爬虫系列(十) 用requests和xpath爬取豆瓣电影
这篇文章我们将使用 requests 和 xpath 爬取豆瓣电影 Top250,下面先贴上最终的效果图:
1、网页分析
(1)分析 URL 规律
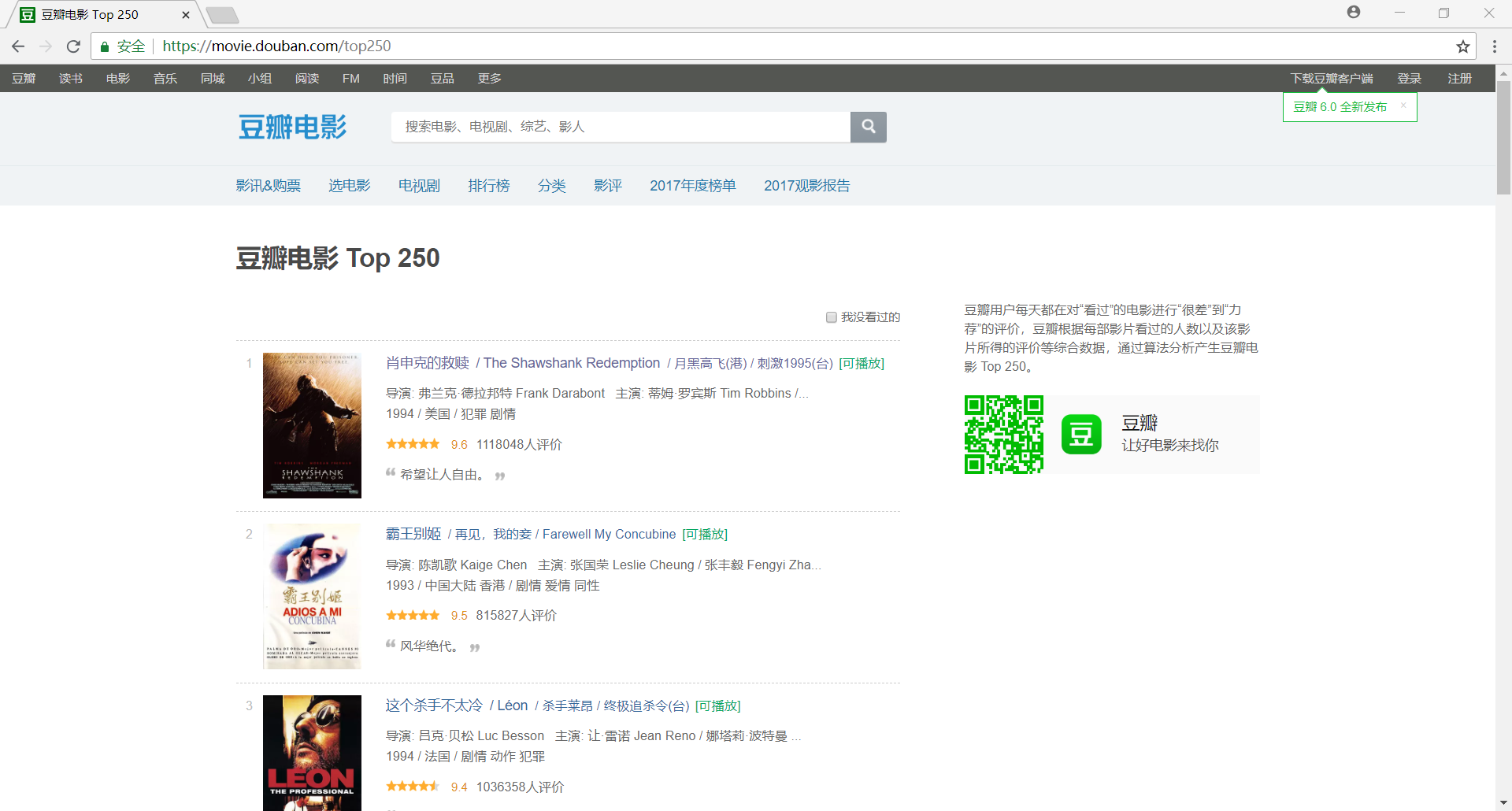
我们首先使用 Chrome 浏览器打开 豆瓣电影 Top250,很容易可以判断出网站是一个静态网页
然后我们分析网站的 URL 规律,以便于通过构造 URL 获取网站中所有网页的内容
首页:https://movie.douban.com/top250
第二页:https://movie.douban.com/top250?start=25&filter=
第三页:https://movie.douban.com/top250?start=50&filter=
...
