Noip 2016 Day1 题解
老师让我们刷历年真题,
然后漫不经心的说了一句:“你们就先做做noip2016 day1 吧”
。。。。。。
我还能说什么,,,,,老师你这是明摆着伤害我们啊2333333333
预计分数:100+25+24
实际分数:100+25+12
T1:玩具谜题
题目描述
小南有一套可爱的玩具小人, 它们各有不同的职业。
有一天, 这些玩具小人把小南的眼镜藏了起来。 小南发现玩具小人们围成了一个圈,它们有的面朝圈内,有的面朝圈外。如下图:
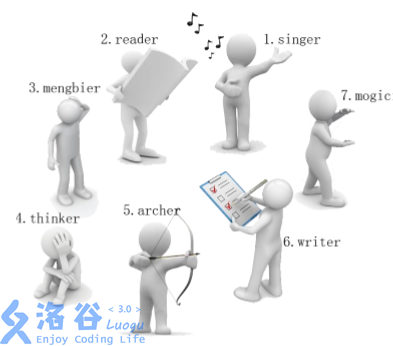
这时singer告诉小南一个谜題: “眼镜藏在我左数第3个玩具小人的右数第1个玩具小人的左数第2个玩具小人那里。 ”
小南发现, 这个谜题中玩具小人的朝向非常关键, 因为朝内和朝外的玩具小人的左右方向是相反的: 面朝圈内的玩具小人, 它的左边是顺时针方向, 右边是逆时针方向; 而面向圈外的玩具小人, 它的左边是逆时针方向, 右边是顺时针方向。
小南一边艰难地辨认着玩具小人, 一边数着:
singer朝内, 左数第3个是archer。
archer朝外,右数第1个是thinker。
thinker朝外, 左数第2个是writer。
所以眼镜藏在writer这里!
虽然成功找回了眼镜, 但小南并没有放心。 如果下次有更多的玩具小人藏他的眼镜, 或是谜題的长度更长, 他可能就无法找到眼镜了 。 所以小南希望你写程序帮他解决类似的谜題。 这样的谜題具体可以描述为:
有 n个玩具小人围成一圈, 已知它们的职业和朝向。现在第1个玩具小人告诉小南一个包含 m条指令的谜題, 其中第 z条指令形如“左数/右数第 s,个玩具小人”。 你需要输出依次数完这些指令后,到达的玩具小人的职业。
输入输出格式
输入格式:
输入的第一行包含两个正整数 n,m, 表示玩具小人的个数和指令的条数。
接下来 n行, 每行包含一个整数和一个字符串, 以逆时针为顺序给出每个玩具小人的朝向和职业。其中0表示朝向圈内, 1表示朝向圈外。保证不会出现其他的数。字符串长度不超过10且仅由小写字母构成, 字符串不为空, 并且字符串两两不同。 整数和字符串之问用一个空格隔开。
接下来 m行,其中第 z行包含两个整数 a,,s,,表示第 z条指令。若 a,= 0,表示向左数 s,个人;若a,= 1 ,表示向右数 s,个人。保证a,不会出现其他的数, 1≤ s,<n 。
输出格式:
输出一个字符串, 表示从第一个读入的小人开始, 依次数完 m条指令后到达的小人的职业。
输入输出样例
7 3
0 singer
0 reader
0 mengbier
1 thinker
1 archer
0 writer
1 mogician
0 3
1 1
0 2
writer
10 10
1 C
0 r
0 P
1 d
1 e
1 m
1 t
1 y
1 u
0 V
1 7
1 1
1 4
0 5
0 3
0 1
1 6
1 2
0 8
0 4
y
说明
【样例1说明】
这组数据就是【题目描述】 中提到的例子。
【子任务】
子任务会给出部分测试数据的特点。 如果你在解决题目中遇到了困难, 可以尝试只解决一部分测试数据。
每个测试点的数据规模及特点如下表:
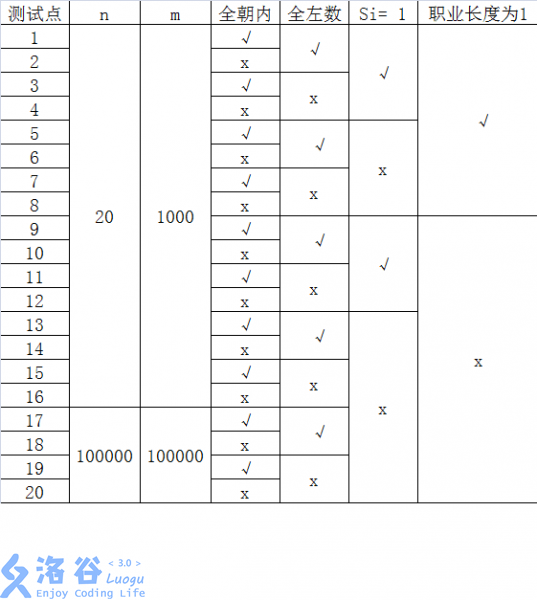
其中一些简写的列意义如下:
• 全朝内: 若为“√”, 表示该测试点保证所有的玩具小人都朝向圈内;
全左数:若为“√”,表示该测试点保证所有的指令都向左数,即对任意的
1≤z≤m, ai=0;
s,= 1:若为“√”,表示该测试点保证所有的指令都只数1个,即对任意的
1≤z≤m, si=1;
职业长度为1 :若为“√”,表示该测试点保证所有玩具小人的职业一定是一个
长度为1的字符串。
思路:纯模拟,可以用数组,理论上也可以用双向链表(但是真实考场上有位大佬炸了,只得了20.。。)。
#include<iostream>
#include<cstdio>
#include<cstring>
#include<cmath>
using namespace std;
const int MAXN=;
int n,m,how,step;
struct node
{
