Hadoop分布式文件系统架构部署
前言* Hadoop是Apache开源组织的一个分布式计算开源框架,在很多大型网站上都已经得到了应用,如亚马逊、Facebook和Yahoo等等。对于我来说,最近的一个使用点就是服务集成平台的日志分析。服务集成平台的日志量将会很大,而这也正好符合了分布式计算的适用场景(日志分析和索引建立就是两大应用场景)。
今天我们来实际搭建一下Hadoop 2.2.0版,实战环境为目前主流服务器操作系统CentOS 5.8系统。
一、实战环境
|
1
2
3
4
5
6
|
系统版本:CentOS 5.8 x86_64JAVA版本:JDK-1.7.0_25Hadoop版本:hadoop-2.2.0192.168.149.128 namenode (充当namenode、secondary namenode和ResourceManager角色)192.168.149.129 datanode1 (充当datanode、nodemanager角色)192.168.149.130 datanode2 (充当datanode、nodemanager角色) |
二、系统准备
1、Hadoop可以从Apache官方网站直接下载最新版本Hadoop2.2。官方目前是提供了linux32位系统可执行文件,所以如果需要在64位系统上部署则需要单独下载src 源码自行编译。(如果是真实线上环境,请下载64位hadoop版本,这样可以避免很多问题,这里我实验采用的是32位版本)
|
1
2
3
4
|
Hadoop下载地址http://apache.claz.org/hadoop/common/hadoop-2.2.0/Java 下载下载http://www.oracle.com/technetwork/java/javase/downloads/index.html |
2、我们这里采用三台CnetOS服务器来搭建Hadoop集群,分别的角色如上已经注明。
第一步:我们需要在三台服务器的/etc/hosts里面设置对应的主机名如下(真实环境可以使用内网DNS解析)
[root@node1 hadoop]# cat /etc/hosts
|
1
2
3
4
5
6
|
# Do not remove the following line, or various programs# that require network functionality will fail.127.0.0.1 localhost.localdomain localhost192.168.149.128 node1192.168.149.129 node2192.168.149.130 node3 |
(注* 我们需要在namenode、datanode三台服务器上都配置hosts解析)
第二步:从namenode上无密码登陆各台datanode服务器,需要做如下配置:
|
1
2
3
4
|
在namenode 128上执行ssh-keygen,一路Enter回车即可。然后把公钥/root/.ssh/id_rsa.pub拷贝到datanode服务器即可,拷贝方法如下:ssh-copy-id -i .ssh/id_rsa.pub root@192.168.149.129ssh-copy-id -i .ssh/id_rsa.pub root@192.168.149.130 |
三、Java安装配置
|
1
2
3
4
5
|
tar -xvzf jdk-7u25-linux-x64.tar.gz &&mkdir -p /usr/java/ ; mv /jdk1.7.0_25 /usr/java/ 即可。安装完毕并配置java环境变量,在/etc/profile末尾添加如下代码:export JAVA_HOME=/usr/java/jdk1.7.0_25/export PATH=$JAVA_HOME/bin:$PATHexport CLASSPATH=$JAVE_HOME/lib/dt.jar:$JAVE_HOME/lib/tools.jar:./ |
