C++常用数据结构的实现
常用数据结构与算法的实现、整理与总结
我将我所有数据结构的实现放在了github中:Data-Structures-Implemented-By-Me
KMP字符串匹配算法
有时候我们需要在一大段字符串中得到找到我们想要的位置,这个时候KMP字符串匹配算法是一种比较好的选择。
首先我们需要进行匹配字符串的预处理,即我们要在一个字符串中找另外一个字符串,我们需要预处理这个字符串。主要是查看这个字符串上有没有“最长公共子序列”。最长公共子序列是是KMP算法的核心概念。这决定了我们一位位向前移动匹配的时候,如果遇到匹配失败的我们应该如何处理,是整个匹配字符串向前挪动一位吗,其实不是挪动一位,只要我们可以知道最长公共子序列,那么我们就可以直接在比较发现不匹配之后,移动一个更大的距离,而不是一格,继续比较。而我们所说的那个“更大的距离”,就是由“最长公共子序列”决定的,我们需要知道,在已经匹配到的子字符串两头最大的公共部分是多少,下次比较的时候我们直接在匹配失败的时候把最大公共部分的前面那部分平移过来,前面那一部分最长公共子序列的下一位开始比较。
预处理还是很简单的:
//我们首先先进行预处理,需要delete这个堆区数组int *pre_handle_arr = pre_handle(patch_string);//然后进行比较int compare_continue = -1;int patch_string_index = 0;int goal_string_index = 0;//退出这个循环主要是两种情况,首先就是目标字符串走完了,还有就是要匹配别人的小字符串走完了,前者代表失败,后者代表成功while(patch_string_index < patch_string.length() && goal_string_index < goal_string.length()){if(patch_string[patch_string_index] == goal_string[goal_string_index]){compare_continue = pre_handle_arr[patch_string_index];patch_string_index++;goal_string_index++;}else{//如果没有匹配成功,并且这个时候compare_continue是-1,说明在已匹配子串中没有最大公共子序列//那么我们直接匹配目标字符串的下一位if(compare_continue == -1){goal_string_index++;patch_string_index = 0;}else{//如果在某一位匹配失败,并且有公共子序列,那么就利用公共子序列,将公共子序列的前半部分向前挪到后半部分的位置patch_string_index = compare_continue + 1;compare_continue = pre_handle_arr[compare_continue];// cout << patch_string_index << "," << compare_continue << endl;}}// cout << patch_string_index << "," << goal_string_index << endl;}
道理很简单,除了第一位,每一位的字符都要和tmp+1这个位置的字符比对一下。如果相等,那么就可以说明最大公共子字符串又扩充了一位。
在逻辑上比较繁琐的就是进行字符串比较的那个过程,有点绕:
//我们首先先进行预处理,需要delete这个堆区数组int *pre_handle_arr = pre_handle(patch_string);//然后进行比较int compare_continue = -1;int patch_string_index = 0;int goal_string_index = 0;//退出这个循环主要是两种情况,首先就是目标字符串走完了,还有就是要匹配别人的小字符串走完了,前者代表失败,后者代表成功while(patch_string_index < patch_string.length() && goal_string_index < goal_string.length()){if(patch_string[patch_string_index] == goal_string[goal_string_index]){compare_continue = pre_handle_arr[patch_string_index];patch_string_index++;goal_string_index++;}else{//如果没有匹配成功,并且这个时候compare_continue是-1,说明在已匹配子串中没有最大公共子序列//那么我们直接匹配目标字符串的下一位if(compare_continue == -1){goal_string_index++;patch_string_index = 1;}else{//如果在某一位匹配失败,并且有公共子序列,那么就利用公共子序列,将公共子序列的前半部分向前挪到后半部分的位置patch_string_index = compare_continue + 1;compare_continue = pre_handle_arr[compare_continue];//cout << patch_string_index << "," << compare_continue << endl;}}// cout << patch_string_index << "," << goal_string_index << endl;}
首先我们要注意循环的条件,必须两个string都没有遍历完才可以进行循环,两个之中有其中一个遍历完了就不可以循环了。
我们主要使用patch_string_index和goal_string_index两个索引分别遍历匹配小字符串和目标字符串。如果相等,当然是这两个索引都会自增,然后比较目标字符串和匹配小字符串的下一位。如果发现不匹配了,首先就要看看以匹配的子串里面有没有最大公共子字符串(使用compare_continue==-1)。如果没有,那么直接使用匹配字符串的第0位去匹配,目标字符串的下一位就好了(patch_string_index=0赋值,goal_string_index自增)。如果发现有最大公共子字符串那就让最大公共子字符串的后一位去匹配目标字符串的当前位置。所以对于比较的结果,一共是三类情况。
环状队列
因为队列只能从尾部加入,从顶部移出,所以我们使用传统数组的方式会有问题,因为随着头部内容的不断移出以及尾部的不断移进,整个队列会逐渐往线性表的后部靠拢,这样子在线性表的前半部分就会有很大的空间浪费。如果要把已经贴近后半部分的内容挪到靠近线性表头部的位置,这就需要大量的开销,所以我们就需要换装队列。
环状队列本质上还是线性表,通过取模的操作获得环状的效果。
环状队列比较什么时候满的时候我们,除了可以维护一个存储了环状队列当前容量的变量之外还可以预留一个空位置。为了统一我们的逻辑,我们必须设定一套在所有的时期都适用的判定环状队列空或者满的办法。我们设定头指针与尾指针重合代表空,尾索引取模如果比头索引取模之后小1,或者比头索引大maxsize-1那么就说明队列已经满了。rear永远指向没有值的下一个要插入的位置,头索引永远指向下一个要推出的值,除非队列是空的。
这次实现中使用了模板类,因为模板类不是类,所以模板类是不能拆的,应该放在一个头文件中,要不就会报错。此外我们就是要注意取模和边界条件。这样子就可以了。总体的实现还是比较简单的。
走迷宫算法
走迷宫算法是一个对栈结构的非常不错的利用,我们我们通过一个栈来获得我们已经走过的路径,如果栈顶的节点在所有方向上都走不通,那就进行弹栈操作。在倒数第二个节点上进行各个方向的尝试。任何曾经进过栈的节点都会被记录下来,防止走重复的路。
这里在编程里面碰到了一些问题,比如在C++11中,我们发现枚举和结构体实例化的时候我们不再需要在前面再加struct和enum这两个关键词。直接当做一个类使用就好了。
此外我们发现int a[][],实际上a变量这个时候并不是一个二维指针,而是一个数组对象,所以说我们没有办法把他当做一个二维指针使用。其实使用栈空间来申请二维数组,获取其二维指针的方式并不是没有,但是比较困难,并且语法比较容易混淆,所以我们使用new的方式产生线性数组,以及指针数组来产生二维数组。
在if和while条件上我也出现了不止一次的错误,注意非(!)与或等运算符组合起来的关系。
还要注意的是,枚举是一种常量,不能进行自增操作。
中缀表达式转后缀表达式
这也是一个使用栈的经典案例,我们使用栈来保存符号,而变量字符会被直接输出。符号一共有6种,加、减、左右小括号,乘除。而这个“符号栈”的入栈和出栈规则如下:
- 符号是有优先级的,正常情况下,符号会一位一位进入栈中,如果碰到了一个运算符,不比栈顶运算符的优先级小,那么这个运算符就要正常入栈。
- 出栈的策略非常简单,如果整个表达式走完了就把所有的符号弹出并且输出,如果表达式没有走完,但是有一个比栈顶运算符优先级小的运算符要入栈,那就先要将栈中的所有元素推出。
- 括号的处理也很重要,一般情况下,左括号我们直接入栈就好,遇到右括号,那么我们就需要我们将右括号与左括号之间的弹栈就好。左括号了右括号不会出现在后缀表达式中。
环装链表
环装链表。环装链表主要就是链表的最后一个元素的next指针会指向链表的头部。
首先是数据成员的设计,在实践过程中发现,环装链表最好不要使用first指针,使用last指针才是比较正确的。因为使用first指针的时候如果我们需要在链表的头部增加节点,那么最后一个节点的next指针要指向新的头部。那这就涉及到一个问题,我们怎么自能让最后一个节点的指针指向新的头部,如果我们只有first指针,那么我们只能遍历整个链表,然后去修改最后一个节点的next指针,这样子开销很大。
所以在环形链表中应该使用last指针,last指针指向链表的最后一个节点,这样子无论从链表的头部开始尾部添加元素都会变得比较简单。
另外我们发现在模板中,我们不能为形参设定缺省值。另外加在头部和尾部的节点也要在逻辑上单独处理。
在删除节点的过程中,我们对于最后一个节点的删除要尤其注意,因为删除最后一个节点之后,我们要重新定位last,所以我们需要单独处理,需要单独记录一下倒数第二个节点的指针,以便让last指针定位。
最后在说一下析构函数,析构函数就是不断执行链表第一个元素的删除操作就好了。
双向链表
当我们需要向头尾两个方向遍历的时候我们就需要双向链表了,为了体现双向链表的优势,我们打算实现goleft、goright、addleft、addright、deleteleft、deleteright,这几个函数,主要的工作就是让一个指针不断在链表中移动,可以理解为是双向链表这个对象和迭代器的结合体。
其实在实现链表的时候书上一直都建议使用空头部节点的设计,这种方式有很多的好处,可以统一逻辑,减少边界条件的判断。在双向链表的实现中我们也使用这种被推荐的设计。此外我们依旧要实现一个换装双向链表。
这里唯一要注意的问题就是这个空白的头结点的左右指针怎么指,为了保证在遍历链表的过程中,让左边最边上一个元素的在往左边走就是空白头结点,而空白头结点再往左边走是右边第一个节点,这样子循环起来。我们需要精心设计空白头结点的通往左节点的指针和右节点的指针。
有关于双向链表的初始化问题比较有一起,比较精妙的设计是初始化一个空白的头结点,然后让这个空白头结点的左右节点指针全部指向自己,这样子做的好处就是可以统一所有的关于插入和删除节点的逻辑。并且上文所说的头结点左右指针的“精心设计”也可以和一般节点的逻辑统一起来。
意外因为头结点比较重要最好不要删除,所以我们在删除的时候会弹出警告。
这样子双向链表就完成了。
树
二叉树
树是一种非常重要的数据结构,二叉树更是重中之重。我们可以知道。使用数组来表示一个二叉树是一个非常容易的事情。我们从数组的1号位置开始记录,我们在1号位置存储的是树的根。对于一个深度为k的数组来说,我们最多可以容纳2^k-1个元素。
我们使用数组对二叉树进行了实现,对于i号元素来说,他的左节点就在i*2处,右节点在i*2+1处。我们知道在此基础之上注意数组溢出的问题就可以了。
子树的删除使用的是递归程序,在删除子树的根节点之后我们知道再去删除子树的左右节点就可以了。
二叉树的数组实现对于完全二叉树来说是一种比较简单合适的解法,但是如果是不太完全的二叉树,那么就会出现空间的浪费,所以使用二叉树的链表表示更为合适。
此外我们还进行了树的链表表示,链表表示的难点就是析构的部分,我觉得使用一种合理的遍历方式就可以进行析构。
树的广度优先搜索
树的链表形式在析构的时候需要广度优先搜索,广度优先搜索的最需要的就是队列这样一个结构,我们首先将根节点放在队列中,我们析构在队列头部的节点,如果这个节点有子女,那么子女也会全部加入在队列尾部。通过不断析构头部元素,当队列为空的时候就代表整个树的析构就完成的。
二叉树的遍历
二叉树有三种常见的遍历方式,分别是前序遍历、中序遍历、后序遍历。具体的遍历方式和这个名字是一样的。遍历的过程是一种递归算法,三种遍历方式区别就是每一次递归子树根节点扫描的次序。如果是前序遍历那扫描的顺序就是“打印根->递归左子树->递归右子树”;如果是中序遍历,那扫描的顺序就是“递归左子树->打印根节点->递归右子树”;如果是后序遍历,那么扫描的顺序就是“递归左子树->递归右子树->打印根节点”。这样子就完成了扫描。
因为我们的二叉树一共提出了两种实现,一种是链表方式,一种是数组方式。所以我们打算为这两种实现的类设定一个基类。这个基类也是一个模板类,所有函数和操作和我们的两种实现一样,我们利用多态,以及虚函数,来保证他们的基类就是前序遍历、中序遍历、后序遍历的形参。
这里稍微提一下C++语法的事情。首先基类的析构函数必须是虚函数。我们知道派生类的构造函数会默认调用基类的缺省构造函数,派生类的析构函数也会调用基类的析构函数。这种特性注定了我们基类的析构函数首先必须是虚函数,并且不能是纯虚函数,因为派生类的析构会用上。
但是我们发现使用外部函数传入Tree类型形参的方式没法很好地进行递归操作。因为一个是链表一个是数组,逻辑没有办法统一。
所以我们使用成员函数的方式对Tree进行遍历。使用两套不一样的逻辑。这里我们对数组二叉树的遍历进行实现。
二叉树的非递归遍历
二叉树而非递归遍历可以节省更多内存占用,我们可以通过使用一个栈来进行前、中、后序遍历。
先说一下非递归的前序遍历,我们的主要思路就是不断将子树的根节点放入栈中,并打印根节点。然后让遍历的指针往左子树不停走。也就是根节点在入栈的时候就要打印,然后当已经没有左节点可以再走的时候,我们就可以进行弹栈操作了,弹栈之后就去看右子树。
然后是非递归的中序遍历,我们还是先不断让根节点入栈,然后不断向左节点移动。中序遍历是在弹栈的时候进行打印。弹栈之后看右子树。
后序遍历是最麻烦的非递归遍历方式。主要就是子树的根会最早进栈,并且在子树的根的右子树还没有遍历的时候,不会出栈,出栈打印。
面对栈的状态我们可以很清楚地知道,前序遍历和中序遍历的栈中右子树节点对应的父节点是不会出现在栈中的,二者的区别主要是栈中元素的打印时间不一样,一个是在入栈,一个是在出栈。后序遍历栈中元素会多一些,因为根节点和右子树的根节点全部都会出现在栈中。
我们在链表二叉树中进行了非递归遍历的实现。
首先是后序遍历,这个遍历的我们需要有“几个注意”,因为是非递归的,所以我们需要对整个的遍历顺序过程极为了解,我们整体遍历的趋势应该是首先“一口气向左子树走到底”,在这过程中,所有的根节点一直入栈,直到“左不下去”了然后弹栈,弹栈的时候要看看栈中的节点有没有有没有右子树,如果有右子树,要优先进入右子树的遍历,也是在右子树中“一口气左到底”,然后不断入栈。在非递归的后序遍历算法中,入栈和出栈都是一种正反馈的过程,只要入栈就会一口气让一串左子树入栈,只要出栈,除非碰到栈顶元素有右子树(右子树会入栈,然后因为正反馈,会让右子树的所有左子树全部入栈),要不弹栈就不会停。
在这个算法的实现中我们需要两个额外空间,一个是栈,一个是标记栈中节点的右子树有没有被遍历的数组。
template<class T>void LinkedBTree<T>::post_order() {//我们进行后序遍历,首先创建一个栈空间。//栈空间存放树的节点now = root;LinkedBItem<T> **stack = new LinkedBItem<T> *[100];//索引从-1开始,指向当前的栈顶int stackIndex = -1;//我们建立一个数组,主要是为了查看栈中节点的有没有右子树需要遍历,如果已经被遍历了,那就可以安心弹栈,如果没有被遍历//那就只能只能再把右节点压栈。压栈是一个"正反馈"的过程,一旦出现了压栈,那就会一压到底,不断向左节点走,直到不能再压//一旦压到不能再压,那就会进入弹栈程序,弹栈主要做的就是检查当前节点的右子树。int *hasScanRight = new int[100];//初始化数组for (int i = 0; i < 100; ++i) {hasScanRight[i] = 0;}//首先我们先让根节点入栈,然后触发"入栈正反馈",直到now是空指针为止stack[++stackIndex] = root;if (root->right != 0) {hasScanRight[stackIndex] = 1;}while (stackIndex != -1) {now = stack[stackIndex];while (now->left != 0) {stack[++stackIndex] = now->left;//入栈之后查看右节点的情况,然后修改那个查看右子树是不是已经被遍历的数组if (stack[stackIndex]->right != 0) {hasScanRight[stackIndex] = 1;}now = now->left;}//当完成"入栈正反馈"之后,我们就可以弹栈过程,弹栈的时候我们就可以看看是不是右子树有没有东西while (stackIndex != -1 && hasScanRight[stackIndex] == 0) {//如果右子树没有东西,那就进入正常的弹栈过程,弹栈也是一个正反馈过程如果,如果一直右子树没有东西,就可以一直弹cout << stack[stackIndex]->element << " , ";stackIndex--;}//从这个while中出来有两种情况,一种就是发现右子树还在的,一种就是stack已经空了if (hasScanRight[stackIndex] == 1) {//如果右子树有东西,那么我们就要进行新一轮的压栈操作,压栈的之后还要看看新入栈的节点有没有右子树stack[stackIndex + 1] = stack[stackIndex]->right;//右节点已经入栈,修改hasScanRight数组hasScanRight[stackIndex] = 0;stackIndex++;if (stack[stackIndex]->right != NULL) {hasScanRight[stackIndex] = 1;}}}cout << endl;//析构申请的资源delete[]stack;delete[]hasScanRight;}
然后我们实现前序遍历和中序遍历,这两种遍历方式的实现基本是一样的,除了栈中元素打印的时间不一样。前序遍历的主要工作就是在子树根节点入栈的时候打印树节点内容。当已经没有左子树根节点可以入栈的时候,我们进行出栈过程,出栈过程也是一个正反馈的过程,只有当当前节点有右子树的时候才会停止,但是当前节点也会被弹出。此时,新发现的右子树会入栈并打印自身,然后又是一系列的“正反馈入栈”。整个过程讲以stack全部弹出并且没有新的节点加入画上一个句号。
template<class T>void LinkedBTree<T>::pre_order() {//前序遍历也需要一个树节点指针的栈区LinkedBItem<T> **stack = new LinkedBItem<T> *[100];//栈索引从-1开始int stackIndex = -1;now = root;//然后我们让根节点进入栈stack[++stackIndex] = root;cout << stack[stackIndex]->element << " , ";//然后开始前序遍历,栈不为空,遍历就继续while (stackIndex != -1) {//如果栈顶元素有左子树,激活入栈正反馈now = stack[stackIndex];//如果栈顶元素没有左子树了那就不用再压栈了while (now->left != 0) {stack[++stackIndex] = now->left;cout << stack[stackIndex]->element << " , ";now = now->left;}//到这里,栈顶元素就是没有左子树的二叉树节点了,我们弹栈,并且查看右子树,如果要弹栈的元素有右子树,那么在弹栈之后把右子树加入//弹栈也是一个正反馈的过程,直到弹空或者发现当前栈顶节点有右子树(此时当前节点也会被弹出)while (stackIndex != -1) {//如果发现当前节点有右子树,那就停止弹栈,但是当前节点也会弹出if (stack[stackIndex]->right != 0) {//进行最后一次弹栈stackIndex--;//然后将右子树加入栈中stack[stackIndex + 1] = stack[stackIndex + 1]->right;stackIndex++;//入栈要打印cout << stack[stackIndex]->element << " , ";//结束循环,回到外层循环顶部进行正反馈入栈,入栈会激活新的入栈break;} else {//当前节点没有右子树直接弹栈,并且如果一直没有右子树,那就一直弹,也是正反馈stackIndex--;}}}cout << endl;//空间回收delete[]stack;}
中序遍历和前序遍历的代码基本上一致,就是打印节点的时机不一样。
template<class T>void LinkedBTree<T>::in_order() {//创造一个栈LinkedBItem<T> **stack = new LinkedBItem<T> *[100];//栈顶索引int stackIndex = -1;//根节点入栈stack[++stackIndex] = root;while (stackIndex != -1) {now = stack[stackIndex];//触发入栈正反馈while (now->left != 0) {stack[++stackIndex] = now->left;now = now->left;}//现在栈顶节点已经没有左子树了//我们可以出栈了while (stackIndex != -1) {//只要没有右子树出现,那就一直执行出栈操作//出现右子树,弹出当前节点,加入右子树根节点if (stack[stackIndex]->right != 0) {//打印当前节点cout << stack[stackIndex]->element << " , ";//将当前节点换成右子树根节点stack[stackIndex] = stack[stackIndex]->right;//退出循环,并且进入外层循环的左子树入栈过程break;} else {//没有右子树,那就一直弹栈cout << stack[stackIndex]->element << " , ";stackIndex--;}}}cout << endl;delete[]stack;}
胜者树与败者树
当我们需要进行多路已排序的数组按照顺序合并的时候,我们需要使用胜者树和败者树。我觉得这两种树实际上性能一样,只是败者树的我们把一个节点拿到之后,新的节点会进入处在叶子节点的缓冲区,新来的节点不用和兄弟节点比较来进行树的重构,而是可以直接和父节点比较来进行重构。我们每次和父节点比较就好了,比如比父节点要优先,那就继续像父节点的父节点比较,如果不比父节点优先,那就把这个值留在原地,父节点代替他不断向上比较。下面胜者树和败者树的结构。

