Linux命令全解
strace
- 获取某个可执行文件执行过程中用到的所有系统调用
:strace -f g++ main.cpp &| vim 查看g++编译过程调用了哪些系统调用,通过管道符用vim接收
:%! grep execve
:%s/ , /\r /g 将文件中的 ,+空格 换成\r, /g表示全局替换
strace参数
-c 统计每一系统调用的所执行的时间,次数和出错的次数等.
-d 输出strace关于标准错误的调试信息.
-f 跟踪由fork调用所产生的子进程.
-ff 如果提供-o filename,则所有进程的跟踪结果输出到相应的filename.pid中,pid是各进程的进程号.
-F 尝试跟踪vfork调用.在-f时,vfork不被跟踪.
-h 输出简要的帮助信息.
-i 输出系统调用的入口指针.
-q 禁止输出关于脱离的消息.
-r 打印出相对时间关于,,每一个系统调用.
-t 在输出中的每一行前加上时间信息.
-tt 在输出中的每一行前加上时间信息,微秒级.
-ttt 微秒级输出,以秒了表示时间.
-T 显示每一调用所耗的时间.
-v 输出所有的系统调用.一些调用关于环境变量,状态,输入输出等调用由于使用频繁,默认不输出.
-V 输出strace的版本信息.
-x 以十六进制形式输出非标准字符串
-xx 所有字符串以十六进制形式输出.
-a column
Linux目录介绍
| 目录 | |
|---|---|
| /bin | 存放二进制可执行文件(ls,cat,mkdir等),常用命令一般都在这里。 |
| /etc | 存放系统管理和配置文件 |
| /home | 存放所有用户文件的根目录,是用户主目录的基点,比如用户user的主目录就是/home/user,可以用~user表示 |
| /usr | 用于存放系统应用程序,比较重要的目录/usr/local 本地系统管理员软件安装目录(安装系统级的应用)。这是最庞大的目录,要用到的应用程序和文件几乎都在这个目录。 /usr/x11r6 存放x window的目录 /usr/bin 众多的应用程序 /usr/sbin 超级用户的一些管理程序 /usr/doc linux文档 /usr/include linux下开发和编译应用程序所需要的头文件 /usr/lib 常用的动态链接库和软件包的配置文件 /usr/man 帮助文档 /usr/src 源代码,linux内核的源代码就放在/usr/src/linux里 /usr/local/bin 本地增加的命令 /usr/local/lib 本地增加的库 |
| /opt | 额外安装的可选应用程序包所放置的位置。一般情况下,我们可以把tomcat等都安装到这里。 |
| /proc | 不能动,虚拟文件系统目录,是系统内存的映射。可直接访问这个目录来获取系统信息。 |
| /sys | 不能动,linux内核, 硬件设备的驱动程序信息 |
| /root | 超级用户(系统管理员)的主目录(特权阶级o) |
| /sbin | 存放二进制可执行文件,只有root才能访问。这里存放的是系统管理员使用的系统级别的管理命令和程序。如ifconfig等。 |
| /dev | 用于存放设备文件。 |
| /mnt | 系统管理员安装临时文件系统的安装点,系统提供这个目录是让用户临时挂载其他的文件系统。 |
| /boot | 存放用于系统引导时使用的各种文件,启动时的核心文件 |
| /lib | 存放跟文件系统中的程序运行所需要的共享库及内核模块。共享库又叫动态链接共享库,作用类似windows里的.dll文件,存放了根文件系统程序运行所需的共享文件。 |
| /tmp | 用于存放各种临时文件,是公用的临时文件存储点。 |
| /var | 用于存放运行时需要改变数据的文件,也是某些大文件的溢出区,比方说各种服务的日志文件(系统启动日志等。)等。 |
| /lost+found | 这个目录平时是空的,系统非正常关机而留下“无家可归”的文件(windows下叫什么.chk)就在这里 |
| /srv | 不能动,service缩写,存放一些服务启动之后需要提取的数据, |
tmux使用
能:
(1) 分屏。
(2) 允许断开Terminal连接后,继续运行进程。
结构:
一个tmux可以包含多个session,一个session可以包含多个window,一个window可以包含多个pane。
实例:
tmux:
session 0:
window 0:
pane 0
pane 1
pane 2
...
window 1
window 2
...
session 1
session 2
...
操作:
(1) tmux:新建一个session,其中包含一个window,window中包含一个pane,pane里打开了一个shell对话框。
(2) 按下Ctrl + a后手指松开,然后按%:将当前pane左右平分成两个pane。
(3) 按下Ctrl + a后手指松开,然后按"(注意是双引号"):将当前pane上下平分成两个pane。
(4) Ctrl + d:关闭当前pane;如果当前window的所有pane均已关闭,则自动关闭window;如果当前session的所有window均已关闭,则自动关闭session。
(5) 鼠标点击可以选pane。
(6) 按下ctrl + a后手指松开,然后按方向键:选择相邻的pane。
(7) 鼠标拖动pane之间的分割线,可以调整分割线的位置。
(8) 按住ctrl + a的同时按方向键,可以调整pane之间分割线的位置。
(9) 按下ctrl + a后手指松开,然后按z:将当前pane全屏/取消全屏。
(10) 按下ctrl + a后手指松开,然后按d:挂起当前session。
(11) tmux a:打开之前挂起的session。
(12) 按下ctrl + a后手指松开,然后按s:选择其它session。
方向键 —— 上:选择上一项 session/window/pane
方向键 —— 下:选择下一项 session/window/pane
方向键 —— 右:展开当前项 session/window
方向键 —— 左:闭合当前项 session/window
(13) 按下Ctrl + a后手指松开,然后按c:在当前session中创建一个新的window。
(14) 按下Ctrl + a后手指松开,然后按w:选择其他window,操作方法与(12)完全相同。
(15) 按下Ctrl + a后手指松开,然后按PageUp:翻阅当前pane内的内容。
(16) 鼠标滚轮:翻阅当前pane内的内容。
(17) 在tmux中选中文本时,需要按住shift键。(仅支持Windows和Linux,不支持Mac,不过该操作并不是必须的,因此影响不大)
(18) tmux中复制/粘贴文本的通用方式:
(1) 按下Ctrl + a后松开手指,然后按[
(2) 用鼠标选中文本,被选中的文本会被自动复制到tmux的剪贴板
(3) 按下Ctrl + a后松开手指,然后按],会将剪贴板中的内容粘贴到光标处
vim使用
意区分 一般模式和编辑模式
vim 无法修改只读文件,可以修改后 输入 :w !sudo tee % --强制保存 然后按 Ctrl + z 退出即可
