caffe中lenet_train_test.prototxt配置文件注解
caffe框架下的lenet.prototxt定义了一个广义上的LeNet模型,对MNIST数据库进行训练实际使用的是lenet_train_test.prototxt模型。
lenet_train_test.prototxt模型定义了一个包含2个卷积层,2个池化层,2个全连接层,1个激活函数层的卷积神经网络模型,模型如下:

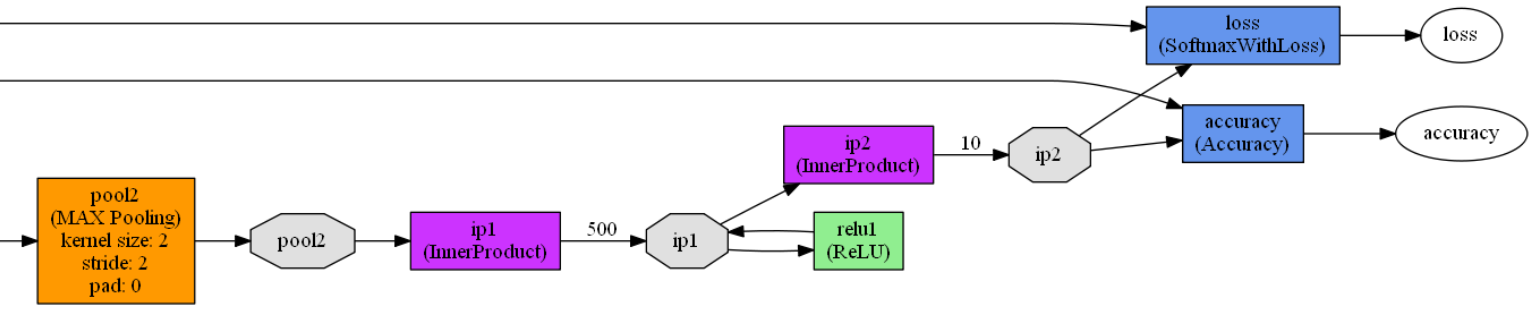
name: "LeNet" //神经网络的名称是LeNetlayer { //定义一个网络层name: "mnist" //网络层的名称是mnisttype: "Data" //网络层的类型是数据层top: "data" //网络层的输出是data和label(有两个输出)top: "label"include { //定义该网络层只在训练阶段有效phase: TRAIN}transform_param {scale: 0.00390625 //归一化参数,输入的数据都是需要乘以该参数(1/256)//由于图像数据上的像素值大小范围是0~255,这里乘以1/256//相当于把输入归一化到0~1}data_param {source: "D:/Software/Caffe/caffe-master/examples/mnist/mnist_train_lmdb" //训练数据的路径batch_size: 64 //每批次训练样本包含的样本数backend: LMDB //数据格式(后缀)定义为LMDB,另一种数据格式是leveldb}}layer { //定义一个网络层name: "mnist" //网络层的名称是mnisttype: "Data" //网络层的类型是数据层top: "data" //网络层的输出是data和label(有两个输出)top: "label"include { //定义该网络层只在测试阶段有效phase: TEST}transform_param {scale: 0.00390625 //归一化系数是1/256,数据都归一化到0~1}data_param {source: "D:/Software/Caffe/caffe-master/examples/mnist/mnist_test_lmdb" //测试数据路径batch_size: 100 //每批次测试样本包含的样本数backend: LMDB //数据格式(后缀)是LMDB}}layer { //定义一个网络层name: "conv1" //网络层的名称是conv1type: "Convolution" //网络层的类型是卷积层bottom: "data" //网络层的输入是datatop: "conv1" //网络层的输出是conv1param {lr_mult: 1 //weights的学习率跟全局基础学习率保持一致}param {lr_mult: 2 //偏置的学习率是全局学习率的两倍}convolution_param { //卷积参数设置num_output: 20 //输出是20个特征图kernel_size: 5 //卷积核的尺寸是5*5stride: 1 //卷积步长是1weight_filler {type: "xavier" //指定weights权重初始化方式}bias_filler {type: "constant" //bias(偏置)的初始化全为0}}}layer { //定义一个网络层name: "pool1" //网络层的名称是pool1type: "Pooling" //网络层的类型是池化层bottom: "conv1" //网络层的输入是conv1top: "pool1" //网络层的输出是pool1pooling_param { //池化参数设置pool: MAX //池化方式最大池化kernel_size: 2 //池化核大小2*2stride: 2 //池化步长2}}layer { //定义一个网络层name: "conv2" //网络层的名称是conv2type: "Convolution" //网络层的类型是卷积层bottom: "pool1" //网络层的输入是pool1top: "conv2" //网络层的输出是conv2param {lr_mult: 1 //weights的学习率跟全局基础学习率保持一致}param {lr_mult: 2 //偏置的学习率是全局学习率的两倍}convolution_param { //卷积参数设置num_output: 50 //输出是50个特征图kernel_size: 5 //卷积核的尺寸是5*5stride: 