保存退出即可,然后执行source /etc/profile 生效。在命令行执行java -version 如下代表JAVA安装成功。
|
1
2
3
4
|
[root@node1 ~]# java -versionjava version "1.7.0_25"Java(TM) SE Runtime Environment (build 1.7.0_25-b15)Java HotSpot(TM) 64-Bit Server VM (build 23.25-b01, mixed mode) |
(注* 我们需要在namenode、datanode三台服务器上都安装Java JDK版本)
四、Hadoop版本安装
官方下载的hadoop2.2.0版本,不用编译直接解压安装就可以使用了,如下:
第一步解压:
|
1
2
|
tar -xzvf hadoop-2.2.0.tar.gz &&mv hadoop-2.2.0 /data/hadoop/(注* 先在namenode服务器上都安装hadoop版本即可,datanode先不用安装,待会修改完配置后统一安装datanode) |
第二步配置变量:
|
1
2
3
4
5
|
在/etc/profile末尾继续添加如下代码,并执行source /etc/profile生效。export HADOOP_HOME=/data/hadoop/export PATH=$PATH:$HADOOP_HOME/bin/export JAVA_LIBRARY_PATH=/data/hadoop/lib/native/(注* 我们需要在namenode、datanode三台服务器上都配置Hadoop相关变量) |
五、配置Hadoop
在namenode上配置,我们需要修改如下几个地方:
1、修改vi /data/hadoop/etc/hadoop/core-site.xml 内容为如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
<?xml version="1.0"?><?xml-stylesheet type="text/xsl" href=\'#\'" Put site-specific property overrides in this file. --><configuration><property> <name>fs.default.name</name> <value>hdfs://192.168.149.128:9000</value> </property><property> <name>hadoop.tmp.dir</name> <value>/tmp/hadoop-${user.name}</value> <description>A base for other temporary directories.</description></property></configuration> |
2、修改vi /data/hadoop/etc/hadoop/mapred-site.xml内容为如下:
|
1
2
3
4
5
6
7
8
|
<?xml version="1.0"?><?xml-stylesheet type="text/xsl" href=\'#\'" Put site-specific property overrides in this file. --> <configuration> <property> <name>mapred.job.tracker</name> <value>192.168.149.128:9001</value> </property></configuration> |
3、修改vi /data/hadoop/etc/hadoop/hdfs-site.xml内容为如下:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
|
