Elasticsearch之批量操作bulk
1、bulk相当于数据库里的bash操作。
2、引入批量操作bulk,提高工作效率,你想啊,一批一批添加与一条一条添加,谁快?
3、bulk API可以帮助我们同时执行多个请求
4、bulk的格式:
action:index/create/update/delete
metadata:_index,_type,_id
request body:_source (删除操作不需要加request body)
{ action: { metadata }}
{ request body }
5、bulk里为什么不支持get呢?
答:批量操作,里面放get操作,没啥用!所以,官方也不支持。
6、create 和index的区别
如果数据存在,使用create操作失败,会提示文档已经存在,使用index则可以成功执行。
7、bulk一次最大处理多少数据量?
bulk会把将要处理的数据载入内存中,所以数据量是有限制的,最佳的数据量不是一个确定的数值,它取决于你的硬件,你的文档大小以及复杂性,你的索引以及搜索的负载。
一般建议是1000-5000个文档,如果你的文档很大,可以适当减少队列,大小建议是5-15MB,默认不能超过100M,可以在es的配置文件(即$ES_HOME下的config下的elasticsearch.yml)中。
elasticsearch-.yml(中文配置详解)
来修改这个值http.max_content_length: 100mb【不建议修改,太大的话bulk也会慢】,
https://www.elastic.co/guide/en/elasticsearch/reference/2.4/modules-http.html
批量操作bulk例子
(1) 比如,我这里,在$ES_HOME里,新建一文件,命名为request。(这里为什么命名为request,去看官网就是)在Linux里,有无后缀没区别。
[hadoop@djt002 elasticsearch-2.4.3]$ pwd
/usr/local/elasticsearch/elasticsearch-2.4.3
[hadoop@djt002 elasticsearch-2.4.3]$ ll
total 56
drwxrwxr-x. 2 hadoop hadoop 4096 Feb 20 22:54 bin
drwxrwxr-x. 3 hadoop hadoop 4096 Feb 21 01:28 config
drwxrwxr-x. 3 hadoop hadoop 4096 Feb 20 22:59 data
drwxrwxr-x. 2 hadoop hadoop 4096 Feb 20 22:54 lib
-rw-rw-r--. 1 hadoop hadoop 11358 Aug 24 00:46 LICENSE.txt
drwxrwxr-x. 2 hadoop hadoop 4096 Feb 21 00:33 logs
drwxrwxr-x. 5 hadoop hadoop 4096 Dec 8 00:41 modules
-rw-rw-r--. 1 hadoop hadoop 150 Aug 24 00:46 NOTICE.txt
drwxrwxr-x. 2 hadoop hadoop 4096 Feb 20 22:59 plugins
-rw-rw-r--. 1 hadoop hadoop 8700 Aug 24 00:46 README.textile
[hadoop@djt002 elasticsearch-2.4.3]$ vim request
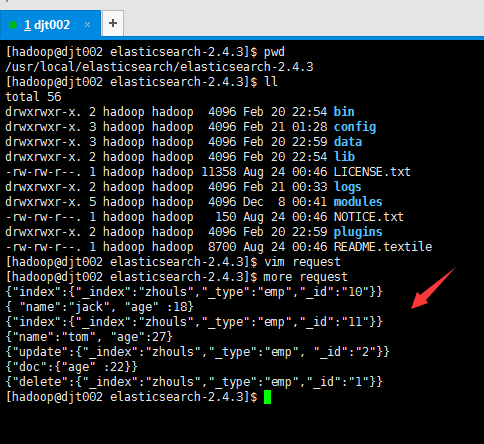
[hadoop@djt002 elasticsearch-2.4.3]$ more request
{"index":{"_index":"zhouls","_type":"emp","_id":"10"}}
{ "name":"jack", "age" :18}
{"index":{"_index":"zhouls","_type":"emp","_id":"11"}}
{"name":"tom", "age":27}
{"update":{"_index":"zhouls","_type":"emp", "_id":"2"}}
{"doc":{"age" :22}}
{"delete":{"_index":"zhouls","_type":"emp","_id":"1"}}
[hadoop@djt002 elasticsearch-2.4.3]$
或者
{ "index" : {"_index":"zhouls","_type":"emp","_id":"21"}}
{ "name" : "test21"}
例子:
{ "index" : { "_index" : "zhouls", "_type" : "type1", "_id" : "1" } }
{ "field1" : "value1" }
{ "index" : { "_index" : "zhouls", "_type" : "type1", "_id" : "2" } }
{ "field1" : "value1" }
{ "delete" : { "_index" : "zhouls", "_type" : "type1", "_id" : "2" } } (删除操作不需要加request body)
{ "create" : { "_index" : "zhouls", "_type" : "type1", "_id" : "3" } }
{ "field1" : "value3" }
{ "update" : {"_index" : "zhouls", "_type" : "type1","_id" : "1" } }