这个是胜者树的结构,这个是一个完全树,所以可以使用数组来进行表示。我们在堆这个结构中用过这种结构。败者树比胜者树多一个节点,也就是数组表示的第0位。

这个是败者树,这个树的结构会比较奇怪,非叶节点存的数两个子树中“胜者的败者”。这就使得我们进行树重构的时候我们只要进行和父节点的比较就好了。重构的策略在上文已经提到。
在树中我们可以看到两类节点,一类是方块表示的缓冲区,存的是每一个归并队列第一个值的方块节点,还有就是记录着队列编号的圆形节点,这个节点表示了是当前哪个队列的节点在这个树里面。我们相信这是一种节省空间的方式。
我们在败者树中设计两个数组,一个是树的数组,一个是缓冲区的数组,两个数组的大小都和要归并的队列数量一样。败者树的构造是基于胜者树去做的,首先先使用buffer里面的值构造出胜者树,然后我们将胜者树的根节点复制到根节点的父节点上面,然后我们自上到下进行败者树改造,从根节点开始,将父节点两个子节点中和父节点不一样的节点复制到父节点上。
缓冲区存的是真正的键值对。非叶节点里面存的是键值对在缓冲区数组的索引号。为了方便实现,我们必须做一个东西来保证父节点可以被找到。我们可以认为这个缓冲区是接在树的数组后面的,这样子就好办很多。我们可以实现一个向父节点或者向儿子节点移动的算法,因为树的最后一层非叶节点指向的节点在另外一个数组中。更简单地说,我们可以认为这个非叶节点数组后面的索引就是一段连续数字,比如说上面这个例子,数组的值就是:[3、1、0、2、4]其实后面还隐藏了[0,1,2,3,4],总共就是[3,1,0,2,4,0,1,2,3,4]。所以说我们要做的就是当我们发现,比如4的后继索引应该是8,但是8明显已经超过了范围,所以我们就让8-非叶节点数组大小就可以了,这样子不用查就可以直接算出3,所以说为什么我们申请数组的时候后面“隐藏”的东西我们没有放到数组里,就是因为后面的值很规律,使得这是我们可以算出来的。
我们要记住一个非常精辟的操作:
int LostTree::getBufferIndex(int treeIndex) {if (treeIndex <= mergeSize - 1) {return indexLeaf[treeIndex];} else {//这是叶节点,没有存在于非叶节点数组中,这里推算return treeIndex - mergeSize;}}
缓冲区和非叶节点在两个数组,但是这个函数统一了逻辑,我们可以找到任何叶节点、包括非叶节点的缓冲区索引,这个索引我们既可以取里面的key去做比较,也可以单纯比较索引的值来看两个树节点对应的key是不是用一个。
弹出旧的节点然后插入新的节点。我们申请两个临时变量,都是索引。一个是Buffer索引,一个是非叶索引。buffer索引指的是不断向上比较的key,非叶索引指向的是被比较的非叶节点。buffer索引指向的key是不会出现的非叶节点中的。如果我们发现要往上爬的节点优先级比被比较的节点低,那么就把非叶索引给buffer索引,让父节点继续向上走。这个过程有点像毛毛虫在移动。
在子节点没有祖先节点大。那么我们就要把buffer索引放到放到树节点中,然后把buffer索引指向树节点中存的以前的索引(所以我们需要使用一个变量把树节点中以前的索引存下来)。然后将被比较的树非叶节点索引向上移动。
对于重构的边界条件的设定也要处以,我们的重构在根节点处就要特殊处理,根节点的父节点更要单独处理。
ALV树
这也是一种平衡树的实践,首先是一种2叉树,和B+树的平衡方式不同的是,ALV树在每个节点上存储一个叫做“平衡因子”的变量来控制平衡。ALV树要求左子树和右子树的差不多高,相差不能超过2。而B树的所有子树是完全平衡的,这就是不同。
ALV树使用我们在红黑树中常见的旋转操作,用来在插入和删除中平衡,而B树和B+树的插入过程使用的是拆分操作,删除过程用的是合并和旋转操作。从这一点来看,ALV树会好实现很多。毕竟只涉及旋转。
当我们将一个节点插入到ALV树中的时候(插入的过程就是二叉查找树),我们要不断检查父节点,看看有没有出现不平衡的情况。实际上我们也可以使用一个递归insert,在insert之后解决不平衡的问题。
一般是因为出现4中情况:
- 对A节点的左儿子的左子树执行一次插入操作
- 对A节点的左儿子的右子树执行一次插入操作
- 对A节点的右儿子的左子树执行一次插入操作
- 对A节点的右儿子的右子树执行一次插入操作
其中,1、4我们归成一类,称作“左左”和“右右”。这类情况是比较好处理的,我们对a做一次左旋或者右旋就好了。右旋就是加大右侧的高度,左旋就是加大左侧的高度。然后我们随机应变就好了。
另外,2、3又是一类,“左右”和“右左”。这个需要两次旋转,对于“左右”来说,需要在左子树上面执行一次左旋,变成“左左”,然后按照“左左”来处理。
值的一提的是,虽然在前文给的链接中,我们是不断检查插入位置为父节点一路往上,看看有没有出现不平衡的,但是实际上我认为出现不平衡的节点只有可能在爷爷节点和或者曾爷爷节点上,这是我个人的意见。但是为了以防万一,还是一路向上进行检查吧。
还有一点,插入过程写成对子树的插入,然后递归插入,每个插入之后进行一次高度的检查,会比较不错。
ALV树的节点删除的思路和节点添加的思路差不多,节点删除逻辑的前半部分和二叉查找树删除方式是一样的,我们首先找到这个节点,如果这个节点是叶子节点,那就直接删除,如果是有两个子树的节点,那就用后继节点替换当前节点,并且递归删除后继节点,如果只有一个子树,那就把这个子树拼接上来。删除一个节点之后,我们需要重新更新这个节点之上的所有的节点的height。所以我们也使用一个递归来进行删除操作。我们递归的子单元就是删除子树的特定元素。
ALV树的实现主要是高度更新和重构的问题。而ALV树的重构主要是要认清是LL型还是LR型,还是RL与RR。主要的逻辑实际上是比较简单的。首先我们看哪两边的高度相差2,这样子第一个字母就定下来了。接下来我们去看第一个字母所代表的子树,看看这个子树的左右高度哪一个高就可以定下第二个字母了。
最小最大堆
最小最大堆是一种实现双端优先队列的数据结构,他是一种二叉完全树,也是一种堆结构。网上关于这方面的资料很少,在文库中有一个:最小最大堆
这是一种一层一层的数据结构,根节点所在的是“最小层”,往下走依次是“最大层”、“最小层”。在最大层的节点要保证在以他为根的子树中,他是最大的;在最小层的节点要保证在以他为根的子树中,他是最小的。

大概是这样的一个结构。
那我们如何判断是最小最大堆呢,实际上这个是可以用log2算的。我们可以给一个节点的索引不断除2来判断出某一个节点是在第几层的,从而也就很好推断出到底是最大层还是最小层。所以我们就用堆的索引进行log2运算,偶数层就是最小层,奇数层就是最大层。
但是C++中的math库并没有log2的计算,只有log10的计算,我们使用换底公式就好了。log2 N = log10 N / log10 2。
节点的添加
最小最大堆中节点的添加还是比较容易的。因为堆是用数组实现的,和普通的堆插入一样,我们可以将先放在数组最后,也就是15的左儿子的位置。然后我们和父节点做一次比较,如果比父节点大,说明这个新加入的节点是不可能待在最小层中了,我们只要和上面最大层的祖先比较就好了,因为如果这个节点往堆上面爬,一定有节点比他小,所以不可能待在最小层了。
反之,如果比父节点小,我们只要和上面最小层的祖先比较就好了。
我们比较之后怎么处理?处理方法和普通堆的处理是一样的,不断向上遍历,把优先级高的节点换下来。最小层就到根节点,最大层就到根节点的子节点,遍历完毕。
我们为上面一个堆插入10,来举一个生动形象的例子。



