MxNet教程:使用一台机器训练1400万张图片
官网链接:http://mxnet.readthedocs.io/en/latest/tutorials/imagenet_full.html
Training Deep Net on 14 Million Images by Using A Single Machine
This note describes how to train a neural network on Full ImageNet Dataset [1] with 14,197,087 images in 21,841 classes.We achieved a state-of-art model by using 4 GeForce GTX 980 cards on a single machine in 8.5 days.
There are several technical challenges in this problem.
- How to pack and store the massive data.
- How to minimize the memory consumption of the network, so we can use net with more capacity than those used for ImageNet 1K
- How to train the model fast.
We also released our pre-trained model for this full ImageNet dataset.
此方法描述了如何是使用一台机器 -4张GTX980互联在一台机器上,训练8.5天训练完整个ImageNet 数据集,此数据集有14,197,087张图片。
1.存储海量数据的方法。
2.最小化内存的计算代价。
3.如何快速训练模型。
Data Preprocessing
The raw full ImageNet dataset is more than 1TB. Before training the network, we need to shuffle these images then load batch of images to feed the neural network. Before we describe how we solve it, let’s do some calculation first:
原始的ImageNet数据超过1TB,在训练之前,必须分批的形式载入神经网络。在描述之前,先进行一些计算。
假设的硬件速度:
4K 随机读取 顺序存取
西数 黑盘: 0.43MB /s (110 IOPS) 170MB/s
三星 850PRO ssd 40MB/s 550MB/s
Assume we have two good storage device [2]:
| Device | 4K Random Seek | Sequential Seek |
| ------------------------- | --------------------- | --------------- |
| WD Black (HDD) | 0.43 MB /s (110 IOPS) | 170 MB/s |
| Samsung 850 PRO (SSD) | 40 MB/s (10,000 IOPS) | 550 MB/s |
A very naive approach is loading from a list by random seeking. If use this approach, we will spend 677 hours with HDD or 6.7 hours with SSD respectively. This is only about read. Although SSD looks not bad, but 1TB SSD is not affordable for everyone.
But we notice sequential seek is much faster than random seek. Also, loading batch by batch is a sequential action. Can we make a change? The answer is we can’t do sequential seek directly. We need random shuffle the training data first, then pack them into
a sequential binary package.
This is the normal solution used by most deep learning packages. However, unlike ImageNet 1K dataset, where wecannot store the images in raw pixels format. Because otherwise we will need more than 1TB space. Instead, we need to
pack the images in compressed format.
一个普通的方法是 从一个列中随机存取,若使用这种途径,我们使用HDD 将使用667小时,或者SSD6.7小时。SSD缺点就是有点贵。
序列化存取比随机存取快,但有时随机存取是必须的。
另外,我们需要一种压缩的格式进行存取数据。
The key ingredients are
- Store the images in jpeg format, and pack them into binary record.
- Split the list, and pack several record files, instead of one file.
- This allows us to pack the images in distributed fashion, because we will be eventually bounded by the IO cost during packing.
- We need to make the package being able to read from several record files, which is not too hard.This will allow us to store the entire imagenet dataset in around 250G space.
After packing, together with threaded buffer iterator, we can simply achieve an IO speed of around 3,000 images/sec on a normal HDD.
主要过程是:
使用jpeg格式存储数据,并进行二次压缩;
将列表拆分;减轻 I/O 代价;
打包存储可以 存储整个 ImageNet的数据集到250GB的空间里。
打包之后,我们可以多线程存取达到 3000张/秒 图像。
Training the model.训练模型
Now we have data. We need to consider which network structure to use. We use Inception-BN [3] style model, compared to other models such as VGG, it has fewer parameters, less parameters simplified sync problem. Considering our problem is much more challenging
than 1k classes problem, we add suitable capacity into original Inception-BN structure, by increasing the size of filter by factor of 1.5 in bottom layers of original Inception-BN network.This however, creates a challenge for GPU memory. As GTX980 only have
4G of GPU RAM. We really need to minimize the memory consumption to fit larger batch-size into the training. To solve this problem we use the techniques such as node memory reuse, and inplace optimization, which reduces the memory consumption by half, more
details can be found in memory optimization note
收集数据完毕,我们需要确定使用哪种网络结构。 在此,我们使用 Inception-BN [3] 形式的模型。相对于其他模型,它有更少的参数,因此有更少的参数同步问题。.............考虑到GTX980只有4G显存,需要分批训练。 我们使用 node memory reuse节点内存救援 的形式,减少一半的内存耗费,详情请见memory
optimization note。
Finally, we cannot train the model using a single GPU because this is a really large net, and a lot of data. We use data parallelism on four GPUs to train this model, which involves smart synchronization of parameters between different GPUs, and overlap
the communication and computation. A runtime denpdency engine is used to simplify this task, allowing us to run the training at around 170 images/sec.