不难发现,URL 可以泛化为 https://movie.douban.com/top250?start={page}&filter=,其中,page 代表页数
最后我们还需要验证一下首页的 URL 是否也满足规律,经过验证,很容易可以发现首页的 URL 也满足上面的规律
核心代码如下:
import requests
# 获取网页源代码
def get_page(url):
# 构造请求头部
headers = {
'USER-AGENT':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'
}
# 发送请求,获得响应
response = requests.get(url=url,headers=headers)
# 获得网页源代码
html = response.text
# 返回网页源代码
return html
(2)分析内容规律
接下来我们开始分析每一个网页的内容,并从中提取出需要的数据
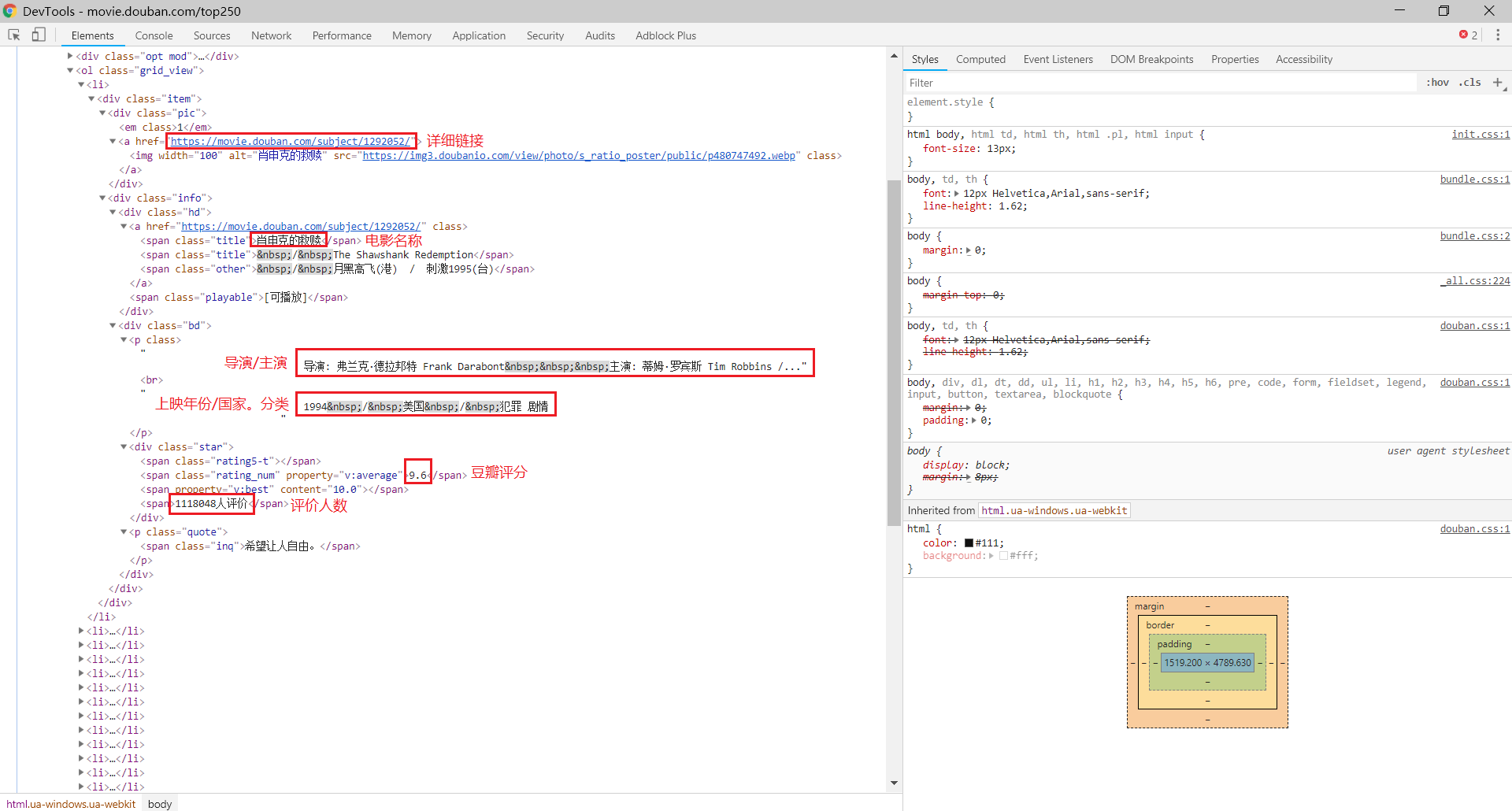
使用快捷键 Ctrl+Shift+I 打开开发者工具,选中 Elements 选项栏分析网页的源代码
需要提取的数据包括(可以使用 xpath 进行匹配):
- 详细链接:
html.xpath('//div[@class="hd"]/a/@href') - 电影名称:
html.xpath('//div[@class="hd"]/a/span[1]/text()') - 导演/主演、上映年份/国家/分类:
html.xpath('//div[@class="bd"]/p[1]//text()') - 豆瓣评分:
html.xpath('//div[@class="bd"]/div/span[2]/text()') - 评价人数:
html.xpath('//div[@class="bd"]/div/span[4]/text()')
核心代码如下:
from lxml import etree
# 解析网页源代码
def parse_page(html):
# 构造 _Element 对象
html_elem = etree.HTML(html)
# 详细链接
links = html_elem.xpath('//div[@class="hd"]/a/@href')
# 电影名称
titles = html_elem.xpath('//div[@class="hd"]/a/span[1]/text()')
# 电影信息(导演/主演、上映年份/国家/分类)
infos = html_elem.xpath('//div[@class="bd"]/p[1]//text()')
roles = [j for i,j in enumerate(infos) if i % 2 == 0]
descritions = [j for i,j in enumerate(infos) if i % 2 != 0]
# 豆瓣评分
stars = html_elem.xpath('//div[@class="bd"]/div/span[2]/text()')
# 评论人数
comments = html_elem.xpath('//div[@class="bd"]/div/span[4]/text()')
# 获得结果
data = zip(links,titles,roles,descritions,stars,comments)
# 返回结果
return data
(3)保存数据
下面将数据分别保存为 txt 文件、json 文件和 csv 文件
import json
import csv
# 打开文件
def openfile(fm):
fd = None
if fm == 'txt':
fd = open('douban.txt','w',encoding='utf-8')
elif fm == 'json':