10和15比我们发现只要和最小层比就好了,然后不断向上比,不断向上跳。最后就换到根节点了。
删除节点
节点删除情况上会复杂一下,我们一般删除的是最大和最小节点。我们以删除最小节点为例。
我们是怎么处理的呢,传统的删除方法就是把最后一个节点放到第一个,然后自上而下递归重构。但是最小最大树就不能这么做了。
我们首先把根节点删除,然后我们进行重构(对于最小值删除):
堆的最小节点没了,那么次小节点肯定在最小节点的儿子和孙子节点上。所以我们就把,次小节点换到根节点上,然后次小节点那里就空出来一个位置了,这个位置是要填满的,要怎么填就是一个问题了。
我们首先把对数组的最后一个节点暂时拿出来,用来填充到之后的空位中。整个过程是这样的,我们在空的根的子女和孙子女节点中找到这个子树的次小值,这个值未必是真正次小的,因为最后一个节点被拿出来了,所以我们找到的这个次小值不见得是“真的次小值”,因为对数组最后一个节点可能比他还小,这个时候我们把我们事先拿出的最后一个节点填到根节点上就好了。
如果堆数组最后一个节点不比我们找到的“次小值”要小的话,那么这又有几种情况,如果这次小值是子树根节点的子女节点的话,我们直接把次小值放到根节点上,然后把堆数组最后一位放到次小值的节点原来的位置上。
为了方便讨论,我们把堆数组最后一位的节点叫做“补位节点”。如果我们找到的次小值是真的“次小值”,并且这个次小值是在子树根节点的孙子女节点上,这个次小值上到根节点上,但是这个补位节点不能盲目地放到次小值原来所在的位置,我们知道这个时候次小值永远都是在最小层上的,那么这个时候次小值的父节点一定在最大层上,如果我们盲目地将补位节点放到次小值所在的子树中,可能会发生补位节点比次小值的父节点要大的情况,这就不满足最小最大堆的性质了,所以我们这里分类讨论,如果补位节点比父节点小,那么我们直接在次小值节点上递归就好了。如果补位节点比较大,那就把补位节点和父节点换一下,然后递归去填补次小值子树的空根,总之只要次小值在根节点的孙子女辈,那都是要递归的。
我们举一个例子:

删除最小值,75单独拿出来,作为补位节点。

然后找到次小值12,75比80小,所以不用替换补位节点。然后在12原来的位置上进行递归,找到次小值15,15是12原本节点儿子节点,15换到原本12的位置,然后将补位节点进行补位就好了。

我们对最小最大堆也进行了实现。
这里我们要注意一个要警惕的问题,那就是如果空着的节点下面没有子树了怎么办,这个是很常见的情况,方式就是我们直接把补位节点放到根节点上就好了。这个是一个前文没有讲到的情况,那就是“如果没有次小节点怎么办”。
双端堆
双端堆是又一种双端优先队列的实现,实现方式的难度简单很多。双端堆是一种根节点没有值的堆结构。

