[置顶] Linux 常用命令集锦
出处:http://www.vaikan.com/what-are-the-most-useful-swiss-army-knife-one-liners-on-unix/
Linux命令行里的“瑞士军刀”

这里说的“瑞士军刀”是指那些简单的一句命令就能完成其它高级语言一大片代码才能完成的工作。
下面的这些内容是Quora网站上Joshua
Levy网友的总结:
- 通过sort/uniq获取文件内容的交集、合集和不同之处:假设有a、b两个文本文件,文件本身已经去除了重复内容。下面是效率最高的方法,可以处理任何体积的文件,甚至几个G的文件。(Sort对内存没有要求,但也许你需要用 -T 参数。)可以试着比较一下,你可以看看如果用Java来处理磁盘上文件的合并,需要用多少行代码。
cat a b | sort | uniq > c # c 是a和b的合集
cat a b | sort | uniq -d > c # c 是a和b的交集
cat a b b | sort | uniq -u > c # c 是a和b的不同
- 汇总一个文本内容里第三列数字的和(这个方法要比用Python来做快3倍并只需1/3的代码量):
awk ‘{ x += $3 } END { print x }’ myfile
- 如果你想查看一个目录树里的文件的体积和修改日期,用下面的方法,相当于你挨个目录做”ls -l”,而且输出的形式比你用”ls -lR”更可读:
find . -type f -ls
- 使用xargs命令。这个命令非常的强大。注意每行上你可以控制多少个东西的执行。如果你不确定它是正确的执行,先使用xargs echo。同样,-I{} 也非常有用。例子:
find . -name \*.py | xargs grep some_function
cat hosts | xargs -I{} ssh root@{} hostname
- 假设你有一个文本文件,比如一个web服务器日志,在某些行上有一些值,比如URL中的acct_id参数。如果你想统计每个acct_id的所有请求记录:
cat access.log | egrep -o ‘acct_id=[0-9]+’ | cut -d= -f2 | sort | uniq -c | sort -rn
--------------------------------------------------------------------------------
每个程序员都应该知道的8个Linux命令
每个程序员,在职业生涯的某个时刻,总会发现自己需要知道一些Linux方面的知识。我并不是说你应该成为一个Linux专家,我的意思是,当面对linux命令行任务时,你应该能很熟练的完成。事实上,学会了下面8个命令,我基本上能完成任何需要完成的任务。
注意:下面的每个命令都有十分丰富的文档说明。这篇文章并不是来详尽的展示每个命令的各种功用的。我在这里要讲的是这几个最常用的命令的最常见用法。如果你对linux命令并不是很了解,你想找一些这方面的资料学习,那这篇文章将会给你一个基本的指导。
让我们从处理一些数据开始。假设我们有两个文件,分别记录的订单清单和订单处理结果。
order.out.log
8:22:19 111, 1, Patterns of Enterprise Architecture, Kindle edition, 39.99
8:23:45 112, 1, Joy of Clojure, Hardcover, 29.99
8:24:19 113, -1, Patterns of Enterprise Architecture, Kindle edition, 39.99 order.in.log
8:22:20 111, Order Complete
8:23:50 112, Order sent to fulfillment
8:24:20 113, Refund sent to processing
cat
cat –
连接文件,并输出结果
cat 命令非常的简单,你从下面的例子可以看到。
jfields$ cat order.out.log
8:22:19 111, 1, Patterns of Enterprise Architecture, Kindle edition, 39.99
8:23:45 112, 1, Joy of Clojure, Hardcover, 29.99
8:24:19 113, -1, Patterns of Enterprise Architecture, Kindle edition, 39.99
就像它的说明描述的,你可以用它来连接多个文件。
jfields$ cat order.*
8:22:20 111, Order Complete
8:23:50 112, Order sent to fulfillment
8:24:20 113, Refund sent to processing
8:22:19 111, 1, Patterns of Enterprise Architecture, Kindle edition, 39.99
8:23:45 112, 1, Joy of Clojure, Hardcover, 29.99
8:24:19 113, -1, Patterns of Enterprise Architecture, Kindle edition, 39.99
如果你想看这些log文件的内容,你可以把它们连接起来并输出到标准输出上,就是上面的例子展示的。这很有用,但输出的内容可以更有逻辑些。
sort
sort –
文件里的文字按行排序
此时sort命令显然是你最佳的选择。
jfields$ cat order.* | sort
8:22:19 111, 1, Patterns of Enterprise Architecture, Kindle edition, 39.99
8:22:20 111, Order Complete
8:23:45 112, 1, Joy of Clojure, Hardcover, 29.99
8:23:50 112, Order sent to fulfillment
8:24:19 113, -1, Patterns of Enterprise Architecture, Kindle edition, 39.99
8:24:20 113, Refund sent to processing
就像上面例子显示的,文件里的数据已经经过排序。对于一些小文件,你可以读取整个文件来处理它们,然而,真正的log文件通常有大量的内容,你不能不考虑这个情况。此时你应该考虑过滤出某些内容,把cat、sort后的内容通过管道传递给过滤工具。
grep
grep,
egrep, fgrep – 打印出匹配条件的文字行
假设我们只对Patterns of Enterprise Architecture这本书的订单感兴趣。使用grep,我们能限制只输出含有Patterns字符的订单。
jfields$ cat order.* | sort | grep Patterns
8:22:19 111, 1, Patterns of Enterprise Architecture, Kindle edition, 39.99
8:24:19 113, -1, Patterns of Enterprise Architecture, Kindle edition, 39.99
假设退款订单113出了一些问题,你希望查看所有相关订单——你又需要使用grep了。
jfields$ cat order.* | sort | grep ":\d\d 113, "
8:24:19 113, -1, Patterns of Enterprise Architecture, Kindle edition, 39.99
8:24:20 113, Refund sent to processing
你会发现在grep上的匹配模式除了“113”外还有一些其它的东西。这是因为113还可以匹配上书目或价格,加上额外的字符后,我们可以精确的搜索到我们想要的东西。
现在我们已经知道了退货的详细信息,我们还想知道日销售和退款总额。但我们只关心Patterns of Enterprise Architecture这本书的信息,而且只关心数量和价格。我现在要做到是切除我们不关心的任何信息。
cut
cut –
删除文件中字符行上的某些区域
又要使用grep,我们用grep过滤出我们想要的行。有了我们想要的行信息,我们就可以把它们切成小段,删除不需要的部分数据。
jfields$ cat order.* | sort | grep Patterns
8:22:19 111, 1, Patterns of Enterprise Architecture, Kindle edition, 39.99
8:24:19 113, -1, Patterns of Enterprise Architecture, Kindle edition, 39.99 jfields$ cat order.* | sort | grep Patterns | cut -d"," -f2,5
1, 39.99
-1, 39.99
现在,我们把数据缩减为我们计算想要的形式,把这些数据粘贴到Excel里立刻就能得到结果了。
cut是用来消减信息、简化任务的,但对于输出内容,我们通常会有更复杂的形式。假设我们还需要知道订单的ID,这样可以用来关联相关的其他信息。我们用cut可以获得ID信息,但我们希望把ID放到行的最后,用单引号包上。
sed
sed –
一个流编辑器。它是用来在输入流上执行基本的文本变换。
下面的例子展示了如何用sed命令变换我们的文件行,之后我们在再用cut移除无用的信息。
jfields$ cat order.* | sort | grep Patterns \
>| sed s/"[0-9\:]* \([0-9]*\)\, \(.*\)"/"\2, '\1'"/
1, Patterns of Enterprise Architecture, Kindle edition, 39.99, '111'
-1, Patterns of Enterprise Architecture, Kindle edition, 39.99, '113' lmp-jfields01:~ jfields$ cat order.* | sort | grep Patterns \
