libSVM介绍(二)
鉴于libSVM中的readme文件有点长,并且,都是採用英文书写,这里,我把当中重要的内容提炼出来,并给出对应的样例来说明其使用方法,大家能够直接參考我的代码来调用libSVM库。
第一部分,利用libSVM自带的简易工具来演示SVM的两类分类过程。(下面内容仅仅是利用libSVM自带的一个简易的工具供大家更好的理解SVM,假设你对SVM已经有了一定的了解,能够直接跳过这部分内容)
首先,你要了解的是libSVM仅仅是众多SVM实现版本号中的当中之中的一个。而SVM是一种进行两类分类的分类器,在libSVM最新版(libSVM3.1)里面,已经自带了简单的工具,能够对二分类进行演示。以windows平台为例,将libSVM.zip解压之后,有一个名为windows的子目录,里面有一个名为svm-toy.exe的可运行文件。直接双击,运行该可运行文件,显演示样例如以下的界面
点击第二个button“Run”,然后,在左上部分,用鼠标左键随机点几下,代表你选择的第一类模式的数据分布,下图是我随即点了几下的结果:

之后,点击“Change”,接着,用鼠标左键在窗体右下方随便点击几下,代表你选择的第二类模式的数据分布,例如以下图所看到的:
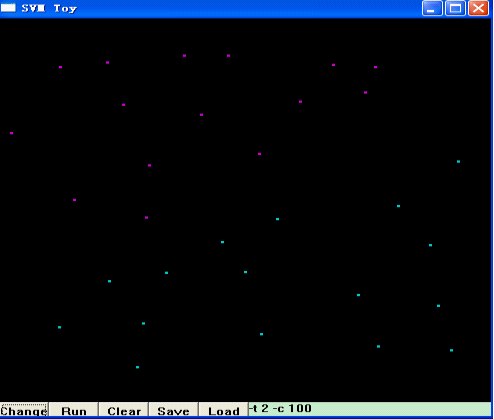
接着,点击“Run”,libSVM就帮你把这两类模式分开了,并用两种不同的颜色区域来代表两类不同的模式,例如以下图所看到的:

图中左上方紫色的区域,是第一类模式所在的区域,右下方的蓝色区域,是你选择的第二类模式所在的的区域,而两者的分界面,也就是SVM的最优分类面。当然,SVM是通过核函数将原始数据映射到高维空间,在高维空间进行线性分类。换句话说,在高维空间,这两类数据应该是线性可分的,即:最优分类面应该是一条直线,而这里看到的,是将高维空间分类的结果又映射回原始空间所呈现的分类结果,即:非线性的分类面。细心的朋友可能已经发现,在上述界面的右下角,有一个编辑框,里面写着“-t 2 -c 100”,显然,这是libSVM的一些參数,你也能够试着更改这些參数,来选择不同的核函数、不同的SVM类型等来达到最好的分类效果。
第二部分:libSVM中的小工具
libSVM中包括下面可运行程序文件(小工具):
(1)svm-scale:一个用于对输入数据进行归一化的简易工具
(2)svm-toy:一个带有图形界面的交互式SVM二分类功能演示小工具;
(3)svm-train:对用户输入的数据进行SVM训练。当中,训练数据是依照下面格式输入的:
<类别号> <索引1>:<特征值1> <索引2>:<特征值2>...
(4)svm-predict:依据SVM训练得到的模型,对输入数据进行预測,即分类。
第三部分:libSVM使用方法介绍:`
libSVM的全部函数申明及结构体定义均包括在libSVM.h文件其中,在使用过程中,你必需要包括该头文件,而且,对libSVM.cpp进行对应的链接。在对libSVM中的函数使用方法进行具体介绍之前,我们最好还是先简单了解一下libSVM.h中一些结构体的含义。
struct svm_node
{
int index;
double value;
};
该结构体,定义了一个“SVM节点”,即:索引i及其所相应的第i个特征值。这样n个同样类别号的SVM节点,就构成了一个SVM输入向量。即:一个SVM输入向量能够表示为例如以下的形式:
类别标签 索引1:特征值1 索引2:特征值2 索引3:特征值3...