进入一般模式后
yy 拷贝当前行 p粘贴 5yy 拷贝当前行向下的5行
dd 删除当前行 5dd 删除当前行向下的五行
在vim底端命令行输入 /要查找的内容 即可找到第一个 输入n寻找下一个 输入N寻找上一个
命令行输入 set nu --显示行号 set nonu --不显示行号
撤销之前的编辑命令 --在一般模式下输入u
光标定位 --一般模式下 行号 shift+g 注意这里是看不到输入的行号的
功能:
(1) 命令行模式下的文本编辑器。
(2) 根据文件扩展名自动判别编程语言。支持代码缩进、代码高亮等功能。
(3) 使用方式:vim filename
如果已有该文件,则打开它。
如果没有该文件,则打开个一个新的文件,并命名为filename
模式:
(1) 一般命令模式
默认模式。命令输入方式:类似于打游戏放技能,按不同字符,即可进行不同操作。可以复制、粘贴、删除文本等。
(2) 编辑模式
在一般命令模式里按下i,会进入编辑模式。
按下ESC会退出编辑模式,返回到一般命令模式。
(3) 命令行模式
在一般命令模式里按下:/?三个字母中的任意一个,会进入命令行模式。命令行在最下面。
可以查找、替换、保存、退出、配置编辑器等。
操作:
(1) i:进入编辑模式
(2) ESC:进入一般命令模式
(3) h 或 左箭头键:光标向左移动一个字符
(4) j 或 向下箭头:光标向下移动一个字符
(5) k 或 向上箭头:光标向上移动一个字符
(6) l 或 向右箭头:光标向右移动一个字符
(7) n<Space>:n表示数字,按下数字后再按空格,光标会向右移动这一行的n个字符
(8) 0 或 功能键[Home]:光标移动到本行开头
(9) $ 或 功能键[End]:光标移动到本行末尾
(10) G:光标移动到最后一行
(11) :n 或 nG:n为数字,光标移动到第n行
(12) gg:光标移动到第一行,相当于1G
(13) n<Enter>:n为数字,光标向下移动n行
(14) /word:向光标之下寻找第一个值为word的字符串。
(15) ?word:向光标之上寻找第一个值为word的字符串。
(16) n:重复前一个查找操作
(17) N:反向重复前一个查找操作
(18) :n1,n2s/word1/word2/g:n1与n2为数字,在第n1行与n2行之间寻找word1这个字符串,并将该字符串替换为word2
(19) :1,$s/word1/word2/g:将全文的word1替换为word2
(20) :1,$s/word1/word2/gc:将全文的word1替换为word2,且在替换前要求用户确认。
(21) v:选中文本
(22) d:删除选中的文本
(23) dd: 删除当前行
(24) y:复制选中的文本
(25) yy: 复制当前行
(26) p: 将复制的数据在光标的下一行/下一个位置粘贴
(27) u:撤销
(28) Ctrl + r:取消撤销
(29) 大于号 >:将选中的文本整体向右缩进一次
(30) 小于号 <:将选中的文本整体向左缩进一次
(31) :w 保存
(32) :w! 强制保存
(33) :q 退出
(34) :q! 强制退出
(35) :wq 保存并退出
(36) :set paste 设置成粘贴模式,取消代码自动缩进
(37) :set nopaste 取消粘贴模式,开启代码自动缩进
(38) :set nu 显示行号
(39) :set nonu 隐藏行号
(40) gg=G:将全文代码格式化
(41) :noh 关闭查找关键词高亮
(42) Ctrl + q:当vim卡死时,可以取消当前正在执行的命令
异常处理:
每次用vim编辑文件时,会自动创建一个.filename.swp的临时文件。
如果打开某个文件时,该文件的swp文件已存在,则会报错。此时解决办法有两种:
(1) 找到正在打开该文件的程序,并退出
(2) 直接删掉该swp文件即可
在打开文件保存后,:%!g++ main.c && ./a.out 直接编译执行
:!% + x, x可以为任意命令,!%可以对vim的整个buffer调用命令行,并替换当前的buffer(用grep 过滤)
编辑二进制只读文件a.out,vim a.out; 然后修改指定位置字符后,:%!xxd 二进制格式打开, 修改后 :%!xxd -r 退出二进制编辑
:w !sudo tee % 强制写入
变量
定义变量
定义变量,不需要加$符号,例如:
name1='yxc' # 单引号定义字符串
name2="yxc" # 双引号定义字符串
name3=yxc # 也可以不加引号,同样表示字符串
使用变量
使用变量,需要加上$符号,或者${}符号。花括号是可选的,主要为了帮助解释器识别变量边界。
name=yxc
echo $name # 输出yxc
echo ${name} # 输出yxc
echo ${name}acwing # 输出yxcacwing
只读变量
使用readonly或者declare可以将变量变为只读。
name=yxc
readonly name
declare -r name # 两种写法均可
name=abc # 会报错,因为此时name只读
删除变量
unset可以删除变量。
name=yxc
unset name
echo $name # 输出空行
变量类型
自定义变量(局部变量)
子进程不能访问的变量
环境变量(全局变量)
子进程可以访问的变量
自定义变量改成环境变量:
acs@9e0ebfcd82d7:~$ name=yxc # 定义变量
acs@9e0ebfcd82d7:~$ export name # 第一种方法
acs@9e0ebfcd82d7:~$ declare -x name # 第二种方法
环境变量改为自定义变量:
acs@9e0ebfcd82d7:~$ export name=yxc # 定义环境变量
acs@9e0ebfcd82d7:~$ declare +x name # 改为自定义变量
关机重启
shutdown -h now --立刻关机
shutdown -h 1 --1分钟后关机
shutdown -r now --立刻重启
halt --关机,作用同上
reboot --重启,作用同上
sync --把内存的数据同步到磁盘
用户管理
useradd -d /home 用户名 --添加用户,目录在home下(不添加默认home),默认建一个与其同名的用户组
passwd 用户名 输入密码即可 --为新用户设置密码
id 用户名 --查看用户所属组
userdel 用户名 --删除用户,但是保留家目录
userdel -r 用户名 --删除用户,同时删除家目录
whoami --查看当前用户信息
groupadd 用户组名 --添加用户组
groupdel 用户组名 --删除用户组
useradd -g 组名 用户名 --添加用户的同时将其加入指定组
用户组相关文件
/etc/passwd文件
用户的配置文件,记录用户各种 信息
每行的含义:用户名:口令:用户标识号:组标识号:注释性描述:主目录:登录shell
/etc/shadow文件
口令的配置文件
