Python内置数据结构之列表list
1. Python的数据类型简介
数据结构是以某种方式(如通过编号)组合起来的数据元素(如数、字符乃至其他数据结构)集合。在Python中,最基本的数据结构为序列(sequence)。 Python内置了多种序列,如列表,元组,字符串(由字符组成的序列)。
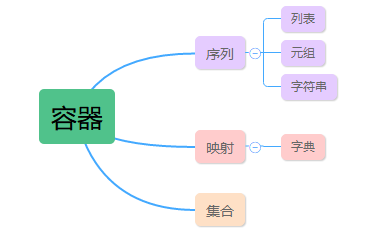
Python支持一种数据结构的基本概念,名为容器(container)。容器基本上就是可包含其他对象的对象。两种主要的容器是序列(列表和元组)和映射(字典)。
在序列中,每个元素都有编号。在映射中,每个元素都有名称(也叫键)。有一种既不是序列也不是映射的容器,它就是集合(set)。

列表和元组的主要不同在于,列表是可以修改的,而元组不可以。
这意味着列表适用于需要中途添加元素的情形,而元组适用于出于某种考虑需要禁止修改序列的情形。禁止修改序列通常出于技术方面的考虑,与Python的内部工作原理相关,这也是有些内置函数返回元组的原因所在。
在我们编写程序时,几乎在所有情况下都可使用列表来代替元组。据我目前所知,当元组用作字典键时,不能用列表来代替元组(原因是因为字典键不允许修改)
元素都有编号,即其位置或索引,其中第一个元素的索引为0,第二个元素的索引为1,依此类推。在有些编程语言中,从1开始给序列中的元素编号,但从0开始指出相对于序列开头的偏移量。这显得更自然,同时可回绕到序列末尾,用负索引表示序列末尾元素的位置。
2. Python序列之列表:Python主力军
索引、切片、相加、相乘和成员资格检查适用于所有的序列。另外, Python还提供了一些内置函数,可用于确定序列的长度以及找出序列中最大和最小的元素。
列表是可变的,即可修改其内容。另外,列表有很多特有的方法。
通过列表可以对数据实现最方便的存储、修改等操作。
列表用中括号括起。
2.1 函数list
可将字符串转化为列表,可将任何序列(不仅仅是字符串)作为list的参数。函数list实际上是一个类,也是一个工厂函数,目前,这种差别不重要。
- >>> list('function')
- ['f', 'u', 'n', 'c', 't', 'i', 'o', 'n']
提示:要将字符列表(如前述代码中的字符列表)转换为字符串,可使用下面的表达式(字符串操作方法):
- >>> test = ['f', 'u', 'n', 'c', 't', 'i', 'o', 'n']
- >>> print(''.join(test))
- function
2.2 基本列表操作
2.2.1 索引(indexing)
序列中所有元素都有编号——从0开始递增。-1是最后一个元素的位置。不同于其他语言,Python没有专门用于表示字符串的类型,因此一个字符就是只包含一个元素的字符串。
- # 索引操作实例
- # Print out a date, given year, month, and day as numbers
- months = ['January', 'February', 'March', 'April', 'May', 'June', 'July', 'August', 'September', 'October', 'November', 'December']
- # A list with one ending for each number from 1 to 31
- endings = ['st', 'nd', 'rd'] + 17 * ['th'] \
- + ['st', 'nd', 'rd'] + 7 * ['th'] \
- + ['st']
- year = input('Year: ')
- month = input('Month (1-12): ')
- day = input('Day (1-31): ')
- month_number = int(month)
- day_number = int(day)
- # Remember to subtract 1 from month and day to get a correct index(The index starts from 0)
- month_name = months[month_number-1]
- ordinal = day + endings[day_number-1]
- print(month_name + ' ' + ordinal + ', ' + year)
- 执行结果:
- Year: 2018
- Month (1-12): 3
- Day (1-31): 3
- March 3rd, 2018
2.2.2 切片
第一个数字表示切片开始位置(默认0)
第二个数字表示切片截止(但不包括)位置(默认位列表长度)
第三个数字表示切片的步长(默认1)
- number = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
- print(number[0:10:1]) # 0,1全部可省略
- print(number[:]) # print(number[:]) = print(number[:10]) = print(number[:100])
- print(number[::2])
- print(number[1::2])
- print(number[2::3]) # 切片,从第二个元素开始,第一个元素的索引(下标)为0,那么3的索引为2,每隔3位取一个元素
- 执行结果:
- [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
- [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
- [1, 3, 5, 7, 9]
- [2, 4, 6, 8, 10]
- [3, 6, 9]
- names = ["DJ", "ZhangYang", "YanYun", "WangYa", "LiLei"]
- print(names)
- print(names[0], names[2])