>| sed s/"[0-9\:]* \([0-9]*\)\, \(.*\)"/"\2, '\1'"/ | cut -d"," -f1,4,5
1, 39.99, '111'
-1, 39.99, '113'
我们对例子中使用的正则表达式多说几句,不过也没有什么复杂的。正则表达式做了下面几种事情
- 删除时间戳
- 捕捉订单号
- 删除订单号后的逗号和空格
- 捕捉余下的行信息
里面的引号和反斜杠有点乱,但使用命令行时必须要用到这些。
一旦捕捉到了我们想要的数据,我们可以使用 \1 & \2 来存储它们,并把它们输出成我们想要的格式。我们还在其中加入了要求的单引号,为了保持格式统一,我们还加入了逗号。最后,用cut命令把不必要的数据删除。
现在我们有麻烦了。我们上面已经演示了如何把log文件消减成更简洁的订单形式,但我们的财务部门需要知道订单里一共有哪些书。
uniq
uniq –
删除重复的行
下面的例子展示了如何过滤出跟书相关的交易,删除不需要的信息,获得一个不重复的信息。
jfields$ cat order.out.log | grep "\(Kindle\|Hardcover\)" | cut -d"," -f3 | sort | uniq -c
1 Joy of Clojure
2 Patterns of Enterprise Architecture
看起来这是一个很简单的任务。
这都是很好用的命令,但前提是你要能找到你想要的文件。有时候你会发现一些文件藏在很深的文件夹里,你根本不知道它们在哪。但如果你是知道你要寻找的文件的名字的话,这对你就不是个问题了。
find
find –
在文件目录中搜索文件
在上面的例子中我们处理了order.in.log和order.out.log这两个文件。这两个文件放在我的home目录里的。下面了例子将向大家展示如何在一个很深的目录结构里找到这样的文件。
jfields$ find /Users -name "order*"
Users/jfields/order.in.log
Users/jfields/order.out.log
find命令有很多其它的参数,但99%的时间里我只需要这一个就够了。
简单的一行,你就能找到你想要的文件,然后你可以用cat查看它,用cut修剪它。但文件很小时,你用管道把它们输出到屏幕上是可以的,但当文件大到超出屏幕时,你也许应该用管道把它们输出给less命令。
less
less –
在文件里向前或向后移动
让我们再回到简单的 cat | sort 例子中来,下面的命令就是将经过合并、排序后的内容输出到less命令里。在 less 命令,使用“/”来执行向前搜索,使用“?”命令执行向后搜索。搜索条件是一个正则表达式。
jfields$ cat order* | sort | less
如果你在 less 命令里使用 /113.*,所有113订单的信息都会高亮。你也可以试试?.*112,所有跟订单112相关的时间戳都会高亮。最后你可以用 ‘q’ 来退出less命令。
linux里有很丰富的各种命令,有些是很难用的。然而,学会了前面说的这8个命令,你已经能处理大量的log分析任务了,完全不需要用脚本语言写程序来处理它们。
--------------------------------------------------------------------------------
最常用的Linux命令简表

{kind=link}
--------------------------------------------------------------------------------
Linux技巧:一次删除一百万个文件的最快方法

最初的测评
昨天,我看到一个非常有趣的删除一个目录下的海量文件的方法。这个方法来自http://www.quora.com/How-can-someone-rapidly-delete-400-000-files里的Zhenyu
Lee。
他没有使用find 或 xargs,他很有创意的利用了rsync的强大功能,使用rsync将目标文件夹以一个空文件夹来替换。之后,我做了一个实验来比较各种方法。让我吃惊的是,Lee的方法要比其它的快的多。下面就是我的测评。
–delete
环境:
- CPU: Intel(R) Core(TM)2 Duo CPU E8400 @ 3.00GHz
- MEM: 4G
- HD: ST3250318AS: 250G/7200RPM
| Method | # Of Files | Deletion Time |
|---|---|---|
| rsync -a –delete empty/ s1/ | 1000000 | 6m50.638s |
| find s2/ -type f -delete | 1000000 | 87m38.826s |
| find s3/ -type f | xargs -L 100 rm | 1000000 | 83m36.851s |
| find s4/ -type f | xargs -L 100 -P 100 rm | 1000000 | 78m4.658s |
| rm -rf s5 | 1000000 | 80m33.434s |
使用 –delete 和 –exclude,你可以选择性删除符合条件的文件。还有一点,当你需要保留这个目录做其它用处时,这种方法是再适合不过了。
重新测评
几天前,Keith-Winstein在回复Quora上的这个帖子时说我之前的测评无法复制,因为操作的时间持续的太久。我澄清一下,这些数据过大,可能是因为我的计算机在过去的几年里做的事太多,测评中可能存在一些文件系统错误。但我不确定是这些原因。现在好了,我弄了一天比较新的计算机,把测评再做一次。这次我使用/usr/bin/time,它能提供更详细的信息。下面就是新的结果。
(每次都是1000000个文件。每个文件的体积都是0。)
| Command | Elapsed | System Time | %CPU | cs (Vol/Invol) |
|---|---|---|---|---|
| rsync -a –delete empty/ a | 10.60 | 1.31 | 95 | 106/22 |
| find b/ -type f -delete | 28.51 | 14.46 | 52 | 14849/11 |
| find c/ -type f | xargs -L 100 rm | 41.69 | 20.60 | 54 | 37048/15074 |
| find d/ -type f | xargs -L 100 -P 100 rm | 34.32 | 27.82 | 89 | 929897/21720 |
| rm -rf f | 31.29 | 14.80 | 47 | 15134/11 |
原始输出
# method 1
~/test $ /usr/bin/time -v rsync -a --delete empty/ a/
Command being timed: "rsync -a --delete empty/ a/"
User time (seconds): 1.31
System time (seconds): 10.60
Percent of CPU this job got: 95%
Elapsed (wall clock) time (h:mm:ss or m:ss): 0:12.42
Average shared text size (kbytes): 0
Average unshared data size (kbytes): 0
Average stack size (kbytes): 0
Average total size (kbytes): 0
Maximum resident set size (kbytes): 0
Average resident set size (kbytes): 0
Major (requiring I/O) page faults: 0
Minor (reclaiming a frame) page faults: 24378
Voluntary context switches: 106
Involuntary context switches: 22
Swaps: 0
File system inputs: 0
File system outputs: 0
Socket messages sent: 0
Socket messages received: 0
Signals delivered: 0
Page size (bytes): 4096
Exit status: 0 # method 2
Command being timed: "find b/ -type f -delete"
User time (seconds): 0.41
System time (seconds): 14.46
Percent of CPU this job got: 52%
Elapsed (wall clock) time (h:mm:ss or m:ss): 0:28.51
Average shared text size (kbytes): 0
Average unshared data size (kbytes): 0
Average stack size (kbytes): 0
Average total size (kbytes): 0
Maximum resident set size (kbytes): 0
Average resident set size (kbytes): 0
Major (requiring I/O) page faults: 0
Minor (reclaiming a frame) page faults: 11749
Voluntary context switches: 14849
Involuntary context switches: 11
Swaps: 0
File system inputs: 0
File system outputs: 0
Socket messages sent: 0
Socket messages received: 0