我们使用多个GPU进行训练,缓解参数过多和数据过多的问题,使用数据并行的方式训练模型,设计到少量的 参数同步。 一个 runtime denpdency engine 用于使这种工作简单化, 可以达到 170张 图片/每秒 的训练速度。
Here is a learning curve of the training process:
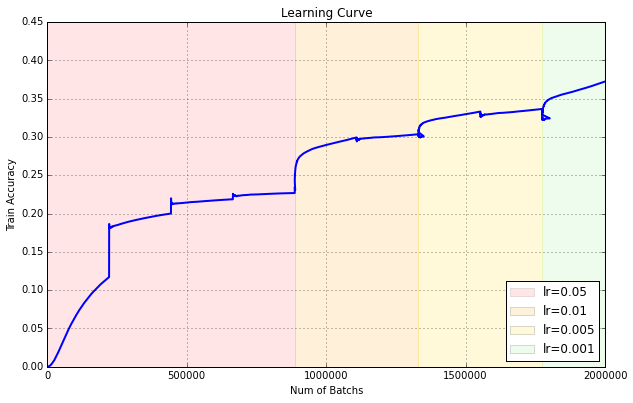
训练-学习曲线
Evaluate the Performance
Train Top-1 Accuracy over 21,841 classes: 37.19%
训练表现:
在21841个类上达到 37.19% 的Top1 分辨率
There is no official validation set over 21,841 classes, so we are using ILVRC2012 validation set to check the performance. Here is the result:
| Accuracy | Over 1,000 classes | Over 21,841 classes |
| -------- | ------------------ | ------------------- |
| Top-1 | 68.3% | 41.9% |
| Top-5 | 89.0% | 69.6% |
| Top=20 | 96.0% | 83.6% |
As we can see we get quite reasonable result after 9 iterations. Notably much less number of iterations is needed to achieve a stable performance, mainly due to we are facing a larger dataset.
We should note that this result is by no means optimal, as we did not carefully pick the parameters and the experiment cycle is longer than the 1k dataset. We think there is definite space for improvement, and you are welcomed to try it out by yourself!
The Code and Model.代码和模型
The code and step guide is publically available at https://github.com/dmlc/mxnet/tree/master/example/image-classification
We also release a pretrained model under https://github.com/dmlc/mxnet-model-gallery/tree/master/imagenet-21k-inception
How to Use The Model.使用模型
We should point out it 21k classes is much more challenging than 1k. Directly use the raw prediction is not a reasonable way.
Look at this picture which I took in Mount Rainier this summer:

We can figure out there is a mountain, valley, tree and bridge. And the prediction probability is :
对于 山峦、峡谷、树木、桥梁的预测准确度:
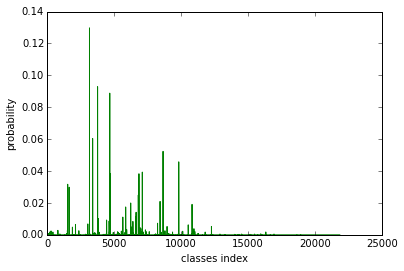
We notice there are several peaks. Let’s print out the label text in among 21k classes and ImageNet 1k classes:
| Rank | Over 1,000 classes | Over 21,841 classes |
| ----- | --------------------------- | -------------------------- |
| Top-1 | n09468604 valley | n11620673 Fir |
| Top-2 | n09332890 lakeside | n11624531 Spruce |
| Top-3 | n04366367 suspension bridge | n11621281 Amabilis fir |
| Top-4 | n09193705 alp | n11628456 Douglas fir |
| Top-5 | n09428293 seashore | n11627908 Mountain hemlock |
There is no doubt that directly use probability over 21k classes loss diversity of prediction. If you carefully choose a subset by using WordNet hierarchy relation, I am sure you will find more interesting results.
Note
[1] Deng, Jia, et al. “Imagenet: A large-scale hierarchical image database.”
Computer Vision and Pattern Recognition, 2009. CVPR 2009. IEEE Conference on. IEEE, 2009.
[2] HDD/SSD data is from public website may not be accurate.
[3] Ioffe, Sergey, and Christian Szegedy. “Batch normalization: Accelerating deep network training by reducing internal covariate shift.”arXiv preprint arXiv:1502.03167 (2015).