{ "doc" : {"field2" : "value2"} }
(2)使用文件的方式
vi requests
写入批量操作语句。比如,下面
{"index":{"_index":"zhouls","_type":"emp","_id":"10"}}
{ "name":"jack", "age" :18}
{"index":{"_index":"zhouls","_type":"emp","_id":"11"}}
{"name":"tom", "age":27}
{"update":{"_index":"zhouls","_type":"emp", "_id":"2"}}
{"doc":{"age" :22}}
{"delete":{"_index":"zhouls","_type":"emp","_id":"1"}}
在$ES_HOME目录下,执行下面命令
curl -PUT '192.168.80.200:9200/_bulk' --data-binary @request;
或
curl -XPOST '192.168.80.200:9200/_bulk' --data-binary @request;

[hadoop@djt002 elasticsearch-2.4.3]$ curl -PUT '192.168.80.200:9200/_bulk' --data-binary @request;
{"took":123,"errors":true,"items":[{"index":{"_index":"zhouls","_type":"emp","_id":"10","_version":1,"_shards":{"total":2,"successful":1,"failed":0},"status":201}},{"index":{"_index":"zhouls","_type":"emp","_id":"11","_version":1,"_shards":{"total":2,"successful":1,"failed":0},"status":201}},{"update":{"_index":"zhouls","_type":"emp","_id":"2","status":404,"error":{"type":"document_missing_exception","reason":"[emp][2]: document missing","index":"zhouls","shard":"-1"}}},{"delete":{"_index":"zhouls","_type":"emp","_id":"1","_version":1,"_shards":{"total":2,"successful":1,"failed":0},"status":404,"found":false}}]}[hadoop@djt002 elasticsearch-2.4.3]$
之后,再查看下。
[hadoop@djt002 elasticsearch-2.4.3]$ curl -XGET 'http://192.168.80.200:9200/zhouls/emp/?pretty'
{
"_index" : "zhouls",
"_type" : "emp",
"_id" : "1",
"found" : false
}
[hadoop@djt002 elasticsearch-2.4.3]$ curl -XGET 'http://192.168.80.200:9200/zhouls/emp/?pretty'
{
"_index" : "zhouls",
"_type" : "emp",
"_id" : "2",
"found" : false
}
[hadoop@djt002 elasticsearch-2.4.3]$ curl -XGET 'http://192.168.80.200:9200/zhouls/emp/?pretty'
{
"_index" : "zhouls",
"_type" : "emp",
"_id" : "11",
"_version" : 4,
"found" : true,
"_source" : {
"name" : "tom",
"age" : 27
}
}
[hadoop@djt002 elasticsearch-2.4.3]$ curl -XGET 'http://192.168.80.200:9200/zhouls/emp/?pretty'
{
"_index" : "zhouls",
"_type" : "emp",
"_id" : "10",
"_version" : 4,
"found" : true,
"_source" : {
"name" : "jack",
"age" : 18
}
}
(3) bulk请求可以在URL中声明/_index 或者/_index/_type
这个,自行去测试!
官网
https://www.elastic.co/guide/en/elasticsearch/reference/current/docs-bulk.html
Elasticsearch之批量操作bulk的更多相关文章
- Elasticsearch批处理操作——bulk API
Elasticsearch提供的批量处理功能,是通过使用_bulk API实现的.这个功能之所以重要,在于它提供了非常高效的机制来尽可能快的完成多个操作,与此同时使用尽可能少的网络往返. 1.批量索引 ...
- 利用kibana插件对Elasticsearch进行批量操作
#############批量获取################# #获取所有数据 GET _mget { "docs": [ {"_index":" ...
