Mark Sweep GC
标记清除算法
GC 标记-清除算法是由标记阶段和清除阶段构成。标记阶段把所有活动的对象做上标记。清除阶段是吧没有标记的对象也就是非活动的对象进行回收。通过这两个阶段就可以对空间进行重新利用。
mark_sweep()函数
mark_sweep(){mark_phase() //标记sweep_phase() //清除}
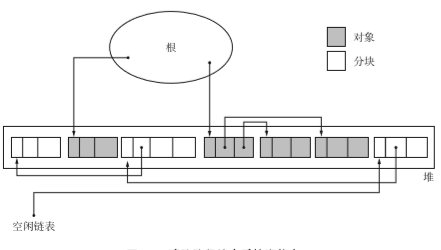
在执行GC前堆的状态
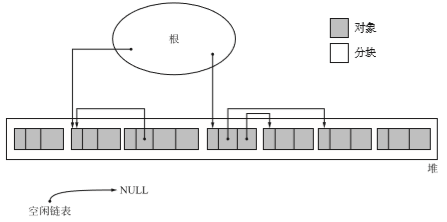
标记阶段
使用 mark_phase()函数进行处理。在标记阶段,collector会为堆里所有活动的对象打上标记。我们首先要通过根找到直接引用的对象进行标记,之后才能递归的访问到对象并把所有活着的对象进行标记。
mark_phase()
mark_phase(){for(r:$roots)mark(*r) //从根开始取它的孩子进行标记}mark(obj){if(ob.mark == FALSE)obj.mark = TRUE // 如果还是标记是FALSE则改为TRUEfor(child :children(obj)) // 再去递归的标记自己的孩子mark(*child)}
标记完所有对象后,标记活动就结束了。这时,状态如下图所示。
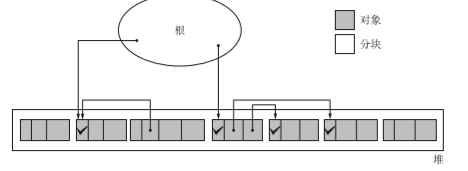
在标记阶段中,程序会标记所有活动对象,毫无疑问,对象越多需要的时间就越多。他们是正相关的。
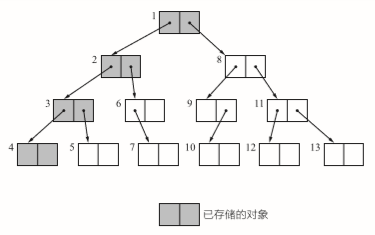
深度优先于广度优先
这时一个老生常谈的问题了。应用很广,因为像这种类型可能没有其他方式遍历了,其使用的队列和递归也是非常常用的。
深度优先depth-first search 使用递归实现
广度优先breadth-first search 使用队列实现
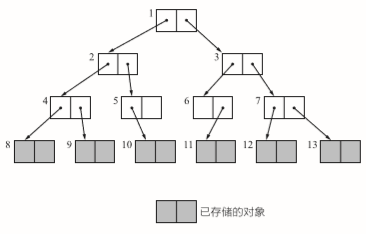
无论使用哪种方法,搜索的对象时不会变的。但是深度优先可以压低内存的使用量,因此我们经常实用深度优先。
清除阶段
在清除阶段,cllector会遍历整个堆。回收垃圾,使其能再次利用。此时出现了size的域这是存储对象大小的域,同mark一样我们在头中定义了它。简单的说,在块的头中现在有mark和size。mark表示时候有用,size表示块的大小。
sweep_phase()
sweep_phase(){sweeping = $heap_start //堆头while(sweeping < $heap_end) //现在为止在堆尾之前if(sweeping.mark == TRUE)SWEEPING.mark = FALSE //这里标记为false。因为如果以后不再使用了她就能被回收,否则就不能回收了。elsesweeping.next = $free_list //初始化空链表$free_list = sweeping // 连接到一个free链表上sweeping += sweeping.size //可以看做是基址+偏移。拿到下一个块地址}
通过上面的操作,我们拿到了free_list。之后我们针对它进行分配空间操作。下图就表现出gc后两个链表
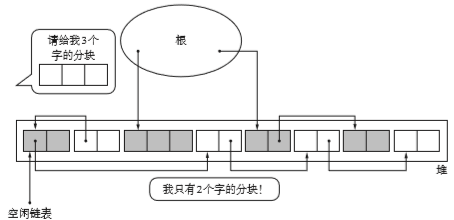
清除阶段同理,会遍历所有块进行垃圾回收。时间和堆的大小成正相关。
分配
那么对于垃圾回收的再利用是怎么进行的呢?。当mutator申请分块时,怎样才能分呢?