string name;
int to;
}a[MAXN];
int read(int &n)
{
char ch=' ';int q=,w=;
for(;(ch!='-')&&((ch<'')||(ch>''));ch=getchar());
if(ch=='-')w=-,ch=getchar();
for(;ch>='' && ch<='';ch=getchar())q=q*+ch-;
n=q*w; return n;
}
int main()
{
//freopen("toya.in","r",stdin);
//freopen("toya.out","w",stdout);
read(n);read(m);
//scanf("%d%d",&n,&m);
//ios::sync_with_stdio(false);
for(int i=;i<=n;++i)
{
read(a[i].to);
//scanf("%d",&a[i].to);
//cout<<a[i].to<<"*************"<<endl;
// 0朝向圈内 1朝向圈外
cin>>a[i].name;
}
int where=;
for(int i=;i<=m;++i)
{
read(how);read(step);
//scanf("%d%d",&how,&step);
// 0向左数,1向右数
if(how==)
{
if(a[where].to==)// 向内
{
where=where-step;
if(where<=)
where=where+n;
}
else if(a[where].to==)// 向外
{
where=where+step;
if(where>n)
where=where-n;
}
}
else// 向右数
{
if(a[where].to==)
{
where=where+step;
if(where>n)
where=where-n;
}
else
{
where=where-step;
if(where<=)
where=where+n;
}
}
}
cout<<a[where].name;
return ;
}
T2:天天爱跑步
题目描述
小c同学认为跑步非常有趣,于是决定制作一款叫做《天天爱跑步》的游戏。«天天爱跑步»是一个养成类游戏,需要玩家每天按时上线,完成打卡任务。
这个游戏的地图可以看作一一棵包含 nn个结点和 n-1n−1条边的树, 每条边连接两个结点,且任意两个结点存在一条路径互相可达。树上结点编号为从11到nn的连续正整数。
现在有mm个玩家,第ii个玩家的起点为 S_iSi,终点为 T_iTi 。每天打卡任务开始时,所有玩家在第00秒同时从自己的起点出发, 以每秒跑一条边的速度, 不间断地沿着最短路径向着自己的终点跑去, 跑到终点后该玩家就算完成了打卡任务。 (由于地图是一棵树, 所以每个人的路径是唯一的)
小C想知道游戏的活跃度, 所以在每个结点上都放置了一个观察员。 在结点jj的观察员会选择在第W_jWj秒观察玩家, 一个玩家能被这个观察员观察到当且仅当该玩家在第W_jWj秒也理到达了结点 jj 。 小C想知道每个观察员会观察到多少人?
注意: 我们认为一个玩家到达自己的终点后该玩家就会结束游戏, 他不能等待一 段时间后再被观察员观察到。 即对于把结点jj作为终点的玩家: 若他在第W_jWj秒重到达终点,则在结点jj的观察员不能观察到该玩家;若他正好在第W_jWj秒到达终点,则在结点jj的观察员可以观察到这个玩家。
输入输出格式
输入格式:
第一行有两个整数nn和mm 。其中nn代表树的结点数量, 同时也是观察员的数量, mm代表玩家的数量。
接下来 n- 1n−1行每行两个整数uu和 vv,表示结点 uu到结点 vv有一条边。
接下来一行 nn个整数,其中第jj个整数为W_jWj , 表示结点jj出现观察员的时间。
接下来 mm行,每行两个整数S_iSi,和T_iTi,表示一个玩家的起点和终点。
对于所有的数据,保证1\leq S_i,T_i\leq n, 0\leq W_j\leq n1≤Si,Ti≤n,0≤Wj≤n 。
输出格式:
输出1行 nn个整数,第jj个整数表示结点jj的观察员可以观察到多少人。
输入输出样例