Signals delivered: 0
Page size (bytes): 4096
Exit status: 0
# method 3
find c/ -type f | xargs -L 100 rm
~/test $ /usr/bin/time -v ./delete.sh
Command being timed: "./delete.sh"
User time (seconds): 2.06
System time (seconds): 20.60
Percent of CPU this job got: 54%
Elapsed (wall clock) time (h:mm:ss or m:ss): 0:41.69
Average shared text size (kbytes): 0
Average unshared data size (kbytes): 0
Average stack size (kbytes): 0
Average total size (kbytes): 0
Maximum resident set size (kbytes): 0
Average resident set size (kbytes): 0
Major (requiring I/O) page faults: 0
Minor (reclaiming a frame) page faults: 1764225
Voluntary context switches: 37048
Involuntary context switches: 15074
Swaps: 0
File system inputs: 0
File system outputs: 0
Socket messages sent: 0
Socket messages received: 0
Signals delivered: 0
Page size (bytes): 4096
Exit status: 0 # method 4
find d/ -type f | xargs -L 100 -P 100 rm
~/test $ /usr/bin/time -v ./delete.sh
Command being timed: "./delete.sh"
User time (seconds): 2.86
System time (seconds): 27.82
Percent of CPU this job got: 89%
Elapsed (wall clock) time (h:mm:ss or m:ss): 0:34.32
Average shared text size (kbytes): 0
Average unshared data size (kbytes): 0
Average stack size (kbytes): 0
Average total size (kbytes): 0
Maximum resident set size (kbytes): 0
Average resident set size (kbytes): 0
Major (requiring I/O) page faults: 0
Minor (reclaiming a frame) page faults: 1764278
Voluntary context switches: 929897
Involuntary context switches: 21720
Swaps: 0
File system inputs: 0
File system outputs: 0
Socket messages sent: 0
Socket messages received: 0
Signals delivered: 0
Page size (bytes): 4096
Exit status: 0 # method 5
~/test $ /usr/bin/time -v rm -rf f
Command being timed: "rm -rf f"
User time (seconds): 0.20
System time (seconds): 14.80
Percent of CPU this job got: 47%
Elapsed (wall clock) time (h:mm:ss or m:ss): 0:31.29
Average shared text size (kbytes): 0
Average unshared data size (kbytes): 0
Average stack size (kbytes): 0
Average total size (kbytes): 0
Maximum resident set size (kbytes): 0
Average resident set size (kbytes): 0
Major (requiring I/O) page faults: 0
Minor (reclaiming a frame) page faults: 176
Voluntary context switches: 15134
Involuntary context switches: 11
Swaps: 0
File system inputs: 0
File system outputs: 0
Socket messages sent: 0
Socket messages received: 0
Signals delivered: 0
Page size (bytes): 4096
Exit status: 0
我真的十分好奇为什么Lee的方法要比其它的快,竟然比rm -rf也要快。如果有人知道,请写在下面,非常感谢。
--------------------------------------------------------------------------------
应该知道的Linux技巧
这篇文章来源于Quroa的一个问答《What are some time-saving tips that every Linux user
should know?》—— Linux用户有哪些应该知道的提高效率的技巧。我觉得挺好的,总结得比较好,把其转过来,并加了一些自己的理解。 首先,我想告诉大家,在Unix/Linux下,最有效率技巧的不是操作图形界面,而是命令行操作,因为命令行意味着自动化。如果你看过《你可能不知道的Shell》以及《28个Unix/Linux的命令行神器》你就会知道Linux有多强大,这个强大完全来自于命令行,于是,就算你不知道怎么去做一个环保主义的程序员,至少他们可以让你少熬点夜,从而有利于你的身体健康和性生活。下面是一个有点长的列表,正如作者所说,你并不需要知道所有的这些东西,但是如果你还在很沉重地在使用Linux的话,这些东西都值得你看一看。
(注:如果你想知道下面涉及到的命令的更多的用法,你一定要man一点。对于一些命令,你可以需要先yum或apt-get来安装一下,如果有什么问题,别忘了Google。如果你要Baidu的话,我仅代表这个地球上所有的生物包括微生物甚至细菌病毒和小强BS你到宇宙毁灭)
基础
- 学习 Bash 。你可以man bash来看看bash的东西,并不复杂也并不长。你用别的shell也行,但是bash是很强大的并且也是系统默认的。(学习zsh或tsch只会让你在很多情况下受到限制)
- 学习 vim 。在Linux下,基本没有什么可与之竞争的编
译辑器(就算你是一个Emacs或Eclipse的重度用户)。你可以看看《简明vim攻略》和
《Vim的冒险游戏》以及《给程序员的Vim速查卡》还有《把Vim变成一个编程的IDE》等等。
- 了解 ssh。明白不需要口令的用户认证(通过ssh-agent, ssh-add),学会用ssh翻墙,用scp而不是ftp传文件,等等。你知道吗?scp 远端的时候,你可以按tab键来查看远端的目录和文件(当然,需要无口令的用户认证),这都是bash的功劳。
- 熟悉bash的作业管理,如: &, Ctrl-Z, Ctrl-C, jobs, fg, bg, kill, 等等。当然,你也要知道Ctrl+\(SIGQUIT)和Ctrl+C (SIGINT)的区别。
- 简单的文件管理 : ls 和 ls -l (你最好知道 “ls -l” 的每一列的意思), less, head, tail 和 tail -f, ln 和 ln -s (你知道明白hard link和soft link的不同和优缺点), chown, chmod, du (如果你想看看磁盘的大小 du -sk *), df,
mount。当然,原作者忘了find命令。
- 基础的网络管理: ip 或 ifconfig, dig。当然,原作者还忘了如netstat, ping, traceroute, 等
- 理解正则表达式,还有grep/egrep的各种选项。比如: -o, -A, 和 -B 这些选项是很值得了解的。
- 学习使用 apt-get 和 yum 来查找和安装软件(前者的经典分发包是Ubuntu,后者的经典分发包是Redhat),我还建议你试着从源码编译安装软件。
日常
- 在 bash 里,使用 Ctrl-R 而不是上下光标键来查找历史命令。
- 在 bash里,使用 Ctrl-W 来删除最后一个单词,使用 Ctrl-U 来删除一行。请man bash后查找Readline Key Bindings一节来看看bash的默认热键,比如:Alt-. 把上一次命令的最后一个参数打出来,而Alt-* 则列出你可以输入的命令。
- 回到上一次的工作目录: cd – (回到home是 cd ~)
- 使用 xargs。这是一个很强大的命令。你可以使用-L来限定有多少个命令,也可以用-P来指定并行的进程数。如果你不知道你的命令会变成什么样,你可以使用xargs echo来看看会是什么样。当然, -I{} 也很好用。示例:
find.
-name \*.py |xargsgrepsome_functioncathosts
|xargs-I{}sshroot@{}hostname
- pstree -p 可以帮你显示进程树。(读过我的那篇《一个fork的面试题》的人应该都不陌生)
- 使用 pgrep 和 pkill 来找到或是kill 某个名字的进程。 (-f 选项很有用).