1 //卷积步长是1weight_filler {type: "xavier" //指定weights权重初始化方式}bias_filler {type: "constant" //bias(偏置)的初始化全为0}}}layer { //定义一个网络层name: "pool2" //网络层的名称是pool2type: "Pooling" //网络层的类型是池化层bottom: "conv2" //网络层的输入是conv2top: "pool2" //网络层的输出是pool2pooling_param { //池化参数设置pool: MAX //池化方式最大池化kernel_size: 2 //池化核大小2*2stride: 2 //池化步长2}}layer { //定义一个网络层name: "ip1" //网络层的名称是ip1type: "InnerProduct" //网络层的类型是全连接层bottom: "pool2" //网络层的输入是pool2top: "ip1" //网络层的输出是ip1param {lr_mult: 1 //指定weights权重初始化方式}param {lr_mult: 2 //bias(偏置)的初始化全为0}inner_product_param { //全连接层参数设置num_output: 500 //输出是一个500维的向量weight_filler {type: "xavier" //指定weights权重初始化方式}bias_filler {type: "constant" //bias(偏置)的初始化全为0}}}layer { //定义一个网络层name: "relu1" //网络层的名称是relu1type: "ReLU" //网络层的类型是激活函数层bottom: "ip1" //网络层的输入是ip1top: "ip1" //网络层的输出是ip1}layer { //定义一个网络层name: "ip2" //网络层的名称是ip2type: "InnerProduct" //网络层的类型是全连接层bottom: "ip1" //网络层的输入是ip1top: "ip2" //网络层的输出是ip2param {lr_mult: 1 //指定weights权重初始化方式}param {lr_mult: 2 //bias(偏置)的初始化全为0}inner_product_param { //全连接层参数设置num_output: 10 //输出是一个10维的向量,即0~9的数字weight_filler {type: "xavier" //指定weights权重初始化方式}bias_filler {type: "constant" //bias(偏置)的初始化全为0}}}layer { //定义一个网络层name: "accuracy" //网络层的名称是accuracytype: "Accuracy" //网络层的类型是准确率层bottom: "ip2" //网络层的输入是ip2和labelbottom: "label"top: "accuracy" //网络层的输出是accuracyinclude { //定义该网络层只在测试阶段有效phase: TEST}}layer { //定义一个网络层name: "loss" //网络层的名称是losstype: "SoftmaxWithLoss" //网络层的损失函数采用Softmax计算bottom: "ip2" //网络层的输入是ip2和labelbottom: "label"top: "loss" //网络层的输出是loss}
caffe中lenet_train_test.prototxt配置文件注解的更多相关文章
- caffe中lenet_solver.prototxt配置文件注解
caffe框架自带的例子mnist里有一个lenet_solver.prototxt文件,这个文件是具体的训练网络的引入文件,定义了CNN网络架构之外的一些基础参数,如总的迭代次数.测试间隔.基础学习 ...
- [转]caffe中solver.prototxt参数说明
https://www.cnblogs.com/denny402/p/5074049.html solver算是caffe的核心的核心,它协调着整个模型的运作.caffe程序运行必带的一个参数就是so ...
- 浅谈caffe中train_val.prototxt和deploy.prototxt文件的区别
本文以CaffeNet为例: 1. train_val.prototxt 首先,train_val.prototxt文件是网络配置文件.该文件是在训练的时候用的. 2.deploy.prototxt ...