6 3
2 3
1 2
1 4
4 5
4 6
0 2 5 1 2 3
1 5
1 3
2 6
2 0 0 1 1 1
5 3
1 2
2 3
2 4
1 5
0 1 0 3 0
3 1
1 4
5 5
1 2 1 0 1
说明
【样例1说明】
对于1号点,W_i=0Wi=0,故只有起点为1号点的玩家才会被观察到,所以玩家1和玩家2被观察到,共有2人被观察到。
对于2号点,没有玩家在第2秒时在此结点,共0人被观察到。
对于3号点,没有玩家在第5秒时在此结点,共0人被观察到。
对于4号点,玩家1被观察到,共1人被观察到。
对于5号点,玩家1被观察到,共1人被观察到。
对于6号点,玩家3被观察到,共1人被观察到。
【子任务】
每个测试点的数据规模及特点如下表所示。 提示: 数据范围的个位上的数字可以帮助判断是哪一种数据类型。
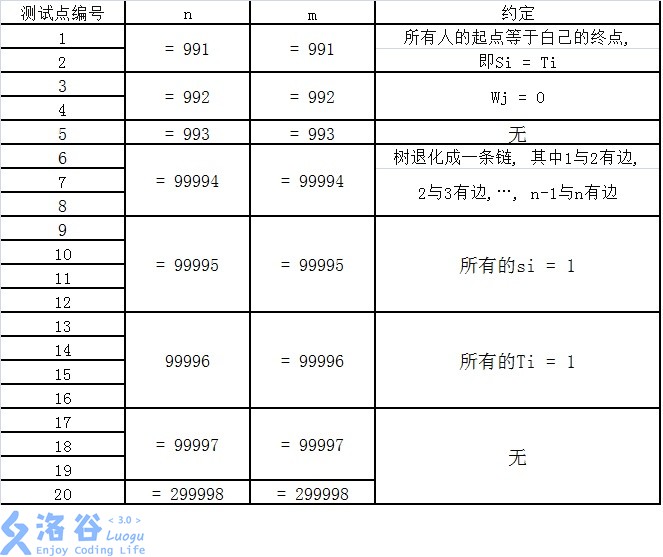
【提示】
如果你的程序需要用到较大的栈空问 (这通常意味着需要较深层数的递归), 请务必仔细阅读选手日录下的文本当rumung:/stact.p″, 以了解在最终评测时栈空问的限制与在当前工作环境下调整栈空问限制的方法。
在最终评测时,调用栈占用的空间大小不会有单独的限制,但在我们的工作
环境中默认会有 8 MB 的限制。 这可能会引起函数调用层数较多时, 程序发生
栈溢出崩溃。
我们可以使用一些方法修改调用栈的大小限制。 例如, 在终端中输入下列命
令 ulimit -s 1048576
此命令的意义是,将调用栈的大小限制修改为 1 GB。
例如,在选手目录建立如下 sample.cpp 或 sample.pas
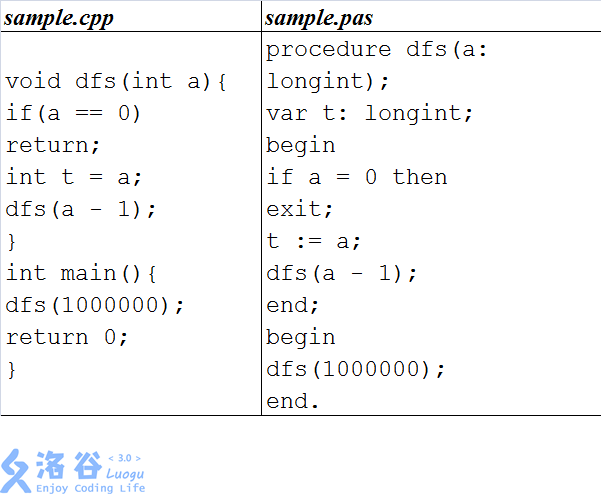
将上述源代码编译为可执行文件 sample 后,可以在终端中运行如下命令运
行该程序
./sample
如果在没有使用命令“ ulimit -s 1048576”的情况下运行该程序, sample
会因为栈溢出而崩溃; 如果使用了上述命令后运行该程序,该程序则不会崩溃。
特别地, 当你打开多个终端时, 它们并不会共享该命令, 你需要分别对它们
运行该命令。
请注意, 调用栈占用的空间会计入总空间占用中, 和程序其他部分占用的内
存共同受到内存限制。
思路:感觉能骗好多好多分,但是我还是太弱了,写完25分的暴力就没时间了。。。
正解: 已超出能力范围,怎么看都看不懂。。。。
引用一下别人的:
25分
考虑此时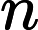 n很小,可以对于每条路径上暴力模拟,经过某个点时可以看一下当前时刻,是否跟经过的点的
n很小,可以对于每条路径上暴力模拟,经过某个点时可以看一下当前时刻,是否跟经过的点的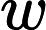 w相等,如果相等,则贡献加一。
w相等,如果相等,则贡献加一。
45分
注意到测试点

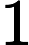
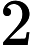 9−12时,保证
9−12时,保证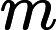 m条路径的出发点都是1,那么我们可以考虑如果将1作为树根,那么一条路径怎样才能对于它经过的点产生贡献。
m条路径的出发点都是1,那么我们可以考虑如果将1作为树根,那么一条路径怎样才能对于它经过的点产生贡献。
不难看出对于一个点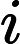 i,只有在
i,只有在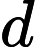
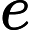
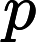
 deep[i]=w[i],才有可能有贡献。
deep[i]=w[i],才有可能有贡献。
我在考场上是直接用的链剖 +线段树,因为这就变成模板题了,而且n不到