- 了解可以发给进程的信号。例如:要挂起一个进程,使用 kill -STOP [pid]. 使用 man 7 signal 来查看各种信号,使用kill -l 来查看数字和信号的对应表
- 使用 nohup 或 disown 如果你要让某个进程运行在后台。
- 使用netstat -lntp来看看有侦听在网络某端口的进程。当然,也可以使用 lsof。
- 在bash的脚本中,你可以使用 set -x 来debug输出。使用 set -e 来当有错误发生的时候abort执行。考虑使用 set -o pipefail 来限制错误。还可以使用trap来截获信号(如截获ctrl+c)。
- 在bash 脚本中,subshells (写在圆括号里的) 是一个很方便的方式来组合一些命令。一个常用的例子是临时地到另一个目录中,例如:
#
do something in current dir(cd/some/other/dir;
other-command)#
continue in original dir
- 在 bash 中,注意那里有很多的变量展开。如:检查一个变量是否存在: ${name:?error message}。如果一个bash的脚本需要一个参数,也许就是这样一个表达式 input_file=${1:?usage: $0 input_file}。一个计算表达式: i=$(( (i + 1) % 5 ))。一个序列: {1..10}。 截断一个字符串:
${var%suffix} 和 ${var#prefix}。 示例: if var=foo.pdf, then echo ${var%.pdf}.txt prints “foo.txt”.
- 通过 <(some command) 可以把某命令当成一个文件。示例:比较一个本地文件和远程文件 /etc/hosts: diff /etc/hosts <(ssh somehost cat /etc/hosts)
- 了解什么叫 “here documents” ,就是诸如 cat
<<EOF 这样的东西。
- 在 bash中,使用重定向到标准输出和标准错误。如: some-command >logfile 2>&1。另外,要确认某命令没有把某个打开了的文件句柄重定向给标准输入,最佳实践是加上 “</dev/null”,把/dev/null重定向到标准输入。
- 使用 man ascii 来查看 ASCII 表。
- 在远端的 ssh 会话里,使用 screen 或 dtach 来保存你的会话。(参看《28个Unix/Linux的命令行神器》)
- 要来debug Web,试试curl 和 curl -I 或是 wget 。我觉得debug Web的利器是firebug,curl和wget是用来抓网页的,呵呵。
- 把 HTML 转成文本: lynx -dump -stdin
- 如果你要处理XML,使用 xmlstarlet
- 对于 Amazon S3, s3cmd 是一个很方便的命令(还有点不成熟)
- 在 ssh中,知道怎么来使用ssh隧道。通过 -L or -D (还有-R) ,翻墙神器。
- 你还可以对你的ssh 做点优化。比如,.ssh/config 包含着一些配置:避免链接被丢弃,链接新的host时不需要确认,转发认证,以前使用压缩(如果你要使用scp传文件):
TCPKeepAlive=yesServerAliveInterval=15ServerAliveCountMax=6StrictHostKeyChecking=noCompression=yesForwardAgent=yes
- 如果你有输了个命令行,但是你改变注意了,但你又不想删除它,因为你要在历史命令中找到它,但你也不想执行它。那么,你可以按下 Alt-# ,于是这个命令关就被加了一个#字符,于是就被注释掉了。
数据处理
- 了解 sort 和 uniq 命令 (包括 uniq 的 -u 和 -d 选项).
- 了解用 cut, paste, 和 join 命令来操作文本文件。很多人忘了在cut前使用join。
- 如果你知道怎么用sort/uniq来做集合交集、并集、差集能很大地促进你的工作效率。假设有两个文本文件a和b已解被 uniq了,那么,用sort/uniq会是最快的方式,无论这两个文件有多大(sort不会被内存所限,你甚至可以使用-T选项,如果你的/tmp目录很小)
cata
b |sort|uniq>
c#
c is a union b 并集cata
b |sort|uniq-d
> c#
c is a intersect b 交集cata
b b |sort|uniq-u
> c#
c is set difference a - b 差集
- 了解和字符集相关的命令行工具,包括排序和性能。很多的Linux安装程序都会设置LANG 或是其它和字符集相关的环境变量。这些东西可能会让一些命令(如:sort)的执行性能慢N多倍(注:就算是你用UTF-8编码文本文件,你也可以很安全地使用ASCII来对其排序)。如果你想Disable那个i18n 并使用传统的基于byte的排序方法,那就设置export LC_ALL=C
(实际上,你可以把其放在 .bashrc)。如果这设置这个变量,你的sort命令很有可能会是错的。
- 了解 awk 和 sed,并用他们来做一些简单的数据修改操作。例如:求第三列的数字之和: awk ‘{ x += $3 } END { print x }’。这可能会比Python快3倍,并比Python的代码少三倍。
- 使用 shuf 来打乱一个文件中的行或是选择文件中一个随机的行。
- 了解sort命令的选项。了解key是什么(-t和-k)。具体说来,你可以使用-k1,1来对第一列排序,-k1来对全行排序。
- Stable sort (sort -s) 会很有用。例如:如果你要想对两例排序,先是以第二列,然后再以第一列,那么你可以这样: sort -k1,1 | sort -s -k2,2
- 我们知道,在bash命令行下,Tab键是用来做目录文件自动完成的事的。但是如果你想输入一个Tab字符(比如:你想在sort -t选项后输入<tab>字符),你可以先按Ctrl-V,然后再按Tab键,就可以输入<tab>字符了。当然,你也可以使用$’\t’。
- 如果你想查看二进制文件,你可以使用hd命令(在CentOS下是hexdump命令),如果你想编译二进制文件,你可以使用bvi命令(http://bvi.sourceforge.net/ 墙)
- 另外,对于二进制文件,你可以使用strings(配合grep等)来查看二进制中的文本。
- 对于文本文件转码,你可以试一下 iconv。或是试试更强的 uconv 命令(这个命令支持更高级的Unicode编码)
- 如果你要分隔一个大文件,你可以使用split命令(split by size)和csplit命令(split by a pattern)。
系统调试
- 如果你想知道磁盘、CPU、或网络状态,你可以使用 iostat, netstat, top (或更好的 htop), 还有 dstat 命令。你可以很快地知道你的系统发生了什么事。关于这方面的命令,还有iftop, iotop等(参看《28个Unix/Linux的命令行神器》)
- 要了解内存的状态,你可以使用free和vmstat命令。具体来说,你需要注意 “cached” 的值,这个值是Linux内核占用的内存。还有free的值。
- Java 系统监控有一个小的技巧是,你可以使用kill -3 <pid> 发一个SIGQUIT的信号给JVM,可以把堆栈信息(包括垃圾回收的信息)dump到stderr/logs。
- 使用 mtr 会比使用 traceroute 要更容易定位一个网络问题。
- 如果你要找到哪个socket或进程在使用网络带宽,你可以使用 iftop 或 nethogs。
- Apache的一个叫 ab 的工具是一个很有用的,用quick-and-dirty的方式来测试网站服务器的性能负载的工作。如果你需要更为复杂的测试,你可以试试 siege。
- 如果你要抓网络包的话,试试 wireshark 或 tshark。
- 了解 strace 和 ltrace。这两个命令可以让你查看进程的系统调用,这有助于你分析进程的hang在哪了,怎么crash和failed的。你还可以用其来做性能profile,使用 -c 选项,你可以使用-p选项来attach上任意一个进程。
- 了解用ldd命令来检查相关的动态链接库。注意:ldd的安全问题
- 使用gdb来调试一个正在运行的进程或分析core dump文件。参看我写的《GDB中应该知道的几个调试方法》
- 学会到 /proc 目录中查看信息。这是一个Linux内核运行时记录的整个操作系统的运行统计和信息,比如: /proc/cpuinfo, /proc/xxx/cwd, /proc/xxx/exe, /proc/xxx/fd/, /proc/xxx/smaps.