每行的含义:登录名:加密口令:最后一次修改时间:最小时间间隔:最大时间间隔:警告时间:不活动时间:失效时间:标志
/etc/group文件
组的配置文件,记录Linux包含的组的信息
每行含义:组名:口令:组标识号:组内用户列表
运行级别
运行级别0:系统停机状态,系统默认运行级别不能设为0,否则不能正常启动
运行级别1:单用户工作状态,root权限,用于系统维护,禁止远程登陆
运行级别2:多用户状态(没有NFS),没有网络连接。
运行级别3:完全的多用户状态(有NFS),登陆后进入控制台命令行模式 最常用,Linux服务器
运行级别4:系统未使用,保留
运行级别5:X11控制台,登陆后进入图形GUI模式
运行级别6:系统正常关闭并重启,默认运行级别不能设为6,否则不能正常启动
init 3 --切换运行级别
systemctl get-default --获取当前运行级别
systemctl get-default mlti-user.target --设置为运行级别3
找回root密码
1、首先启动系统,进入开机界面,在界面中按'e'进入编辑界面,注意要快 15s
2、进入编辑页面,使用键盘上下键将光标移动,找到以“Linux16”开头的内容所在的行,在行的最后输入:init=/bin/sh
3、输入Ctrl+x启动,进入单用户模式
4、接着在光标闪烁的位置输入mount -o remount,rw / (各个单词之间有空格),完成后按回车键
5、在新的一行输入passwd ,按回车输入密码,然后再次确认密码即可
6、接着,在鼠标闪烁的位置(最后一行)插入:touch /.autorelabel(注意touch与/间有一个空格),完成后回车
7、继续在光标闪烁的位置,输入:exec /sbin/init(exec与/之间有空格),完成后回车,等待即可,系统会自动重启
帮助指令
man 命令 --获得帮助信息
ls -a --查看所有文件,包括隐藏文件,linux下以.开头的文件为隐藏文件
ls -l --单列显示ls 还可以ls -la/ls -al
help --获得shell内置命令的帮助信息
文件目录
pwd --显示当前工作目录的绝对路径
cd ~ --家目录
cd / --根目录
mkdir --创建目录 md /home/animal
mkdir -p --创建多级目录 md -p /home/animal/dog
rmdir 目录 --删除空目录 rm /home/animal
rmdir -rf 目录 --递归删除整个目录 rm -rf /home/animal
cp 1.txt /test --拷贝文件到指定目录
cp -r /home/svicen /home/test --递归拷贝整个目录到指定目录,将svicen整个给test
\cp -r /home/svicen /home/test --递归拷贝,强制覆盖原来的文件
rm --删除文件或目录 -r递归删除整个文件夹 -f强制删除不提示
mv test0 test01 --移动文件与目录或从重命名 如果两文件在同一目录则为重命名
mv test /root/test01 --移动文件并重命名
mv /opt/bbb /home --移动整个目录及其下的文件
cat [-n] 文件名 --查看文件内容 -n 显示行号
cat -n test | more --为了浏览方便,一般会加上 管道符|+more more往往是用来展示的
more -- 空格->向下翻一页 回车->向下翻一行 q->离开more Ctrl+F->向下滚动一屏 Ctrl+B->向上一屏 :f->输出文件名和当前行号
less 要查看的文件 --分配查看文件,与more类似,但并不是一次全部加载,根据显示需要加载,效率更高
echo $PATH --输出内容到控制台
head -n 5 --显示文件前5行,默认显示前10行
tail -n 5 --显示后五行
taile -f 文件名 --监视制定文件,如果其内内容发生变化,在此可以展示变化
重定向 > --覆盖内容 >> --追加内容
ls -l /home > /home/info.txt --将home目录下文件以单列显示方式写入到info.txt中
ln -s 源文件或目录 软链接名 --软连接 ln -s /root /home/myroot -> 访问myroot就相当于访问root目录
history --查看历史命令
!历史命令编号 --可以执行历史命令
时间日期指令
date --显示当前时间,年月日时分秒
date '+%Y-%m-%d' --显示年月日,以-分隔 注意大小写
date -s "2022-04-04 14:23:10" --设置系统日期
cal --查看本月日历 cal 2022 显示2022整年的日历
查找指令
find /home -name hello.txt --在指定目录下找着指定名的文件
find /opt -user root | more --查找指定目录下用户名称为root的文件
find / size +200M --查找整个linux系统下大于200M的文件 -200M为小于 默认为等于
ls -lh --按照人更直观的方式显示文件大小
updatedb; locate 搜索文件 --可以快速定位文件路径 注意需要先写 updatedb
cat 1.txt | grep -n "hello" --grep过滤查找,管道符| 表示将前一个命令的结果传递给后面的命令处理
grep -n "hello" /home/1.txt --与上相同
压缩和解压
gzip /home/hello.txt --压缩文件
gunzip /home/hello.txt.gz --解压文件
zip --压缩文件或文件夹,在项目打包发布中很有用
zip -r myhome.zip /home/ --将home及home目录下的所有文件及文件夹都压缩 -r 递归压缩
unzip --解压缩文件/文件夹
unzip -d /opt/tmp /home/myhome.zip --解压到opt/tmp文件夹下
tar --打包命令,最后打包好的是.tar.gz文件
-c 产生.tar打包文件 -V 显示详细信息 -f 指定压缩后文件名 -z 打包同时压缩 -x 解压.tar文件
tar -zcvf pc.tar.gz /home/pig.txt /home/cat.txt 多个文件压缩为pc.tar.gz
tar -zxvf pc.tar.gz -C opt/tmp --解压缩到指定目录opt/tmp
Linux组
对于linux的文件,有三个概念所有者,所在组,其他组
所有者-谁创建的谁为所有者 查看文件所有者ls -ahl 或者 ll
组的创建 groupadd 当一个用户创建一个文件时,该文件所属的组就是该用户所属的组
chgrp 组名 文件名 --修改文件所在组
其他组 --除了所在组及所有者,系统的其他用户所在组都是其他组
usermod -g 新组名 用户名 --修改用户所在组
usermod -d 目录名 用户名 --改变用户初始目录, 前提用户需要有进入到该目录的权限
权限管理
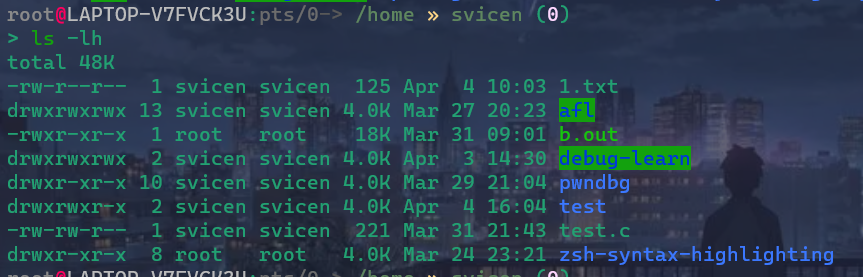