+线段树,因为这就变成模板题了,而且n不到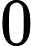 10w,尽管复杂度偏高,但是不易错。
10w,尽管复杂度偏高,但是不易错。
直接对于每条路径经过的点在线段树上增加1次经过次数,显然只有deep与w相等的点才会产生贡献。
事实上对于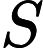 S=1的情况有线性的算法,正解会详细介绍,不再赘述。
S=1的情况有线性的算法,正解会详细介绍,不再赘述。
60分
注意到测试点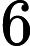
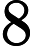 6−8时,题目保证树退化成链。我们观察一下对于链而言,有什么特别的地方。首先要明确,此时m条路径在链上肯定是要么往左要么往右,即
6−8时,题目保证树退化成链。我们观察一下对于链而言,有什么特别的地方。首先要明确,此时m条路径在链上肯定是要么往左要么往右,即
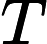 S<=T或者
S<=T或者 S>T。
S>T。
先只考虑S<=T的情况,如果对于S到T之间的点i,要产生贡献的话,肯定满足i−S=w[i],移项可得S=i−w[i]时才可以满足要求。
注意到等式右边只与i本身有关,不妨设为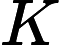 K[i],所以题目变成了查询S到T之间K[i]等于S的i的数量。
K[i],所以题目变成了查询S到T之间K[i]等于S的i的数量。
因为题目只涉及到首和尾,我们可以很容易联想到差分,即对于S打上+1标记,T打上−1标记。
根据上述思路,我们考虑具体做法:对于每个点i,我们很容易发现只有从一个特定的点出发才有可能对i产生贡献。
我们考虑维护一个统计数组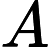 A,
A,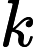 A[k]表示的是处理到当前的结点时,从k出发的路径(而且还没有走到终点)有多少条。
A[k]表示的是处理到当前的结点时,从k出发的路径(而且还没有走到终点)有多少条。
这样对于每个点i,我们只要查询一下所对应的A[K[i]]就可以了,根据上面的分析,这就是我们的答案了。
有一点注意处理:处理一个点i时,我们需要把以i为起点的路径加入统计数组A,再计算这个结点的贡献,最后再把以这个结点为终点的路径从A中消除,具体可以用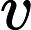

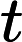

 vector实现(上述处理顺序的必要性仔细想想就很容易想通了)。
vector实现(上述处理顺序的必要性仔细想想就很容易想通了)。
而对于S>T的情况完全类似,只是需要把K[i]定义为i+w[i],其余做法完全类似。
100分
题目中设计的几个档次的部分分其实暗示已经很明显了。
链的做法离正解就不远了。
而S=1和T=1是在告诉我们什么呢?
拆路径!
很容易发现,一条S到T的路径可以拆成一条S到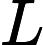
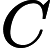 LCA的路径和LCA到T的路径,然后对于这两条路径,一条往上,一条往下,都可以对应成链的处理方式了!
LCA的路径和LCA到T的路径,然后对于这两条路径,一条往上,一条往下,都可以对应成链的处理方式了!
考虑对于每条路径,先将其拆分成两条路径(为了简化对LCA在两条路径中都出现的各种情况,我们可以先就让LCA出现两次,如果最后发现LCA是有贡献的,只需−1即可),同样,我们先只考虑向上的路径。
如果我们对于S在统计数组A上打上1的标记,LCA在统计数组A上打上−1的标记,那么题目转化为求一个点的子树和。
考虑上述做法正确性:因为只有S到LCA路径之间的点会产生贡献,而当这个点位于路径之间时,子树和会产生1的贡献,而在S的子树中或者LCA的上方都不会产生贡献。
具体实现呢?