- 如果你调试某个东西为什么出错时,sar命令会有用。它可以让你看看 CPU, 内存, 网络, 等的统计信息。
- 使用 dmesg 来查看一些硬件或驱动程序的信息或问题。
作者最后加了一个免责声明:Disclaimer: Just because you can do something in bash, doesn’t necessarily mean you should. ;) (全文完)
(转载本站文章请注明作者和出处 酷壳 – CoolShell.cn ,请勿用于任何商业用途)
--------------------------------------------------------------------------------
一些强大的命令
再分享一些可能你不知道的shell用法和脚本,简单&强大!
在阅读以下部分前,强烈建议读者打开一个shell实验,这些都不是shell教科书里的大路货哦:)
!$
!$是一个特殊的环境变量,它代表了上一个命令的最后一个字符串。如:你可能会这样:
$mkdir mydir
$mv mydir yourdir
$cd yourdir
可以改成:
$mkdir mydir
$mv !$ yourdir
$cd !$
sudo !!
以root的身份执行上一条命令 。
场景举例:比如Ubuntu里用apt-get安装软件包的时候是需要root身份的,我们经常会忘记在apt-get前加sudo。每次不得不加上sudo再重新键入这行命令,这时可以很方便的用sudo !!完事。
(陈皓注:在shell下,有时候你会输入很长的命令,你可以使用!xxx来重复最近的一次命令,比如,你以前输入过,vi /where/the/file/is, 下次你可以使用 !vi 重得上次最近一次的vi命令。)
cd –
回到上一次的目录 。
场景举例:当前目录为/home/a,用cd ../b切换到/home/b。这时可以通过反复执行cd –命令在/home/a和/home/b之间来回方便的切换。
(陈皓注:cd ~ 是回到自己的Home目录,cd ~user,是进入某个用户的Home目录)
- ‘ALT+.’ or ‘<ESC> .’
热建alt+. 或 esc+. 可以把上次命令行的参数给重复出来。
^old^new
替换前一条命令里的部分字符串。
场景:echo "wanderful",其实是想输出echo "wonderful"。只需要^a^o就行了,对很长的命令的错误拼写有很大的帮助。(陈皓注:也可以使用 !!:gs/old/new)
- du -s * | sort -n | tail
列出当前目录里最大的10个文件。
- :w !sudo tee %
在vi中保存一个只有root可以写的文件
- date -d@1234567890
时间截转时间
- > file.txt
创建一个空文件,比touch短。
- mtr coolshell.cn
mtr命令比traceroute要好。
- 在命令行前加空格,该命令不会进入history里。
- echo “ls -l” | at midnight
在某个时间运行某个命令。
- curl -u user:pass -d status=”Tweeting from the shell” http://twitter.com/statuses/update.xml
命令行的方式更新twitter。
- curl -u username –silent “https://mail.google.com/mail/feed/atom” | perl -ne ‘print “\t” if /<name>/; print “$2\n” if /<(title|name)>(.*)<\/\1>/;’
检查你的gmail未读邮件
- ps aux | sort -nk +4 | tail
列出头十个最耗内存的进程
man ascii
显示ascii码表。
场景:忘记ascii码表的时候还需要google么?尤其在天朝网络如此“顺畅”的情况下,就更麻烦在GWF多应用一次规则了,直接用本地的man ascii吧。
ctrl-x e
快速启动你的默认编辑器(由变量$EDITOR设置)。
netstat –tlnp
列出本机进程监听的端口号。(陈皓注:netstat -anop 可以显示侦听在这个端口号的进程)
tail -f /path/to/file.log | sed '/^Finished: SUCCESS$/ q'
当file.log里出现Finished: SUCCESS时候就退出tail,这个命令用于实时监控并过滤log是否出现了某条记录。
ssh user@server bash < /path/to/local/script.sh
在远程机器上运行一段脚本。这条命令最大的好处就是不用把脚本拷到远程机器上。
- ssh user@host cat /path/to/remotefile | diff /path/to/localfile -
比较一个远程文件和一个本地文件
- net rpc shutdown -I ipAddressOfWindowsPC -U username%password
远程关闭一台Windows的机器
screen -d -m -S some_name ping my_router
后台运行一段不终止的程序,并可以随时查看它的状态。-d -m参数启动“分离”模式,-S指定了一个session的标识。可以通过-R命令来重新“挂载”一个标识的session。更多细节请参考screen用法man screen。
wget --random-wait -r -p -e robots=off -U mozilla http://www.example.com
下载整个www.example.com网站。(注:别太过分,大部分网站都有防爬功能了:))
curl ifconfig.me
当你的机器在内网的时候,可以通过这个命令查看外网的IP。
- convert input.png -gravity NorthWest -background transparent -extent 720×200 output.png
改一下图片的大小尺寸
lsof –i
实时查看本机网络服务的活动状态。
- vim scp://username@host//path/to/somefile
vim一个远程文件
python -m SimpleHTTPServer
一句话实现一个HTTP服务,把当前目录设为HTTP服务目录,可以通过http://localhost:8000访问 这也许是这个星球上最简单的HTTP服务器的实现了。
history | awk '{CMD[$2]++;count++;} END { for (a in CMD )print CMD[a] " " CMD[a]/count*100 "% " a }' | grep -v "./" | column -c3 -s " " -t | sort -nr | nl | head -n10
(陈皓注:有点复杂了,history|awk ‘{print $2}’|awk ‘BEGIN {FS=”|”} {print $1}’|sort|uniq -c|sort -rn|head -10)
这行脚本能输出你最常用的十条命令,由此甚至可以洞察你是一个什么类型的程序员。
- tr -c “[:digit:]” ” ” < /dev/urandom | dd cbs=$COLUMNS conv=unblock | GREP_COLOR=”1;32″ grep –color “[^ ]“
想看看Marix的屏幕效果吗?(不是很像,但也很Cool!)
看不懂行代码?没关系,系统的学习一下*nix shell脚本吧,力荐《Linux命令行与Shell脚本编程大全》。
最后还是那句Shell的至理名言:(陈皓注:下面的那个马克杯很不错啊,404null.com挺有意思的)
“Where there is a shell,there is a way!”