也就是在堆数组的表现中,我们的1索引的值是空的。并且节点之间存在一种对应关系,对于一个最小堆中的节点来说,这个节点的“对应节点”就是最大堆中同样位置的节点。比如最小堆中的节点15对应的节点就是20。当另一个堆中对应元素的位置为空的时候,那么对应节点就是那个空位置的父节点。也就是说19对应的是25。
双端堆的插入
双端堆的插入是比较简单的,我们一般插在整个双端堆的最后一个位置,也就是放在20边上。然后我们和对应节点进行比较,正常来说双端堆的最大部分的值一定是大于最小堆部分对应位置的值,所以我们要进行适当的交换,让最大堆中对应位置的值小于最小堆。然后我们让新加入的值在堆中进行上升重构操作就好了。
双端堆的删除
双端堆的删除稍微复杂一些,我们要么删除最大值,要么删除最小值,删除之后还是涉及堆的重构,我们删除根节点之后,我们的根节点到叶节点中的与兄弟相比比较小的节点依次上升最后会在叶节点中空出一个位置,然后我们将双端堆数组中最后一个元素的值补到这个空的叶节点上。
插入排序
插入排序的思路就像我们按顺序整理一套扑克牌一样。我们以从小到大排序为例,我们从第一位开始将一个牌从当前位置抽出,然后让这张牌与之前的牌作比较。比这张牌大的牌都依次往前移一位,直到之前的牌比抽出的牌小。这样子就会空出来一个位置,将抽出的牌放到这个位置就好了。插入排序的特点就是我们抽出的牌的前面的牌都是已经排好序的。我们要做的实际上就是不断让一个新的值插入到一个已经排好序的序列中。
伪代码:
//插入排序,我们假设为从小到大排序//形参是输入和数组的长度insert_sort(A[],len)for i <- 0 to lendo//首先我们获取当前位置的元素tmp <- A[i]//这里激活一个嵌套循环,让获取的元素和之前的元素做比较for j <- i to 0doif A[j] >= tmpthenA[j+1] = A[j]elseA[j] = tmpbreak;
这个是一个时间复杂度为n^2的算法。
选择排序
选择排序是一种看起来更笨拙的排序方式,时间复杂度也是n^2。他的总体原理是一开始遍历整个数组,将最小的放在数组的第一个位置。然后遍历数组的剩下部分,将最小的放在数组的第二个位置,直到最后所有的元素都各得其所。
合并(归并)排序
合并排序算法思路
这是一种比较快的排序算法,时间复杂度达到了nlogn。他的思路就是将整个要排序的集合不断拆分,然后再两两合并,在合并的过程中进行排序操作。归并排序是一个递归算法,要合并的两个子列都是已经经过合并排好序的。所以这个算法的核心就是对已经排好序的两个数组进行合并,合并之后依旧是排好序的数组
数组合并伪代码:
//输入为两个数组和两个数组的大小,从小到大的排序merge(A[],B[],m,n){i <- 0j <- 0q <- 0result[m+n]while i < m && j < ndoif A[i] > B[j]thenresult[q] = B[j]j++q++elseresult[q] = A[i]i++q++//两个数组中有其中一个数组还会剩余元素,我们将其拷到要返回的目标数组中for i1 <- i to mdoresult[q] = A[i1]q++for j1 <- j to ndoresult[q] = A[j1]q++}
以上就是归并排序的核心部分,但是实际上外部还需要一个函数来进行驱动
//归并排序,形参为要排序的乱序数组merge_sort(A[],len){//将数组进行拆分mid = len/2A1[mid]A2[len-mid-1]for i <- 0 to middoA1[i] = A[i]for j <- 0 to len-mid-1doA2[j] = A[mid+1+j]merge_sort(A1[] , mid)merge_sort(A2[] , len-mid-1)A[] = merge(A1[] , A2[] , mid , len-mid-1)}
改造归并排序求逆序对个数
这个是一个到腾讯的笔试中出的一个考题,可以通过修改归并排序来获得一个数组中逆序对的个数。我们的主要的思路如下,依旧是一个递归的思路,但是我们需要在递归的过程中加入一个计数的步骤。
假设A[]数组,前后分为A1[m]和A2[n]两个部分。A1中的元素我们在逻辑上不需要特殊处理,然后A2中的元素我们在进行合并的时候要特殊处理。比如,A2中的第x个元素合并完之后就在A中的y位置。这个时候我们就知道这个元素对应的逆序就是,m-(y-x)。y-x算出的是A1中比这个元素小的元素,而m-(y-x)就是A1中比这个元素大的元素,所以这样子就可以算出与这个元素相关的逆序数。通过不断的遍历和向上递归,整个数组的逆序数就算出来了。
冒泡排序
这是一种乍一看和插入排序很像的排序方式,但是实际上有着本质上的不同。我们以从小到大排列为例,我们首先要注意冒泡的方向。将从小到大排列中我们可以从右边开始,将小的元素向左冒泡,也可以从左边开始将打的元素向右冒泡。每一轮冒泡都可以讲当前子列最大或者最小值挪到数组的两端。
//冒泡即是将打的值从左侧bubble_sort(A[] , len)//冒泡的轮数for i <- 0 to lendo//每一轮要冒泡的元素for j <- 0 to len - i -1doif(A[j]>A[j+1])tmp = A[j+1]A[j+1] = A[j]A[j] = tmp
霍纳规则的多项式运算
这个就是秦九昭算法,将多项式的计算变成了一个每一步都逻辑相同的递归。对于多项式来说我们不断提出前n项共有的X来进行化简。直到最后在每一个都可以进行ax+b的递归。
堆排序
堆排序是一种精妙的设计。堆是一种完全二叉树,他除了最后一层的每一层都是满的,最后一层也优先放满树的左边。这样子就可以造成一个非常好的效果就是,如果我们使用二叉树的数组表示来表示这个堆,那么这个数组的有内容的前半部分是完全满的,对于已经占用的空间来说,完全没有任何空间浪费。堆有一个很不错的性质就是在表达堆的数组中,假设一共占用了n个位置,那么n/2+1开始都是这个堆的叶子节点。
最大堆与最小堆是我们用来分别进行从大到小与从小到大排序的工具。以最大堆为例,一个节点的值永远比他的两个儿子节点要打,堆的根节点以及堆中所有子树的根节点的值都是在他那个子树里最大的。这里就涉及一个堆结构的保持问题,如果我们在一个子树的根部换上一个比儿子节点小的值,那么我们就需要进行堆的递归重构。重构的过程就是让这个子树的根节点和他的两个儿子相比较(这两个儿子都是所在的子树都是一个最大堆),如果根节点不是这两个儿子中最大的,那么就和这两个儿子中值比较大的那个儿子交换。然后继续递归那个值发生交换的子树最大堆。直到已经没有值可以交换为止,这样子堆就完成了重构,并保持了原有的性质。
对于一个杂乱无章的数组来说,堆排序分为两个部分,一个是堆的构造,一个是堆排序。堆是一个自下而上构造的过程,我们从数组的中间位置开始向前进行子堆重构,直到整个堆的所有内容都进行了,整个堆形成了最大堆,这个时候根节点就是最大值,我们将根节点和数组中的最后一个有效值进行交换,再让数组剩下的部分再进行一次堆重构。然后不断把数组剩下的部分进行整个堆的重构,这样子最后就可以得到一个排好序的数组。下面是伪代码。
//这里是子堆重构的函数//输入参数第一个是堆的数组表示,n是要重构的子堆的根节点。而这个根节点的两个儿子都是各自最大堆的根节点//这个函数有一个假设,就是这个根节点的两个左右子树都是已经构造好的子堆childRebuild(A[],n)//我们首先要看的就是A[]与左右子节点的比较,选出一个最大值和子树的根做交换//之后的这几个if就是在比较三个值之间的最大值//首先和左节点做比较if A[n] > A[n*2]thenlarge <- nelselarge <- n*2if A[large] < A[n*2 +1]thenlarge <- n*2 +1//选完之后我们就可以进行交换操作了,如果不需要交换,重构结束if large != nthentmp <- A[large]A[large] <- A[n]A[n] <- tmp//继续在子堆上递归childRebuild(A[],large)
使用这个函数也可以进行堆合并的操作。主要的操作就是使用一个叶子节点来放在两个堆的根上。然后执行一次从跟开始的堆重构工作。
我们通过这个根节点的两个儿子都是各自最大堆的根节点的特殊子堆的重构函数,我们通过自下而上的推构造方式进行无序数组的堆构造。
//输入是无序数组和这个数组的长度,我们要把这个数组的内容构造成堆heap_build(A[] , len)//我们堆的最低一层非叶子节点开始往回遍历数组,重构for j <- len/2 downto 1do//因为这个函数有个假设,子树必须是一个堆,所以这个乱序数组的重构就是从下到上的childRebuild(A[] , j)
这样子我们就完成了堆的构造工作。下面我们就可以进行堆排序了。为了节省空间,我们就把排好序的部分放在这个堆数组中,也就是放在堆数组的最后一个。通过让每一次从堆中选出的最大值和整个数组的最后一个值交换就好,然后我们对堆的剩下部分不断进行重构,最后就可以得到一个排好序的序列了
//利用之前两个函数,进行堆排序核心算法//输入为要排序的数组和数组的长度len,数组的第一位是空白的,我们这个len是数组不空白的部分heap_sort(A[] , len)//乱序的时候进行大规模重构heap_build(A[],len)//每一次我们选出来一个值,所以重构的过程需要反复len-1次for j <- 1 to len-1do//让最大值和数组最后一位交换(节省空间),然后重构//交换tmp <- A[1]A[1] <- A[len - 1]A[len-1] <- tmp//我们将堆的有效长度-1,让下次只重构剩下的部分len--;//因为左右子树都是最小堆,所以只要进行根节点的重构就好childRebuild(A[],1)//我们就这样通过最大堆来构成了一个从小到大排列的序列
其实我们也可以修改交换的位置来用最小堆实现这个过程。
最大优先队列
这是一种与与堆排序有着异曲同工的。我们知道在堆排序中,节点在堆中只有可能下降,这个过程叫做堆下降。在最大(最小)优先队列中,算法的核心在于“堆上升”。在最大优先队列中,在堆中的一个元素的优先级只有可能突然上升,这个元素就有可能出现堆上升的操作。
此外我们还可以基于堆上升的操作完整最大优先队列的插入操作。只要就是将一个元素插入在堆数组的尾部,并且对这个元素执行堆上升操作。从而维持堆的性质。
而在堆的根部的元素就是优先级最高的。我们有时候需要取出最大值。最大值取出之后我们还需要进行堆的重构,重构的过程和堆排序很像,我们把数组最后的值放到根节点处,然后进行重构。重构就是使用之前的递归“堆下降”工作。
现在我们实现一下最大优先队列。使用伪代码。
//导出最大优先队列的最优先元素,也就是A[1],然后我们就要使用重构堆,重构的方法就是把数组最后一个节点放在根节点处,然后重构。这个是最大优先队列功能的核心。导出的永远都是优先级最高的节点。//导出优先级最高的节点extra_max(A[],len)tmp = A[1]print tmpA[1] = A[len]childRebuild(A[],1)
节点上升函数,可以应对某一个节点优先级增大的情况。并且是在堆中加入节点的重要部分。
//实现节点上升的函数//三个形参,第一个是堆的数组表现,我们对A的要求就是A已经要是一个符合最大堆规范的对,第二个要修改的这个堆中的节点在数组中的位置,第三个是要将这个节点修改成的值,这个值只能变大不能变小,这个是最大优先队列的一个原则。increasing_key(A[],i,key)//首先看看输入值是不是合法,对应堆节点的值是不是变大了if(A[i] > key)then//输入值没有变大,输入违法return;A[i] <- key//然后我们进行递归的堆上升操作,让新改变的节点向上浮while i > 1 && A[parent(i)] < A[i]do//我们执行交换操作tmp <- A[i]A[i] <- A[parent(i)]A[parent(i)] <- tmpi <- parent(i)
然后就是节点添加的函数,我们将节点放在最后,然后对这个节点进行堆上升操作。
insert_item(A[],newEle)A[++len] <- newEleincreasing_key(A[],len,newEle)
我们可以使用堆的插入操作来进行堆的构建,实际上我认为对于堆的插入操作,我们唯一可以做的就是把一个一个新的值放在堆数组的最后一位,然后采用“堆上升”操作对堆进行重构。
除了二叉堆,我们还有D叉堆,这种堆结构在每个节点都有更多的节点,但是堆的高度会变小。这种变化,会对“堆下降”操作带来负担,但是堆上升操作会快很多。
我们这里总结一下堆,我们发现我们的重构过程容易搞混。这里我们要先说说从根部开始的重构,我们在之前叙述的时候,我们常说“堆上升,堆下降”。堆上升是我觉得是一种“调整”,堆下降是一种“重构”。比如堆下降过程,他保证的是下降节点的左右子树也同样是堆,这个过程是在乱序数组推构建(自下而上的堆下降重构)、以及堆排序的时候叶节点换到跟节点的重构工作;而堆上升是在堆插入和堆中某一个节点的优先级变大,也会进行节点的堆上升工作。
快速排序
快速排序是一种最佳的排序算法。虽然最坏运行情况很差 ,但是平均排序性能很好。并且因为使用的是就近的空间,所以并不需要额外的空间。相比之下,虽然归并排序也有不错的性能表现,但是因为归并排序需要额外的空间需要,所以快速排序是一种更好地选择。
快速排序的特点就是想起来很简单,但是实现起来就有不同的效果。他的核心在于“桩”这个概念,在每一个子列处理完之后,我们要达到一个效果,(假设是从小到大排列),我们要做的就是让比桩大的值都放在桩的右边,比桩小的值都放在桩的左边。然后将桩左边和右边的值分别递归,进行子列的处理。直到子列的大小只有1,递归停止。因为桩一般情况下都在两头,最后桩的位置又非常重要,我们要在最后将在数列中部符合要求的值和在头尾的桩进行交换,而什么叫“符合要求”我们要根据“桩”在头部开始尾部,以及这个队列最终是要从小到大还是从大到小排列有关。
整个算法的设计如下。除了指向我们需要快排的子列的首指针和尾指针,我们还需要两个指针,一个指针指向我们正在扫描的数组元素(初始化的时候指向0位置),还有一个指针(如果是从小到大排列)大值与小值的边界(一开始放在子列(前边界索引-1)的位置)。
template<class T>void part_quick_sort(T *inputArr, int start, int end);template<class T>void quick_sort(T *inputArr, int len) {//这个是一个递归的算法part_quick_sort(inputArr, 0, len - 1);}//这个部分是要递归的函数,template<class T>void part_quick_sort(T *inputArr, int start, int end) {//判定递归停止if (start >= end ) {//递归停止return;}//我们需要初始化两个指针,一个指针从头开始扫描int i = start - 1;//这个变量是桩,桩在数组的最后int pile = inputArr[end];int tmp = 0;for (int j = start; j <= end; ++j) {//j这个索引从子列的头部开始扫描,如果发现桩比数组小,那么就让j当前指向的元素和i+1所在的元素交换,并且i向前移动//对于i这个索引来说,我们要保证i是比桩小的,i+1是比桩大的。//我们要把比桩小的往前扔if (inputArr[j] <= pile) {tmp = inputArr[j];inputArr[j] = inputArr[i + 1];inputArr[i + 1] = tmp;i++;}}//等循环结束之后,i所在的位置就是桩经过换到中间之后的位置。现在我们拆分数组,进行递归part_quick_sort(inputArr, 0, i - 1);part_quick_sort(inputArr, i + 1, end);}
因为快速排序拥有比较好的平均性能,所以我们必须为快速排序加入一些随机化的因素来体现其平均性能的优势。所以我们的“桩”(在算法导论中叫做“主元元素”)是随机选取的,我么通过摇一个随机数在要处理的子列中选出一个随机的元素和尾部的元素做一次交换,然后再用尾部的元素做桩,以此达到了加入随机因素的结果。
非比较排序
我们之前用的全部都是基于比较的排序,现在我们可以看到一些不基于比较的排序。对于基于比较的排序,我们可以使用树状图的方式来判定这种排序的时间复杂度。非比较排序就不适合这种方式了。
总得来说非比较排序的时间复杂度甚至还要更小。
计数排序
计数排序是一种用空间换时间的典型案例。计数排序的主要思路就是我们将一个数列中比每一个数小或者相等的数的数目记录下来。比如说,在我们需要排列的数组中有一个数是5,然后在这个数组中我们发现比5小的数有3个,那么我们就要记录:“比5小的数有3个”,体现在编程中,就是我们在一个临时数组的第5个位置记录一个数字”3“。然后我们最后直接在输出数组的第4个位置填一个5就可以了,因为5比三个数字大嘛。
然后这又有新的问题,那就是如果有很多个相同的数字怎么办。比如我们发现”5“一共有多个,那么我们会在向输出数组添加一个5的时候,在计数的临时数组中我们就要把5对应的值-1。
我们怎么输出?在整理完临时的计数数组的时候,我们要依照输入数组的内容查询临时数组,并且将查到的内容进行输出数组的构建,直到输入数组被完全遍历。
总之,计数排序我们一共涉及3个数组,输入、输出、临时计数。下面我们进行C++语言的实现。
这里先提及一个实现问题,就是指针的引用问题,为了保证我们的指针的指向在函数之内可以进行真正意义上的改变。指针的引用要注意“*”与“&”的顺序:
func(int *&p)
在编程中我们还遇到一个问题,就是栈区数组变量与指针变量实际上是不一样的。我们要注意区分。如果是要传数组的引用,那就是:
func(int &p[数组大小])
我们可以看到指针是指针,数组变量是数组变量,虽然他们有一定的一致性,并且数组变量还可以赋给指针。使得新的指针就是一个指向栈区的指针。但是数组变量是不可以改变的。数组变量不可以改变用其他数组变量来赋值,也不可以进行引用传参。根据网上的说法,数组变量并不是真正意义上的变量,所以在内存上实际上没有这个数组变量的空间,在程序运行的时候作为立即数存在,也就没有修改和引用的说法。
所以说数据变量的存在和指针之间很容易产生混淆和误解,对于数组,我们尽可能使用new+指针指向的方式来声明。数组变量的局限性比较大。
这里我们好好讲讲数组变量和指针。他们有很大的相似,也有不少的区别,首先数组变量是可以赋值给指针的,但是指针是不可以赋值给数组变量的,换句话说,数组变量是一种常量,是不能被赋值的。
我们看一下数组和指针在函数形参下的表现:
void PrintValues(const int ia[10])
首先我们看如果数组是形参的话,我们要用这样的形式,并且这里声明了大小,实际上这里,这个数组的形参实际上会被编译器改造为一个指针,所以实际上和形参是const int* a没有区别,那个中括号中的10是没啥用的。此外,我们还可以利用数组可以给指针赋值的特性,使用指针来为数组传参。
void PrintValues(const int *ia,int size)
此外我们可以传数组的引用。这时候的那个2是有明确意义的,不能省略的。
void PrintValues( int (&ia)[2])
计数排序中我们还需要注意一点,就是输入数组和输出数组的大小和索引我们要注意,输入数组是从0索引开始使用的,输出数组也是这样,但是临时数组在计数的时候是从1开始算的,也就是计数为1的算到输出数组的0索引里面。
void count_sort(int* &inputArr, int len) {//首先我们设定一个临时数组,这个临时数组的大小和输入数组中所有元素的最大值有关系//我们遍历输入数组,然后我们找出最大值int large = -1;for (int i = 0; i < len; ++i) {if (large < inputArr[i]) {large = inputArr[i];}}//然后根据这个最大值创造一个数组,这里我们要注意这个数组的大小//我们要让输入数组的最大值与临时数组的最大索引保持一致int *temp_count = new int[large + 1];//这个计数数组的初始化for (int j = 0; j <= large; ++j) {temp_count[j] = 0;}//然后我们进行计数for (int k = 0; k < len; ++k) {temp_count[inputArr[k]]++;}// for (int j = 0; j <= large ; ++j) {// cout << temp_count[j] << " , ";// }// cout << endl;//然后我们进一步处理临时计数数组,让数组第n位记录输入数组中小于等于n的元素个数//处理方法就是不断从临时数组的第一位开始不断让相邻的两个数相加for (int l = 1; l <= large; ++l) {temp_count[l] = temp_count[l] + temp_count[l - 1];}// for (int j = 0; j <= large ; ++j) {// cout << temp_count[j] << " , ";// }// cout << endl;//建立输出数组int *output = new int[len];//然后我们遍历输入数组,为输入数组的每一个元素在输出数组中找到一个新的位置for (int m = 0; m < len; ++m) {//通过查看临时计数数组,给输入元素找在输出元素的位置output[temp_count[inputArr[m]]-1] = inputArr[m];//因为可能有重复元素,所以我们要在排序之后将计数值-1temp_count[inputArr[m]]--;}delete inputArr;inputArr = output;}
计数排序的主要的应用场景是在排序的数比较密集的,不太密集的话会造成空间的浪费。
基数排序
这也是一种非比较排序,基数排序和小学生做数字比较大小思路很像。就是一位一位一位比。
基数排序是一种从最小位到最大位不断比较的排序,这个和我们自然的认识可不一样,我们对于每一位的排序必须是稳定排序,也就是说我们在进行高位的排序的时候如果高位一样,就一定要保证低位的顺序。
首先,排序算法的稳定性大家应该都知道,通俗地讲就是能保证排序前2个相等的数其在序列的前后位置顺序和排序后它们两个的前后位置顺序相同。在简单形式化一下,如果Ai = Aj,Ai原来在位置前,排序后Ai还是要在Aj位置前。
其次,说一下稳定性的好处。排序算法如果是稳定的,那么从一个键上排序,然后再从另一个键上排序,第一个键排序的结果可以为第二个键排序所用。基数排序就是这样,先按低位排序,逐次按高位排序,低位相同的元素其顺序再高位也相同时是不会改变的。另外,如果排序算法稳定,对基于比较的排序算法而言,元素交换的次数可能会少一些。
下面是这个算法的伪代码:
//下面进行整数的计数排序从低位到高位进行排序,对不同位数进行稳定排序radix_sort(A[] , len)//我们进行循环,两层循环,一层是遍历数组,一层是遍历数字的每一位,从低到高//首先进行位数的遍历for ido//经过改造的插入排序,每次都对其中一位进行插入排序insert_sort(A , len , i)
桶排序
这个是一个感觉有点像哈希的排序,只是排序的时候我们要保证要进行排列的数组的每一位在进行处理之后,产生的新的数字不改变其在数列中的排序。产生的这个数字就是桶的编号,而桶就是一个链表结构,在链表中的元素就是经过桶分类的数列元素,在插入桶的过程中,他依然经过了排序。使得在链表中的元素也是按照某种方式排列的。并且在高位的桶中的每一个元素也“大于”在低位桶中的每一个元素。
桶排序在元素分布均匀的数列排序中表现出色,时间复杂度为n。
顺序统计量的选择问题
顺序统计量就是数列中第n大的数,这个数可以是最大值,也可以是最小值,也可以是中位数,顺序统计量的选择我们可以排序之后直接选,也可以使用一些时间复杂度为n的算法。
找出最大值和最小值
我们找到最大值和最小值的算法其实就是我们常用的算法。总体的思路就是设定一个变量就是min活着max,然后遍历输入数组,数组中的每一个元素都要和min活着max比较,最后的效果就是让max或者min存着已比较元素中最大或者最小的那个元素。
get_min(A[] , len)for j <- 0 upto lendoif(min -> A[j])thenmin <- A[j]
这个的时间复杂度是n。一共进行了n次比较
如果我们需要同时找到最大值和最小值,那就是2n吗,实际上有一种只需要3n/2次比较就可以了。
get_min_and_max(A[] , len)for j <- 0 upto len j <- j+2doif A[j] > A[j+1]thenif max < A[j]thenmax <- A[j]if min > A[j+1]thenmin <- A[j+1]elseif max < A[j+1]thenmax <- A[j+1]if min > A[j]thenmin <- A[j]
我们在算法导论中还发现一个问题,在题目中有一个问题:“我们如何才能找到一个数列中的最小或者第二小的值”,其实最诡异的就是题目还要求进行n+lgn-2次比较。
我们发现使用树状比较可以创造出满足要求的东西,我们举一个例子。