对于一个点i,产生贡献的条件是deep[S]−deep[i]=w[i],同样令K[i]=deep[i]+w[i],当我们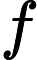
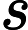 dfs到i时查询A[k[i]]的值即为贡献。
dfs到i时查询A[k[i]]的值即为贡献。
为了保证正确性,我们思考统计答案的方式和顺序。
首先我们肯定是在处理完i的子树之后再来处理i(想想就知道了),然后我们需要再把以i出发的向上的路径加入统计数组,再进行查询,最后把以i为终点的路径所产生的贡献在统计数组A中消除即可。
注意到我们上面维护的仅仅是一个点的深度,由于同一深度的点很多,所以我们查询的时候会发现会把不在同一子树的点统计入答案,那怎么办呢?我们考虑对于一个点要查询子树和,肯定是只要单独地考虑这一个子树的贡献,所以我们可以记录进入i时A[k[i]]的值,再在访问完i的子树之后统计答案时,看一下此时新的A[k[i]]的值。
容易发现新的值减掉进入时的,才是真正的i的子树中的A[k[i]]的值。
这样我们就可以避免把别的子树的答案统计进来了。
对于向下的点做法类似,有一点复杂的地方就是等式变成了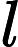 deep[T]−deep[i]=len−w[i](len为路径长度),发现如果这样做的话会出现负数,那么我们就把统计数组向右平移
deep[T]−deep[i]=len−w[i](len为路径长度),发现如果这样做的话会出现负数,那么我们就把统计数组向右平移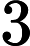

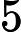 3∗105位就可以了。
3∗105位就可以了。
上述做法如果采用的是倍增求LCA的话,复杂度就是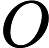
 O(nlogn);
O(nlogn);
如果用
 tarjan离线求LCA的话,可以做到O(n+m)。
tarjan离线求LCA的话,可以做到O(n+m)。
25分代码:
#include<cstdio>
#include<cstring>
#include<queue>
#include<algorithm>
using namespace std;
const int MAXN=;
const int INF=0x7fffff;
inline void read(int &n)
{
char c=getchar();n=;bool flag=;
while(c<''||c>'') c=='-'?flag=,c=getchar():c=getchar();
while(c>=''&&c<='') n=n*+c-,c=getchar();flag==?n=-n:n=n;
}
struct node
{
int u,v,nxt;
}edge[MAXN];
int head[MAXN];
int num=;
inline void add_edge(int x,int y)
{
edge[num].u=x;
edge[num].v=y;
edge[num].nxt=head[x];
head[x]=num++;
}
int n,m;
int W[MAXN];
struct Player
{
int bg,ed;
}player[MAXN];
int dis[MAXN];
int vis[MAXN];
int PointPre[MAXN];
int ans[MAXN];
inline void SPFA(int S,int T)
{
for(int i=;i<=n+;i++) dis[i]=INF,vis[i]=,PointPre[i]=-;
queue<int>q;dis[S]=;vis[S]=;
q.push(S);
while(!q.empty())
{
int p=q.front();q.pop();
vis[p]=;
for(int i=head[p];i!=-;i=edge[i].nxt)
{
if(dis[edge[i].v]>dis[edge[i].u]+)
{
dis[edge[i].v]=dis[edge[i].u]+;
PointPre[edge[i].v]=edge[i].u;
if(!vis[edge[i].v])
q.push(edge[i].v),vis[edge[i].v]=;
}
}
}
}
void Calc(int S,int T)
{
int NowPoint=T,NowTime=;
while(PointPre[NowPoint]!=-)
{
NowPoint=PointPre[NowPoint];
NowTime++;
}
NowPoint=T;
while(PointPre[NowPoint]!=-)
{
if(W[NowPoint]==NowTime)
ans[NowPoint]++;
NowTime--;
NowPoint=PointPre[NowPoint];
}
if(W[NowPoint]==NowTime)
ans[NowPoint]++;
}
int main()
{
memset(head,-,sizeof(head));
read(n);read(m);
for(int i=;i<=n-;i++)
{int x,y;read(x);read(y);add_edge(x,y);add_edge(y,x);}