<?xml version="1.0" encoding="UTF-8"?><?xml-stylesheet type="text/xsl" href=\'#\'" /name><value>/data/hadoop/data_name1,/data/hadoop/data_name2</value></property><property><name>dfs.data.dir</name><value>/data/hadoop/data_1,/data/hadoop/data_2</value></property><property><name>dfs.replication</name><value>2</value></property></configuration> |
4、在/data/hadoop/etc/hadoop/hadoop-env.sh文件末尾追加JAV_HOME变量:
|
1
|
echo "export JAVA_HOME=/usr/java/jdk1.7.0_25/" >> /data/hadoop/etc/hadoop/hadoop-env.sh |
5、修改 vi /data/hadoop/etc/hadoop/masters文件内容为如下:
|
1
|
192.168.149.128 |
6、修改vi /data/hadoop/etc/hadoop/slaves文件内容为如下:
|
1
2
|
192.168.149.129192.168.149.130 |
如上配置完毕,以上的配置具体含义在这里就不做过多的解释了,搭建的时候不明白,可以查看一下相关的官方文档。
如上namenode就基本搭建完毕,接下来我们需要部署datanode,部署datanode相对简单,执行如下操作即可。
|
1
|
for i in `seq 129 130 ` ; do scp -r /data/hadoop/ root@192.168.149.$i:/data/ ; done |
自此整个集群基本搭建完毕,接下来就是启动hadoop集群了。
六、启动hadoop并测试
在启动hadoop之前,我们需要做一步非常关键的步骤,需要在namenode上执行如下命令初始化name目录和数据目录。
|
1
|
cd /data/hadoop/ ; ./bin/hadoop namenode -format |
那如何算初始化成功呢,如下截图成功创建name目录即正常:
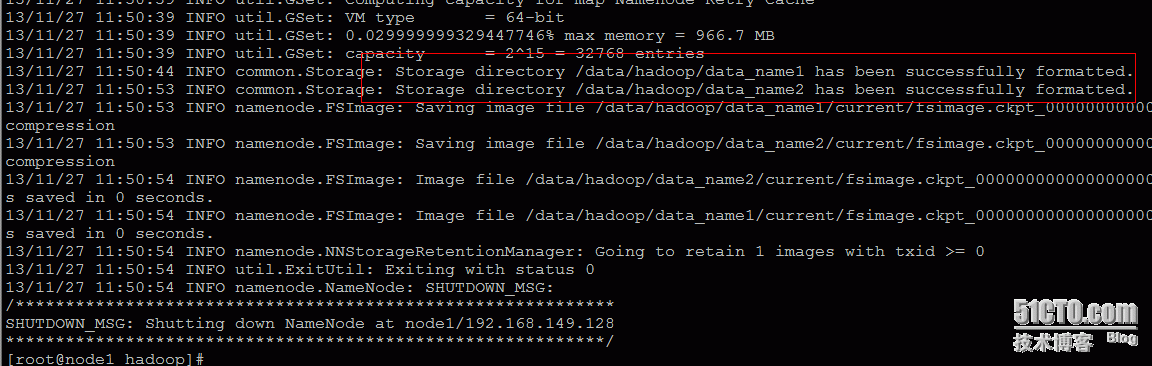
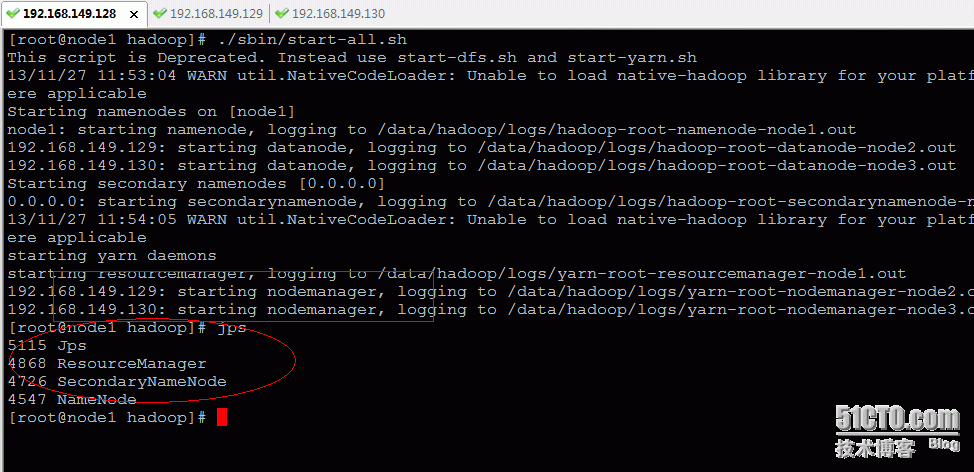
然后启动hadoop所有服务,如下命令:
|
1
|
[root@node1 hadoop]# ./sbin/start-all.sh |
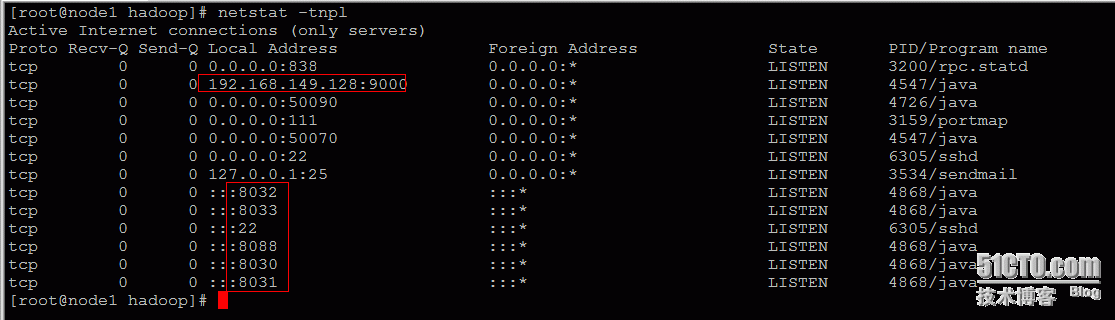
我们还可以查看相应的端口是否启动:netstat -ntpl
访问如下地址:http://192.168.149.128:50070/

访问地址:http://192.168.149.128:8088/
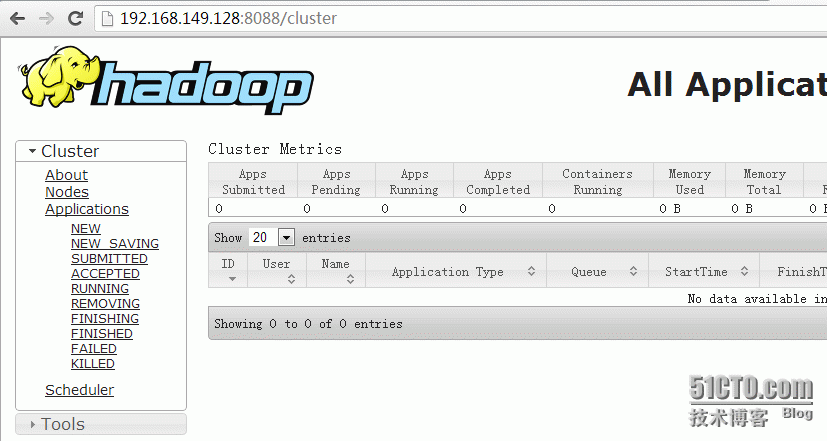
搭建完成后,我们简单的实际操作一下,如下图: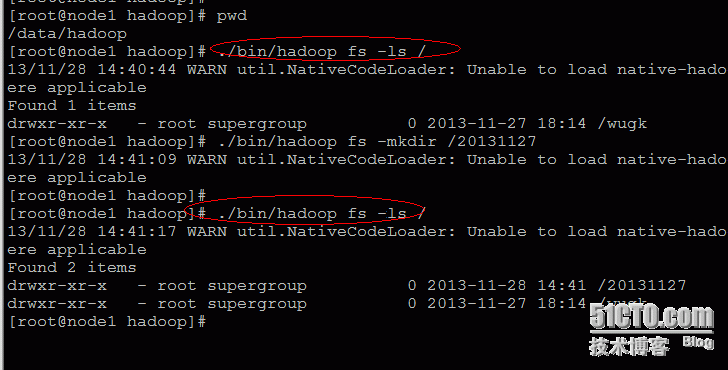
自此hadoop基本搭建完毕,接下来还有更深更多的东西需要去了解和学习,希望和大家一起学习,进步,分享、快乐。
本文出自 “吴光科-专注自动化运维” 博客,请务必保留此出处http://wgkgood.blog.51cto.com/1192594/1332340
Hadoop分布式文件系统架构部署的更多相关文章
- Hadoop 分布式文件系统:架构和设计
引言 Hadoop分布式文件系统(HDFS)被设计成适合运行在通用硬件(commodity hardware)上的分布式文件系统.它和现有的分布式文件系统有很多共同点.但同时,它和其他的分布式文件系统 ...
