分布式ID解决方案
<div class="content" id="articleContent">
<div class="ad-wrap">
开发十年,就只剩下这套Java开发体系了
>>> 
在游戏开发中,我们使用分布式ID。有很多优点
- 便于合服
- 便于ID管理
- 等等
一、单服各自ID系统的弊端
1. 列如合服
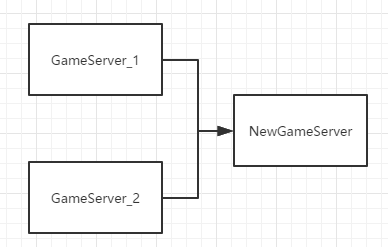
在游戏上线后,合服是避免不了的事情。如果按照传统的数据库表自增来作为数据的唯一ID、或者每个游戏中是相同的自增。这样在合服的时候你就会相当的麻烦了。
比如上图我们要把GameServer_2的数据合并到GameServer_1中,它们都有一个Player ID = 1的玩家,这个时候你就必须要重建GameServer_2中的Player_ID了。而引用了PlayerID的相关数据的PlayerID也全部需要修改。这还只是PlayerID的变化。在游戏中很多的表和关联,如果都要去修正ID,想想都可怕!
2. ID管理
在很多手游、页游中。都设计有跨服系统。一旦ID是各自自增。在跨服服务器你就傻傻分不清楚了。还有比如GM后台查询等等一系列问题。
二、分布式ID推荐
为了解决上面的问题,最好的解决办法就是采用分布式ID方案,分布式ID方案很多。java有自带的UUID。但是考虑到排序、存储空间等。UUID不是最佳的解决方案。下面我介绍一种分布式ID解决方案。
Twitter_Snowflake
SnowFlake的结构如下(每部分用-分开):
0 - 0000000000 0000000000 0000000000 0000000000 0 - 00000 - 00000 - 000000000000
1位标识,由于long基本类型在Java中是带符号的,最高位是符号位,正数是0,负数是1,所以id一般是正数,最高位是0
41位时间截(毫秒级),注意,41位时间截不是存储当前时间的时间截,而是存储时间截的差值(当前时间截 - 开始时间截)
得到的值),这里的的开始时间截,一般是我们的id生成器开始使用的时间,由我们程序来指定的(如下下面程序IdWorker类的startTime属性)。41位的时间截,可以使用69年,年T = (1L << 41) / (1000L * 60 * 60 * 24 * 365) = 69
10位的数据机器位,可以部署在1024个节点,包括5位datacenterId和5位workerId<br>
12位序列,毫秒内的计数,12位的计数顺序号支持每个节点每毫秒(同一机器,同一时间截)产生4096个ID序号
加起来刚好64位,为一个Long型。<br>
SnowFlake的优点是,整体上按照时间自增排序,并且整个分布式系统内不会产生ID碰撞(由数据中心ID和机器ID作区分),并且效率较高,经测试,SnowFlake每秒能够产生26万ID左右。上面这种分位,可能有些不是很适合服务器很多的游戏。这里留给我们可部署的服务器节点站位10个
System.out.print(1 << 10);算得结果就是1024个服务器,1024个服务器对于大多数游戏应该是够用了。但是极个别的1024个服务器节点可能不够。我们可以有很多办法解决此问题。
1.独立ID服务器:
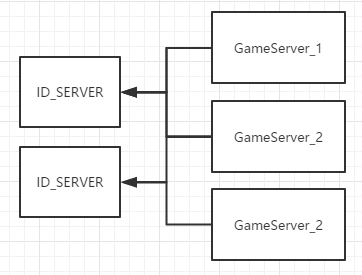
同一个ID_SERVER可以同时为多个游戏服务器提供ID,游戏服务器可以固定自定ID服务器,也可以吧ID服务器做成集群。这样我们的游戏就不受1024个节点的限制了!