for(int i=;i<=n;i++) read(W[i]);//观察员出现的时间
for(int i=;i<=m;i++)
{read(player[i].bg);read(player[i].ed);} if(n%==)
{
for(int i=;i<=n;i++)
{
int nt=;
if(player[i].bg>player[i].ed)
{
for(int j=player[i].bg;j>=player[i].ed;j--)
if(W[j]==nt) ans[j]++;
nt++;
}
else
{
for(int j=player[i].bg;j<=player[i].ed;j++)
if(W[j]==nt) ans[j]++;
nt++;
}
}
for(int i=;i<=n;i++)
printf("%d ",ans[i]);
}
else
{
for(int i=;i<=m;i++)
{SPFA(player[i].bg,player[i].ed);
Calc(player[i].bg,player[i].ed);} for(int i=;i<=n;i++)
printf("%d ",ans[i]);
} return ;
}
T3:换教室
题目描述
对于刚上大学的牛牛来说,他面临的第一个问题是如何根据实际情况申请合适的课程。
在可以选择的课程中,有 2n2n 节课程安排在 nn 个时间段上。在第 ii(1 \leq i \leq n1≤i≤n)个时间段上,两节内容相同的课程同时在不同的地点进行,其中,牛牛预先被安排在教室 c_ici 上课,而另一节课程在教室 d_idi 进行。
在不提交任何申请的情况下,学生们需要按时间段的顺序依次完成所有的 nn 节安排好的课程。如果学生想更换第 ii 节课程的教室,则需要提出申请。若申请通过,学生就可以在第 ii 个时间段去教室 d_idi 上课,否则仍然在教室 c_ici 上课。
由于更换教室的需求太多,申请不一定能获得通过。通过计算,牛牛发现申请更换第 ii 节课程的教室时,申请被通过的概率是一个已知的实数 k_iki,并且对于不同课程的申请,被通过的概率是互相独立的。
学校规定,所有的申请只能在学期开始前一次性提交,并且每个人只能选择至多 mm 节课程进行申请。这意味着牛牛必须一次性决定是否申请更换每节课的教室,而不能根据某些课程的申请结果来决定其他课程是否申请;牛牛可以申请自己最希望更换教室的 mm 门课程,也可以不用完这 mm 个申请的机会,甚至可以一门课程都不申请。
因为不同的课程可能会被安排在不同的教室进行,所以牛牛需要利用课间时间从一间教室赶到另一间教室。
牛牛所在的大学有 vv 个教室,有 ee 条道路。每条道路连接两间教室,并且是可以双向通行的。由于道路的长度和拥堵程度不同,通过不同的道路耗费的体力可能会有所不同。 当第 ii(1 \leq i \leq n-11≤i≤n−1)节课结束后,牛牛就会从这节课的教室出发,选择一条耗费体力最少的路径前往下一节课的教室。
现在牛牛想知道,申请哪几门课程可以使他因在教室间移动耗费的体力值的总和的期望值最小,请你帮他求出这个最小值。
输入输出格式
输入格式:
第一行四个整数 n,m,v,en,m,v,e。nn 表示这个学期内的时间段的数量;mm 表示牛牛最多可以申请更换多少节课程的教室;vv 表示牛牛学校里教室的数量;ee表示牛牛的学校里道路的数量。
第二行 nn 个正整数,第 ii(1 \leq i \leq n1≤i≤n)个正整数表示 c_ici,即第 ii 个时间段牛牛被安排上课的教室;保证 1 \le c_i \le v1≤ci≤v。
第三行 nn 个正整数,第 ii(1 \leq i \leq n1≤i≤n)个正整数表示 d_idi,即第 ii 个时间段另一间上同样课程的教室;保证 1 \le d_i \le v1≤di≤v。
第四行 nn 个实数,第 ii(1 \leq i \leq n1≤i≤n)个实数表示 k_iki,即牛牛申请在第 ii 个时间段更换教室获得通过的概率。保证 0 \le k_i \le 10≤ki≤1。
接下来 ee 行,每行三个正整数 a_j, b_j, w_jaj,bj,wj,表示有一条双向道路连接教室 a_j, b_jaj,bj,通过这条道路需要耗费的体力值是 w_jwj;保证 1 \le a_j, b_j \le v1≤aj,bj≤v, 1 \le w_j \le 1001≤wj≤100。
保证 1 \leq n \leq 20001≤n≤2000,0 \leq m \leq 20000≤m≤2000,1 \leq v \leq 3001≤v≤300,0 \leq e \leq 900000≤e≤90000。
保证通过学校里的道路,从任何一间教室出发,都能到达其他所有的教室。
保证输入的实数最多包含 33 位小数。
输出格式:
输出一行,包含一个实数,四舍五入精确到小数点后恰好22位,表示答案。你的输出必须和标准输出完全一样才算正确。
测试数据保证四舍五入后的答案和准确答案的差的绝对值不大于 4 \times 10^{-3}4×10−3。 (如果你不知道什么是浮点误差,这段话可以理解为:对于大多数的算法,你可以正常地使用浮点数类型而不用对它进行特殊的处理)
输入输出样例
3 2 3 3
2 1 2
1 2 1
0.8 0.2 0.5
1 2 5
1 3 3
2 3 1
2.80
说明
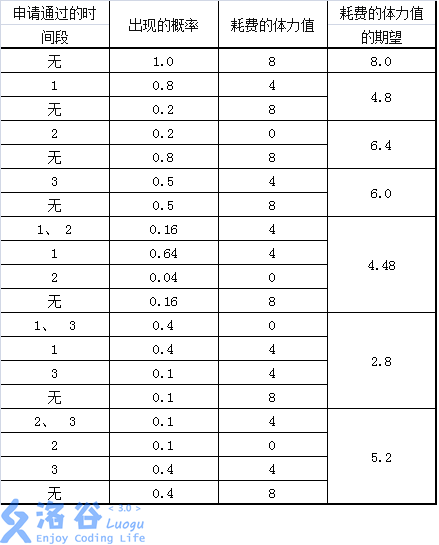
【样例1说明】
所有可行的申请方案和期望收益如下表:
【提示】
- 道路中可能会有多条双向道路连接相同的两间教室。 也有可能有道路两端连接