最左边一列有10位
1.第0位确定文件类型(d是目录,l是链接,b是块设备,硬盘 -是普通文件 c是字符设备文件,鼠标键盘)
2.第1-3为确定所有者(该文件的所有者)拥有该文件的权限 ---User
3.第4-6位确定所属组拥有该文件的权限 --group
4.第7-9位确定其他用户拥有该文件的权限 --other
左数第二列的数字:文件即为1,为目录即其子目录数与子文件总和
左数第三四列:文件所有者 和 文件所在组
左数第五列:文件大小按字节数
左数第六列:最近修改日期
rwx作用详解
- rwx作用到文件
1.[r]代表read,可以读取,查看
2.[w]代表write,可以修改,但是不一定可以删除该文件,删除一个文件的前提是对该文件所在的目录有写权限。
3.[x]代表execute,可以执行
r=4,w=2,x=1 因此 rwx=4+2+1=7
- rwx作用到目录
1.[r]代表read,可以读取,ls查看目录内容
2.[w]代表write,可以修改,对目录内创建文件、删除文件,重命名目录
3.[x]代表execute,可以进入该目录,但不可以ls
chmod修改文件或目录的权限 u-所有者 g-所有组 o-其他 a-所有人
第一种方式:+ - = 变更权限
chmod u=rwx,g=rx,o=x 文件/目录名
chmod o+w 文件/目录名 --给文件的其他用户赋予修改权限
chmod a-x 文件/目录名 --对所有人去掉可执行权限
第二种方式:通过数字变更权限 r=4,w=2,x=1
chmod u=rwx,g=rx,o=x abc 相当于 chmod 751 abc
修改文件所有者-chown
chown newowner 文件/目录 --改变文件所有者为王newowner
chown -R newowner /home/test --递归改变文件和其目录下所有文件的所有者为newowner
修改文件/目录所在组chgrp
chgrp newgroup 文件/目录 --改变所在组
chgrp -R newgroup /home/test --递归修改test目录下所有文件的所在组为newgroup
对于目录
1.被赋予x执行权限的用户,该用户可以进入目录,但不能读取目录,不能使用ls,但是对于该目录下的文件该拥有的权限还是有的
可以修改或读取有指定权限的文件 1.txt的内容因此被修改
2.赋予w写权限的用户,可以对该目录下的文件进行创建、修改 --可以把目录看成文件 一切皆文件
3.赋予r读权限的用户,可以在进入该目录后ls,但只赋予读权限是不能进入文件目录的
crond任务调度
- 常用选项
-e 编辑crontab定时任务
-l 列出当前有哪些crontab任务
-r 删除当前用户所有的crontab任务
- 命令介绍
*/1****ls -l /etc/ > /tmp/to.txt
意思是每小时的每分钟执行ls -l /etc/ > /tmp/to.txt目录
- 五个占位符说明
| 项目 | 含义 | 范围 |
|---|---|---|
| 第一个* | 一小时当中的第几分钟 | 0-59 |
| 第二个* | 一天当中的第几小时 | 0-23 |
| 第三个* | 一个月当中的第几天 | 1-31 |
| 第四个* | 一年当中的第几月 | 1-12 |
| 第五个* | 一周当中的星期几 | 0-7(0和7都代表星期日) |
crontab -e --编辑定时任务
- 特殊符号的说明
| 特殊符号 | 含义 |
|---|---|
| * | 代表任何时间 |
| , | 代表不连续的时间,比如"0 8,12,16 * * *"命令代表在每天的8点0分,12点0分,16点0分都执行一次命令 |
| - | 代表连续的时间范围,比如"0 5 * * 1-6"命令代表在周一到周六的凌晨5点0分执行命令 |
| */n | 代表每隔多久执行一次,比如"* /10* * * *"命令代表每隔10分钟执行一次命令 |
0 0 1,15 * 1 命令表示每月1号和15号且是周一的凌晨0点0分执行命令,注意星期几和几号最好不要同时写
at任务调度
基本介绍
1.at命令是一次性定时任务,at的守护进程atd会以后台模式运行,检查作业队列来运行
2.默认情况下,atd守护进程每60秒检查作业队列,有作业时,会检查作业运行时间,如果时间与当前时间匹配,则运行该作业
3.at命令是一次性定时任务,执行完一个任务后便不再执行
4.在使用at命令时,一定要保证atd进程的启动,可以使用相关指令来查看 ps -ef | grep atd
at命令格式
at [选项] [时间] 写完后两次Ctrl + D代表输入结束
at now + 2 minutes
>at date > /home/mydate.log 两分钟后执行该命令,先要将at服务启动sudo /etc/init.d/atd start
at 5pm tomorrow
>at /bin/sh ls /home 明天下午5点用sh执行ls命令
at 5pm + 2 days
>at /root/my.sh 两天后5点执行脚本my.sh,前提脚本存在且有执行权限
atrm 2 删除任务队列号为2的任务
atq 查看当前任务队列

磁盘分区、挂载
分区的方式
- mbr分区
- 最多支持四个主分区
- 系统只能安装在主分区
- 扩展分区要占一个主分区
- MBR最大只支持2TB,但拥有最好的兼容性
- gpt分区
- 支持无限多个主分区(但操作系统可能限制,比如windows下最多128个分区)
- 最大支持18EB的大容量(1EB=1024PB,PB=1024TB)
- windows7 64位以后支持gpt
- mbr分区
Linux分区
- Linux来说无论有几个分区,分给哪一个目录使用,它归根结底就只有一个根目录,一个独立且唯一的文件结构,Linux中每个分区都是用来组成整个文件系统的一部分。
- Linux采用了一种叫做“载入”的处理方法,它的整个文件系统中包含了一整套的文件和目录,且将一个分区和一个目录联系起来。这时要载入的一个分区将使它的存储空间在一个目录下获得。
硬盘说明
- Linux硬盘分IDE硬盘和SCSI硬盘,目前基本上是SCSI硬盘
- 对于IDE硬盘,驱动器标识符为"hdx~",其中"hd"表明分区所在设备的类型,这里是指IDE硬盘,"x"为盘号(a为基本盘,b为基本从属盘,c为辅助主盘,d为辅助从属盘)," ~"代表分区,前四个分区用数字1到4表示,他们是主分区或扩展分区,从5开始就是逻辑分区。例:hda3表示为第一个IDE硬盘上的第三个主分区或扩展分区,hdb2表示第二个IDE硬盘的第二个主分区或扩展分区
- 对于SCSI硬盘则标识为"sdx~",SCSI硬盘使用"sd"来表示分区所在设备的类型的,其余和IDE硬盘表示方法一样
- lsblk -f:查看当前系统的分区和挂载情况。(list block)
挂载的经典案例
- 需求是给我们的Linux系统增加一个新的硬盘,并且挂载到/home/newdisk
虚拟机添加硬盘 ---设置->硬盘->添加
分区:fdsk /dev/sdb -- 设置分区号 Ctrl + backspace 删除 回车确认 命令哪里输入w 写入并退出