MxNet教程:使用一台机器训练1400万张图片的更多相关文章
- 使用ARP欺骗, 截取局域网中任意一台机器的网页请求,破解用户名密码等信息
ARP欺骗的作用 当你在网吧玩,发现有人玩LOL大吵大闹, 用ARP欺骗把他踢下线吧 当你在咖啡厅看上某一个看书的妹纸,又不好意思开口要微信号, 用arp欺骗,不知不觉获取到她的微信号和聊天记录,吓一 ...
- centos 安装redis(一台机器可以安装多个redis)
我在运行时redis版本是2.8 操作前设置以管理员身份: 打开终端输入 su - 安装redis需要确保系统已经安装了(gcc gcc-c++)# yum -y install gcc gcc-c+ ...
- 微信内嵌浏览器sessionid丢失问题,nginx ip_hash将所有请求转发到一台机器
现象微信中打开网页,图形验证码填写后,经常提示错误,即使填写正确也会提示错误,并且是间歇性出现. 系统前期,用户使用主要集中在pc浏览器中,一直没有出现这样的问题.近期有部分用户是在微信中访问的,才出 ...
- window下在同一台机器上安装多个版本jdk,修改环境变量不生效问题处理办法
window下在同一台机器上安装多个版本jdk,修改环境变量不生效问题处理办法 本机已经安装了jdk1.7,而比较早期的项目需要依赖jdk1.6,于是同时在本机安装了jdk1.6和jdk1.7. 安装 ...
- eclipse快速移动项目到另一台机器_步骤
快速移动项目到另一台机器_步骤 1.设置好eclipse的编码,必须对应个人项目文件的编码{ window--preferences--general--workspace-text file en ...
- windows下用一台机器配置分布式redis(主从服务器)
目录1.Replication的工作原理2.如何配置Redis主从复制 1.Replication的工作原理在Slave启动并连接到Master之后,它将主动发送一条SYNC命令.此后Master将启 ...
- ssh两台机器建立信任关系无密码登陆
在建立信任关系之前先看看基于公钥.私钥的加密和认证. 私钥签名过程 消息-->[私钥]-->签名-->[公钥]-->认证 私钥数字签名,公钥验证 Alice生成公钥和私钥,并将 ...
- 用pf透明地将流量从一台机器转到另一台机器上的缘起及实现方式对比
下面是也是我在12580工作时发生的事情,重新记录并发出来.这种特殊需求很考 验PF的功底.在新旧系统并存,做重构的时候有时很需要这种救急的作法.一.缘起miscweb1(172.16.88.228) ...
- Oracle RAC中的一台机器重启以后无法接入集群
前天有个同事说有套AIX RAC的其中一台服务器重启了操作系统以后,集群资源CSSD的资源一直都在START的状态,检查日志输出有如下内容: [ CSSD][1286]clssnmv ...
随机推荐
- hadoop2.3.0cdh5.0.2 升级到cdh5.7.0
后儿就放假了,上班这心真心收不住,为了能充实的度过这难熬的两天,我决定搞个大工程.....ps:我为啥这么期待放假呢,在沙发上像死人一样躺一天真的有意义嘛....... 当然版本:hadoop2.3. ...
- Pillow 模块~Python图像处理
什么是验证码? 验证码(CAPTCHA)是“Completely Automated Public Turing test to tell Computers and Humans Apart”(全自 ...
- chromeDriver下载地址
http://chromedriver.storage.googleapis.com/index.html
- ClassCastException:ColorDrawable cannot be cast to RoundRectDrawableWithShadow
错误信息 java.lang.ClassCastException: android.graphics.drawable.ColorDrawable cannot be cast to android ...
- R语言为数据框添加列名或行名
1.添加列名 wts=c(1,1,1) names(wts)=c("setosa","versicolor","virginica") 2. ...
- asp.net--webservice--安全验证SoapHeader
服务端的设置 客户端设置,需要生成一个服务端的代理,调用服务端的方法
- uva A Spy in the Metro(洛谷 P2583 地铁间谍)
A Spy in the Metro Secret agent Maria was sent to Algorithms City to carry out an especially dangero ...
- PHP array_intersect()
定义和用法 array_intersect() 函数返回两个或多个数组的交集数组. 结果数组包含了所有在被比较数组中,也同时出现在所有其他参数数组中的值,键名保留不变. 注释:仅有值用于比较. 语法 ...
- nyoj891(区间上的贪心)
题目意思: 给一些闭区间,求最少须要多少点,使得每一个区间至少一个点. http://acm.nyist.net/JudgeOnline/problem.php?pid=891 例子输入 4 1 5 ...
- [Node.js] Setup Local Configuration with Node.js Applications
Github To stop having to change configuration settings in production code and to stop secure informa ...