- 【官方文档】Hadoop分布式文件系统:架构和设计
http://hadoop.apache.org/docs/r1.0.4/cn/hdfs_design.html 引言 前提和设计目标 硬件错误 流式数据访问 大规模数据集 简单的一致性模型 “移动计 ...
- Hadoop分布式文件系统:架构和设计
原文地址:http://hadoop.apache.org/docs/r1.0.4/cn/hdfs_design.html 引言 前提和设计目标 硬件错误 流式数据访问 大规模数据集 简单的一致性模型 ...
- Hadoop分布式集群部署(单namenode节点)
Hadoop分布式集群部署 系统系统环境: OS: CentOS 6.8 内存:2G CPU:1核 Software:jdk-8u151-linux-x64.rpm hadoop-2.7.4.tar. ...
- Hadoop分布式文件系统使用指南
原文地址:http://hadoop.apache.org/docs/r1.0.4/cn/hdfs_user_guide.html 目的 概述 先决条件 Web接口 Shell命令 DFSAdmin命 ...
- Hadoop分布式文件系统
在一个经典的数据架构中,Hadoop是处理复杂数据流的核心.数据从各种系统中收集而来,并汇总导入到Hadoop分布式文件系统HDFS中,然后通过MapReduce或者其它基于MapReduce封装的语 ...
- Hadoop分布式文件系统HDFS详解
Hadoop分布式文件系统即Hadoop Distributed FileSystem. 当数据集的大小超过一台独立的物理计算机的存储能力时,就有必要对它进行分区(Partition)并 ...
- Hadoop分布式文件系统HDFS的工作原理
Hadoop分布式文件系统(HDFS)是一种被设计成适合运行在通用硬件上的分布式文件系统.HDFS是一个高度容错性的系统,适合部署在廉价的机器上.它能提供高吞吐量的数据访问,非常适合大规模数据集上的应 ...
- Hadoop教程(五)Hadoop分布式集群部署安装
Hadoop教程(五)Hadoop分布式集群部署安装 1 Hadoop分布式集群部署安装 在hadoop2.0中通常由两个NameNode组成,一个处于active状态,还有一个处于standby状态 ...
随机推荐
- 网页title上面添加图片
1.效果:
- 用sqlldr导入csv文件
1.新建文件test.ctl,内容如下 load dataCHARACTERSET 'UTF16' \*指定编码格式,很重要*\ infile 'vodall.csv' append into tab ...
- v$open_cursor中的相同record
之前在查看v$open_cursor的时候,发现很多相同的record. 让我很疑惑, sid saddr sql_id 都相同,我就想 这不是一个cursor吗? 那为什么在open_cursor中 ...
- HDU 4516
此题不难,但我就是RE,搞不懂啊...郁闷. 说下基本算法吧,只要留意到要分解的因式是(x+ai)..的形式,x前是系数为1的,而且,它们的绝对值在1000以内,于是,好办了.只要枚举(x+k)中的k ...
- js判断object的具体类型(或者说判断object的类class)
The JavaScript specification gives exactly one proper way to determine the class of an object: Objec ...
- jQuery Validate 使用
jQuery Validate 使用 <script src="js/b/js/jquery.validate.js"></script> <styl ...
- 在CentOS VPS上源代码安装高版本号git
背景:个别软件在国内下载非常慢,在vps下载就非常快. 可是下载好后的文件通过scp弄出来的时候又非常慢,所以想通过在vps里安装git,通过gitlab或oschina来进行中转.但遗憾的是,上传到 ...
- linux下启动jekins报错
进入默认安装目录,执行java -jar jekins.war 启动使用端口号: java -jar jenkins.war --httpPort=8085,即启动完成 这个有个弊端,关闭后下次还得这 ...
- ibatis 一对多查询
<typeAlias alias="businessScopeItem" type="com.sdfrdj.vo.BusinessScopeItem"/& ...
- B2241 打地鼠 暴力模拟
大水题!!!30分钟AC(算上思考时间),直接模拟就行,加一个判断约数的剪枝,再多加几个剪枝就可以过(数据巨水) 我也就会做暴力的题了. 题干: Description 打地鼠是这样的一个游戏:地面上 ...