fd = open('douban.json','w',encoding='utf-8')
elif fm == 'csv':
fd = open('douban.csv','w',encoding='utf-8',newline='')
return fd
# 将数据保存到文件
def save2file(fm,fd,data):
if fm == 'txt':
for item in data:
fd.write('----------------------------------------\n')
fd.write('link:' + str(item[0]) + '\n')
fd.write('title:' + str(item[1]) + '\n')
fd.write('role:' + str(item[2]) + '\n')
fd.write('descrition:' + str(item[3]) + '\n')
fd.write('star:' + str(item[4]) + '\n')
fd.write('comment:' + str(item[5]) + '\n')
if fm == 'json':
temp = ('link','title','role','descrition','star','comment')
for item in data:
json.dump(dict(zip(temp,item)),fd,ensure_ascii=False)
if fm == 'csv':
writer = csv.writer(fd)
for item in data:
writer.writerow(item)
2、编码实现
下面是完整代码,也是几十行可以写完
import requests
from lxml import etree
import json
import csv
import time
import random
# 获取网页源代码
def get_page(url):
headers = {
'USER-AGENT':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36'
}
response = requests.get(url=url,headers=headers)
html = response.text
return html
# 解析网页源代码
def parse_page(html):
html_elem = etree.HTML(html)
links = html_elem.xpath('//div[@class="hd"]/a/@href')
titles = html_elem.xpath('//div[@class="hd"]/a/span[1]/text()')
infos = html_elem.xpath('//div[@class="bd"]/p[1]//text()')
roles = [j.strip() for i,j in enumerate(infos) if i % 2 == 0]
descritions = [j.strip() for i,j in enumerate(infos) if i % 2 != 0]
stars = html_elem.xpath('//div[@class="bd"]/div/span[2]/text()')
comments = html_elem.xpath('//div[@class="bd"]/div/span[4]/text()')
data = zip(links,titles,roles,descritions,stars,comments)
return data
# 打开文件
def openfile(fm):
fd = None
if fm == 'txt':
fd = open('douban.txt','w',encoding='utf-8')
elif fm == 'json':