我们使用nwe_obj函数来分配。
new_obj
nwe_obj(){chunk = pickup_chunk(size, $free_list) // 我需要的大小size 和查找对象 free_listif (chunk !=NULL)return chunk //拿到了elseallocation_fail() // 拿不到}
在分配的时候有几个点:不能分配比size小的,只能使用大于等于size的块去进行分配,如果大小合适再好不过,如果大了就需要去分割一个和size一样大小的块再分配,剩余部分返回空链表。
First-fit、Best-fit、Worst-fit三种分配策略
- First-fit:最初发现大于等于size的分块就进行操作。可能第一个就比size大,但是第二个就和size一样大。这样就直接分了第一个,碎片严重。
- Best-fit:遍历空链表,选择最合适的。性能低啊。
- Worst-fit:找出空闲链表中最大的块,分割成size和其他。也容易产生碎片,比第一个还容易,不推荐使用。
综上, 考虑到碎片和性能问题,选择First-fit还是比较明智的选择。
合并
根据分配策略会生成大量小块,但是如果小块是连续的我们其实可以将它连接起来成为一个大块。这就叫做合并coalescing
sweep_phase()
sweep_phase(){sweeping = $heap_start //堆头while(sweeping < $heap_end) //现在为止在堆尾之前if(sweeping.mark == TRUE)SWEEPING.mark = FALSE //这里标记为false。因为如果以后不再使用了她就能被回收,否则就不能回收了。elseif(sweeping = $free_list+$free_list.size)// 先验证是不是相邻的。$free_list.size +=sweeping.size //这样就连接起来了。elsesweeping.next = $free_list //初始化空链表$free_list = sweeping // 连接到一个free链表上sweeping += sweeping.size //可以看做是基址+偏移。拿到下一个块地址}
优点
实现简单
他其实就是用到了标识位,然后进行遍历。算法上难度很低。不像其他算法难度是比较大的。
与保守式GC算法兼容
在保守式GC中,对象时不能被移动的。例如复制算法他就是将数据复制过来,在复制过去,是移动的。而标记清除不移动对象,所以非常适合保守式GC算法。实际上很多采用保守式gc的程序中使用到了标记清除。
缺点
碎片化
算法使用过程中产生被细化的分块,在不久后就会散落在各处。我们将这种状况称为碎片化(fragmentation)。windows文件系统也会有这种现象。
如果发生了碎片化,及时空闲链表再大,也不能分配成功。为了解决这个问题可以采用压缩,但是本文中介绍了一下BIBOP法提供参考。
分配速度
标记清除算法中分块不是连续的,因此每次都需要遍历链表。在最糟糕的情况下是每次是链表的最后一块。因此速度非常慢,如果一个大型游戏采用这种方式后果可想而知。
后文叙述的多个空闲链表和BIBOP都是为了解决速度而采取的方案。
与写时复制技术不兼容
写时复制技术(copy-on-write)是在Linux等众多unix操作系统的虚拟存储中使用的高速化方案。例如在Linux复制进程使用fork()时,大部分空间都不会被复制。如果说为了复制进程就复制了所有空间这样内存怎么多也不够。因此写时复制技术就假装复制了内存空间实际上是共享内存空间。
当然我们对共享的空间写入时不能直接写它,因为它是别的。这时候就要将其复制到自己的私有空间然后进行重写。复制后之访问私有空间不访问共享空间。
但是标记清除算法,就算是没有重写,也会进行不断的复制。实际上我们还是希望它是用共享,而不是浪费内存。为了处理这个问题我们采用为图标记法bitmap marking。
多个空闲链表
之前的算法中使用的只有一个空闲链表,对大块和小块进行统一的处理。这样一来无论大小都要遍历很长的链。
因此我们对块进行分类。大的是一组,小的是一组。这样一来按照mutator所申请的空间大小选择合适的块就容易的多。
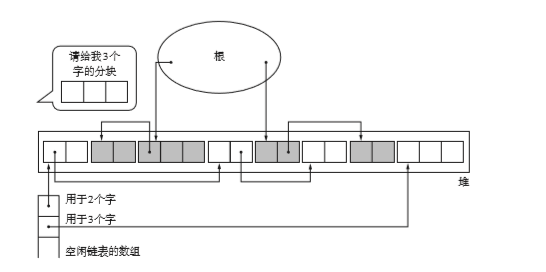