的是同一间教室。
2.请注意区分n,m,v,e的意义, n不是教室的数量, m不是道路的数量。
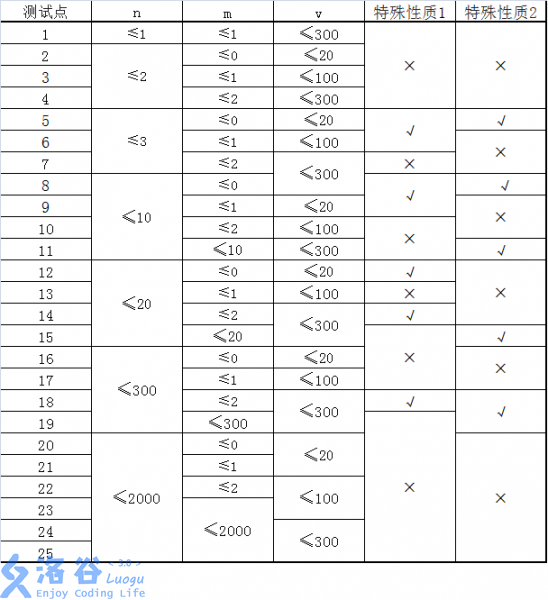
特殊性质1:图上任意两点 ai, bi, ai≠ bi间,存在一条耗费体力最少的路径只包含一条道路。
特殊性质2:对于所有的1≤ i≤ n, ki= 1 。
483 055 310
Noip历年以来的第一道概率题
我一开始想到了24分的做法,就是m=0的情况,
还有一种80分的做法,暴力枚举换不换。
100分的做法是DP
用dp[i][j][0]表示前i个时间段,已经换了j个,第i个不换的情况,dp[i][j][1]表示换的情况,
转移方程需要考虑:
1.这次换不换
2.上次换没换
3.对于每一种情况的期望,
然后根据期望具有线性的原理,
累加即可
注意在读入边的时候需要特殊判断一下
#include<cstdio>
#include<cstring>
#include<queue>
#include<algorithm>
using namespace std;
const int MAXN=;
const int INF=0x7ffff;
inline void read(int &n)
{
char c=getchar();n=;bool flag=;
while(c<''||c>'') c=='-'?flag=,c=getchar():c=getchar();
while(c>=''&&c<='') n=n*+c-,c=getchar();flag==?n=-n:n=n;
}
int n,m,v,e;
int C[MAXN],D[MAXN];
double K[MAXN];// 概率
double dis[MAXN][MAXN];
double dp[MAXN][MAXN][];
inline void floyed()
{
/*for(int k=1;k<=v;k++)
for(int i=1;i<=v;i++)
for(int j=1;j<=v;j++)
if(dis[i][j]>dis[i][k]+dis[k][j]) dis[i][j]=dis[i][k]+dis[k][j];*/
for(int k=;k<=v;k++)
for(int i=;i<=v;i++)
if(k!=i)
for(int j=;j<=v;j++)
if(i!=j && j!=k)
dis[j][i]=dis[i][j]=min(dis[i][j],dis[i][k]+dis[k][j]);
for(int i=;i<=n;i++)
{
for(int j=;j<=m;j++)
dp[i][j][]=dp[i][j][]=INF;
}
dp[][][]=;dp[][][]=;
}
inline void DP()
{
for(int i=;i<=n;i++)// 每一个时间段
{
for(int j=;j<=m;j++)// 可以提出申请的次数
{
if(j==)
dp[i][j][]=dp[i-][j][]+dis[C[i]][C[i-]];
else
{
dp[i][j][]=min( dp[i-][j][] + dis[C[i]][C[i-]] ,
dp[i-][j][] + dis[C[i]][D[i-]] * K[i-] +
dis[C[i]][C[i-]] * (-K[i-]));
// 本次不提出申请
dp[i][j][]=min( dp[i-][j-][] + dis[D[i]][C[i-]] * K[i]
+ dis[C[i]][C[i-]] * (-K[i]) ,
dp[i-][j-][] + dis[D[i]][D[i-]] * K[i] * K[i-]
+ dis[D[i]][C[i-]] * K[i] * (-K[i-])
+ dis[C[i]][D[i-]] * (-K[i]) * K[i-]
+ dis[C[i]][C[i-]] * (-K[i]) * (-K[i-]));
}
}
}
double ans=;
for(int j=;j<=m;j++)
ans=min(ans,min(dp[n][j][],dp[n][j][]));
printf("%.2lf",ans);
}
int main()
{
//freopen("classrooma.in","r",stdin);
//freopen("classrooma.out","w",stdout);
read(n);read(m);read(v);read(e);
for(int i=;i<=n;i++) read(C[i]);
for(int i=;i<=n;i++) read(D[i]);
for(int i=;i<=n;i++) scanf("%lf",&K[i]);
for(int i=;i<=v;i++)
{
for(int j=;j<=v;j++)
dis[i][j]=INF;
dis[i][i]=;
}
for(int i=;i<=e;i++)
{ int x,y;double z;
read(x);read(y);scanf("%lf",&z);
dis[y][x]=dis[x][y]=min(dis[x][y],z);
}
floyed();
DP();
return ;
}
Noip 2016 Day1 题解的更多相关文章
- NOIP 2018 day1 题解
今年noip的题和去年绝对是比较坑的题了,但是打好的话就算是普通水准也能350分以上吧. t1: 很显然这是一个简单的dp即可. #include<iostream> #include&l ...