fd = open('douban.json','w',encoding='utf-8')
elif fm == 'csv':
fd = open('douban.csv','w',encoding='utf-8',newline='')
return fd
# 将数据保存到文件
def save2file(fm,fd,data):
if fm == 'txt':
for item in data:
fd.write('----------------------------------------\n')
fd.write('link:' + str(item[0]) + '\n')
fd.write('title:' + str(item[1]) + '\n')
fd.write('role:' + str(item[2]) + '\n')
fd.write('descrition:' + str(item[3]) + '\n')
fd.write('star:' + str(item[4]) + '\n')
fd.write('comment:' + str(item[5]) + '\n')
if fm == 'json':
temp = ('link','title','role','descrition','star','comment')
for item in data:
json.dump(dict(zip(temp,item)),fd,ensure_ascii=False)
if fm == 'csv':
writer = csv.writer(fd)
for item in data:
writer.writerow(item)
# 开始爬取网页
def crawl():
url = 'https://movie.douban.com/top250?start={page}&filter='
fm = input('请输入文件保存格式(txt、json、csv):')
while fm!='txt' and fm!='json' and fm!='csv':
fm = input('输入错误,请重新输入文件保存格式(txt、json、csv):')
fd = openfile(fm)
print('开始爬取')
for page in range(0,250,25):
print('正在爬取第 ' + str(page+1) + ' 页至第 ' + str(page+25) + ' 页......')
html = get_page(url.format(page=str(page)))
data = parse_page(html)
save2file(fm,fd,data)
time.sleep(random.random())
fd.close()
print('结束爬取')
if __name__ == '__main__':
crawl()
【爬虫系列相关文章】
爬虫系列(十) 用requests和xpath爬取豆瓣电影的更多相关文章
- 爬虫系列(十一) 用requests和xpath爬取豆瓣电影评论
这篇文章,我们继续利用 requests 和 xpath 爬取豆瓣电影的短评,下面还是先贴上效果图: 1.网页分析 (1)翻页 我们还是使用 Chrome 浏览器打开豆瓣电影中某一部电影的评论进行分析 ...
- requests+lxml+xpath爬取豆瓣电影
(1)lxml解析html from lxml import etree #创建一个html对象 html=stree.HTML(text) result=etree.tostring(html,en ...
- 爬虫系列1:Requests+Xpath 爬取豆瓣电影TOP
爬虫1:Requests+Xpath 爬取豆瓣电影TOP [抓取]:参考前文 爬虫系列1:https://www.cnblogs.com/yizhiamumu/p/9451093.html [分页]: ...