但是有注意的一点,不要一个一个的去拿ID。毕竟不是当前进程去远程拿ID还是有网络、IO等消耗。较好的做法是一次拿一批,比如每次拿1000个然后缓存在本地服务器,当1000个快要耗尽时再去拿一批ID。
2.就是改Snowflake的分位
Snowflake能使用69年,如果觉得时间过长可以缩短时间的位数。比如39位可以用17年。那么我们机器标示就是12位就可以有4096个服务器节点。如果还是觉得不好我们可以把单位时间做到秒级时间占31位,我们现在还有32位可支配。后面自增系列16位,一秒钟可以生成65536个ID,同样机器标示位16位也可以65536个服务器节点。怎么组合就看你自己的需求了。
Snowflake源码
package com.sojoys.artifact.tools;
/**
* Twitter_Snowflake<br>
* SnowFlake的结构如下(每部分用-分开):<br>
* 0 - 0000000000 0000000000 0000000000 0000000000 0 - 00000 - 00000 - 000000000000 <br>
* 1位标识,由于long基本类型在Java中是带符号的,最高位是符号位,正数是0,负数是1,所以id一般是正数,最高位是0<br>
* 41位时间截(毫秒级),注意,41位时间截不是存储当前时间的时间截,而是存储时间截的差值(当前时间截 - 开始时间截)
* 得到的值),这里的的开始时间截,一般是我们的id生成器开始使用的时间,由我们程序来指定的(如下下面程序IdWorker类的startTime属性)。41位的时间截,可以使用69年,年T = (1L << 41) / (1000L * 60 * 60 * 24 * 365) = 69<br>
* 10位的数据机器位,可以部署在1024个节点,包括5位datacenterId和5位workerId<br>
* 12位序列,毫秒内的计数,12位的计数顺序号支持每个节点每毫秒(同一机器,同一时间截)产生4096个ID序号<br>
* 加起来刚好64位,为一个Long型。<br>
* SnowFlake的优点是,整体上按照时间自增排序,并且整个分布式系统内不会产生ID碰撞(由数据中心ID和机器ID作区分),并且效率较高,经测试,SnowFlake每秒能够产生26万ID左右。
*/
public class SnowflakeIdWorker {
<span class="hljs-comment">// ==============================Fields===========================================</span>
<span class="hljs-comment">/** 开始时间截 (2015-01-01) */</span>
<span class="hljs-keyword">private</span> <span class="hljs-keyword">final</span> <span class="hljs-keyword">long</span> twepoch = <span class="hljs-number">1420041600000L</span>;
<span class="hljs-comment">/** 机器id所占的位数 */</span>
<span class="hljs-keyword">private</span> <span class="hljs-keyword">final</span> <span class="hljs-keyword">long</span> workerIdBits = <span class="hljs-number">5L</span>;
<span class="hljs-comment">/** 数据标识id所占的位数 */</span>
<span class="hljs-keyword">private</span> <span class="hljs-keyword">final</span> <span class="hljs-keyword">long</span> datacenterIdBits = <span class="hljs-number">5L</span>;
<span class="hljs-comment">/** 支持的最大机器id,结果是31 (这个移位算法可以很快的计算出几位二进制数所能表示的最大十进制数) */</span>
<span class="hljs-keyword">private</span> <span class="hljs-keyword">final</span> <span class="hljs-keyword">long</span> maxWorkerId = -<span class="hljs-number">1L</span> ^ (-<span class="hljs-number">1L</span> << workerIdBits);
<span class="hljs-comment">/** 支持的最大数据标识id,结果是31 */</span>
<span class="hljs-keyword">private</span> <span class="hljs-keyword">final</span> <span class="hljs-keyword">long</span> maxDatacenterId = -<span class="hljs-number">1L</span> ^ (-<span class="hljs-number">1L</span> << datacenterIdBits);
<span class="hljs-comment">/** 序列在id中占的位数 */</span>
<span class="hljs-keyword">private</span> <span class="hljs-keyword">final</span> <span class="hljs-keyword">long</span> sequenceBits = <span class="hljs-number">12L</span>;
<span class="hljs-comment">/** 机器ID向左移12位 */</span>
<span class="hljs-keyword">private</span> <span class="hljs-keyword">final</span> <span class="hljs-keyword">long</span> workerIdShift = sequenceBits;
<span class="hljs-comment">/** 数据标识id向左移17位(12+5) */</span>
<span class="hljs-keyword">private</span> <span class="hljs-keyword">final</span> <span class="hljs-keyword">long</span> datacenterIdShift = sequenceBits + workerIdBits;
<span class="hljs-comment">/** 时间截向左移22位(5+5+12) */</span>
<span class="hljs-keyword">private</span> <span class="hljs-keyword">final</span> <span class="hljs-keyword">long</span> timestampLeftShift = sequenceBits + workerIdBits + datacenterIdBits;