- print(names[1:3]) # 切片,顾头不顾尾!取位置为1~2的字符串
- print(names[-1]) # 切片,从左往右数,-4,-3,-2,-1 取最后一个元素
- print(names[-2:]) # 切片,取最后两个值
- print(names[-3:-1]) # 切片,从左往右数,顾头不顾尾!取倒数第三个和倒数第二个元素
- print(names[0:3]) # 切片,0可以省略,取前三个元素
- 执行结果:
- ['DJ', 'ZhangYang', 'YanYun', 'WangYa', 'LiLei']
- DJ YanYun
- ['ZhangYang', 'YanYun']
- LiLei
- ['WangYa', 'LiLei']
- ['YanYun', 'WangYa']
- ['DJ', 'ZhangYang', 'YanYun']
2.2.3 追加
- names = ["DJ", "ZhangYang", "YanYun", "WangYa", "LiLei"]
- print(names)
- names.append("LiLei")
- print(names)
- 执行结果:
- ['DJ', 'ZhangYang', 'YanYun', 'WangYa', 'LiLei']
- ['DJ', 'ZhangYang', 'YanYun', 'WangYa', 'LiLei', 'LiLei']
2.2.4 插入
- names = ["DJ", "ZhangYang", "YanYun", "WangYa", "LiLei"]
- names.insert(1, "FFF") # 插入,1——>下标
- names.insert(3, "ppp") # 插入,3——>下标
- print(names)
- 执行结果:
- ['DJ', 'FFF', 'ZhangYang', 'ppp', 'YanYun', 'WangYa', 'LiLei']
2.2.5 修改(替换)
- names = ["DJ", "ZhangYang", "YanYun", "WangYa", "LiLei"]
- names[1] = "XXXXX" # 替换
- print(names)
- 执行结果:
- ['DJ', 'XXXXX', 'YanYun', 'WangYa', 'LiLei']
2.2.6 删除
- # delete
- names = ["DJ", "ZhangYang", "YanYun", "WangYa", "LiLei"]
- # names.remove("YanYun")
- # del names[3] = names.pop(3)
- names.pop() # 如果不输入下标,默认删除最后一个
- print(names)
- 执行:
- ['DJ', 'ZhangYang', 'YanYun', 'WangYa']
2.2.7 统计
- names = ["DJ", "ZhangYang", "YanYun", "WangYa", "LiLei"]
- print(names.count("ZhangYang"))
- 执行:
- 1
2.2.8 扩展(合并)
- names = ["DJ", "ZhangYang", "YanYun", "WangYa", "LiLei"]
- names2 = ['', '', 'FFF', 'DJ']
- # 合并,如果不删除names2,仍然存在
- names.extend(names2)
- del names2
- print(names)
- 执行:
- ['DJ', 'ZhangYang', 'YanYun', 'WangYa', 'LiLei', '', '', 'FFF', 'DJ']
2.2.9 清空
- >>> names = ["DJ", "ZhangYang", "YanYun", "WangYa", "LiLei"]
- >>> print(names.clear())
- None
2.2.10 排序(特殊符号,数字,大写,小写)
- names = ["DJ", "ZhangYang", "zhangYang", "YanYun", "WangYa", "LiLei"]
- names.sort()
- print(names)
- names2 = ['LiLei', '#!WangYa', '4DDD', 'aFFF', 'ZhangYang', 'FFF', 'DJ']
- names2.sort()
- print(names2)
- 执行:
- ['DJ', 'LiLei', 'WangYa', 'YanYun', 'ZhangYang', 'zhangYang']
- ['#!WangYa', '4DDD', 'DJ', 'FFF', 'LiLei', 'ZhangYang', 'aFFF']
2.2.11 反转排序
- names = ["DJ", "ZhangYang", "zhangYang", "YanYun", "WangYa", "LiLei"]
- names.reverse()
- print(names)
- names2 = ['LiLei', '#!WangYa', '4DDD', 'aFFF', 'ZhangYang', 'FFF', 'DJ']
- names2.reverse()
- print(names2)
- 执行:
- ['LiLei', 'WangYa', 'YanYun', 'zhangYang', 'ZhangYang', 'DJ']
- ['DJ', 'FFF', 'ZhangYang', 'aFFF', '4DDD', '#!WangYa', 'LiLei']
2.2.12 浅copy
- import copy
- person = ['name', ['saving', 1000]]
- p1 = person.copy() # 浅copy,只复制上一层的子列表,子列表是一个独立的内存指针,是一个内存地址,复制的是内存地址
- p2 = person[:]
- p3 = list(person)
- p1[0] = 'alex'
- p2[0] = 'A_Wife'