我们能够将若干个这种输入向量输入到libSVM进行训练,或者,输入一个类别标签未知的向量对其进行预測。
struct svm_problem
{
int l;
double *y;
struct svm_node **x;
};
该结构体中的l代表训练样本的个数;double型指针y代表l个训练样本中每一个训练样本的类别号,也就是我们常说的“标签”;而"SVM节点"x,则是一个指针的指针(假设你对指针的指针不熟悉,全然能够把x理解为一个矩阵),x所指向的内容就是全部训练样本全部的特征值数据。
假如我们有以下的训练样本数据:
类别标签 特征值1 特征值2 特征值3 特征值4 特征值5
1 0 0.1 0.2 0 0
2 0 0.1 0.3 -1.2 0
1 0.4 0 0 0 0
2 0 0.1 0 1.4 0.5
1 -0.1 -0.2 0.1 1.1 0.1
那么,svm_problem结构体中的l=5(共同拥有5个训练样本),y=[1,2,1,2,1];指针x所指向的内容能够视为5个行向量,每一个行向量有5列,即:x指代一个5*5的矩阵,其值为:
(1,0)(2,0.1)(3,0.2)(4,0)(5,0)(-1,?)
(1,0)(2,0.1)(3,0.3)(4,-1.2)(5,0)(-1,?)
(1,0.4)(2,0)(3,0)(4,0)(5,0)(-1,?)
(1,0)(2,0.1)(3,0)(4,1.4)(5,0.5)(-1,?)
(1,-0.1)(2,-0.2)(3,0.1)(4,1.1)(5,0.1)(-1,?)
须要提醒的是,这里,每一行最后一列都是以“-1”开头,这是libSVM规定的特征值向量的结束标识;此外,索引应该依照升序方式进行排列。
enum { C_SVC, NU_SVC, ONE_CLASS, EPSILON_SVR, NU_SVR };//libSVM规定的SVM类型
enum { LINEAR, POLY, RBF, SIGMOID, PRECOMPUTED };//libSVM规定的核函数的类型
struct svm_parameter
{
int svm_type;//取值为前面提到的枚举类型中的值
int kernel_type;//取值为前面提到的枚举类型中的值
int degree; //用于多项式核函数/
double gamma;//用于多项式、径向基、S型核函数
double coef0;//用于多项式和S型核函数
/* 下面參数只用于训练阶段 */
double cache_size; //核缓存大小,以MB为单位
double eps; //误差精度小于eps时,停止训练
double C; //用于C_SVC,EPSILON_SVR,NU_SVR
int nr_weight; //用于C_SVC
int *weight_label;//用于C_SVC
double* weight;//用于C_SVC
double nu;//用于NU_SVC,ONE_CLASS,NU_SVR
double p;//用于EPSILON_SVR
int shrinking; //等于1代表运行启示式收缩
int probability;//等于1代表模型的分布概率已知
};
该结构体定义了libSVM中的用到的SVM參数。当中svm_type能够是C_SVC, NU_SVC, ONE_CLASS, EPSILON_SVR, NU_SVR中的随意一种,代表着SVM的类型;
C_SVC: C-SVM classification
NU_SVC: nu-SVM classification
ONE_CLASS: one-class-SVM
EPSILON_SVR: epsilon-SVM regression
NU_SVR: nu-SVM regression
kernel_type能够是LINEAR, POLY, RBF, SIGMOID中的一种,代表着核函数的类型;
LINEAR: u'*v,线性核函数;
POLY: (gamma*u'*v + coef0)^degree,多项式核函数;
RBF: exp(-gamma*|u-v|^2),径向基核函数;
SIGMOID: tanh(gamma*u'*v + coef0),S型核函数;
PRECOMPUTED: kernel values in training_set_file,自己定义的核函数;
nr_weight, weight_label, and weight这三个參数用于改变某些类的惩处因子。当输入数据不平衡,或者误分类的风险代价不正确称的时候,这三个參数将会对样本训练起到很重要的调节作用。
nr_weight是weight_label和weight的元素个数,或者称之为维数。Weight[i]与weight_label[i]之间是一一相应的,weight[i]代表着类别weight_label[i]的惩处因子的系数是weight[i]。假设你不想设置惩处因子,直接把nr_weight设置为0就可以。
为了防止错误的參数设置,你还能够调用libSVM提供的接口函数svm_check_parameter()来对输入參数进行检查。