- elasticsearch 中文API bulk(六)
bulk API bulk API允许开发者在一个请求中索引和删除多个文档.下面是使用实例. import static org.elasticsearch.common.xcontent.XCont ...
- Elasticsearch之CURL命令的bulk批量操作
大家,也可去看看我下面的博客 Elasticsearch之批量操作bulk 官网上,是举例了新建一个requests文件. [hadoop@master elasticsearch-]$ pwd /h ...
- elasticsearch使用bulk实现批量操作
本篇文章提供ES原生批量操作语法及使用bulk批量操作文档.文章依旧提供语法,具体实现大家根据语法,在对应处进行替换即可 一.原生批量获取文档 1.获取指定文档值(1) 语法: GET /_mget ...
- ElasticSearch(二):文档的基本CRUD与批量操作
ElasticSearch(二):文档的基本CRUD与批量操作 学习课程链接<Elasticsearch核心技术与实战> Create 文档 支持自动生成文档_id和指定文档_id两种方式 ...
- 【Elasticsearch 7 探索之路】(二)文档的 CRUD 和批量操作
上一篇,我们介绍了什么是 Elasticsearch,它能做什么用以及基本概念(索引 Index.文档 Document.类型 Type)理解.这篇主要对 文档的基本 CRUD 和 倒排索引进行讲解. ...
- 《读书报告 -- Elasticsearch入门 》-- 安装以及简单使用(1)
<读书报告 – Elasticsearch入门 > 第一章 Elasticsearch入门 Elasticsearch是一个实时的分布式搜索和分析引擎,使得人们可以在一定规模上和一定速度上 ...
- ElasticSearch的基本认识和基本操作
1.1. ElasticSearch(简称ES) ES即为了解决原生Lucene使用的不足,优化Lucene的调用方式,并实现了高可用的分布式集群的搜索方案,其第一个版本于2010年2月出现在Git ...
随机推荐
- 利用shell脚本去备份幸运28源码搭建下载所指定的数据库
#! /bin/bash幸运28源码搭建下载Q[115288oo99]logintool=/home/yx/server/mysql/mysql/bin/mysqldumptool=/home/yx/ ...
- 关于桌面程序被安全软件误判为HEUR:Trojan.Win32.Generic的解决方案
最近写了一个桌面程序,里面用了些读取系统环境变量.提取文件图标.启动外部程序之类的操作. 然后…………卡巴斯基就把它识别成了HEUR:Trojan.Win32.Generic………… 咱遵纪守法好程序 ...
- 【vue】vue中实现标签页
前言 tab标签页实现很多, 纯css实现, js实现等, 外加一些特殊动画. vue中实现标签页实现 keep-alive标签和is特性 vue-router中嵌套路由 is特性实现(推荐) 优点: ...
- SGU180 Inversions(树状数组求逆序数)
题目: 思路:先离散化数据然后树状数组搞一下求逆序数. 离散化的方法:https://blog.csdn.net/gokou_ruri/article/details/7723378 自己对用树状数组 ...
- sql server的 between and 日期问题
- 关于PyQt5,在pycharm上的安装步骤及使用技巧
前序 之前学习了一款GUI图形界面设计的Tkinter库,但是经大佬的介绍,PyQT5全宇宙最强,一脸的苦笑 毫不犹豫的选择转战PyQT5,在学习之前需要先安装一些必须程序,在一番查阅后,发现PyQt ...
- bootstrap下的双选时间插件使用方法
bootstrap画的页面很漂亮,能自动适应网页端,移动端.实现一个双选时间控件: 要得jar包自己去下 一.页面 二.JS var $createTime=$('#createTime');$cre ...
- Servlet中使用RequestDispatcher调派请求--forware
顺便演示了MVC的作法,以后hello.view可以移交到jsp中处理. 而MODEL和CONTROL,VIEW就实现了分享. HelloModel.java: package cc.openhome ...
- Cash Machine POJ 1276 多重背包
Time Limit: 1000MS Memory Limit: 10000K Total Submissions: 35387 Accepted: 12816 Description A B ...
- 个人博客搭建----基于solo
个人站地址是:http://www.iwillhaveacatoneday.cn 博客是基于开源的Java 博客系统--solo搭建的,这里记录下部署过程中遇到的一些主要问题 后台 solo后台采的是 ...