<span class="hljs-comment">/** 生成序列的掩码,这里为4095 (0b111111111111=0xfff=4095) */</span>
<span class="hljs-keyword">private</span> <span class="hljs-keyword">final</span> <span class="hljs-keyword">long</span> sequenceMask = -<span class="hljs-number">1L</span> ^ (-<span class="hljs-number">1L</span> << sequenceBits);
<span class="hljs-comment">/** 工作机器ID(0~31) */</span>
<span class="hljs-keyword">private</span> <span class="hljs-keyword">long</span> workerId;
<span class="hljs-comment">/** 数据中心ID(0~31) */</span>
<span class="hljs-keyword">private</span> <span class="hljs-keyword">long</span> datacenterId;
<span class="hljs-comment">/** 毫秒内序列(0~4095) */</span>
<span class="hljs-keyword">private</span> <span class="hljs-keyword">long</span> sequence = <span class="hljs-number">0L</span>;
<span class="hljs-comment">/** 上次生成ID的时间截 */</span>
<span class="hljs-keyword">private</span> <span class="hljs-keyword">long</span> lastTimestamp = -<span class="hljs-number">1L</span>;
<span class="hljs-comment">//==============================Constructors=====================================</span>
<span class="hljs-comment">/**
* 构造函数
* <span class="hljs-doctag">@param</span> workerId 工作ID (0~31)
* <span class="hljs-doctag">@param</span> datacenterId 数据中心ID (0~31)
*/</span>
<span class="hljs-function"><span class="hljs-keyword">public</span> <span class="hljs-title">SnowflakeIdWorker</span><span class="hljs-params">(<span class="hljs-keyword">long</span> workerId, <span class="hljs-keyword">long</span> datacenterId)</span> </span>{
<span class="hljs-keyword">if</span> (workerId > maxWorkerId || workerId < <span class="hljs-number">0</span>) {
<span class="hljs-keyword">throw</span> <span class="hljs-keyword">new</span> IllegalArgumentException(String.format(<span class="hljs-string">"worker Id can't be greater than %d or less than 0"</span>, maxWorkerId));
}
<span class="hljs-keyword">if</span> (datacenterId > maxDatacenterId || datacenterId < <span class="hljs-number">0</span>) {
<span class="hljs-keyword">throw</span> <span class="hljs-keyword">new</span> IllegalArgumentException(String.format(<span class="hljs-string">"datacenter Id can't be greater than %d or less than 0"</span>, maxDatacenterId));
}
<span class="hljs-keyword">this</span>.workerId = workerId;
<span class="hljs-keyword">this</span>.datacenterId = datacenterId;
}
<span class="hljs-comment">// ==============================Methods==========================================</span>
<span class="hljs-comment">/**
* 获得下一个ID (该方法是线程安全的)
* <span class="hljs-doctag">@return</span> SnowflakeId
*/</span>
<span class="hljs-function"><span class="hljs-keyword">public</span> <span class="hljs-keyword">synchronized</span> <span class="hljs-keyword">long</span> <span class="hljs-title">nextId</span><span class="hljs-params">()</span> </span>{
<span class="hljs-keyword">long</span> timestamp = timeGen();
<span class="hljs-comment">//如果当前时间小于上一次ID生成的时间戳,说明系统时钟回退过这个时候应当抛出异常</span>
<span class="hljs-keyword">if</span> (timestamp < lastTimestamp) {
<span class="hljs-keyword">throw</span> <span class="hljs-keyword">new</span> RuntimeException(
String.format(<span class="hljs-string">"Clock moved backwards. Refusing to generate id for %d milliseconds"</span>, lastTimestamp - timestamp));