格式化:mkfs -t ext4 /dev/sdb1 格式化后就有了UUID号
挂载:新建目录:mkdir /home/newdisk;挂载:mount /dev/sdb1 /home/newdisk
命令行下挂载,重启命令行便无效了
设置可以自动挂载(永久挂载):重启系统后,仍然可以挂载。vim etc/fstab 增加挂载信息赋值修改 UUID或者在UUID的位置写设备名/dev/sdb1,之后输入mount -a或reboot生效
- 取消挂载:unmount /dev/sdb1
磁盘情况查询:df -h / df -l
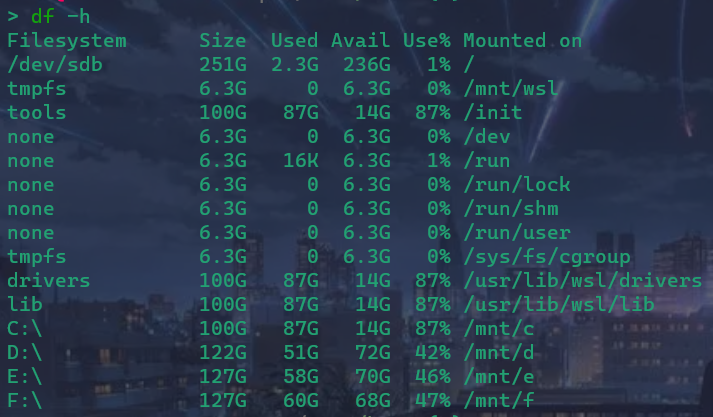
查询指定目录的磁盘占用情况:du -h /目录,默认为当前目录
- -s:指定目录占用大小汇总
- -h:带计量单位
- -a:含文件
- --max-depth=1:子目录深度为1
- -c:列出明细的同时,增加汇总值
示例:du -hac --max-depth=1 /opt
磁盘情况-工作实用指令
统计/home文件夹下文件的个数:
ls -l /home | grep "^-" | wc -l以 - 开头的为文件统计/home文件夹下目录的个数:
ls -l /home | grep "^d" | wc -l以 d 开头的为文件夹统计/home文件夹下文件的个数,包括子文件夹里的:
ls -lR /home | grep "^-" | wc -l统计文件夹下目录的个数,包括子文件夹里的:
ls -lR /home | grep "^d" | wc -l以树状显示目录结构:首先安装tree指令:yum install tree,tree /home
tree /home -d --仅列出目录 tree -l 不给出指定目录则为当前目录
网络配置
指定固定IP:直接修改配置文件来指定IP,并可以连接到外网,编辑:vim /etc/sysconfig/network-scripts/ifcfg-eth0
修改:静态分配IP:BOOTPROTO="static"
IP地址:IPADDR=192.168.1.100
网关:GATEWAY = 192.168.200.2
DNS域名解析器DNS1=192.168.200.2
接着打开虚拟机,编辑->虚拟网络编辑器->Vmnet8 -> 下的子网IP改为 192.168.200.1 与网卡和DNS解析器在同一网段
同时在虚拟网络编辑器下 - > NAT设置 -> 修改网关IP为 192.168.200.2
重启网络服务:service network restart
设置主机名和hosts映射
在Windows下 C:\Windows\System32\drivers\etc\hosts
在Linux下 在/etc/hosts文件指定 写上 IP地址 和 主机名映射 即可
主机名解析机制
1.浏览器先检查浏览器缓存中有没有该域名解析IP地址,有就先调用这个IP完成解析,如果没有则检查DNS解析器缓存,如果有直接返回IP完成解析。 这两个缓存可以理解为本地解析器缓存。
2.一般来说,当电脑第一次成功访问某一网站后,在一定时间内,浏览器或操作系统会缓存他的IP地址(DNS解析记录)
ipconfig /displaydns //DNS域名解析缓存
ipconfig /flushdns //手动清理DNS缓存
3.如果本地解析器缓存没有找到对应映射,检查系统中hosts文件中有没有配置对应的域名IP映射,有则完成解析
4.如果本地DNS解析器缓存和hosts文件中均没有找到对应IP则到DNS服务器进行解析
进程管理
在Linux中,每个执行的程序(代码)都称为一个进程。每个进程都分配一个ID号
每一个进程,都会对应一个父进程,而这个父进程可以复制多个子进程。例如www服务器。
每个进程都可能以两种方式存在:前台和后台。
- 前台进程:用户目前的屏幕上可以进行操作的。比如说Vim
- 后台进程:实际在操作,但由于屏幕上无法看到的进程,通常使用后台方式执行。比如说数据库
一般系统的服务都是以后台进程的方式存在,而且都会常驻在系统中,直到关机才结束。
显示系统执行的进程
ps:查看目前系统中,有哪些正在执行,以及它们执行的状况。可以不加任何参数。PID:进程识别号;TTY:终端机号;TIME:此进程所消耗的CPU时间;CMD:正在执行的命令或进程名; RSS:占物理内存的情况 VSZ: 占虚拟内存的情况
STAT:进程状态,S-睡眠 R-正在运行 D-短期等待 Z-僵死进程,需要定时清除 T-被跟踪或者被停止
ps -a:显示当前终端的所有进程信息。
ps -u:以用户的格式显示进程信息。
ps -x:显示后台进程运行的参数。
ps -axu | grep xxx:过滤得到xxx的信息。 ps -axu | grep sshd
ps -ef:以全格式显示当前所有的进程,查看进程的父进程PPID。
-e:显示所有进程。
-f:全格式。
终止进程
kill [选项] 进程号:通过进程号杀死进程
killall 进程名称:通过进程名称杀死进程,也支持通配符,这在系统因负载过大而变得很慢时很有用
-9:表示强迫进程立刻停止
案例1:踢掉非法用户:kill 进程号
案例2:终止远程登录服务sshd,在适当时候再次重启sshd服务
kill sshd对应的进程号; /bin/systemctl start sshd.service --重启sshd服务
案例3:终止多个gedit编辑器:killall 进程名称
killall gedit
案例4:强制杀掉一个终端:kill -9 进程号 对于正在运行的终端直接kill 进程号 系统会认为是误操作
查看进程树:pstree [选项]
- -p:显示进程的PID
- -u:显示进程的所属用户
服务(service)管理
service管理指令:service 服务名 [start | stop | restart | reload | status]
在CentOS7.0之后,不再使用service,而是systemctl,被service管理的服务主要是/etc/init.d下的服务
service network stop --停止网络服务 service network start --启动网络服务
查看防火墙情况:
- service iptables status
- systemctl status firewalld(7.0之后的版本)
测试某个端口是否在监听:telnet
查看服务名:
方式1:使用setup->系统服务就可以看到
前面带*的为自启动的,光标停在上面按空格可以取消自启动 按tab退出
方式2:/etc/init.d/服务名称 ls -l /etc/init.d --查看init.d下的服务名称
服务的运行级别(runlevel):

查看或修改默认级别:systemctl get-default --查看当前服务级别 systemctl set-default multi-user. target
vim /etc/inittab
每个服务对应的每个运行级别都可以设置
如果不小心将默认的运行级别设置成0或者6,怎么处理?