参考文献:
- Unix Shell Wiki
- Github language ranking
- An introduction of
Unix Shell history - Tiobe Software
- http://www.commandlinefu.com/
(转载本站文章请注明作者和出处 酷壳 – CoolShell.cn ,请勿用于任何商业用途)
--------------------------------------------------------------------------------
28个Unix/Linux的命令行神器
下面是Kristóf Kovács收集的28个Unix/Linux下的28个命令行下的工具(原文链接),有一些是大家熟悉的,有一些是非常有用的,有一些是不为人知的。这些工具都非常不错,希望每个人都知道。本篇文章还在Hacker
News上被讨论,你可以过去看看。我以作者的原文中加入了官网链接和一些说明。
dstat & sar
iostat, vmstat, ifstat 三合一的工具,用来查看系统性能(我在《性能调优攻略》中提到过那三个xxstat工具)。
官方网站:http://dag.wieers.com/rpm/packages/dstat/
你可以这样使用:
alias dstat='dstat -cdlmnpsy'
slurm
查看网络流量的一个工具
官方网站: Simple Linux Utility for Resource Management
vim & emacs
真正程序员的代码编辑器。
screen, dtach, tmux, byobu
你是不是经常需要 SSH 或者 telent 远程登录到 Linux 服务器?你是不是经常为一些长时间运行的任务而头疼,比如系统备份、ftp 传输等等。通常情况下我们都是为每一个这样的任务开一个远程终端窗口,因为他们执行的时间太长了。必须等待它执行完毕,在此期间可不能关掉窗口或者断开连接,否则这个任务就会被杀掉,一切半途而废了。
Screen是一个可以在多个进程之间多路复用一个物理终端的窗口管理器。Screen中有会话的概念,用户可以在一个screen会话中创建多个screen窗口,在每一个screen窗口中就像操作一个真实的telnet/SSH连接窗口那样。请参看IBM DeveloperWorks的这篇文章《使用
screen 管理你的远程会话》
dtach是用来模拟screen的detach的功能的小工具,其可以让你随意地attach到各种会话上 。下图为dtach+dvtm的样子。

tmux是一个优秀的终端复用软件,类似GNU
Screen,但来自于OpenBSD,采用BSD授权。使用它最直观的好处就是,通过一个终端登录远程主机并运行tmux后,在其中可以开启多个控制台而无需再“浪费”多余的终端来连接这台远程主机;当然其功能远不止于此。与screen相比的优点:可以横向和纵向分割窗口,且窗格可以自由移动和调整大小。可在多个缓冲区进行复制和粘贴,支持跨窗口搜索;非正常断线后不需重新detach;…… 有人说——与tmux相比,screen简直弱爆了。
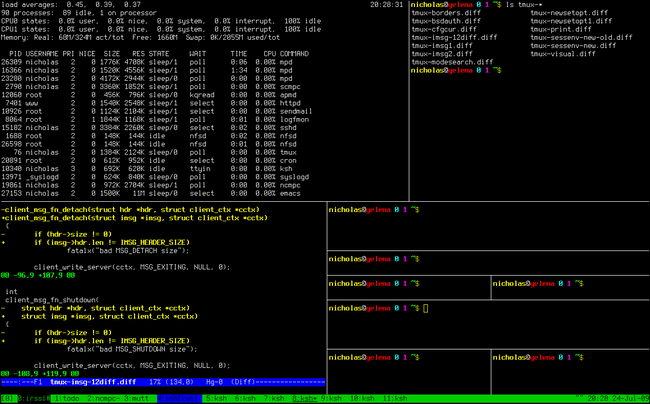
byobu是Ubuntu开发的,在Screen的基础上进行包装,使其更加易用的一个工具。最新的Byobu,已经是基于Tmux作为后端了。可通过“byobu-tmux”这个命令行前端来接受各种与tmux一模一样的参数来控制它。Byobu的细节做的非常好,效果图如下: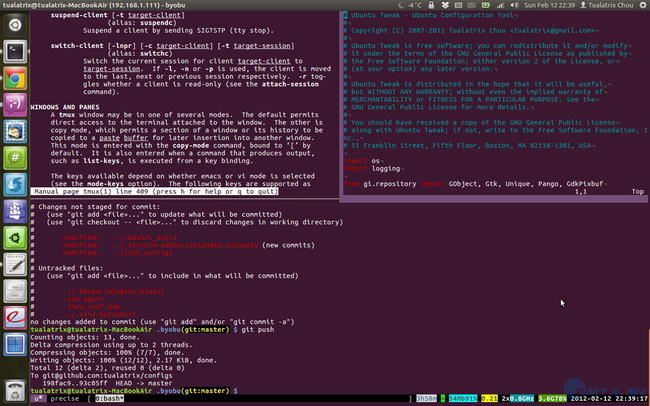
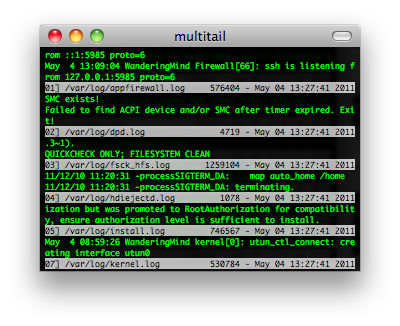
multitail
MultiTail是个用来实现同时监控多个文档、类似tail命令的功能的软件。他和tail的区别就是他会在控制台中打开多个窗口,这样使同时监控多个日志文档成为可能。他还可以看log文件的统计,合并log文件,过滤log文件,分屏,……。
官网:http://www.vanheusden.com/multitail/
tpp
终端下的PPT,要是在某某大会上用这个演示PPT,就太TMD的Geek了。
官网:http://www.ngolde.de/tpp.html
xargs & parallel
Executes tasks from input (even multithread).
xargs 是一个比较古老的命令,有简单的并行功能,这个不说了。对于GNU parallel ( online manpage )来说,它不仅能够处理本机上多执行绪,还能分散至远端电脑协助处理。而使用GNU
parallel前,要先确定本机有安装GNU parallel / ssh / rsync,远端电脑也要安装ssh。
duplicity & rsyncrypto
Duplicity是使用rsync算法加密的高效率备份软件,Duplicity支持目录加密生产和格式上传到远程或本地文件服务器。
rsyncrypto 就是 rsync + encryption。对于rsync的算法可参看酷壳的rsync核心算法。
Encrypting backup tools.