一般情况来说,mutator很少会申请非常大的分块。为了应对这种极少数情况,我们给分块设定一个上限。如果分块大于等于这个大小,就全部采用一个空链表。
利用多个空链表时,我们需要修正new_obj()以及sweep_phase()
new_obj
nwe_obj(){index = size/(WORD_LENGTH/BYTE_LENGTH) //根据商来选择合适的建表if (index <=100 ) //小于100字if($free_list[index] !=NULL)chunk = $free_list[index] // 获取链的索引,分给他一个index字链上的第一块$free_list[index] = $free_list[index].nextreturn chunkelse //大于100字chunk = pickup_chunk(size, $free_list[101]) // 我需要的大小size 和 查找对象 free_listif (chunk !=NULL)return chunk //拿到了elseallocation_fail() // 拿不到}
sweep_phase()
sweep_phase(){for(i:2...101)$free_list[1] = NULLsweeping = $heap_start //堆头while(sweeping < $heap_end) //现在为止在堆尾之前if(sweeping.mark == TRUE)SWEEPING.mark = FALSE //这里标记为false。因为如果以后不再使用了她就能被回收,否则就不能回收了。elseindex = size/(WORD_LENGTH/BYTE_LENGTH)if(index <=100)sweeping.next = $free_list[index]$free_list[index] = sweepingelsesweeping.next = $gree_list[101]$free_list[101] = sweepingsweeping += sweeping.size //可以看做是基址+偏移。拿到下一个块地址}
BIBOP法
BiBOP是Big Bag Of Pages的缩写,就是将大小相近的对象整理成固定大小的块进行管理的做法。我们可以使用这个方法把堆分成固定大小的块,让每个块只能配置同样大小的对象这就是BiBOP算法。不觉得内存利用效率低吗?熊die。
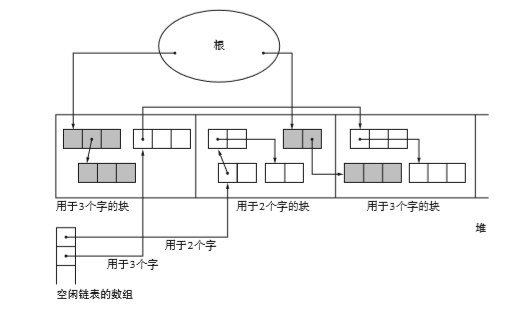
如图所示,在多个分块中残留同样大小的对象反而会使堆的使用效率低下。
位图标记
在以前的标记清除算法中,标记是在对象头中的,这样造成了与写时复制技术的不兼容。对此收集头部标识表格化将标识与对象分开管理。这样的标记方法称为位图表格(bitmap table)。位图标记可以采用如散列表,树形结构等。为了简单起见我们使用数组。如下图。
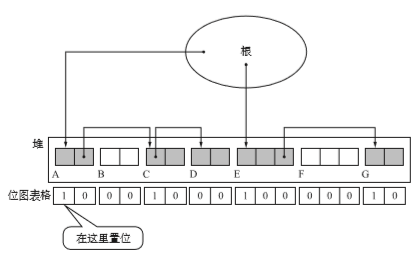
表中的位置和堆里的对象一一对应。一般来说堆中的一个字会分到一个位。
mark()
mark(obj){obj_num = (obj-$heap_start)/WORD_LENGTHindex = obj_num / WORD_LENGTHoffset = obj_num % WORD_LENGTHif (($bitmap_tbl[index]&(1<<offset))==0)$bitmap_tbl[index] != (1<<offset)for (child :children(obj))mark(*child)}
这里WORD_LENGTH 是个常量,表示各机器中1个字的位宽。obj_num指从位图表格前面数起,obj的标志位在第几个。例如上图中E,它的obj_num就是8.但是bitmap的图是从后往前的所以E的标志位应该从右往左数是第九个位。如下图
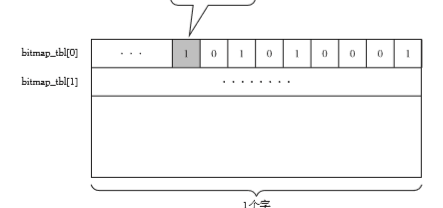
优点
与写时复制技术兼容
以往标记位是对对象进行设置,而位图标记不对对象进行设置采用了映射或许可以理解为引用。所以自然不会发生无谓的复制。
清除操作更高效