我们使用的方式主要是树状比较排序。对于数的每一层,我们两两分组进行比较,直到只剩下一个根节点,这个就是最大值,一共需要n-1次排序。因为每一层的内容我们需要使用一个数组进行保留。然后我我们做的就是将和最小元素比较过的元素单独拿出来进行一个次比较,找出这些元素中的最小值,比较次数为lgn-1次。
随机选择排序—找出第n小的元素
这个是一个比找最大值和最小值都要复杂的算法,整体的思路复用了快速排序算法的内容。我们知道快速排序的平均时间复杂度非常小,所以我们要在当中加入随机化因素。
现在说说随机选择排序的算法思路。这个东西与快速排序有异曲同工之妙,或者说他就是一个进行了一半的快速排序,是一个会提前结束的“快速排序”。我么知道进行快速排序的一次递归之后,整个数组会被分成3个部分。一个是桩变量,一个是小于桩变量的数组,一个是大于桩变量的数组。因为小于桩变量的数组和大于桩变量的数组大小我们都是知道的。假设桩在数组中第i个位置,我们可以证明,桩是第i+1小的数。假设我们要找的是第j小的数,如果j==i+1,那么就说明桩变量就是我们想要的。如果我们发现j\i+1,那么我们就要在大于桩变量的数组中找第j-i-1小的元素。所以说这个也是一个递归函数,而且与快速排序不同的是,这个是单侧,并且会提前停止的递归。递归的条件只有一个,那就是我们找到的桩在快速排序之后的索引,如果这个索引的大小+1和我们要找的第j小的这个j相等,那么就意味着我们找到的第j小的元素,并且递归结束。下面我们实际实现以下这个算法。
//第一个形参的输入数组,第二个形参为参与随机选择的数组的起始位置,第三个为参与随机选择的数组结束位置//第四个为我们要找的是当前范围第rank小的元素//我们借助快速排序从小到大排序template<class T>T random_select_fun(T *inputArr, int start, int end, int rank) {//我们确定一个递归结束条件,这个if应该永远不会进入的if (start > end) {cout << "发生了错误" << endl;return NULL;}//我们首先加入随机过程,随机制定start和end之间的数为桩//首先我们摇一个种子srand(time(0));//找出一个桩int stake = rand() % (end - start + 1) + start;int tmp = inputArr[end];inputArr[end] = inputArr[stake];inputArr[stake] = tmp;stake = end;//桩的数值大小int stackNum = inputArr[stake];//然后进行类似于快速排序的工作,声明两个索引,一个是放在数组的第一位一个是放在-1位//数组的扫描索引int j;//比桩变量小的数组的最大索引,i+1就是桩,i+2就是比桩大的第一个数int i = start - 1;for (int j = start; j <= end; ++j) {//遍历我们要进行扫描和处理的数组if (inputArr[j] <= stackNum) {//发现有比桩小的数组,我们就把他们放到start和i(包括i)之间,主要是使用交换的方式//因为桩还没有换过来,所以i+1就是比桩大的部分。i++;tmp = inputArr[i];inputArr[i] = inputArr[j];inputArr[j] = tmp;}}//最后i就是桩所在的位置//我们看看这个桩是不是我们需要的//这里要注意,我们虽然发现桩是i,但是实际上i索引所对应的排位应该是i-start+1if (rank == i - start + 1) {return inputArr[i];}//如果我们要的数的排序比i+1要小,那么就要进行桩左部数组的递归if (rank < i - start + 1) {return random_select_fun(inputArr, start, i - 1, rank);}//如果我们要的数的排序比i+1要打,那么就要进行右部的递归//我们首先要知道比i小的数在这个部分一共有多少个,也就是在i左面有多少个数,我们让i和start重合,取一个特殊值就知道有i-start个。//所以rank要减去一个i还要减去i左边的数rank - (i - start) - 1if (rank > i - start + 1) {//这里递归调用的形参要好好注意return random_select_fun(inputArr, i + 1, end, rank - (i - start) - 1);}}template<class T>T random_select(T *inputArr, int len, int rank) {return random_select_fun(inputArr, 0, len - 1, rank);}
实现的难点就是关于桩在当前范围的数组中的排序的计算,要考虑随机选择的起始位置,以及递归调用的时候rank这个形参的计算。当+1-1算不清的时候我们可以适当取取特值。
这个算法我们也可以找出最差时间复杂度可以达到n的方法,主要就是在于桩的选取。我们在上面是采用随机的方法找桩,现在我们采用这样一种方式:
- 将数据5个分为一组,最后不足5个的单独分为一组
- 我们对每一组进行插入排序,获得其中位数
- 将所有的中位数再次进行插入排序,再获取中位数
- 将此中位数为桩进行快速排序的一次迭代。
- 判断桩的位置和我们需要元素的排序之间的关系,选取左子数组或者右子数组进行递归。
多叉树的实现与表示
我们实现过二叉树,当时的实现有两种问题,一种就是我们没有办法向父节点回溯,还有一个问题就是没有办法接受任意个数的儿子。所以我们我们同辈之前使用链表连接起来,并且提供一个可以指向父节点的指针。我们的节点结构和二叉树的节点结构非常像,但是我们还是要进行一些修成和扩充,但是总体的思路就是:父指针指向父节点,右指针指向儿子节点,左指针指向兄弟节点。所以我们可以看到实际上任何多叉树都可以变成一个二叉树。
这个类的实现首先我们需要注意的就是关于那个“儿子链表”的处理,我们要处理好插入和删除节点的位置问题,要走适当的距离。并且链表还有边界问题。
二叉查找树
二叉查找树是一种可以用来查找的二叉树。我们可以在二叉查找树的一个节点中放一个值,也可以放一个键值对(然后我们主要进行键的查找)。二叉查找树的主要的性质就是左子树的(所有值)大小要小于他的父节点,而右子树(所有值)的大小要大于他的父节点。整个查找的过程最坏的时间复杂度和树的高度是一样的。我们可以使用中序遍历可以将二叉查找树中的内容可以按照顺序输出出来。
二叉查找树首先的一些操作就是查找、前趋、以及后继节点的访问,以及最大值最小值的访问。查找的过程是很简单的,我们使用一个指针,从根节点开始遍历,如果我们要找的元素比子树的根大,那指针就往右子树方向走,如果我们要找的元素比子树的根小,那就往左子树走,直到找到我们需要的节点就好了。
子树极大值和极小值的查找也是比较简单的,极大值我们就一路一直往右子树走,直到不能再走了为止,极小值我们就一路一直往左子树走。
任意节点的前趋和后继节点是比较需要想想的,对于一个从小到大排序的序列来说,我们某一个节点的后继节点实际上就是只比这个节点大一个次序的节点。总共有两种情况,一种是当这个节点有右子树的时候,那么后继节点就是此节点右子树的最左节点,也就是右子树的最小值,但是有一个比较特殊的情况,那就是如果这个节点没有右子树怎么办,那么这个时候就要在父节点下文章了,我们需要不断寻找当前节点的祖先节点,使用父指针一直往回走,直到我们找到第一个祖先节点是某一个节点的左子树,那么这个“某一个节点”就是后继节点,也是中序遍历的下一个元素。前继元素和后继元素的方式类似,但是就是稍微“反过来一下就好”。我们首先关注左子树,也就是去找左子树的最大节点,或者说最右节点,如果没有左子树怎么办,我们使用的方法还是不断往当前节点的祖先节点遍历,直到我们发现一个祖先节点是某一个节点的右子树根节点,那么这个“某一个节点”就是我们所说前驱结点。
很难记?其实我们只要记住一个例子,画一画就好,例子一共三层。
8
4 12
2 6 10 14
1 3 5 7 9 11 13 15
我们只要知道最底层是一个奇数列,就好了。然后往上一直取中位数就好了。
为什么我们那么在意后继节点查找呢,因为这个在元素删除的时候要用到。下面我们说一下元素的增加与删除。二叉查找树的增加前半部分的搜索一样,新的节点添加在树的叶子节点。
那删除怎么办,对于二叉搜索树的,我们的删除过程还是比较简单的,其实主要矛盾就是在子树的处理,我们在删除的同时怎么维护整个整个树还保持原来性质,首先如果我们删除的节点没有子树,那就直接删掉就好了。如果有一个子树,那就把连接子树的那个指针给父节点就好了,如果有两个子树,我们要做的就是把这个节点的后继节点(右子树的最左叶子节点)替换过来,用后继节点替换当前节点的位置。
我们现在实现一个二叉查找树。我们复用链表二叉树的代码,但是为树节点加上一个父指针,这个父指针是为了方便寻找父节点而设计的。另外,为了展示出树真正的查找方式,实际上我们在二叉搜索树中存的都是键值对,我们是通过键的值来进行数的构造,但是最终的结果当然是获取值。不过我们在这里加以简化,我们没有键值对的结构,只有“键”,为了实现搜索算法,我们写一段函数来查看某一个树节点是不是存在。
这里我们有两个算法是需要拐拐弯的,一个是删除树节点,还有一个是查找树节点的后继节点。这两个都要依据子树的情况进行分配讨论。
在删除节点有一个有意思的现象,就是如果删除的节点有两个子树,那么会用后继节点换上来,但是实际上想一想,也可以使用前驱结点换上来。
在之前版本的实现中我们可以发现,实际上我们对根节点的删除处理得很不好,因为根节点的指针实际上我们是需要重定位的。如果我们删除一个根节点,并且这个根节点的只有一个子树,那么根节点对象会被直接析构,root指针就需要重新定义了。
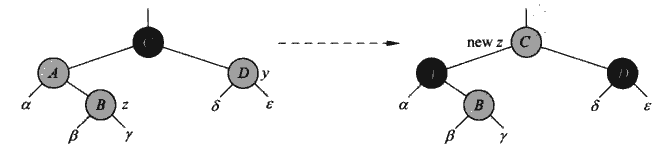
红黑树
查找树的算法思路的细节很多,算法的核心在于分类讨论。
我们知道,我们实现的二叉查找树有有严重的问题,那就是如果树左右很不平衡,可能就会导致树的高度不必要地大,最后导致时间复杂度过于复杂。
红黑树是一种可以保证基本平衡的树,在红黑树中,根节点和叶节点是黑的,黑的节点的子节点可以是任何颜色的节点,红节点的儿子必须全是黑节点。因为每一个子树的每一条到叶节点的路径黑节点数量是一致的,我们通过这样的设计就可以保证最长的深度和最小深度之间的差距不超过一倍。
算法导论对于这个深度的控制进行了详细的数学证明。其实我们对于最长深度和最小深度之间的差距为一倍可以有一个感性认识。对于一个节点来时,他的深度最小的时候就是子树全是黑节点的时候,深度最大的时候黑节点和红节点相互交替的时候。
为了保证优异的边界判断,我们为红黑树设置NIL叶节点,这个叶节点的值是空的,所有没有指向的指针(根节点的父指针、“真”叶节点的左右子指针)。最后产生一个结构。
红黑树的旋转
我们保证在树的修改之后红黑树的性质的不变形。我们需要引入旋转操作。旋转操作就是在不影响二叉查找树的前提下,我们可以进行数的深度的平衡。
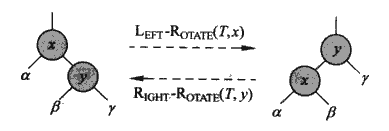
注意x与y的子树在旋转之后的位置,旋转的两个节点的子树的左右相对位置是没有变化的。
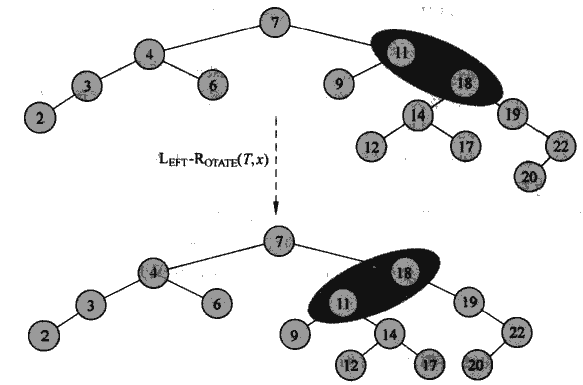
就像是这样。我们可以看到旋转之后19、22、20那条线的深度变小的,11、9这条线的深度变大了。总体的平衡性就好很多。并且不影响查找树的构成,中序遍历的结果还是一样的。并且旋转也有一个很好的地方,就是旋转也不会改变红黑树的其中一个性质:从任意子树根节点到叶子节点的黑高度相同。也就是说旋转不会对黑高度有影响。
红黑树的重构
红黑树最难的就是插入和删除的过程,这个过程是比较难的。首先就是插入过程,这个过程和基本的树的插入是一个样的,但是要注意几点:首先是染成红色,然后就是,没有内容的左右指针要指向NIL节点。
在插入数据的过程中会有两种情况被破坏,一个是根节点需要是黑色,因为我们插入的元素都会被染成红色,这个很好解决,空树插入的时候注意一下就好了。还有一个会被破坏的条件就是红红节点不能相连会被破坏,在红黑树中,黑黑可以相连,黑红可以相连,但是红红是不可以相连的。
我们一共要处理6中情况,其中可以分为两组,使用一张只有我能看懂的图来描述这个过程。
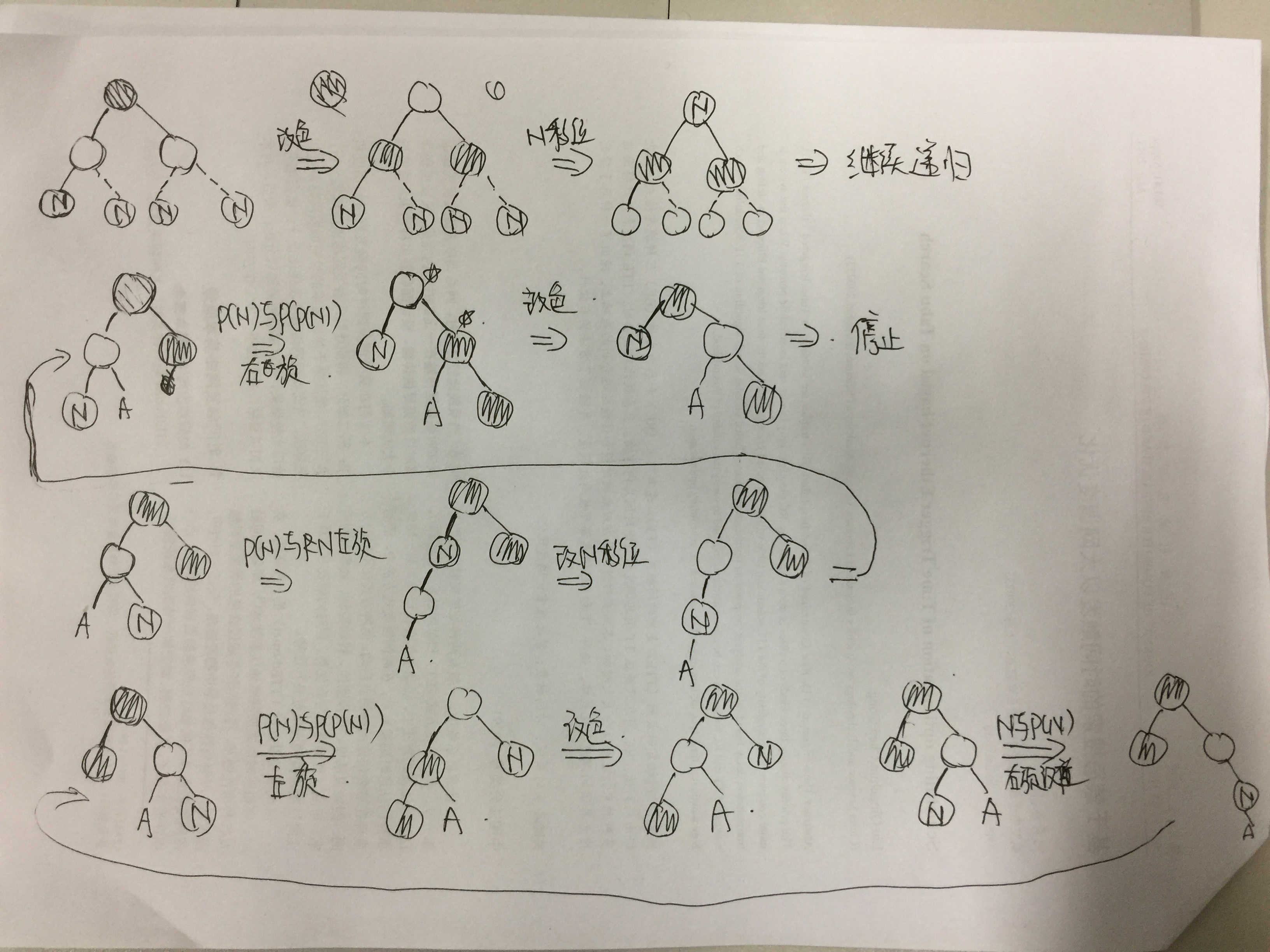
对于插入之后性质保持额过程主要分为这么几个层次。首先我们的主要矛盾就是插入的新节点和其父节点直接都是红色的矛盾。关于根节点在重构过程中变为红色的问题我们直接修改根节点的颜色即可。并且我们可以知道出现矛盾的新加入的叶子节点的爷爷节点肯定是黑色的,父亲节点一定是红色。
红黑树的重构是一种从叶子节点到根节点方向的重构。在重构的过程中有三个比较关键的情况都要考虑。主要的处理思路分为三步:看叔叔节点的颜色、看新加入节点的位置、看新加入节点的父节点的位置。
首先就是新节点的叔叔节点是黑的还是红的,如果新节点的叔叔节点的颜色是红色,那么我们只要重新定制父辈和爷爷节点的颜色。将它们的颜色翻转,然后将指向新加入节点的“关键元素指针”指向爷爷节点就好。
处理完这种情况之后我们还需要不断进行向上的重构。
这里提到了关键元素指针,这个指针一开始是指向新加入节点的,我们的主要矛盾就是这个指针指向的元素的父元素是不是红色的问题,如果是黑色,问题就直接解决了,整个红黑树就不需要重构了,父元素是红色,那就要进行重构操作。这里还有一个问题,就是当有两个节点都是红色,我们要让“关键节点指针”必须指向子节点,这个问题会在下面出现,我们需要重新修改一下“关键节点指针”的位置。
这里还有一个问题如果我们发现没有爷爷节点或者关键元素指针指向了根节点怎么办,处理很简单,这两种情况都是根节点是红色的情况,我们只要把根节点变成黑色的就好了。
然后就是叔叔节点也是黑色节点的情况,这里我们单单改色是不够的,要先进行旋转,旋转的方式和关键节点和父节点的位置有关,第一步就是“将关键节点和父节点放在同一侧”,方式就是将关键节点和其其父节点放在爷爷节点的同一层,并且重新定位指针。
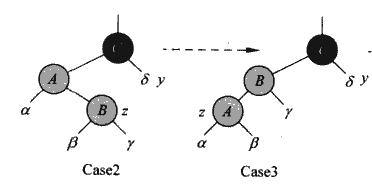
这里的这个z就是关键节点我们和他的父节点做一次左旋转,然后重新定位一下“关键节点指针”。当然,如果父节点的右边的话,我们就做右旋转就好了。
当整理到同侧之后,我们就让父节点和爷爷节点做适当的旋转让子孙三代平衡起来。然后我们改了颜色,让关键节点的父节点的变为黑色,爷爷节点变为红色。如果不变色,黑深度就会不平衡。
这里我们的重构就会完成,因为我们发现关键节点的父节点已经是黑色了。重构完成。
所以说实际上我们需要处理三种情况(包含对称的还需要更多),然后使用一个循环,直到父节点变为黑色,或者到达根节点。
这就是插入重构的所有过程。接下来是删除操作,我们需要进行删除,并且为了保留已有性质而进行树的重构操作。总的来说,红黑树节点的删除操作比插入操作更加复杂一些。
在红黑树的删除操作中,我们的主要矛盾就是黑节点删除,因为红节点的删除不会引起红黑树任何性质的变化,主要是黑色的问题,因为删除了黑色之后,首先可能会破坏根节点是黑色的条件,此外我们还可能破坏两个红节点不能连续的条件,因为一个黑节点很可能在两个红节点之间,删除了黑节点就意味着红节点之间出现了相连的现象,除此之外对于黑色节点的删除还可能导致每个节点的黑深度不再相同。
这里算法导论引入了一种“节点双重颜色”的设定,一下子加大了算法理解的难度,这里我们主要看的是链接经典算法研究系列:五、红黑树算法的实现与剖析的剖析。
红黑树的节点删除代码也分为节点删除和树重构两个部分,在算法导论中给出的代码不好理解,下面是我在网上找的一个实现:
RB-DELETE(T, z){//T为树对象,z为要删除的树节点的指针if left[z] = nil[T] or right[z] = nil[T] {//这步处理的是当我们要删除的节点的左右子树都是空的时候y = z;} else{//如果都不是空的,那么y就是z的后继节点y = z的后继节点;}if left[y] != nil[T]{//如果y的左节点不是空的,那x就是y的左节点x = left[y];}else{//如果y的左节点是空的,那么x就是y的右节点,这个x有可能是空节点x = right[y];}//这里我们可以确定的是y是一定要删除的节点,y指向z的时候要被删除,指向z的后继节点的时候要被删除//而x指向的是y存在的左右子树,或者y不存在左右子树的时候的空节点//这个时候我们将x的父节点指向y的父节点,这样子造成的效果就是将要删除的y的子节点和y的父节点就连接上了//这是删除y的前兆p[x] = p[y];if p[y] == nil[T] {//如果p是根节点,那么我们重新定义根节点root[T] = x}else{//如果要删除的角色不是根节点,那么我们就让删除节点的父节点的子节点指针重连//而具体与哪一个指针连接我们需要进行一个判断if(y == p[y].left){p[y].left = x;}else{p[y].right = x;}}if(y != z){//这里说明y是z的后继节点,我们删除y是没有用的,我们还要把后继节点放到z的位置上去key[z] = key[y];}if (color[y] == black) {//如果被删除的元素是黑色,我们就面临红黑树的重构,因为黑节点的删除可能会导致红黑树://1、根节点颜色是黑色//2、黑深度不统一//3、红节点不能相连//这三个条件被破坏//这里进行重构RB-DELETE-FIXUP(T, x)}}
我们可以看到这个过程和二叉查找树是基本一样的,主要是重构的问题,真正被删除的节点可能就是调用者要删除的节点,也有可能是调用者要删除节点的后继节点。如果被真正删除的节点是黑色的,那就会激发一个红黑树的重构。
下面我们看看节点的重构代码。
//修复节点的删除//我们这里的x是比较有门道的,x是什么?因为我们的y始终指向的是被删除的节点,而这个被删除节点的子节点小于等于一个,所以x要不就是被删除节点y的唯一子节点,或者NIL哨兵。RB-DELETE-FIXUP(T, x){//重构是一个自下而上的循环过程,x会不断上移,当x移到根节点或者当x节点的颜色变为红色的时候重构就会结束//那x一开始会不会是红色的呢,如果一开始就是红色,我们只要把被删除黑节点y的这个红色子节点换成红色就好了。//这样子就保证了y的祖先节点的黑高度平衡while x != root[T] and color[x] == BLACK{//下文所述的逻辑}color[x] = BLACK;}
这里一共分为四种情况,都是x节点的黑色的情况,所有的矛盾都是发生在x的兄弟节点和兄弟节点的子节点之间。这样就诞生了很多种可能,首先就是兄弟节点是红色,除此之外就是兄弟节点是黑色,面对黑色的情况我们就要看看儿子节点,根据排列组合,左右儿子节点莫非红红、黑红、黑黑、红黑,这么四种组合,实际上右节点为红色的组合是可以组合的,所以实际上在兄弟节点是黑色的情况实际上有三种情况,算上兄弟节点的是黑色的情况实际上就是四种情况。
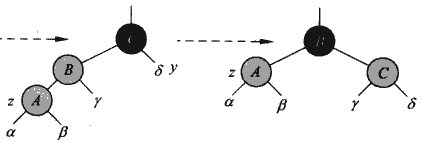
这里我们处理一下这四种情况,这四种方法没有什么重构的理由,更像是一种需要死记硬背的设计。首先卡 第一种:

这里x节点就是重构的核心,因为x的原父节点被删除了,现在x这一侧的黑高度比另外一侧小一,我们这么进行一次转换,就把第一种情况转换为另外三种情况了,三另外三种情况中,x这一侧的黑高度会加一,从而就可以保证平衡了。这里就是将x的父节点和兄弟节点进行颜色的互换(父节点的原始颜色必须是黑色),然后在兄弟节点和父节点之间进行一次旋转,旋转方向与X所在子树的方向一致。
下面是第二种情况,就是兄弟黑,并且兄弟的子女全是黑的情况:

这里我们直接改变兄弟节点的颜色就好,这样子B之下的高度就是平衡的了(因为少了一个黑节点),所以我们把B之下黑高度平衡搞定了,现在主要矛盾又变成B节点一侧的高度不平衡。所以我们将B看成新的x节点。如果B是红的,实际上把B改成黑的就可以一下子解决平衡问题,B之下的平衡解决了,B与其他子树的平衡也会解决,如果B是黑色的,那么B一侧的平衡问题就重新变为1、2、3、4类,通过考虑兄弟节点的情况进行进一步重构。
这里我们可以看到整个重构过程的主要矛盾就是“黑高度平衡”的矛盾。我们处理的问题从来都是X所在子树比另外一侧的黑高度少一的问题。解决这类问题就是在x与父节点位置的节点直接做文章,要么通过直接修改X的颜色,要么在X与父节点之间加一个黑节点进来。
然后就是第三种情况,第三种情况主要就是为了产生第四种情况而设计的,主要就是把兄弟节点的红黑子树编程右侧是红子树的情况。实际上这里我们举的例子是x在左侧的情况,在实际的实现中,实际上这个例子体现为,在x的兄弟节点中,与x同侧的是红色,与x异侧的是黑色。我们要把他转化为异侧是红色。主要方法就是让同侧节点和兄弟节点互换颜色,然后向x的异侧旋转。也就是我们需要把红节点旋到外侧。

我们可以看到这里没有改变任何红黑树现有的状态,但是这个转换的贡献就是他将新的第三种情况转换为第四种情况。

这里父节点有一个红色子节点在x的对侧。我们让x的父节点和兄弟节点进行颜色的交换,然后进行一次和x节点所在子树方向一致的旋转。
通过这几次旋转,我们不难看出,在节点删除的问题上,都是让要旋转的两个节点交换颜色并且根绝子节点与父节点的位置关系进行旋转。图中我们举的都是x在左子树的例子,在实际情况中还有右子树的例子,和左子树的情况是对称的。
红黑树是现在我们所见过的树中最复杂的结构,因为重构的情况实在是过于复杂。这个结构在实际的测试中考察的可能性很低,因为实现的时间会很长,但是我们要牢记红黑树的优势,以便在合适的时候进行调用。
在金远平著的数据结构一书中,没有对红黑树的介绍,但是有一种非常平衡的树:AVL树。这个树在算法导论的课后题中有详细介绍,我们会进行详尽的实现和讨论。
B树
红黑树拥有非常复杂的结构和实现,但是依旧没有办法做到绝对的平衡。B树是一种绝对平衡的多叉树。他的实现相对红黑树来说更有规律,在节点的删除和添加上也没有很奇怪的实现。总的来说是一种性能较好,并且实现也很有逻辑可寻的数。
B树的设计很简单。B树有一个概念,叫做阶。一个阶为m的节点非叶非根的节点一红有不多于m个不少于2/m个子树,也就是说key的数量不能少于m/2-1。B树的节点除了有一串n个指向子树的指针之外,还有n-1个key值来索引。低a个子树的所有key值都在a-1和a号键值之间。其实这就是一个查找树,只是节点元素不固定的多叉查找树而已。
B树节点添加
B树的节点添加key实际上要注意的就是节点的拆分,我们知道阶为n的节点有n-1个key,如果key超过n-1个就要将这个节点拆为两个节点。
拆的方法很简单,我们从中间进行划分,假设节点key值索引的最大值为n,中间key的索引为n/2。这个key值是要进入父节点中了。然后我们看看父节点,放到哪?这个和要拆分的根节点在父节点长出的位置有关系。比如放在a与a+1两个key值之间,之前只有这个子节点,假设要新加入的key值为b。拆完的两个节点一个是x,一个是y,那么a与b之间的指针指向x,b与a+1之间的指针要指向y。我们从尾部向前使用类似于插入排序的操作。主要比b大的key值向后挪一位,然后插入,我们记录一下插入的位置X。然后我们的指针也是要插入的,指针数组我们从最后到X+1的指针都往后挪。然后我们说一说子节点拆分的事情,原来的节点不用着急析构,我们只保留原来的节点前n/2-1个key值,前n/2个指针。然后我们把n/2+1之后的key值,以及n/2+1之后的指针值放到另外一个节点中。那么两个节点中有多少个key呢,其实我们用头尾两个key的索引值相减+1就可以。我们在拆分的时候我们要注意的就是两个数组索引号是斜着对齐的,拆分的时候要注意两个数组的边界。以及拆分的子节点在父节点中如何指向的问题。
上面说的是怎么拆的,现在说一说我们要怎么拆。主要的方式就是“提前拆”,提前拆可以保证不需要回溯父节点。因为子节点的拆分需要父节点的重新定位,所以我们要做的就是我们扫描在父节点的时候就把该拆的子节点拆了。那拆什么呢,拆我们添加的查找路径上的节点。我们要往这个子节点的方向走,那么我们就先看看能不能拆,如果这个节点已经满了,那就拆,拆完之后我们再找拆完的一个子节点。这种方式有什么好处呢,就是我们在添加的时候直接添加就好,不需要不断向父节点方向修改。
另外添加的过程我们要注意根节点,这个是一个比较特殊的节点,因为他的分裂会产生一个只有一个节点的新根,这个是需要特出处理的。
这个就是B树节点的添加过程。
添加前:

添加后:

这里就展示了K与N出现M的时候向上拆分的。但是实际上因为算法导论的没有父节点的实现中,是不需要向上的递归重构的,索引M的插入出现这种情景是不应该的,应该是当遍历到G节点的时候就发现往下走会超,所以提前分裂,将HKNQ分为H和NQ,K上升到父节点中,然后在插入M的时候我们就会把M插到NQ所在的叶子节点中。
B树节点的删除
删除key值的过程比较麻烦,但是也没有红黑树麻烦(笑)。删除的过程还是很容易的,主要分几种情况一种是叶节点的删除,这种删除直接删就可以了,因为我们在向下遍历B树的路径上会让key值个数在2/m-1的节点提前扩容,扩容的方式有好几种,一种是向兄弟节点拿,兄弟节点也拿不出来的,那就将这个key和两个兄弟合并一下,key会下降下来和两个节点合并。这种提前准备的过程也是“先看看我们要走的子节点需不需要扩容”的逻辑。
主要注意“向兄弟要”和“与父节点的元素合并”两个过程,向兄弟要我们可以向做兄弟要,也可以向右兄弟要。当左右兄弟有要不起的时候,我们只能从左右挑一个兄弟和自己合并。
怎么往左右要节点呢,要的方法当然是我们向左边要最大的节点LMAX,向右边要最小的节点RMIN,我们假设夹在这两个节点之间的key为KEY,其实就是把LMAX放到KEY上,然后再把KEY放到需要key的最右边就好,当然外侧子节点的指针也会换过去。
这里我们再说一下删除的问题。在删之前我们总是要找到这个key吧,我们找这个key的过程首先是要保证一路向下,去找,找的过程中提前做好平衡工作,即防止有一个节点存的内容个数下下边界上,这个和那个添加节点之前提前分裂的逻辑是一样啊。
找到之后如果是叶节点,我们直接删除就好了,如果我们发现我们要删除的东西在非叶节点上我们又要做一些处理。B树是一种特殊的查找树,我们删除的时候实际上是用我们要删除的key是在前趋和后继所在的叶子节点上。如果当前key左叶子的子树个数多于m/2个,那么我们就去递归删除前趋,然后将前趋换到当前节点上来,如果左边子树节点比较小,但是右边节点的大小够,那就去删除和替换后继节点。如果左右大小都不够,那就进行一次合并,然后再递归删除合并节点上的key。实际上如果代码处理的好,是可以一次扫描的。
我们的删除函数也如是设计,首先删除的过程就是一个找节点的过程,找到之后如果是非页节点就递归删除后继或前趋key,然后换过来,也有可能是合并之后的原地递归。我们查找的过程也要提前看看要去的节点规模,然后进行平衡操作。这个函数我们设计为递归函数,递归函数以扫描到叶节点结束。
B树的实现
这次我们在节点中需要实现一个在堆区的指针数组。这个数组的声明要格外注意,注意“*”的位置,也不要加任何的括号:
childArr = new BTreeItem<T>*[Treerank];
B树的实现思路并不难,但是很麻烦,有很多的数组插入操作,实际上我们可以单独提炼为一个函数,这样就可以大大减少代码量。另外分裂、合并、节点的旋转这三个是比较重要的操作,最后就是删除和增加了。删除要的向下查找的过程中以及添加的时候向下遍历的过程也要进行预先处理,控制路径山节点的内容数量。
此外对于非叶节点的删除我们在找不到前趋和后继的替换节点的时候我们也要进行合并。
B+树
B+树是一种对于B树的改进。实现起来也会很不一样,首先就是他的节点子树的数量和节点key数量是一样的。索引为a的子树中的所有值大小在key[a]到key[a+1]的左开右闭区间。B+树的重构过程是要插入之后再统一进行的,特别是删除的时候。
B+树的删除
下面说一下B+树的删除,因为我们删完之后如果删的是某一个(或者非叶节点)叶节点的最大值的话,那么我们要用这个节点的次大值来替换掉父节点的当前子树key[a+1]的值了。因为删除全是叶节点的删除,主要分为这么几种情况。
我们以这个树为例:

正常删除:
我们删除91,这个删除直接作用于叶节点,不会破坏B+树的任何性质。

需要重构的删除:
索引重构,这个是比B树多的一种重构方式,因为B+树的的所有非叶节点都是索引,并且所有的做一年都要在叶子节点的最右边出现。我们看到12、44、59、72、97就是非叶节点元素的所有可能。
所以我们想一个问题,如果删了97或者72怎么办,这就需要重构非叶节点索引,如果一个节点的最大key被删除或者因为key的插入导致最大key被其他的key覆盖,这种我们都要进行向上的索引循环重构。
我们删除一下97或者添加一个100,这都涉及索引重构。
删除97:

除了一般的索引重构,还有在B树中就有的因为删除之后单节点里面的key太少导致的左右旋转重构和合并,B+树在这方面的实现更加简单,B书中我们是先把父节点的东西放到子节点,然后把兄弟节点的东西交给父节点,但是B+树的过程就没有那么难。
比如我想在一开始的树上面删除51,这样会使一个节点只有59了,我们要怎么做?逻辑还是一样的,向兄弟节点直接要就好,然后改一下父节点的索引。


不管怎么挪,我们都要在父节点中将两个子树夹着的这个key改成左边节点最大值的索引。因为这个改动不会影响父节点以上的B+树性质,也完全不需要索引重构,完全没有向上递归的事情。
当然如果从左右节点要不到key的情况下,那就只能进行合并了。还是一开始那棵树,我们删除59:

这就只能合并,合并的方法很简单,左右随便找一个合并就好了,首先,夹在两个节点之间的父节点key会消失,然后两个节点合并并且向上循环重构父索引。

这里有一个比较综合的情况,如果父索引因为少了一个key也导致重构怎么办。这里就涉及子树的处理,非叶节点合并,我们子树数组也合并在一起就好了。如果是从左右两边要key,那就把key对应的子树指针也挪过来就好了。索引的重构是循环向上的,但是节点key值个数的重构如果涉及合并就需要向上递归重构了。
这就是节点删除的所有过程。
B+树的添加
添加简单很多,我觉得很有可能在机试中考。正常的添加我就不再赘述了,如果不涉及重构就加在叶节点上就好了。
和删除一样,我们还是先进行索引重构,然后进行节点key重构,我们在下面的B+树种加入100



这幅图就是索引重构完的结果。这个过程用一个循环算法就好。
然后就是节点重构。

当前节点拆分,m/2索引所在的key复制到父节点中,并且重新调整父节点的子节点指针就好。m/2我们给左边。
非叶节点的拆分也很好办,子树指针也是按照m/2拆分,然后m/2给左边的方式就好了。
我们发现B+树的实现其实更加简单一些。多了一个索引重构的概念。也可能是可以使用父指针向回走的缘故,所以逻辑上比B树简单太多了。
然后我们拆分还有一个问题要注意,因为B+树的叶节点之间是相连的,所以我们在做叶节点的拆分的时候,我们要让左面的节点有一个指针指向右节点。
图
图是一种比树更加宽泛的数据结构。可以是有向图,也可以是无向图。其中,无向图我们可以理解为每条边都是双向的有向图。
图的表示有两种方式,一个是使用“邻接表”,还有一种方式是使用“邻接矩阵”。邻接表是一种特别像哈希表的结构。

最左边是一个线性表,索引是一条边的起点的编号,后面接的是一个链表,这个链表里面就是线性表中节点的所有终点。比如在索引为1的位置后面的链表接的是2和5,那么这就说明图中有1->2和1->5两个边。
还有一种方式是更为简单的邻接矩阵,矩阵的纵索引是边的起点,横索引是边的终点。

这个就是上面那个邻接表对应的邻接矩阵。
这两种实现进行其他的改造都非常合适,比如我们可以在链表中加入一个新的字段来获得带权边的表示,也可以在矩阵中使用一个整数而不是1来表达一个带权图。
广度优先遍历
广度优先遍历的特点就是,与遍历的根节点距离为k+1的节点被遍历之前,所有与遍历根节点距离为k的节点全部都会被遍历。也就是说先遍历所有离遍历根节点近的被遍历,然后再遍历所有离根节点远的。
广度优先遍历和我们之前使用的按层遍历异曲同工,我们为所有的节点标记三种颜色,并且输出除了遍历的结果之外,还有每个节点与遍历的根之间的距离、每个节点在遍历之后形成的树的父节点。这两个内容。每个节点与根之间的距离是用来记录最短距离的,而我们对于父节点的记录可以找出最短路径。
就如上文所说,找出两个节点之间的最短路径是广度优先遍历的一个主要应用。
通常来讲,广度优先所有只有一个源节点,所以最后形成的是一个树的结构,这是因为广度优先遍历可以用来进行最短路径的查找。而我们之后提到的深度优先搜索一般从多个源节点开始,在一开始的逻辑中,深度优先搜索会遍历图中所有的节点,并针对所有的节点递归调用深度优先的遍历,最后,深度优先遍历会优先变为“深度优先森林”,而广度优先搜索会更倾向于变成一个树。遍历的起点从算法的角度来讲并没有并没有强制的规定,这只是揭示了两种算法通常的用法。
广度优先遍历将节点分成三种颜色,一种是黑色的节点,一种是灰色的节点,一种是白色的节点。一开始所有的节点都是白色的。没有被便利到的节点是白色的,黑色的节点是已经被遍历的节点,而灰色的节点是白色和黑色节点之间的分界。是与白色节点还在接壤状态的节点。
广度优先遍历使用一个队列作为实现的中间数据结构,在队列中的所有节点都是灰色的节点,都是还有子节点没有被遍历到的节点,当一个灰色节点从队列中弹出就意味着与这个节点指向的白色节点变成灰色节点并且进入队列。当队列中已经没有元素之后,整个的广度优先遍历就结束了。
我们在实现的过程中还使用了现成的容器类来完成队列的工作。那就是deque,这是一个模板类。C++ STL学习之三:容器deque深入学习
我们主要要记住几个函数,一个是push_XXX,这个函数一个在队列的头部和尾部插入元素,还有一个是pop_XXX,这个函数可以在队列的尾部和头部弹出元素,但是不能将弹出的元素作为返回值返回,所以我们还需要使用front和back两个函数来返回队列头部和尾部的值。
广度优先遍历还是比较简单的,但是要在实现中遇到节点的弹栈和出栈都要时刻注意修改父节点记录、颜色记录、与搜索根之间的距离,三个数组。
深度优先遍历
深度优先遍历我们是以深度为优先级的遍历方式,他的方式和我们之前的那个“迷宫算法”很像,都是使用一个栈结构来存储历史路径,走不下去了,就往回走一个,然后看看还有没有路可以往下走。整个深度优先遍历的停止条件就是这个栈变空了。
为了简化代码实现,实际上我们可以不用执着于使用栈结构,而是使用递归算法,考虑到栈结构的使用需要保存好多中间变量,所以想想还是算了吧。
深度优先遍历保留了存储每个节点在深度优先节点森林中的父节点(深度优先遍历一般不是从单一节点开始的,而是从多个节点都开始的,也就是说深度优先遍历,实际上一定会遍历到图中的所有节点),也保留了每个节点的父节点,以及每个节点“入栈”与“弹栈”的时间戳数组,“时间”是一个全局变量,只要有有节点“变色”就会自增,并且进行记录,只是在递归算法中,栈被隐藏起来了,所以我们只能通过“变色”来判断了。我们会记录两个时间戳,一个是节点从白到灰,一个是节点从灰到黑。
什么时候记录时间戳,我们有一个驱动函数,还有一个递归函数,我们在驱动函数里面不进行任何的其他操作,只去做一些初始化。时间戳的修改、颜色的修改,我们会统一在递归函数中进行,当递归到某一个节点,我们才会进行这些数组的修改。而父节点的设定我们会在调用递归函数的时候进行设置。
此外还有记录节点颜色的临时数组。这个和广度优先搜索是一样的。
深度优先遍历有一个性质叫做括号定理。深度优先遍历最后得到的东西是一个深度优先森林,除非是树的根,要嘛每一个节点都会有祖先节点,之所以被称作括号定理,就是两个节点的出栈以及入栈时间戳要不就是完全不相交,要么就是相互包含。如果相互包含,那么这两个节点一定有祖先和后继的关系。
拓扑排序
拓扑排序就是将一个有向图无环图之间的所有节点进行一个线性排序。也就是排成一条线,然后所有的箭头都会向一个方向指。这个图一般表达了一些事件的先后逻辑顺序,也就是事件A要发生之前必须要发生事件B的关系。下面是一个在算法导论中的例子:

上面这个图表达了穿衣服必须的先后次序。而后面的那个排成一条线的是一个人实际穿衣服的顺序。处理的方式也是比较简单的,我们进行深度优先遍历,将节点按出栈时间戳倒序排列。就形成了一个拓扑排序。
强连通分支
强连通分支的寻找是对拓扑排序和深度优先搜索的一种应用。强连通分支是是图的一个子集,他满足一个非常重要的性质,那就是在强连通分支的节点,两两都是相互可达的,也就是A可以走到B,也可以从B走到A。
强连通分支是简化图的有力工具。因为强连通分支的所有点都是两两可达的,所以我们可以把一个强连通分支简化为一个点,这样子可以进行图的化简。
强连通分支还需要用到图的转置,所谓图的转置就是将图的所有边反向。整个算法一开始就是进行一次深度优先搜索,得出图中所有节点的拓扑排序,然后我们对图进行转置,在新的转置图中我们按照拓扑排序是顺序对所有的所有的节点发动深度优先搜索,在每一次栈为空的时候(也就是递归重新回到驱动函数的时候),所形成的一个个深度优先森林的树就是强连通分支。
最小生成树
最小生成树是在带权图中找一个代价最小的树。而最小生成树需要在无向连通图生成。算法导论在这方面的描述就是玄学,最小生成树的诞生主要有两个算法。一个是克鲁斯卡尔(Kruskal)算法,一个是Prim。
克鲁斯卡尔算法的思想是比较简单的。我们将各边按照权值的大小进行排序,然后不断遍历图,找到权值最小,但是不和已有的选出来的边形成环就好。

这个是一个很重要的例子。整个过程是比较简单的,我们不断寻找新的权值最小的边,如果这个边和我们已经调出来边构成了环,那就忽略这条边,继续向下找。
这个算法的实现还是比较简单的,我们将边都拿出来,然后使用一定的算法进行排序。然后我们不断找出权值最小的边,将边的两个点进行标记,代表说这个边已经在树中的。当新的节点需要加入的时候,我们看看这个新的边的两个顶点是不是已经在树中,如果已经在树中,那就跳过这个边,看看下一个代价比较小的边。
Prim也是一种寻找最小生成树的策略,和克鲁斯卡尔算法不一样的地方是,Prim算法关注的是点,是我们从任意节点作为根来进行最小生成树的构建。我们看树中已有节点接壤的那些边,权值最小、并且不与已有树构成环的边加入树,最后当所有节点都加入树的时候我们的算法就结束了。


这个就是Prim算法的过程,我们将对Kruskal算法进行一下实现。
整个的实现过程还是比较简单的,主要就是分为两步,一个是边的排序,然后按照从小到大的顺序进行边的选择,防止与已有的边构成环路。
单源最短路径问题
实际上我们在广度优先搜索中就提到了最短路径问题,但是在广度优先搜索中,我们每一个边实际上都是权值为“1”的边。我们这里讲的单源最短路径问题就是解决权值大于1的时候我们应该怎么办。
对于单源最短路径,我们需要了解一个叫做“松弛(RELAX)”的操作,这个操作的目的就是找一个新的路径,降低两个点之间的权值。最短路径的查找过程就是一个不断“松弛”的过程,在松弛之后,点于点之间的权值就会变小,最后最短路径就会浮现出来。

在单源最短路径的寻找过程中我们需要两个数组,一个是“前驱结点数组”,一个是“源节点代价估计数组”。前趋节点数组一般用来存对应编号节点的前趋节点,后者用来存储当前我们对节点到源节点之间距离的估计。
松弛技术的算法,是就是当我们找到其他的节点的源节点距离估计和其他节点到当前节点的距离只和比当前节点的距离估计要小的话,那就修改当前节点的距离估计。

我们的整个算法就是进行整个图的RELAX操作。我们一个图中的每一个边都要进行一次RELAX处理,我们这种处理要进行很多轮,要进行的轮数和点的数量-1相等。因为我们知道单源最短路径组成的树最多有节点数量-1个边,而因为我们每进行一轮所有边的RELAX操作至少可以找到一个单源最短路径的树的一条边。这就是我们进行RELAX轮数设置的原则。
对于单源最短路径问题的处理方法实际上很简单,我们使用一个gif就可以一眼望穿。