}
<span class="hljs-comment">//如果是同一时间生成的,则进行毫秒内序列</span>
<span class="hljs-keyword">if</span> (lastTimestamp == timestamp) {
sequence = (sequence + <span class="hljs-number">1</span>) & sequenceMask;
<span class="hljs-comment">//毫秒内序列溢出</span>
<span class="hljs-keyword">if</span> (sequence == <span class="hljs-number">0</span>) {
<span class="hljs-comment">//阻塞到下一个毫秒,获得新的时间戳</span>
timestamp = tilNextMillis(lastTimestamp);
}
}
<span class="hljs-comment">//时间戳改变,毫秒内序列重置</span>
<span class="hljs-keyword">else</span> {
sequence = <span class="hljs-number">0L</span>;
}
<span class="hljs-comment">//上次生成ID的时间截</span>
lastTimestamp = timestamp;
<span class="hljs-comment">//移位并通过或运算拼到一起组成64位的ID</span>
<span class="hljs-keyword">return</span> ((timestamp - twepoch) << timestampLeftShift) <span class="hljs-comment">//</span>
| (datacenterId << datacenterIdShift) <span class="hljs-comment">//</span>
| (workerId << workerIdShift) <span class="hljs-comment">//</span>
| sequence;
}
<span class="hljs-comment">/**
* 阻塞到下一个毫秒,直到获得新的时间戳
* <span class="hljs-doctag">@param</span> lastTimestamp 上次生成ID的时间截
* <span class="hljs-doctag">@return</span> 当前时间戳
*/</span>
<span class="hljs-function"><span class="hljs-keyword">protected</span> <span class="hljs-keyword">long</span> <span class="hljs-title">tilNextMillis</span><span class="hljs-params">(<span class="hljs-keyword">long</span> lastTimestamp)</span> </span>{
<span class="hljs-keyword">long</span> timestamp = timeGen();
<span class="hljs-keyword">while</span> (timestamp <= lastTimestamp) {
timestamp = timeGen();
}
<span class="hljs-keyword">return</span> timestamp;
}
<span class="hljs-comment">/**
* 返回以毫秒为单位的当前时间
* <span class="hljs-doctag">@return</span> 当前时间(毫秒)
*/</span>
<span class="hljs-function"><span class="hljs-keyword">protected</span> <span class="hljs-keyword">long</span> <span class="hljs-title">timeGen</span><span class="hljs-params">()</span> </span>{
<span class="hljs-keyword">return</span> System.currentTimeMillis();
}
<span class="hljs-comment">//==============================Test=============================================</span>
<span class="hljs-comment">/** 测试 */</span>
<span class="hljs-function"><span class="hljs-keyword">public</span> <span class="hljs-keyword">static</span> <span class="hljs-keyword">void</span> <span class="hljs-title">main</span><span class="hljs-params">(String[] args)</span> </span>{
SnowflakeIdWorker idWorker = <span class="hljs-keyword">new</span> SnowflakeIdWorker(<span class="hljs-number">0</span>, <span class="hljs-number">0</span>);
<span class="hljs-keyword">for</span> (<span class="hljs-keyword">int</span> i = <span class="hljs-number">0</span>; i < <span class="hljs-number">1000</span>; i++) {
<span class="hljs-keyword">long</span> id = idWorker.nextId();
System.out.println(Long.toBinaryString(id));
System.out.println(id);
}
}
}

</div>
</div>
<div class="ui hidden divider"></div>
<p style="text-align:center;">
© 著作权归作者所有
</p>
</div>
分布式ID解决方案的更多相关文章
- spring cloud微服务快速教程之(十二) 分布式ID解决方案(mybatis-plus篇)
0-前言 分布式系统中,分布式ID是个必须解决的问题点: 雪花算法是个好方式,不过不能直接使用,因为如果直接使用的话,需要配置每个实例workerId和datacenterId,在微服务中,实例一般动 ...
- 最常用的分布式ID解决方案,你知道几个
一.分布式ID概念 说起ID,特性就是唯一,在人的世界里,ID就是身份证,是每个人的唯一的身份标识.在复杂的分布式系统中,往往也需要对大量的数据和消息进行唯一标识.举个例子,数据库的ID字段在单体的情 ...