利用位图表格的清除操作把所有对象的标志位集合到一处,可以快速定位。与一般的清除阶段相同,我们sweeping遍历整个堆,不过这里使用了index和offset两个变量,在遍历堆的同时也遍历位图表格。
sweep_phase
sweep_phase(){sweeping = $heap_startindex = 0offset = 0while(sweeping <$heap_end)if($bitmap_tb1[index] &(1<<offset) ==0)sweeping.next = $free_list$free_list = sweepingindex +=(offset + sweeping.size) /WORD_LENGTHoffset = (offset + sweeping.size) % WORD_LENGTHsweeping += sweeping.sizefor (i:0...(HEAP_SIZE/WORD_LENGTH-1))$bitmap_tbl[i] = 0}
注意
对象地址和位图表格对应。通过对象的地址求与其对应的位置标志,要进行位运算的。再有多个堆且地址不连续的情况下,必须采用多个表。即每个堆一个表。
延迟清除法
我们之前说过,清除花费的时间和堆的大小成正比。这样一来堆越大就越影响mutator。会越慢。
延迟清除(Lazy Sweep)是缩减因清除操作而导致的mutator最大暂停时间的方法。在标记操作结束后,不一并进行清除。通过延迟来防止mutator长时间暂停。
nwe_obj
nwe_obj(size){chunk = lazy_sweep(size)if (chunk!=NULL)return chunkmark_phase()chunk = lazy_sweep(size)if(chunk !=NULL)return chunkallocation_fail()}
分配时调用lazy_sweep进行清除。如果他能用清除操作来分配块,就会返回分开,如果不能分配块就会执行标记操作。当lazy_sweep函数返回NULL时就是没有找到。那就在进行一遍此操作。如果还没能分得代表没有分块。mutator也就不需要进行下一步处理。
lazy_sweep
lazy_sweep(size){while($sweeping <heap_end)if($sweeping.mark == TRUE)$sweeping.mark = FALSEelse if($sweeping.size >=size)chunk = $sweeping$sweeping +=$sweeping.sizereturn chunk$sweeping += $sweeping.size$sweeping = $heap_startreturn NULL}
次函数会一直遍历堆,知道找打大于等于所申请的空间。再找到时候会将其返回,但是$sweeping是全局变量,也就是说遍历开始位置谓语上一次清除操作中发现的分块右边。
当次函数没有找打分块时候会返回NULL。
此方法在分配时执行必要的遍历,因此可以压缩清除操作导致mutator暂停的时间,这就是延迟的意思。
只有延迟清除是不够的
虽然可以减少mutator的暂停时间。但是延迟清除的效果是不均匀的。打个比方如下图。

垃圾变成了垃圾堆,活动对象变成了活动对象堆。这种情况下,程序清除垃圾较多的部分时马上就能获得分块,随意能减少mutator的暂停时间。然鹅一旦程序开始清除活动对象周围就怎么也获得不了分块,这就增加了mutator的暂停时间。
至于有什么其他方法。后续会在其他文章里。
Mark Sweep GC的更多相关文章
- 1. GC标记-清除算法(Mark Sweep GC)
世界上第一个GC算法,由 JohnMcCarthy 在1960年发布. 标记-清除算法由标记阶段和清除阶段构成. 标记阶段就是把所有的活动对象都做上标记的阶段. 标记阶段就是"遍历对象并标记 ...
- Gson序列化问题导致的内存溢出,tip:Background sticky concurrent mark sweep GC freed
问题原因,如果在json model里面放了非可序列化的对象就会导致这中问题,可序列化的就是那些基础数据类型和集合类型,如果在里面放个Android的Activity或者adapter这类类型字段,变 ...