这个算法的思路主要来源于这个文章:最短路径—Dijkstra算法和Floyd算法
这里给出他的实现。
//这个代表最大的Int值,在初始化中使用,代表不连通的两个点,也代表一开始“最短路径”的初始值const int MAXINT = 32767;//点的数量const int MAXNUM = 10;//和某个源节点最短路径的长度int dist[MAXNUM];//最短路径构成的树的某个节点的前趋节点int prev[MAXNUM];//邻接矩阵,记录了两个点之间的距离int A[MAXUNM][MAXNUM];//形参是起始节点的编号void Dijkstra(int v0) {//S是一个数组,已经找到最短路径的节点就会加入到这个数组中,代表这个节点的单源最短路径已经找到了bool S[MAXNUM];int n = MAXNUM;//这个循环是用来初始化的for (int i = 1; i <= n; ++i) {//将dist进行初始化,让直接与源节点v0相邻的节点的路径长度记录一下dist[i] = A[v0][i];//一开始所有的节点都没有确定和源节点的最短路径,所以全部初始化为falseS[i] = false; // 初始都未用过该点//如果某一个节点和初始节点不直接相连,就把他的前趋节点初始化为-1,代表它没有前驱结点if (dist[i] == MAXINT) {prev[i] = -1;} else {//与初始节点直接向量的前趋节点就是初始节点prev[i] = v0;}}//初始节点的初始化dist[v0] = 0;S[v0] = true;//到这里除了源节点有很多点还没有加入S,也就是说现在除了源节点之外其他节点都没有找到和源节点之间的最短路径。所以我们开始从与源节点距离最短的点开始寻找最短路径。for (int i = 2; i <= n; i++) {int mindist = MAXINT;int u = v0; // 找出当前未使用的点j的dist[j]最小值//这个循环要求找到S集合的邻接节点中和源节点距离最近的节点for (int j = 1; j <= n; ++j) {if ((!S[j]) && dist[j] < mindist) {u = j; // u保存当前邻接点中距离最小的点的号码mindist = dist[j];}}//这个节点和源节点之间的距离就是最近的,并且是可以确定的S[u] = true;//因为新的节点加入了S集合,所以S集合的邻接节点的集合就变大了。所以我们需要更新一下dist,将新的邻接节点的dist更新一下。//这里遍历所有的节点for (int j = 1; j <= n; j++){//如果节点是新的邻接节点并且和新加入S集合的U节点是直接相连的,那么这个节点的与源节点的距离可以算出来。if ((!S[j]) && A[u][j] < MAXINT) {//因为这个邻接节点可能是S集合其他的节点的邻接节点,所以dist可能之前已经找出来了,我们看看通过这个新加入的S集合的节点,能不能找到一个与源节点相连的最短路径。//这个if语句就是进行一个RELAX操作if (dist[u] + A[u][j] < dist[j]) //在通过新加入的u点路径找到离v0点更短的路径{dist[j] = dist[u] + A[u][j]; //更新distprev[j] = u; //记录前驱顶点}}}}}
我们简述一下这个gif的过程,红色,代表这个节点和源节点之间的最短路径已经找到了。一开始红色肯定是源节点1,当1确定下来之后,和红节点相邻的节点的与源节点之间的距离就可以暂时算出来,这些和红节点相邻的节点叫做“邻接节点”,邻接节点和源节点之间的最短路径可以走两条路,一条是通过与红色的节点相连找到通往临界点的最短路径,一种是通过与其他的邻接节点相连找到通往源节点的最短路径。我们要确定一点,那就是一个邻接节点不可能通过与非邻接非红节点相连找到与源节点相通的最短路径。
这个算法的核心思想就是不断从邻接节点中找到与源节点距离最短的节点(这种节点只能通过与红节点相连找到最短路径,所以这种节点是可以直接加入红节点的)加入红节点,然后对与这个新加入红节点相连的节点进行一波RELAX操作,更新他们的最短距离,然后反复进行这个过程,直到所有的节点都已经加入S集合,那么所有节点的单源最短路径就找到了。
在这个实现当中我们也发现了网上这个博主提供的方案的巧妙之处,最外层的for循环直接解决了不可达点的问题for (int i = 2; i <= n; i++) {,也就是说,即便在图中出现了源节点的不可达点,也可以在一定的循环次数之后停止单源最短路径的寻找。
传递闭包
传递闭包有个看起来很厉害的名字,但是实际上是一个很简单的道理。传递闭包是一个矩阵,当一个有向图的一个点可以通过有向图的边到达另外一个点的时候,那么传递闭包矩阵的对应的[i,j]位置就是1。
传递闭包的算法是非常简单的,这里主要要注意的就是位运算的应用。我们遍历所有的节点,并且看看这个节点是不是其他节点的中心节点。
1 warshall(A[1...n,1...n]2 r(0)<-A;3 for(k=1;k<=n;k++)4 for(i=1;i<=n;i++)5 for(j=1;j<=n;j++)6 r(k)[i,j]=r(k-1)[i,j] or(r(k-1)[i,k] and r(k-1)[k,j]);7 return r(n);
这个很“暴力”的算法名称叫做warshall,代码的重点就是第6行,先看or后面的东西,r(k-1)[i,k] and r(k-1)[k,j],这个代表了当a和b相连,b和c相连,那么a和c相连。而且or的代码说明如果两个点已经被证明相连了,那么我们就直接认定为相连。
这个算法的难度非常的低,我们就不再具体进行实现了。
我们在实现中遇到的一些问题
在模板类中进行运算符重载
我们之前尝试在模板类中进行运算符的重载,主要是在为一个模板类重新实现cout打印。但是老是出错,这是为什么,因为我们重载的这个运算符是一个友元函数。也就是说在模板类中不能声明一个带着类型变量T的友元函数,因为编译器会不知道这个T是个什么数据类型,从而报错。我们声明在class上面的上面的那个template对友元函数是不起作用的,因为friend函数并不是这个类的函数。
那么现在问题来了,因为对于cout<<打印这种“<<”左边的类型完全不可能是当前this指针指向的数据类型。所以将运算符的重载放到成员函数中是不可能的。所以我们直接在class声明之外,将运算符的重载作为普通的模板函数声明就好,像这样:
template<class T>class MinMaxLeapItem {friend class MinMaxLeap<T>;public://我们重载一下打印的运算符// friend ostream &operator<<(ostream& out, const MinMaxLeapItem<T>& minMaxLeapItem);//构造函数MinMaxLeapItem(int key, T value);int getKey() const;T getValue() const;private:int key;T value;};template<class T>ostream &operator<<(ostream &out,const MinMaxLeapItem<T>* &minMaxLeapItem) {out << "进入" << endl;out << minMaxLeapItem->getKey() << " , " << minMaxLeapItem->getValue();//递归返回,方便级联调用//并且因为cout并没有实现良好的拷贝构造函数,所以我们必须返回引用return out;};
因为没有了友元函数,所以我们的运算符模板函数不能直接调用类的私有数据成员,我们需要get函数。
引用传参、拷贝传参与const
时刻要记住,C++的const数据类型我们理解为是单独的,也就是说const与const int是两种数据类型,他在必要的时候,int这种普通类型是可以转化为const int这种常量类型的,但是反之就不可以了。
下面我们看一个很有意思的例子。
template<class T>ostream &operator<<(ostream &out,const MinMaxLeapItem<T>* minMaxLeapItem) {out << "进入" << endl;out << minMaxLeapItem->getKey() << " , " << minMaxLeapItem->getValue();//递归返回,方便级联调用//并且因为cout并没有实现良好的拷贝构造函数,所以我们必须返回引用return out;};
对于这样的一个函数,我们cout后面可以接一个MinMaxLeapItem<T>类型的常量以及非常量的指针,因为因为我们是拷贝传值,所以就好像我们把一个int类型的数据赋值给一个const int类型的数据一样。所以我们cout<<后面不管接的是不是常量都是没有事的。那么如果我换一下。
template<class T>ostream &operator<<(ostream &out,const MinMaxLeapItem<T>* &minMaxLeapItem) {out << "进入" << endl;out << minMaxLeapItem->getKey() << " , " << minMaxLeapItem->getValue();//递归返回,方便级联调用//并且因为cout并没有实现良好的拷贝构造函数,所以我们必须返回引用return out;};
好的现在我变成了常量的指针的引用呢。这就不一样了,如果我cout<<后面是一个const类型的指针,那是没事的。如果cout<<后面不是一个常量的指针,那么我们只能打印出一个地址,没有掉起来重载函数。难道不会强制类型转换吗?实际上应该是会的,但是因为cout后面跟非常量指针引用的这个模式已经有默认实现了,所以编译器就不会调用我们重载的那个实现。
所以还是不要用引用这个东西了。
友元关系之间的继承
友元之间是不能继承的,A是B的友元,B是C的友元,那么A并不会是C的友元,并不能调用C的私有数据成员。我们需要在B和C中都声明友元的情况。
函数的缺省形参
函数的有时候声明和实现是分开的,我们只需要在函数声明阶段为函数最后几个形参上面加入缺省形参,但是在函数的实现那个部分就不用再重复声明缺省形参了。
运算符的重载
我们有时候会在类的成员函数中进行运算符的重载,就像这样:
bool operator==(const KruskalEdge otherEage) {if (this->u == otherEage.u && this->v == otherEage.v) {return true;}if (this->u == otherEage.v && this->v == otherEage.u) {return true;}return false;}
这种重载方式比较简洁,但是我们要注意的是如果我们使用这个类的指针是不能调用这个重载的,也就是说上面这个“==”的左边不能是一个类的指针的。我们必须是用一个真正对象和==进行拼接才能调用这个重载运算符函数。
C++常用数据结构的实现的更多相关文章
- JAVA常用数据结构及原理分析
JAVA常用数据结构及原理分析 http://www.2cto.com/kf/201506/412305.html 前不久面试官让我说一下怎么理解java数据结构框架,之前也看过部分源码,balaba ...
- 常用数据结构及复杂度 array、LinkedList、List、Stack、Queue、Dictionary、SortedDictionary、HashSet、SortedSet
原文地址:http://www.cnblogs.com/gaochundong/p/data_structures_and_asymptotic_analysis.html 常用数据结构的时间复杂度 ...
- php常用数据结构
# 常用数据结构--------------------------------------------------------------------------------## 树(Tree)- ...
- Redis常用数据结构
Redis常用数据结构包括字符串(strings),列表(lists),哈希(hashes),集合(sets),有序集合(sorted sets). redis的key最大不能超过512M,可通过re ...
- Java 常用数据结构对象的实现原理 集合类 List Set Map 哪些线程安全 (美团面试题目)
Java中的集合包括三大类,它们是Set.List和Map, 它们都处于java.util包中,Set.List和Map都是接口,它们有各自的实现类. List.Set都继承自Collection接口 ...
- (6)Java数据结构-- 转:JAVA常用数据结构及原理分析
JAVA常用数据结构及原理分析 http://www.2cto.com/kf/201506/412305.html 前不久面试官让我说一下怎么理解java数据结构框架,之前也看过部分源码,balab ...
- 常用数据结构及算法C#/Java实现
常用数据结构及算法C#实现 1.冒泡排序.选择排序.插入排序(三种简单非递归排序) ,, , , , , , , , , }; //冒泡排序 int length = waitSort.Length; ...
- 图解Java常用数据结构(一)【转载】
最近在整理数据结构方面的知识, 系统化看了下Java中常用数据结构, 突发奇想用动画来绘制数据流转过程. 主要基于jdk8, 可能会有些特性与jdk7之前不相同, 例如LinkedList Linke ...
- 图解Java常用数据结构(一)
最近在整理数据结构方面的知识, 系统化看了下Java中常用数据结构, 突发奇想用动画来绘制数据流转过程. 主要基于jdk8, 可能会有些特性与jdk7之前不相同, 例如LinkedList Linke ...
- Java 集合框架(常用数据结构)
早在Java 2中之前,Java就提供了特设类.比如:向量(Vector).栈(Stack).字典(Dictionary).哈希表(Hashtable)这些类(数据结构)用来存储和操作对象组.虽然这些 ...
随机推荐
- Linux下守护进程精析
什么是守护进程? 守护进程就是通常所说的Daemon进程,它是Linux中的后台服务程序. 它是一个生存期较长的进程,通常独立于终端而且周期性的运行某种须要的任务以及有时候会等待一些将会发生的 ...
- 《机器学习实战》基于朴素贝叶斯分类算法构建文本分类器的Python实现
============================================================================================ <机器学 ...
- 【MySQL集群】——Java程序连接MySQL集群
上篇简介了怎样在Windows环境下建立配置MySQL集群,这里用一个实现注冊功能的小Demo通过jdbc的方式连接到MySQL集群中. 外部程序想要远程连接到mysql集群,还须要做的一个操作就是设 ...
- Maven学习总结(18)——深入理解Maven仓库
一.本地仓库(Local Repository) 本地仓库就是一个本机的目录,这个目录被用来存储我们项目的所有依赖(插件的jar包还有一些其他的文件),简单的说,当你build一个Maven项目的时候 ...
- 各大免费邮箱邮件群发账户SMTP服务器配置及SMTP发送量限制情况
网络产品推广和新闻消息推送时,经常用到的工具就是用客户邮箱发送邮件了,如果是要发送的邮件量非常大的话,一般的建议是搭建自己的邮局服务器,或者是花钱购买专业的邮件群发服务,免费邮箱的SMTP适合少量的邮 ...
- Hbase技术详细学习笔记
注:转自 Hbase技术详细学习笔记 最近在逐步跟进Hbase的相关工作,由于之前对Hbase并不怎么了解,因此系统地学习了下Hbase,为了加深对Hbase的理解,对相关知识点做了笔记,并在组内进行 ...
- 洛谷——P1096 Hanoi双塔问题
https://www.luogu.org/problem/show?pid=1096 题目描述 给定A.B.C三根足够长的细柱,在A柱上放有2n个中间有孔的圆盘,共有n个不同的尺寸,每个尺寸都有两个 ...
- [D3] Add label text
If we want to add text to a node or a image // Create container for the images const svgNodes = svg ...
- 例说linux内核与应用数据通信(一):加入一个系统调用
[版权声明:尊重原创.转载请保留出处:blog.csdn.net/shallnet,文章仅供学习交流,请勿用于商业用途] 应用不能訪问内核的内存空间.为了应用和内核交互信息,内核提供一 ...
- Spring-data-redis:特性与实例--转载
原文地址:http://shift-alt-ctrl.iteye.com/blog/1886831 Spring-data-redis为spring-data模块中对redis的支持部分,简称为“SD ...