- 分布式 ID 解决方案之美团 Leaf
分布式 ID 在庞大复杂的分布式系统中,通常需要对海量数据进行唯一标识,随着数据日渐增长,对数据分库分表以后需要有一个唯一 ID 来标识一条数据,而数据库的自增 ID 显然不能满足需求,此时就需要有一 ...
- 分布式ID生成策略之ZK
import org.apache.curator.framework.CuratorFramework; import org.apache.curator.framework.CuratorFra ...
- 就这?分布式 ID 发号器实战
分布式 ID 需要满足的条件: 全局唯一:这是最基本的要求,必须保证 ID 是全局唯一的. 高性能:低延时,不能因为一个小小的 ID 生成,影响整个业务响应速度. 高可用:无限接近于100%的可用性. ...
- 分布式ID生成器的解决方案总结
在互联网的业务系统中,涉及到各种各样的ID,如在支付系统中就会有支付ID.退款ID等.那一般生成ID都有哪些解决方案呢?特别是在复杂的分布式系统业务场景中,我们应该采用哪种适合自己的解决方案是十分重要 ...
- 分布式ID生成器解决方案
一.分布式系统带来ID生成挑战 在复杂的系统中,往往需要对大量的数据如订单,账户进行标识,以一个有意义的有序的序列号来作为全局唯一的ID; 而分布式系统中我们对ID生成器要求又有哪些呢? 全局唯一性: ...
- Java分布式ID生成解决方案
分布式ID生成器 我们采用的是开源的twitter( 非官方中文惯称:推特.是国外的一个网站,是一个社交网络及微博客服务) 的snowflake算法(推特雪花算法). 封装为工具类,源码如下: p ...
- CRL快速开发框架系列教程六(分布式缓存解决方案)
本系列目录 CRL快速开发框架系列教程一(Code First数据表不需再关心) CRL快速开发框架系列教程二(基于Lambda表达式查询) CRL快速开发框架系列教程三(更新数据) CRL快速开发框 ...
随机推荐
- ZZUACM 2015 暑假集训 round 01
A. Encoding Problem Description Given a string containing only 'A' - 'Z', we could encode it using t ...
- AAC编解码
AAC编码可以使用faac /** 初始化 @param sampleRate 音频采样率 @param channels 通道数 @param bitSize 音频采样精度 16 */ - (voi ...
- 在linux环境下增加别名
编辑.cshrc文件:gvim ~/.cshrc 增加要添加的别名,例如:alias la 'ls -a' qw保存退出 source ~/.cshrc即可生效
- HDU 6217 BBP Formula (数学)
题目链接: HDU 7217 题意: 题目给你可以计算 \(π\) 的公式: \(\pi = \sum_{k=0}^{\infty}[\frac{1}{16^k}(\frac{4}{8k+1})-(\ ...
- 洛谷——P2241 统计方形(数据加强版)
https://www.luogu.org/problem/show?pid=2241 题目背景 1997年普及组第一题 题目描述 有一个n*m方格的棋盘,求其方格包含多少正方形.长方形 输入输出格式 ...
- UIDeviceOrientationDidChangeNotification和UIApplicationDidChangeStatusBarFrameNotification
这几天做App的时候,需要添加旋转屏通知以便调整UI布局 刚开始我使用的是UIDeviceOrientationDidChangeNotification, 一直有一些问题就是,如果使用这个通知,当i ...
- log4j 2.x 版本的 properties 配置
#用于设置log4j2自身内部的信息输出,可以不设置,当设置成trace时,会看到log4j2内部各种详细输出status = debugdest = errname = PropertiesConf ...
- jquery-validate使用.md
html <form id="s_form" class="form-horizontal" action="http://www.baidu. ...
- UVA 11388 - GCD LCM 水~
看题传送门 题目大意: 输入两个数G,L找出两个正整数a 和b,使得二者的最大公约数为G,最小公倍数为L,如果有多解,输出a<=b且a最小的解,无解则输出-1 思路: 方法一: 显然有G< ...
- LA 4329 - Ping pong 树状数组(Fenwick树)
先放看题传送门 哭瞎了,交上去一直 Runtime error .以为那里错了. 狂改!!!!! 然后还是一直... 继续狂改!!!!... 一直.... 最后发现数组开小了.......... 果断 ...