- p1[1][1] = 500
- print(p1)
- print(p2)
- print(p3)
- 执行:
- ['alex', ['saving', 500]]
- ['A_Wife', ['saving', 500]]
- ['name', ['saving', 500]]
2.2.13 深copy
- import copy
- names = ["DJ", "ZhangYang", "YanYun",['alex', 'Jack'], "WangYa", "LiLei"]
- # 浅copy,只复制上一层的子列表,子列表是一个独立的内存指针,是一个内存地址,复制的是内存地址
- # names2 = names.copy()
- # 深copy,占两份独立的地址空间
- names2 = copy.deepcopy(names)
- print(names)
- print(names2)
- names[0] = "帝姬"
- names[3][0] = "ALEX" # 由于指向同一块地址空间,names[3][0] = names2[3][0]
- print(names)
- print(names2)
- 执行:
- ['DJ', 'ZhangYang', 'YanYun', ['alex', 'Jack'], 'WangYa', 'LiLei']
- ['DJ', 'ZhangYang', 'YanYun', ['alex', 'Jack'], 'WangYa', 'LiLei']
- ['帝姬', 'ZhangYang', 'YanYun', ['ALEX', 'Jack'], 'WangYa', 'LiLei']
- ['DJ', 'ZhangYang', 'YanYun', ['alex', 'Jack'], 'WangYa', 'LiLei']
3. Python序列之元组:不可修改的序列
元组其实跟列表差不多,也是存一组数,只不是它一旦创建,便不能像列表式的增删改,只能查,切片,所以元组又叫只读列表。
元组用圆括号括起(这是通常采用的做法)。
3.1 函数tuple
函数tuple的工作原理与list类似:它将一个序列作为参数,并将其转换为元组。如果参数已经是元组,就原封不动地返回它。它同样是工厂函数。
- >>> tuple([1, 2, 3])
- (1, 2, 3)
- >>> tuple('abc')
- ('a', 'b', 'c')
- >>> tuple((1, 2, 3))
- (1, 2, 3)
- >>>
3.2 基本元组操作(方法)
2个方法:一个是count(计数),一个是index(索引),当然,它同样可以切片
- names = ('alex', 'jack', 'DJ', 'alex', 'Alex')
- print(names.count('alex'))
- print(names[names.index('DJ')])
- print(names.index('DJ'))
- 执行:
- 2
- DJ
- 2
它们用作映射中的键(以及集合的成员),而列表不行。
有些内置函数和方法返回元组,这意味着必须跟它们打交道。只要不尝试修改元组,与
元组“打交道”通常意味着像处理列表一样处理它们(需要使用元组没有的index和count等方法时例外)。
一般而言,使用列表足以满足对序列的需求。
3. 购物车小程序
- product_list = [
- ('IPhone', 6000),
- ('Mac Pro', 12000),
- ('Starbucks Latte', 50),
- ('Bicycle', 800),
- ("Watches", 12000)
- ]
- shopping_list = []
- salary = input("Input your salary:")
- if salary.isdigit():
- # 判断用户输入的工资是否为数字类型
- salary = int(salary)
- while True:
- for index, item in enumerate(product_list):
- print(index,item)
- # 取出列表元素对应下标,并打印下标和数据
- user_choice = input("Please choose goods:")
- if user_choice.isdigit():
- user_choice = int(user_choice)
- # 判断输入的元素下标是否是数字类型(判断用户的输入是否为数字类型)
- if not user_choice >= len(product_list) and user_choice >= 0:
- p_item = product_list[user_choice]
- # 通过下标把商品取出来
- if p_item[1] <= salary: # 买得起
- shopping_list.append(p_item)
- salary -= p_item[1]
- print('Added \033[32m %s \033[m into shopping cart,'
- 'Your curent balance is \033[31m %s \033[m' % (p_item, salary))
- else:
- print("\033[41m 你的余额只剩[%s]啦!\033[m" % salary)
- else:
- print("\033[42m product code [%s] is not exits!\033[m" % user_choice)
- elif user_choice == 'q':
- print("------shopping list------")
- for p in shopping_list:
- print(p)
- print("\033[45m Your current balance:\033[0m", salary)
- print("------shopping list------")
- exit()
- else:
- print("invalid option!")