在使用libSVM进行分类之前,你须要通过样本学习,构建一个SVM分类模型。该分类模型也能够理解为生成一些用于分类的“数据”。当然,构建的分类模型须要保存为文件,以便兴许使用。用于libSVM训练的函数,其申明例如以下所看到的:
struct svm_model *svm_train(const struct svm_problem *prob, const struct svm_parameter *param);
显然,该函数的输入,就是svm_problem结构体的prob指针所指向的内容。该结构体在前面已经介绍过,其内部,不仅包括了训练样本的个数,还包括每一个训练样本的“标签”及该训练样本相应的特征数据。而svm_parameter类型的param指针则指定了libSVM所用到的诸如SVM类型,核函数类型,惩处因子之类的參数。另外,该函数的返回值是一个svm_model结构体,该结构体的定义,在libSVM.cpp其中:
struct svm_model
{
svm_parameter param; //SVM參数设置
int nr_class; //类别数量,对于regression和ne-class SVM这两种情况,该值为2
int l; //支持向量的个数
svm_node **SV; //支持向量
double **sv_coef; //用于决策函数的支持向量系数
double *rho; //决策函数中的常数项
double *probA; // pariwise probability information
double *probB;
// for classification only
int *label; // 每一个类类别标签
int *nSV; //每一个类的支持向量个数
int free_sv; //假设svm_model已经通过svm_load_model创建,则该值为1;假设svm_model是通过svm_train创建的,该值为0
};
须要提醒的是,libSVM支持多类分类问题,当有k个待分类问题时,libSVM构建k*(k-1)/2种分类模型来进行分类,即:libSVM採用一对一的方式来构建多类分类器,例如以下所看到的:
1 vs 2, 1 vs 3, ..., 1 vs k, 2 vs 3, ..., 2 vs k, ..., k-1 vs k。
用户在得到SVM分类模型之后,须要将其进行保存。在这里,libSVM已经提供了对应的函数接口:
int svm_save_model(const char *model_file_name, const struct svm_model *model);
在调用训练函数之后,仅仅须要指定保存位置,直接调用该函数,就能够进行对应的保存。
在对样本进行训练得到分类模型之后,就能够利用该分类模型对未知输入数据进行类别推断了,也就是我们常说的“预測”。用于libSVM预測的函数,其申明例如以下所看到的:
double svm_predict(const struct svm_model *model, const struct svm_node *x);
该函数的第一个參数就是利用样本训练得到的SVM分类模型,第二个參数,是输入的未知模式的特征数据,即:得到了表征某一类别的特征数据,依据这些数据,来推断它所相应的类别标签。而SVM分类模型,能够由libSVM定义的以下这个接口函数来进行载入:
struct svm_model *svm_load_model(const char *model_file_name);
此外,在使用上述函数过程中,须要对svm_model及svm_parameter申请内存,而不使用它们的时候,用户须要调用下面两个函数进行内存释放:
void svm_destroy_model(struct svm_model *model);
void svm_destroy_param(struct svm_parameter *param);
libSVM介绍(二)的更多相关文章
- Lucene.Net 2.3.1开发介绍 —— 二、分词(六)
原文:Lucene.Net 2.3.1开发介绍 -- 二.分词(六) Lucene.Net的上一个版本是2.1,而在2.3.1版本中才引入了Next(Token)方法重载,而ReusableStrin ...
- Lucene.Net 2.3.1开发介绍 —— 二、分词(五)
原文:Lucene.Net 2.3.1开发介绍 -- 二.分词(五) 2.1.3 二元分词 上一节通过变换查询表达式满足了需求,但是在实际应用中,如果那样查询,会出现另外一个问题,因为,那样搜索,是只 ...
- Lucene.Net 2.3.1开发介绍 —— 二、分词(三)
原文:Lucene.Net 2.3.1开发介绍 -- 二.分词(三) 1.3 分词器结构 1.3.1 分词器整体结构 从1.2节的分析,终于做到了管中窥豹,现在在Lucene.Net项目中添加一个类关 ...
- Lucene.Net 2.3.1开发介绍 —— 二、分词(四)
原文:Lucene.Net 2.3.1开发介绍 -- 二.分词(四) 2.1.2 可以使用的内置分词 简单的分词方式并不能满足需求.前文说过Lucene.Net内置分词中StandardAnalyze ...