- 进入单用户模式,修改成正常的即可。
chkconfig:可以给每个服务的各个运行级别设置自启动/关闭 ---不适用于Ubuntu系统可用 sudo apt-get install sysv-rc-conf
查看xxx服务:chkconfig –list | grep xxx
查看服务的状态:chkconfig 服务名 --list
给服务的运行级别设置自启动:chkconfig –level 5 服务名 on/off
要所有运行级别关闭或开启:chkconfig 服务名 on/off
应用实例查看防火墙状况,关闭和重启防火墙
- systemctl status firewalld ubuntu下 ufw status
wsl2里面没有
systemd命令,我们需要用sudo /etc/init.d/docker start代替sudo systemctl start dockersystemctl stop firewalld systemctl start firewalld 临时生效
systemctl is-enabled firewalld --判断是否是自启动 systemcal disable firewalld --设置为开机不自启动
注:上面两个命令对于Centos 7 以后的系统的3和5运行级别同时生效
firewall指令
- firewall-cmd --permanent --add-port=111/tcp --在防火墙中开放端口111打开后需 firewall-cmd --reload
- firewall-cmd --permanent --remove-port=111/tcp --在防火墙中关闭端口111 reload
- firewall-cmd --permanent --query-port=111/tcp ---查询端口是否开放
动态监控进程
top [选项]
top和ps命令很相似。它们都用来显示正在执行的进程。top和ps最大的不同之处在于top在执行一段时间可以更新正在运行的进程。
-d 秒数:指定top命令每隔几秒更新。默认是3秒。
-i:使top不显示任何闲置或者僵死进程。
-p:通过指定监控进程ID来仅仅监控某个进程的状态。
案例1:监控特定用户:top查看进程;u输入用户名。
top ; u ; 输入用户: Tom
案例2:终止指定的进程:top查看进程;k输入要结束的进程。
案例3:指定系统状态更新的时间(每隔10秒自动更新,默认是3秒):top -d 10
交互操作说明:
- P:以CPU使用率排序,默认就是此项
- M:以内存的使用率排序
- N:以PID排序
- q:退出top
监控网络状态
- netstat [选项]
- -an:按一定顺序排列输出
- -p:显示哪个进程在调用
RPM
RPM:RedHat Package Manager,红帽软件包管理工具。
RPM查询已安装的rpm列表:rpm -qa | grep xx
示例:查看当前系统是否安装Firefox:rpm -qa | grep firefox
rpm包的其它查询指令:
- rpm -qa:查询所安装的所有rpm软件包
- rpm -qa | more
- rpm -qa | grep xx
- rpm -q xx:查询xx软件包是否安装
- rpm -qi xx:查询软件包信息
- rpm -ql xx:查询软件包中的文件
- rpm -qf 文件全路径名:查询文件所属的软件包
卸载rpm包:rpm -e 软件包名称 强制删除 rpm -e --nodeps foo
删除时可能会发生依赖错误,忽视依赖强制删除的方法:rpm -e --nodeps 软件包名称
安装rpm包:rpm -ivh 软件包全路径名称
- i=install:安装
- v=verbose:提示
- h=hash:进度条
YUM
- YUM:是一个shell前端软件包管理器。基于RPM包管理,能够从指定的服务器自动下载RPM包并安装,可以自动处理依赖性关系,并且一次安装所有依赖的软件包。使用yum的前提是联网。
- yum list | grep xx:查询yum服务器是否有需要安装的软件
- Ubuntu下 apt list | grep
- yum install xx:安装指定的yum包
- yum -y remove xx:卸载指定的yum包
shell编程
vim hello.sh
#!/bin/bash(zsh)
echo "helloworld!"
脚本的常用执行方式
- 方式一:输入脚本的绝对路径或相对路径,需要先赋予hello.sh脚本的x权限,sudo chmod u+x hello.sh
- 方式二:(sh + 脚本)说明:不用赋予脚本+x权限,直接执行 比如 sh hello.sh
Shell的变量
变量分为:系统变量和用户自定义变量
- 系统变量:$HOME、$PWD、$SHELL、$USER等等,比如echo $HOME等等
- 显示当前shell中所有变量:set
shell变量的定义
- 定义变量:变量名=值
- 撤销变量:unset 变量
- 声明静态变量:readonly变量,注意:不能unset
案例
定义变量A
vim var.sh
#!/bin/bash(zsh)
A=100
echo $A # ./var.sh --100
echo A=$A # ./var.sh --A=100
echo "A=$A" # ./var.sh --A=100
撤销变量
unset A声明静态变量
readonly B=2 # 还可以 declare -r B 声明为只读变量
echo "B=$B"
#unset B --不可以unset B
#显示行号 :nu
shell变量命名规则
- 变量名称可以由字母、数字、下划线组成,但是不能以数字开头
- 等号两侧不能有空格
- 变量名称一般习惯大写
将命令的返回值赋给变量
A=`date` #反引号,运行里面的命令,并把结果返回给变量A
A=$(date) #等价于反引号
设置环境变量
export 变量名=变量值 #功能描述:将shell变量输出为环境变量/全局变量
source 配置文件 #功能描述:让修改后的配置信息立即生效
echo $变量名 #功能描述:查询环境变量的值
快速入门
#1.在/etc/profile文件中定义TOMCAT_HOME环境变量
tomcat位于/opt/ 文件目录下
vim /etc/profile
export TOMCAT_HOME=/opt/tomcat
sourse /etc/profile
#2.查看环境变量的值
echo $TOMCAT_HOME
#3.在另外一个shell程序中使用TOMCAT_HOME
vim var.sh
echo "tomcat_home=$TOMCAT_HOME"
:<<!
多行注释
!
位置参数变量
当我们执行一个shell脚本时,如果希望获取到命令行的参数信息,就可以使用到未知参数变量
基本语法
- $n (功能描述:n为数字,$0代表目录本身,$1-$9代表第一到第九个参数,十以上的参数需要用大括号包含,如${10})
- $* (功能描述:这个变量代表命令行中所有的参数,$*把所有的参数看成一个整体)
- $@ (功能描述:这个变量也代表命令行中所有的参数,不过$@把每个参数区分对待)
- $# (功能描述:这个变量代表命令行中所有参数的个数)(不限于9个,但统计数量时不包含作为第一个参数的Shell文件名)
案例:
编写一个shell脚本,position.sh,在脚本中获取到命令行的各个参数信息
预定义变量
就是shell设计者事先已经定义好的变量,可以直接在shell脚本中使用
- 基本语法
- $$ (功能描述:当前进程的进程号(PID))
- $! (功能描述:后台运行的最后一个进程的进程号(PID))
- $?(功能描述:最后一次执行的命令的返回状态。如果这个变量的值为0,证明上一个命令正确执行;如果这个变量的值非0,则证明上一个命令执行不正确了)
- $-用于得到当前Shell(用set)设置的执行标识名组成的字符串
- 基本语法
运算符
基本语法
- "$((运算式))"或"$[运算式]"或者expr m + n //expression 表达式
- 注意expr运算符间要有空格,如果希望将expr的结果赋给某个变量,使用``
- expr m - n
- expr \*,/,% 乘,除,取模
实例
计算(2+3)*4的值
vim operator.sh
#!bin/bash
#第一种方式:
RES1=$(((2+3)*4))
echo "res1=$RES1"
#第二种方式
RES2=$[(2+3)*4]
echo "res2=$RES2" #推荐使用
#第三种方式
TEMP=`expr 2 + 3` #注意要用空格,否则输出结果为 2+3
RES3=`expr $TEMP \* 4`
echo "temp=$TEMP"
echo "res3=$RES3"
求出命令行的两个参数[整数]的和 20 50
SUM=$[$1+$2]
echo "sum=$SUM"
然后再命令行输入 ./operator.sh 20 50 --输出结果 sum=70
条件判断
基本语法
if [ condition ] (注意condition前后要有空格) 非空返回true,可使用$?验证(0为true,>1为false)
示例
[ abc ] --返回true [] --返回false [ condition ] && echo ok || echo notok 条件满足执行后边的语句
判断语句
常用判断条件
1)= 字符串比较,判断两个字符串是否相等
2)两个整数的比较
-lt 小于
-le 小于等于
-eq 等于
-gt 大于
-ge 大于等于
-ne 不等于
3)按照文件权限划分
-r 有读的权限
-w 有写的权限
-x 有执行的权限
4)按照文件类型划分
-f 文件存在并且是一个常规文件
-e 文件存在
-d 文件存在并是一个目录
应用实例
vim ifdemo.sh
#!bin/bash
#案例1:判断"ok"是否等于"ok"
if [ "ok" = "ok" ]
then
echo "equal"
fi
#案例2:23是否大于等于22
if [ 23 -ge 22 ]
then
echo "大于"
fi
#案例3:/root/shcode/aaa.txt 判断目录中的文件是否存在
if [ -f /root/shcode/aaa.txt ]
then
echo "存在"
fi
流程控制
多分支语句
案例:如果输入的参数大于60,则输出及格了,否则输出不及格
#!/bin/bash
if [ $1 -ge 60 ]
then
echo "及格了"
elif [ $1 -lt 60 ]
then
echo "不及格"
case语句
#!/bin/bash
case $1 in
"1")
echo "周一"
;;
"2")
echo "周二"
;;
"3")
echo "周三"
;;
*)
echo "Other.."