Python内置数据结构之列表list的更多相关文章
- Python内置数据结构--列表
本节内容: 列表 元组 字符串 集合 字典 本节先介绍列表. 一.列表 一种容器类型.列表可以包含任何种类的对象,比如说数字.子串.嵌套其他列表.嵌套元组. 任意对象的有序集合,通过索引访问其中的元素 ...
- Python基础语法-内置数据结构之列表
列表的一些特点: 列表是最常用的线性数据结构 list是一系列元素的有序组合 list是可变的 列表的操作, 增:append.extend.insert 删:clear.pop.remove 改:r ...
- Python内置数据结构之字符串str
1. 数据结构回顾 所有标准序列操作(索引.切片.乘法.成员资格检查.长度.最小值和最大值)都适用于字符串,但是字符串是不可变序列,因此所有的元素赋值和切片赋值都是非法的. >>> ...
- Python内置数据结构之元组tuple
1. Python序列之元组:不可修改的序列 元组其实跟列表差不多,也是存一组数,只不是它一旦创建,便不能像列表式的增删改,只能查,切片,所以元组又叫只读列表. 元组用圆括号括起(这是通常采用的做法) ...
- Python内置数据结构之字典dict
1. 字典 字典是Python中唯一的内置映射类型,其中的值不按顺序排列,而是存储在键下.键可能是数(整数索引).字符串或元组.字典(日常生活中的字典和Python字典)旨在让你能够轻松地找到特定的单 ...
- python内置数据结构方法的时间复杂度
转载自:http://www.orangecube.net/python-time-complexity 本文翻译自Python Wiki 本文基于GPL v2协议,转载请保留此协议. 本页面涵盖了P ...
- [PY3]——内置数据结构(1)——列表及其常用操作
列表及其常用操作_xmind图 about列表 列表是一个序列,用于顺序存储数据 列表分为两种:ArrayList(用数组实现).LinkedList(用链表实现) 定义与初始化 #l ...
- python 内置数据结构 切片
切片 通过索引区间访问线性结构的一段数据 sequence[start:stop] 表示返回[start,stop]区间的子序列 支持负索引 start为0,可以省略 stop为末尾,可以省略 超过上 ...
- python 内置数据结构 字符串
字符串 一个个字符组成的有序的序列,是字符的集合 使用单引号,双引号,三引号引住的字符序列 字符串是不可变对象 Python3起,字符串就是Unicode类型 字符串定义 初始化 s1 = 'stri ...
随机推荐
- c#初学12-12-为什么mian函数必须是static的
c#初学12-12-为什么mian函数必须是static的 c#程序刚开始启动的时候都会有唯一一个入口函数main()函数, 而非静态成员又称实例成员,必须作用于实例.在程序刚开始运行的时候,未建立任 ...
- Aspx小记
关闭按钮 protected void Close_Click(object sender, EventArgs e) { //Page.RegisterStartupScript("clo ...
- 【摘录】JAVA内存管理-有关垃圾收集的关键参数
第八章 有关垃圾收集的关键参数 一些命令行参数可以用来选择垃圾收集器,指定堆或代的大小,修改垃圾收集行为,获取垃圾收集统计数据.本章给出一些最常用的参数.有关各种各样参数更多完整的列表和详细信息可以参 ...
- ZBrush破解版真的好用么?
安装ZBrush®的时候是不是经常出现各种奇葩问题,使用ZBrush时候是不是经常出现停止工作状况,究其原因,原来都是破解搞的鬼.ZBrush破解版你还敢用么? 随着国人对版权的重视,越来越多的制作商 ...
- 执行python manage.py makemigrations时报错TypeError: __init__() missing 1 required positional argument: 'on_delete'
在执行python manage.py makemigrations时报错: TypeError: __init__() missing 1 required positional argument: ...
- oralce存储过程实现不同用户之间的表数据复制
create or replace procedure prc_test123 is temp_columns ); sqltemp ); cursor cur is select table_nam ...
- 如何打印枚举类型:%d
#include <stdio.h> typedef enum SessionState { SESSION_OPENING, /* Session scope is being crea ...
- UVA401-Palindromes(紫书例题3.3)
A regular palindrome is a string of numbers or letters that is the same forward as backward. For exa ...
- 自动合法打印VitalSource Bookshelf中的电子书
最近有一本2千多页的在VitalSource中的电子书想转为PDF随时阅读,没料网上找了一圈没有找到合适的.相对好一些的只有一个用Python写的模拟手动打印.于是想到了用AutoHotkey写一个自 ...
- 【codeforces 810C】Do you want a date?
[题目链接]:http://codeforces.com/contest/810/problem/C [题意] 给你一个集合,它包含a[1],a[2]..a[n]这n个整数 让你求出这个集合的所有子集 ...