- Lucene.Net 2.3.1开发介绍 —— 二、分词(二)
原文:Lucene.Net 2.3.1开发介绍 -- 二.分词(二) 1.2.分词的过程 1.2.1.分词器工作的过程 内置的分词器效果都不好,那怎么办?只能自己写了!在写之前当然是要先看看内置的分词 ...
- Lucene.Net 2.3.1开发介绍 —— 二、分词(一)
原文:Lucene.Net 2.3.1开发介绍 -- 二.分词(一) Lucene.Net中,分词是核心库之一,当然,也可以将它独立出来.目前Lucene.Net的分词库很不完善,实际应用价值不高.唯 ...
- {Django基础十之Form和ModelForm组件}一 Form介绍 二 Form常用字段和插件 三 From所有内置字段 四 字段校验 五 Hook钩子方法 六 进阶补充 七 ModelForm
Django基础十之Form和ModelForm组件 本节目录 一 Form介绍 二 Form常用字段和插件 三 From所有内置字段 四 字段校验 五 Hook钩子方法 六 进阶补充 七 Model ...
- MySQL之多表查询一 介绍 二 多表连接查询 三 符合条件连接查询 四 子查询 五 综合练习
MySQL之多表查询 阅读目录 一 介绍 二 多表连接查询 三 符合条件连接查询 四 子查询 五 综合练习 一 介绍 本节主题 多表连接查询 复合条件连接查询 子查询 首先说一下,我们写项目一般都会建 ...
- MySQL行(记录)的详细操作一 介绍 二 插入数据INSERT 三 更新数据UPDATE 四 删除数据DELETE 五 查询数据SELECT 六 权限管理
MySQL行(记录)的详细操作 阅读目录 一 介绍 二 插入数据INSERT 三 更新数据UPDATE 四 删除数据DELETE 五 查询数据SELECT 六 权限管理 一 介绍 MySQL数据操作: ...
- {MySQL完整性约束}一 介绍 二 not null与default 三 unique 四 primary key 五 auto_increment 六 foreign key 七 作业
MySQL完整性约束 阅读目录 一 介绍 二 not null与default 三 unique 四 primary key 五 auto_increment 六 foreign key 七 作业 一 ...
随机推荐
- ElasticSearch vs 关系型数据库
它们之间的关系,如下图所示.
- vue中computed与watch的异同
一.computed 和 watch 都可以观察页面的数据变化.当处理页面的数据变化时,我们有时候很容易滥用watch. 而通常更好的办法是使用computed属性,而不是命令是的watch回调. ...
- scrollwidth ,clientwidth ,offsetwidth 三者的区别
clientwidth:内容可视区域的宽度 offsetwidth:元素整体宽度 scrollwidth:实际内容的宽度
- chkconfig---检查设置系统服务
chkconfig命令 chkconfig命令检查.设置系统的各种服务.这是Red Hat公司遵循GPL规则所开发的程序,它可查询操作系统在每一个执行等级中会执行哪些系统服务,其中包括各类常驻服务 ...
- chattr---文件隐藏属性
- type---显示指定命令的类型
type命令用来显示指定命令的类型,判断给出的指令是内部指令还是外部指令. 命令类型: alias:别名. keyword:关键字,Shell保留字. function:函数,Shell函数. bui ...
- 【2017 Multi-University Training Contest - Team 5】Rikka with Competition
[Link]: [Description] [Solution] 把所有人的能力从大到小排; 能力最大的肯定可能拿冠军; 然后一个一个地往后扫描; 一旦出现a[i-1]-a[i]>k; 则说明从 ...
- ZOJ 3524 Crazy Shopping
Crazy Shopping Time Limit: 3000ms Memory Limit: 65536KB This problem will be judged on ZJU. Original ...
- 洛谷——P1307 数字反转
https://www.luogu.org/problem/show?pid=1307#sub 题目描述 给定一个整数,请将该数各个位上数字反转得到一个新数.新数也应满足整数的常见形式,即除非给定的原 ...
- 思科模拟器之路由器-RIP-DNS解析server
思科三层交换机之下的局域网搭建,请看这. 接下来将解说怎样通过路由器的RIP协议来连接多个局域网. 并设置DNSserver. 1.路由器RIP配置 RIP协议有个非常致命的缺点:就是它是依据路径长短 ...