- Caffe中deploy.prototxt 和 train_val.prototxt 区别
之前用deploy.prototxt 还原train_val.prototxt过程中,遇到了坑,所以打算总结一下 本人以熟悉的LeNet网络结构为例子 不同点主要在一前一后,相同点都在中间 train ...
- caffe中通过prototxt文件查看神经网络模型结构的方法
在修改propotxt之前我们可以对之前的网络结构进行一个直观的认识: 可以使用http://ethereon.github.io/netscope/#/editor 这个网址. 将propotxt文 ...
- caffe 中solver.prototxt
关于cifar-10和mnist的weight_decay和momentum也是相当的重要:就是出现一次把cifar-10的两个值直接用在mnist上,发现错误很大.
- caffe mnist实例 --lenet_train_test.prototxt 网络配置详解
1.mnist实例 ##1.数据下载 获得mnist的数据包,在caffe根目录下执行./data/mnist/get_mnist.sh脚本. get_mnist.sh脚本先下载样本库并进行解压缩,得 ...
- caffe中LetNet-5卷积神经网络模型文件lenet.prototxt理解
caffe在 .\examples\mnist文件夹下有一个 lenet.prototxt文件,这个文件定义了一个广义的LetNet-5模型,对这个模型文件逐段分解一下. name: "Le ...
- Windows下使用python绘制caffe中.prototxt网络结构数据可视化
准备工具: 1. 已编译好的pycaffe 2. Anaconda(python2.7) 3. graphviz 4. pydot 1. graphviz安装 graphviz是贝尔实验室开发的一个 ...
随机推荐
- insmod hello.ko -1 Invalid module format最简单的解决的方法
在下也是从网上搜索到的这样的解决的方法. 遇到这样的情况后,通过dmesg看一下内核日志. 假设发现有例如以下日志.那就好办了. hello: version magic '2.6.33.3 ' sh ...
- PHPStorm中使用bootstrap3控件!
PHPStorm中使用bootstrap3控件! 奇怪为什么不自动提示呢? 原来需要Ctrl+j才显示出来! 很方便的控件!!!!
- 光标属性CSS cursor 属性
CSS cursor 属性 CSS cursor属性,以前不知道,如果以后用到自己看的 <html> <body> <p>请把鼠标移动到单词上,可以看到鼠标指针发生 ...
- 基本类型转换成NSNumber类型
int i=100; float f=2.34; NSNumber *n1=[NSNumber numberWithInt:i]; NSNumber *n2=[NSNumber numberWithF ...
- 体系化认识RPC--转
原文地址:http://www.infoq.com/cn/articles/get-to-know-rpc?utm_source=infoq&utm_medium=popular_widget ...
- java与javascript对cookie操作的工具类
Java对cookie的操作 package cn.utils; import java.util.HashMap; import java.util.Map; import javax.servle ...
- HDU 1009 FatMouse' Trade【贪心】
解题思路:一只老鼠共有m的猫粮,给出n个房间,每一间房间可以用f[i]的猫粮换取w[i]的豆,问老鼠最多能够获得豆的数量 sum 即每一间房间的豆的单价为v[i]=f[i]/w[i],要想买到最多的豆 ...
- 记一次html页面传值给另一个html并解码
前言 由于最近写项目用到layui中的table.render,好像是直接由当前html直接与后台controller取数据,由一方(后台)遍历列表给html,而如果当前html需要传值给这个后台co ...
- 【XSY2988】取石子
题目来源:NOI2018模拟测试赛(二十六) 题解: 设a<b: 可以先考虑a=1的特殊情况,注意到后手的最优策略是跟着另外一个人取,取到最后剩余不到$a+b$时再看奇偶性: 那么很容易想到把所 ...
- BZOJ 3413 匹配 (后缀自动机+线段树合并)
题目大意: 懒得概括了 神题,搞了2个半晚上,还认为自己的是对的...一直调不过,最后终于在jdr神犇的帮助下过了这道题 线段树合并该是这道题最好理解且最好写的做法了,貌似主席树也行?但线段树合并这个 ...