;;
esac
for语句
vim testFor1.sh
#!/bin/bash
#基本语法1
<< comment
for 变量 in 值1 值2 值3...
do
程序主代码
done
comment
#案例1:打印命令行输入的参数
for i in "$*" # $*把所有的参数看成一个整体
do
echo "num is $i" #这里只会输出一句话
done for j in "$@" #$@把每个参数区分对待
do
echo "num is $j"
done
#基本语法2
for ((初始值;循环控制条件;变量变化))
do
主程序代码
done
#案例2:从1到100的值累加显示
SUM=0
for ((i=1; i<=100; i++))
do
SUM=$[$SUM+$I]
done
echo "sum=$SUM"
while语句
while [ 条件判断式 ]
do
程序
done
vim testWhile.sh
#!/bin/bash
#案例1:从命令行输入一个参数n,统计1+2+..+n
SUM=0
i=0
while [ $i -le $1 ]
do
SUM=$[$SUM+$i]
# i自增
i=$[$i+1]
done
echo "结果=$SUM"
read获取控制台输入
read(选项)(参数)
选项:
-p:指定读取值时的提示符
-t:指定读取值时等待的时间(秒),如果没有在指定时间内输入,就不再等待了
参数:变量:指定读取值的变量名
#实例:testRead.sh
#案例1:读取控制台输入一个num值
#!/bin/bash
read -P "请输入一个数num=" NUM1
echo "你输入的num=$NUM1"
#案例2:读取控制台输入一个num值,在10秒内输入
read -t 10 -P "请输入一个数num=" NUM2
echo "你输入的num=$NUM2"
函数
系统函数
basename:功能为返回完整路径的最后/的部分,常用于获取文件名
basename [pathname] [suffix] (选项suffix为后缀,如果suffix被指定了,basename会将pathname或string的suffix去掉)
basename [string] [suffix] (功能:basename命令后会删掉所有的前缀包括最后一个/字符,然后将字符串显示出来)
#案例1:返回/home/aaa/test.txt的"test.txt"部分
basename /home/aaa/test.txt --test.txt
basename /home/aaa/test.txt .tst --test
dirname:功能为返回完整路径最后/的前面部分,常用于返回路径部分
dirname /home/aaa/test.txt --/home/aaa
自定义函数
function funname ()
{
Action;
[return int;]
}
#调用时直接写函数名:funname [参数值]
#案例1:计算输入的两个参数的和(动态获取)
vim testFunc.sh
#!/bin/bash
#定义函数
function getSum(){
SUM=$[$n1+$n2]
echo "和=$SUM"
}
#控制台输入两个值
read -P "请输入一个数n1=" n1
read -P "请输入一个数n2=" n2
#调用
getSum $n1 $n2
Shell编程综合案例
需求分析:
1.每天凌晨2:30备份数据库hspedu到 /data/backup/db
2.备份开始和结束能够给出相应的提示信息
3.备份后的文件要求以备份时间为文件名,并打包成.tar.gz的形式,比如2021-04-10_104515.tar.gz
4.在备份的同时,检查是否有10天前备份的数据库文件,如果有就将其删除
#!/bin/bash
#备份目录
BACKUP=/data/backup/db
#获取当前时间
DATETIME=$(date +%Y-%m-%d_%H%M%S)
#数据库的地址
HOST=localhost
#数据库用户名
DB_USER=root
#数据库密码
DB_PW=root
#备份的数据库
DATABASE=hspedu
#创建备份目录,如果不存在就创建,如果存在就直接使用
[ ! -d "${BACKUP}/${DATETIME}" ] && mkdir -p "${BACKUP}/${DATETIME}" #! -d 表示如果不是一个目录 {}为可选的
#备份数据库 -q -R表示若有多个数据库都备份
mysqldump -u${DB_USER} -p${DB_PW} --host=${HOST} -q -R --datebases ${DATABASE} | gzip > ${BACKUP}/${DATETIME}/$DATETIME.sql.gz
#将文件处理成tar.gz形式
cd ${BACKUP}
tar -zcvf $DATETIME.tar.gz ${DATETIME} # 将${DATETIME}压缩为$DATETIME.tar.gz
#删除备份的文件夹目录及之下的文件
rm -rf ${BACKUP}/${DATETIME}
#检查是否有十天前备份的文件,将其删除
find ${BACKUP} -atime +10 -name "*.tar.gz" -exec rm -rf {} \; #-atime +10 查找十天前创建的备份文件
echo "备份数据库${DATABASE}成功" #设置定时任务
crontab -e
30 2 * * * /usr/sbin/mysql_db_backup.sh(以上所写脚本文件所在目录)
日志

expr命令用于求表达式的值,格式为:
expr 表达式
表达式说明:
用空格隔开每一项
用反斜杠放在shell特定的字符前面(发现表达式运行错误时,可以试试转义)
对包含空格和其他特殊字符的字符串要用引号括起来
expr会在stdout中输出结果。如果为逻辑关系表达式,则结果为真,stdout为1,否则为0。
expr的exit code:如果为逻辑关系表达式,则结果为真,exit code为0,否则为1。
字符串表达式
length STRING
返回STRING的长度
index STRING CHARSET
CHARSET中任意单个字符在STRING中最前面的字符位置,下标从1开始。如果在STRING中完全不存在CHARSET中的字符,则返回0。
substr STRING POSITION LENGTH
返回STRING字符串中从POSITION开始,长度最大为LENGTH的子串。如果POSITION或LENGTH为负数,0或非数值,则返回空字符串。
示例:
str="Hello World!"