nethack & slash’em
NetHack(Wiki),20年历史的古老电脑游戏。没有声音,没有漂亮的界面,不过这个游戏真的很有意思。网上有个家伙说:如果你一生只做一件事情,那么玩NetHack。这句话很惹眼,但也让人觉得这个游戏很复杂不容易上手。其实,这个游戏很虽然很复杂,却容易上手。虽然玩通关很难,但上手很容易。NetHack上有许多复杂的规则,”the
DevTeam thinks of everything”(开发团队想到了所有的事情)。各种各样的怪物,各种各样的武器….,有许多spoilers文件来说明其规则。除了每次开始随机生成的地图,每次玩游戏,你也都会碰到奇怪的事情: 因为喝了一种药水,变成了机器人;因为踢坏了商店的门被要求高价赔偿;你的狗为你偷来了商店的东西….. 这有点象人生,你不能完全了解这个世界,但你仍然可以选择自己的面对方式。
网上有许多文章所这是最好的电脑游戏或最好的电脑游戏之一。也许是因为它开放的源代码让人赞赏,古老的历史让人宽容,复杂的规则让人敬畏。虽然它不是当前流行的游戏,但它比任何一个当前流行的游戏都更有可能再经受20年的考验。
Slash’EM 也是一个基于NetHack的经典游戏。
lftp
利用lftp命令行ftp工具进行网站数据的增量备份,镜像,就像使用rsync一样。
ack
ack是一个perl脚本,是grep的一个可选替换品。其可以对匹配字符有高亮显示。是为程序员专门设计的,默认递归搜索,省提供多种文件类型供选。
calcurse & remind + wyrd
calcurse是一个命令行下的日历和日程软件。remind + wyrd也很类似。关于日历,我不得不提一个Linux的Cycle日历,也是一个神器,呵呵。
newsbeuter & rsstail
newsbeuter和 rsstail 是命令行下RSS的阅读工具。
powertop
做个环保的程序员,看看自己的电脑里哪些程序费电。PowerTOP 是一个让 Intel 平台的笔记本电脑节省电源的 Linux 工具。此工具由 Intel
公司发布。它可以帮助用户找出那些耗电量大的程序,通过修复或者关闭那些应用程序或进程,从而为用户节省电源。
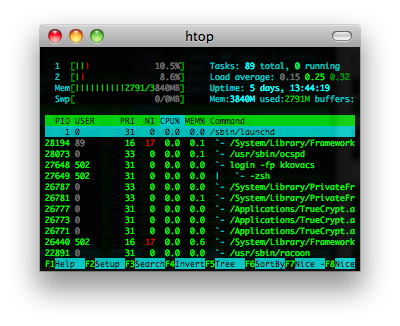
htop & iotop
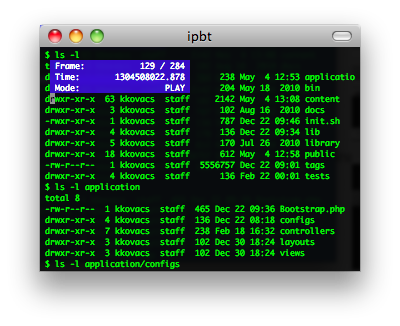
ttyrec & ipbt
ttyrec 是一个 tty 控制台录制程序,其所录制的数据文件可以使用与之配套的 ttyplay 播放。不管是你在 tty 中的各种操作,还是在 tty 中耳熟能详的软件,都可进行录制。
ipbt 是一个用来回放 ttyrec 所录制的控制台输入过程的工具。
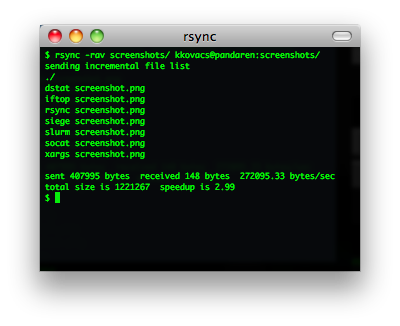
rsync
通过SSH进行文件同步的经典工具(核心算法)
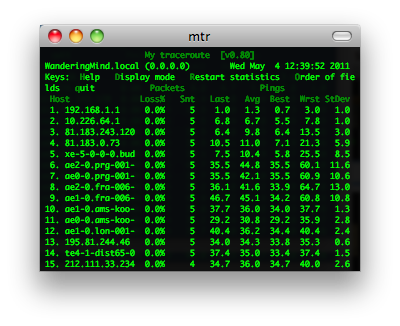
mtr
MTR - traceroute 2.0,其是把 traceroute 和 ping 集成在一块的一个小工具 用于诊断网络。
socat & netpipes
socat是一个多功能的网络工具,名字来由是” Socket CAT”,可以看作是netcat的N倍加强版。
netpipes 和socat一样,主要是用来在命令行来进行socket操作的命令,这样你就可以在Shell脚本下行进socket网络通讯了。
iftop & iptraf
iftop和iptraf可以用来查看当前网络链接的一些流量情况。
siege & tsung
Siege是一个压力测试和评测工具,设计用于WEB开发这评估应用在压力下的承受能力:可以根据配置对一个WEB站点进行多用户的并发访问,记录每个用户所有请求过程的相应时间,并在一定数量的并发访问下重复进行。
Tsung 是一个压力测试工具,可以测试包括HTTP, WebDAV, PostgreSQL, MySQL, LDAP, and XMPP/Jabber等服务器。针对 HTTP 测试,Tsung 支持 HTTP 1.0/1.1 ,包含一个代理模式的会话记录、支持 GET、POST 和 PUT 以及 DELETE 方法,支持 Cookie
和基本的 WWW 认证,同时还支持 SSL。
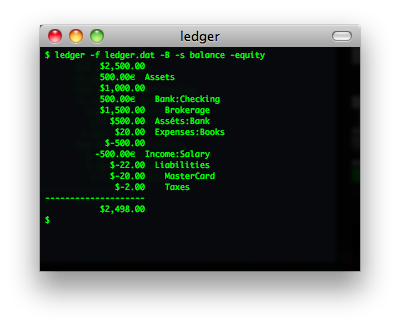
ledger
ledger 一个命令行下记帐的小工具。
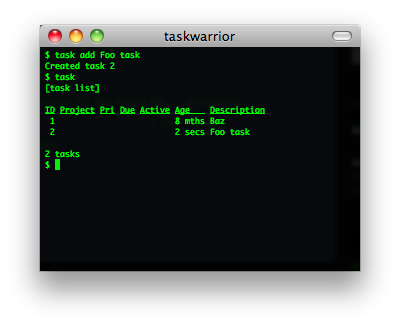
taskwarrior
TaskWarrior 是一个基于命令行的 TODO 列表管理工具。主要功能包括:标签、彩色表格输出、报表和图形、大量的命令、底层API、多用户文件锁等功能。
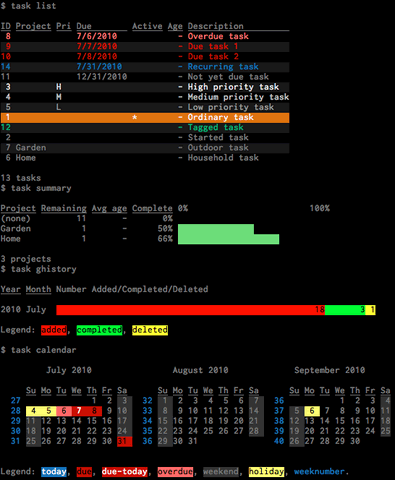
下图是TaskWarrior 2.0的界面:
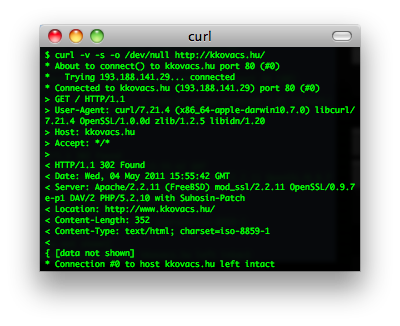
curl
cURL是一个利用URL语法在命令行下工作的文件传输工具,1997年首次发行。它支持文件上传和下载,所以是综合传输工具,但按传统,习惯称cURL为下载工具。cURL还包含了用于程序开发的libcurl。cURL支援的通訊協定有FTP、FTPS、HTTP、HTTPS、TFTP、SFTP、Gopher、SCP、Telnet、DICT、FILE、LDAP、LDAPS、IMAP、POP3、SMTP和RTSP。
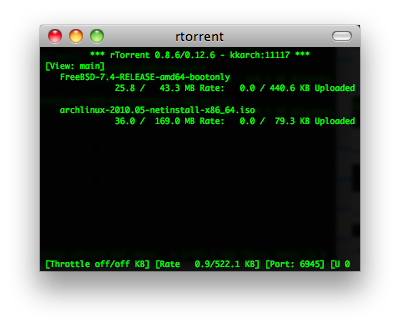
rtorrent & aria2
rTorrent 是一个非常简洁、优秀、非常轻量的BT客户端. 它使用了 ncurses 库以 C++ 编写, 因此它完全基于文本并在终端中运行. 将 rTorrent 用在安装有 GNU Screen 和 Secure Shell 的低端系统上作为远程的 BT 客户端是非常理想的。
aria2 是 Linux 下一个不错的高速下载工具。由于它具有分段下载引擎,所以支持从多个地址或者从一个地址的多个连接来下载同一个文件。这样自然就大大加快了文件的下载速度。aria2 也具有断点续传功能,这使你随时能够恢复已经中断的文件下载。除了支持一般的 http(s) 和 ftp 协议外,aria2 还支持 BitTorrent 协议。这意味着,你也可以使用
aria2 来下载 torrent 文件。
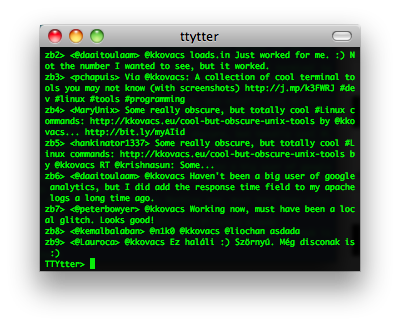
ttytter & earthquake
