if...else...,到之后的switch,再到循环控制的for循环和while ...
- 解决UIWebView内存不释放问题
走访很多朋友,查阅了很多资料发现UIWebView这尼玛就是个坑,有人说是sdk自带的bug....... 所以一个新的方法诞生了#import <WebKit/WebKit.h> WKW ...
- 为什么三层架构中业务层(service)、持久层(dao)需要使用一个接口?
为什么三层架构中业务层(service).持久层(dao)需要使用一个接口? 如果没有接口那么我们在控制层使用业务层或业务层使用持久层时,必须要学习每个方法,若哪一天后者的方法名改变了则直接影响到前面 ...
- [SuperSocket2.0]SuperSocket 2.0从入门到懵逼
SuperSocket 2.0从入门到懵逼 SuperSocket 2.0从入门到懵逼 1 使用SuperSocket 2.0在AspNetCore项目中搭建一个Socket服务器 1.1 引入Sup ...
- 基于 Kafka 的实时数仓在搜索的实践应用
一.概述 Apache Kafka 发展至今,已经是一个很成熟的消息队列组件了,也是大数据生态圈中不可或缺的一员.Apache Kafka 社区非常的活跃,通过社区成员不断的贡献代码和迭代项目,使得 ...
- C#异步编程由浅入深(三)细说Awaiter
上一篇末尾提到了Awaiter这个类型,上一篇说了,能await的对象,必须包含GetAwaiter()方法,不清楚的朋友可以看上篇文章.那么,Awaiter到底有什么特别之处呢? 首先,从上 ...