- Python爬虫:现学现用xpath爬取豆瓣音乐
爬虫的抓取方式有好几种,正则表达式,Lxml(xpath)与BeautifulSoup,我在网上查了一下资料,了解到三者之间的使用难度与性能 三种爬虫方式的对比. 这样一比较我我选择了Lxml(xpa ...
- requests结合xpath爬取豆瓣最新上映电影
# -*- coding: utf-8 -*- """ 豆瓣最新上映电影爬取 # ul = etree.tostring(ul, encoding="utf-8 ...
- python3+requests+BeautifulSoup+mysql爬取豆瓣电影top250
基础页面:https://movie.douban.com/top250 代码: from time import sleep from requests import get from bs4 im ...
- 爬虫系列(六) 用urllib和re爬取百度贴吧
这篇文章我们将使用 urllib 和 re 模块爬取百度贴吧,并使用三种文件格式存储数据,下面先贴上最终的效果图 1.网页分析 (1)准备工作 首先我们使用 Chrome 浏览器打开 百度贴吧,在输入 ...
- 一起学爬虫——通过爬取豆瓣电影top250学习requests库的使用
学习一门技术最快的方式是做项目,在做项目的过程中对相关的技术查漏补缺. 本文通过爬取豆瓣top250电影学习python requests的使用. 1.准备工作 在pycharm中安装request库 ...
- Python爬虫爬取豆瓣电影之数据提取值xpath和lxml模块
工具:Python 3.6.5.PyCharm开发工具.Windows 10 操作系统.谷歌浏览器 目的:爬取豆瓣电影排行榜中电影的title.链接地址.图片.评价人数.评分等 网址:https:// ...
随机推荐
- 向Java枚举类型中加入新方法
除了不能继承enum之外,可将其看做一个常规类.甚至能够有main方法. 注意:必须先定义enum实例.实例的最后有一个分号. 以下是一个样例:返回对实例自身的描写叙述,而非默认的toString返回 ...
- HibernateBaseDAO
HibernateBaseDAO接口 package com.iotek.homework.dao; import java.io.Serializable; import java.util.Lis ...
- 1366 xth 的第 12 枚硬币
1366 xth 的第 12 枚硬币 时间限制: 1 s 空间限制: 128000 KB 题目等级 : 钻石 Diamond 题解 题目描述 Description 传说 xth 曾 ...
- linux sed 命令,sed -i
-i 参数 :直接在原文件上进行操作整条语句意思是将b.c文件里第一个匹配printa替换为printb
- 检测含有挖矿脚本的WiFi热点——果然是天下没有免费的午餐
见:http://www.freebuf.com/articles/web/161010.html 本质上是在开放wifi热点,自己搭建挖掘的网页,让接入的人访问该网页. 802.11无线协议本身特点 ...
- hdoj--1518--Square(dfs)
Square Time Limit: 10000/5000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others) Total Su ...
- B1045 糖果传递 数学
糖果传递,一开始就想到了n^2的模拟贪心算法,但是一看,数据范围太大,好像只有O(N)能过...没啥方法,只好看题解,之后发现,woc,还有这种操作? 这个题直接可以用数学证明... 证明如下: 首先 ...
- 利用存储过程插入50W+数据
转自:https://www.aliyun.com/jiaocheng/1396184.html 首先,建立部门表和员工表: 部门表: create table dept( id int un ...
- Appium - 命令行参数
1.cmd端口输入,appium -help参考帮助信息 2.Appium - 命令行参数 参数 默认 描述 举个例子 --shell 空值 进入REPL模式 --ipa 空值 (仅限IOS)ab ...
- 工作2-5年,身为iOS开发的我应该怎么选择进修方向?
前言: 跳槽,面试,进阶,加薪:这些字眼,相信每位程序员都不陌生! 但是方向的选择,却不知如何抉择!其实最好的方向,已经在各个企业面试需求中完美的体现出来了: 本文展示了2份面试需求,以及方向的总结, ...