echo `expr length "$str"` # ``不是单引号,表示执行该命令,输出12
echo `expr index "$str" aWd` # 输出7,下标从1开始
echo `expr substr "\$str" 2 3` # 输出 ell
整数表达式
expr支持普通的算术操作,算术表达式优先级低于字符串表达式,高于逻辑关系表达式。
+ -
加减运算。两端参数会转换为整数,如果转换失败则报错。
* / %
乘,除,取模运算。两端参数会转换为整数,如果转换失败则报错。
() 可以改变优先级,但需要用反斜杠转义
逻辑关系表达式
或运算符 |
如果第一个参数非空且非0,则返回第一个参数的值,否则返回第二个参数的值,但要求第二个参数的值也是非空或非0,否则返回0。如果第一个参数是非空或非0时,不会计算第二个参数。
与运算符 &
如果两个参数都非空且非0,则返回第一个参数,否则返回0。如果第一个参为0或为空,则不会计算第二个参数。
比较运算符 < <= = == != >= >
比较两端的参数,如果为true,则返回1,否则返回0。”==”是”=”的同义词。”expr”首先尝试将两端参数转换为整数,并做算术比较,如果转换失败,则按字符集排序规则做字符比较。
() 可以改变优先级,但需要用反斜杠转义Linux命令全解的更多相关文章
- Linux命令详解之—tail命令
tail命令也是一个非常常用的文件查看类的命令,今天就为大家介绍下Linux tail命令的用法. 更多Linux命令详情请看:Linux命令速查手册 Linux tail命令主要用来从指定点开始将文 ...
- Linux命令详解之—less命令
Linux下还有一个与more命令非常类似的命令--less命令,相比于more命令,less命令更加灵活强大一些,今天就给大家介绍下Linux下的less命令. 更多Linux命令详情请看:Linu ...
- Linux命令详解之—more命令
Linux more命令同cat命令一样,多用来查看文件内容,本文就为大家介绍下Linux more命令的用法. 更多Linux命令详情请看:Linux命令速查手册 Linux的more命令类似 ca ...
- 【转】linux命令详解:md5sum命令
[转]linux命令详解:md5sum命令 转自:http://blog.itpub.net/29320885/viewspace-1710218/ 前言 在网络传输.设备之间转存.复制大文件等时,可 ...
- Linux命令详解之—cat命令
cat命令的功能是连接文件或标准输入并打印,今天就为大家介绍下Linux中的cat命令. 更多Linux命令详情请看:Linux命令速查手册 Linux 的cat命令通常用来显示文件内容,也可以用来将 ...
- Linux命令详解之—pwd命令
Linux的pwd命令也是一个非常常用的命令,本文为大家介绍下Linux中pwd命令的用法. 更多Linux命令详情请看:Linux命令速查手册 Linux pwd命令用于显示工作目录. 执行pwd指 ...
- Linux命令详解之–cd命令
cd命令是linux实际使用当中另一个非常重要的命令,本文就为大家介绍下Linux中cd命令的用法. 更多Linux命令详情请看:Linux命令速查手册 Linux cd命令用于切换当前工作目录至 d ...
- Linux命令详解之–ls命令
今天开始为大家介绍下Linux中常用的命令,首先给大家介绍下Linux中使用频率最高的命令--ls命令. 更多Linux命令详情请看:Linux命令速查手册 linux ls命令用于显示指定工作目录下 ...
- Linux命令-压缩解压命令:gzip、gunzip
gzip [选项] 源文件名(压缩前) gunzip [选项] 源文件名(压缩后) cd /tmp 切换tmp目录 rm -rf * 强制删除tmp目录下面所有的文件和目录 touch beijing ...
随机推荐
- 【万字长文】使用 LSM-Tree 思想基于.Net 6.0 C# 实现 KV 数据库(案例版)
文章有点长,耐心看完应该可以懂实际原理到底是啥子. 这是一个KV数据库的C#实现,目前用.NET 6.0实现的,目前算是属于雏形,骨架都已经完备,毕竟刚完工不到一星期. 当然,这个其实也算是NoSQL ...
- height,min-height,max-heigth的作用机制问答
1.min-height和height同时存在,子元素高度100%,以哪个高度为准? 答:min-height 2.height存在,子元素高度100%,子元素内容高度大于100%,子元素高度为多少? ...
- 操作表查询&操作表创建&操作表删除&操作表修改
2.操作表 C(create):创建 语法: create table 表明( 列名1 数据类型1, 列名2 数据烈性2, .... 列名n 数据类型n ); create table Student ...
- Redis 哈希Hash底层数据结构
1. Redis 底层数据结构 Redis数据库就像是一个哈希表,首先对key进行哈希运算得到哈希值再取模得到一个下标,每个元素是一个节点,节点之间形成链表.这感觉有点像Java中的HashMap. ...
- 金玉良缘易配而木石前盟难得|M1 Mac os(Apple Silicon)天生一对Python3开发环境搭建(集成深度学习框架Tensorflow/Pytorch)
原文转载自「刘悦的技术博客」https://v3u.cn/a_id_189 笔者投入M1的怀抱已经有一段时间了,俗话说得好,但闻新人笑,不见旧人哭,Intel mac早已被束之高阁,而M1 mac已经 ...
- 使用Typora+EasyBlogImageForTypora写博客,无图床快速上传图片
如今,使用markdown攥写博客已成为主流,而Typora作为markdown的主流工具,广受大众好评,本文讲述从Typora的安装到快速将Typora写好的博文上传到博客园 Typora下载 Ty ...
- 如何在Linux快速搭建一套ADB环境
一.ADB简介 1.什么是ADB Android Debug Bridge,安卓调试桥,它借助adb.exe(Android SDK安装目录platform-tools下),用于电脑端与模拟器或者真实 ...
- 100行代码实现一个RISC-V架构下的多线程管理框架
1. 摘要 本文将基于RISC-V架构和qemu仿真器实现一个简单的多线程调度和管理框架, 旨在通过简单的代码阐明如何实现线程的上下文保存和切换, 线程的调度并非本文的重点, 故线程调度模块只是简单地 ...
- fast json 乱序问题解决过程
解决问题:保存到redis中的jsonstring在转回jsonObject的时候乱序: 解决方案:https://inlhx.iteye.com/blog/2312512 解决过程: 1 看fast ...
- LGV 引理——二维DAG上 n 点对不相交路径方案数
文章目录 引入 简介 定义 引理 证明 例题 释疑 扩展 引入 有这样一个问题: 甲和乙在一张网格图上,初始位置 ( x 1 , y 1 ) , ( x 2 , y 2 ) (x_1,y_1),(x_ ...