- Noip 2016 愤怒的小鸟 题解
[NOIP2016]愤怒的小鸟 时间限制:1 s 内存限制:256 MB [题目描述] Kiana最近沉迷于一款神奇的游戏无法自拔. 简单来说,这款游戏是在一个平面上进行的. 有一架弹弓位于(0, ...
- NOI 2016 Day1 题解
今天写了NOI2016Day1的题,来写一发题解. T2 网格 题目传送门 Description \(T\) 次询问,每次给出一个 \(n\times m\) 的传送门,上面有 \(c\) 个位置是 ...
- noip 2016 day1 T1玩具谜题
题目描述 小南有一套可爱的玩具小人, 它们各有不同的职业. 有一天, 这些玩具小人把小南的眼镜藏了起来. 小南发现玩具小人们围成了一个圈,它们有的面朝圈内,有的面朝圈外.如下图: 这时singer告诉 ...
- NOIP 2016 蚯蚓 题解
一道有趣的题目,首先想到合并果子,然而发现会超时,我们可以发现首先拿出来的切掉后比后拿出来切掉后还是还长,即满足单调递增,故建立三个队列即可. 代码 #include<bits/stdc++.h ...
- [NOIP]2016天天爱跑步
[NOIP]2016天天爱跑步 标签: LCA 树上差分 NOIP Description 小C同学认为跑步非常有趣,于是决定制作一款叫做<天天爱跑步>的游戏.<天天爱跑步>是 ...
- NOIp 2016 总结
NOIp 2016 总结 -----YJSheep Day 0 对于考前的前一天,晚自习在复习图论的最短路和生成树,加深了图的理解.睡得比较早,养足精力明日再战. Day 1 拿到题目,先过一边,题目 ...
- 【NOIP 2016】斗地主
题意 NOIP 2016 斗地主 给你一些牌,按照斗地主的出牌方式,问最少多少次出完所有的牌. 分析 这道题的做法是DFS. 为了体现这道题的锻炼效果,我自己写了好多个代码. Ver1 直接暴力搞,加 ...
- THUSC2017 Day1题解
THUSC2017 Day1题解 巧克力 题目描述 "人生就像一盒巧克力,你永远不知道吃到的下一块是什么味道." 明明收到了一大块巧克力,里面有若干小块,排成n行m列.每一小块都有 ...
随机推荐
- yum-config-manager --add-repo=
[root@server0 yum.repos.d]# yum-config-manager --add-repo=ftp://192.168.31.121/centos7u4Loaded plugi ...
- 【codeforces 816B】Karen and Coffee
[题目链接]:http://codeforces.com/contest/816/problem/B [题意] 给你很多个区间[l,r]; 1<=l<=r<=2e5 一个数字如果被k ...
- SPOJ 962 Intergalactic Map
Intergalactic Map Time Limit: 6000ms Memory Limit: 262144KB This problem will be judged on SPOJ. Ori ...
- Jquery控件jrumble
<!DOCTYPE HTML> <html> <head> <title>demo.html</title> <meta h ...
- hdu2236
链接:点击打开链接 题意:在一个n*n的矩阵中,找n个数使得这n个数都在不同的行和列里而且要求这n个数中的最大值和最小值的差值最小 代码: #include <iostream> #inc ...
- Android实战技巧之三十七:图片的Base64编解码
通经常使用Base64这样的编解码方式将二进制数据转换成可见的字符串格式,就是我们常说的大串.10块钱一串的那种,^_^. Android的android.util包下直接提供了一个功能十分完备的Ba ...
- bzoj3158&3275: 千钧一发(最小割)
3158: 千钧一发 题目:传送门 题解: 这是一道很好的题啊...极力推荐 细看题目:要求一个最大价值,那么我们可以转换成求损失的价值最小 那很明显就是最小割的经典题目啊?! 但是这里两个子集的分化 ...
- nyoj--108--士兵杀敌(一)(区间求和&&树状数组)
士兵杀敌(一) 时间限制:1000 ms | 内存限制:65535 KB 难度:3 描述 南将军手下有N个士兵,分别编号1到N,这些士兵的杀敌数都是已知的. 小工是南将军手下的军师,南将军现在想知 ...
- SparkSQL基础
* SparkSQL基础 起源: 1.在三四年前,Hive可以说是SQL on Hadoop的唯一选择,负责将SQL编译成可扩展的MapReduce作业.鉴于Hive的性能以及与Spark的兼容,Sh ...
- kindeditor 不能编辑 问题
/*显示上传窗体*/ function ShowUplodToDaily() { var _sdata = grid.getSelecteds(); if (_sdata) { /*创建编辑器*/ v ...