- Reference Counting GC (Part two :Partial Mark & Sweep)
目录 部分标记清除算法 前提 dec_ref_cnt()函数 new_obj()函数 scan_hatch_queue()函数 paint_gray()函数 scan_gray()函数 collect ...
- Mark Compact GC (Part two :Two-Finger)
目录 Two-Finger算法 前提 概要 步骤一:移动对象 步骤二:更新指针 优缺点 表格算法 概要 步骤一:移动对象群 和 构筑间隙表格 移动对象群 构筑间隙表格 步骤二:更新指针 优缺点 Two ...
- Mark Compact GC (Part one: Lisp2)
目录 什么是GC 标记-压缩算法 Lisp2 算法的对象 概要 步骤 步骤一:设定forwarding指针 步骤二:更新指针 步骤三:移动对象 优缺点 什么是GC 标记-压缩算法 需要对标记清除和GC ...
- copy GC 和 mark & compaction GC的算法异同
先标记 然后 copy GC是,对所有child,判断, 如果child没有被访问过,那么拷贝到新地址,child的forwording指向新地址,child标记为已访问,把自己对child的引用改为 ...
- GC学习笔记
GC学习笔记 这是我公司同事的GC学习笔记,写得蛮详细的,由浅入深,循序渐进,让人一看就懂,特转到这里. 一.GC特性以及各种GC的选择 1.垃圾回收器的特性 2.对垃圾回收器的选择 2.1 连续 V ...
- 非常详细GC学习笔记
转载:http://blog.csdn.net/fenglibing/article/details/6321453 这是我公司同事的GC学习笔记,写得蛮详细的,由浅入深,循序渐进,让人一看就懂,特转 ...
- [译]GC专家系列1: 理解Java垃圾回收
原文链接:http://www.cubrid.org/blog/dev-platform/understanding-java-garbage-collection/ 了解Java的垃圾回收(GC)原 ...
随机推荐
- HDU 3415 Max Sum of Max-K-sub-sequence 单调队列题解
本题又是一题单调队列题解. 技巧就是须要计算好前n项和Sn = a1 + a2 + ... an 这样方便处理. 记录一条单调队列,其意义是: q(head), q(head+1), ...q(tai ...
- HDOJ 5008 Boring String Problem
后缀数组+RMQ+二分 后缀数组二分确定第K不同子串的位置 , 二分LCP确定可选的区间范围 , RMQ求范围内最小的sa Boring String Problem Time Limit: 6000 ...
- 使用quick自己定义Button
使用quick时自己封装的类存放于特定的文件夹.便于以后使用 以下是作者经经常使用到的一个按钮 local MyButton = class("MyButton") functio ...
- Java中MySQL事务处理举例
实例(以sql语句中的insert语句为例) import java.sql.Connection; import java.sql.DriverManager; import java.sql.Pr ...
- go语言中在变量后加上接口是什么意思?
如题刚刚开始学习go 语言有些不懂: a.Data = make(map[string]interface{}) 我认为它是在申请a.Data map为字符串类型的空间,那么它后面接一个空的inter ...
- Linux 运维笔试题(一)
试题: 1.说出下列服务对应的端口或者端口对应的服务 21 23 25 873 161 111 110 53 123 2049 2.文件atime,ctime,mtime的区 ...
- iOS开发——根据数组中的字典中的某一元素排序
数组中的元素是字典,字典中的某一个元素,比如说姓名,现在需要按照姓名的首字母来排序,怎么搞? 做法很简单,在字典中加一个元素,保存姓名的首字母,然后用下面的方法排序. - (void)sortWifi ...
- d3 bubble源码分析
技术 d3.d3.pack.d3.hierarchy 展示 https://bl.ocks.org/xunhanliu/e0688dc2ae9167c4c7fc264c0aedcdd1 关于怎么使用, ...
- HDU-1541 Stars 树状数组
题目链接:https://cn.vjudge.net/problem/HDU-1541 题意 天上有许多星星 现给天空一个平面坐标轴,统计每个星星的level, level是指某一颗星星的左下角(x& ...
- Python爬虫基础示例
使用pip安装相关依赖: pip install requests pip install bs4 安装成功提示:Successfully installed *... 爬取中国天气网数据示例代码: ...