TTYtter 是一个Perl写的命令行上发Twitter的工具,可以进行所有其他平台客户端能进行的事情,当然,支持中文。脚本控、CLI控、终端控、Perl控的最愛。
Earthquake也是一个命令行上的Twitter客户端。
vifm & ranger
Vifm 基于ncurses的文件管理器,DOS风格,用键盘操作。
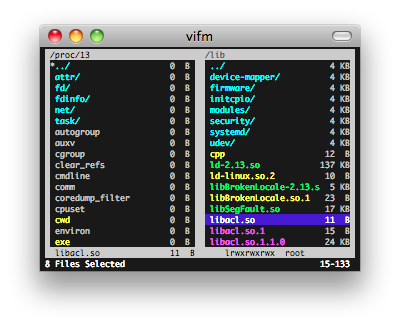
Ranger用 Python 完成,默认为使用 Vim 风格的按键绑定,比如 hjkl(上下左右),dd(剪切),yy(复制)等等。功能很全,扩展/可配置性也非常不错。类似MacOS X下Finder(文件管理器)的多列文件管理方式。支持多标签页。实时预览文本文件和目录。
cowsay & sl
cowsay 不说了,如下所示,哈哈哈。还有xcowsay,你可以自己搜一搜。
sl是什么?ls?,呵呵,你会经常把ls 打成sl吗?如果是的话,这个东西可以让你娱乐一下,你会看到一辆火车呼啸而过~~,相当拉风。你可以使用sudo apt-get install sl 安装。
最后,再介绍一个命令中linuxlogo,你可以使用 sudo apt-get install linuxlogo来安装,然后,就可以使用linuxlogo -L
来看一下各种Linux的logo了
(全文完)
[置顶] Linux 常用命令集锦的更多相关文章
- [置顶] linux常用命令手册
前言:整理了一份linux常用命令手册,与大家分享.这是一些比较常用的命令. 我已经整理成一份PDF带书签的手册,可以到CSDN免费下载. 下载地址:http://download.csdn.net/ ...
- [置顶] linux常用命令大全
SSH 密令控制台 user/pwd 一:停止tomcat 1,cd .. 进入根目录 2,cd home/ 3,ll 4,cd bin/ 进入tomcat bin目录 5,ll 6,ps -ef | ...
- linux 常用命令 集锦
第一章 LINUX简介及安装 1一.LINUX介绍 1二.LINUX安装 2三.LINUX目录 2四.总结来说: 3第二章 常用命令及帐户管理 4一.linux命 ...
- [置顶] UNIX常用命令
scp命令用于两个机器之前文件的拷贝 scp 被拷贝文件 远程机器用户名@远程机器IP:拷贝目的目录或者拷贝目录下的目的文件 dos2unix 在执行编译文件时,本来应该生成可执行文件a,但是执行完后 ...
- linux 常用命令集锦
喝断片儿了,我是谁?我在什么地方?我做过些什么事?查看当前用户 who am i查看当前路径 pwd查看历史记录 history 我忘了程序放哪了,就记得个名.更新系统数据库 updatedb查找文件 ...
- linux常用命令集锦
linux 查看所有用户所在组 vi /etc/group 一个用户可以属于多个组,查看用户所属的组,groups + 用户名 linux 查找文件命令 find -name 文件名 在 ...
- linux常用命令的介绍
本文主要介绍Linux常用命令工具,比如用户创建,删除,文件管理,常见的网络命令等 如何创建账号: 1. 创建用户 useradd -m username -m 表示会在/home 路径下添加创建用户 ...
- Linux常用命令 笔记
Linux常用命令 笔记 一.文件处理命令 1. ls命令:显示目录文件 -a 显示所有文件,包括隐藏文件.(all) ...
- Linux常用命令之文件和目录处理命令
目录 1.Linux命令的普遍语法格式 2.目录处理命令 一.显示目录文件命令:ls 二.创建目录命令:mkdir 三.切换目录命令:cd 四.shell内置命令和外部命令的区别 五.显示当前目录命令 ...
随机推荐
- 训练1-S
给出N个正整数,检测每个数是否为质数.如果是,输出"Yes",否则输出"No". Input 第1行:一个数N,表示正整数的数量.(1 <= N < ...
- [NOI 2002] 银河英雄传说 (带权并查集)
题目描述 公元五八○一年,地球居民迁至金牛座α第二行星,在那里发表银河联邦创立宣言,同年改元为宇宙历元年,并开始向银河系深处拓展. 宇宙历七九九年,银河系的两大军事集团在巴米利恩星域爆发战争.泰山压顶 ...
- Hive sql
1.DDL操作 1.1 建表 CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name [(col_name data_type [COMMENT col_ ...
- TCP协议和UDP协议
一:TCP(Transmission Control Protocol) 传输控制协议 TCP是主机对主机层的传输控制协议,提供可靠的连接服务,采用三次握手确认建立一个连接: 第一次握手:主机A发送 ...
- Using index, using temporary, using filesort - how to fix this?
解释一: These are the following conditions under which temporary tables are created. UNION queries use ...
- asp.net mvc--传值-前台->后台
前端传值->后端 一.Model Binding 方式 前台 @model ADMgr.Web.Models.ListModel 后台 [HttpPost] public ActionResul ...
- Storm同时接收多个源(spout和bolt)
参考: http://blog.csdn.net/nyistzp/article/details/51483779
- 用 query 方法 获得xml 节点的值
DECLARE @result xml SET @result='<s:Envelope xmlns:s="http://schemas.xmlsoap.org/soap/envelo ...
- Impala ODBC 安装笔记
Impala在线文档介绍了 Impala ODBC接口安装和配置 http://www.cloudera.com/content/cloudera-content/cloudera-docs/CDH5 ...
- linux下jenkins安装
在安装jenkins之前.首先确认jdk和tomcat,maven已经配置好 详细配置方法,请看的我博客. jdk:jdk的安装与配置 tomcat:tomcat的安装与配置 maven:maven的 ...