深入理解KMP算法
前言:本人最近在看《大话数据结构》字符串模式匹配算法的内容,但是看得很迷糊,这本书中这块的内容感觉基本是严蔚敏《数据结构》的一个翻版,此书中给出的代码实现确实非常精炼,但是个人感觉不是很好理解。
截止到目前为止,讲解KMP算法的文章,个人比较推荐有两篇:
http://www.cnblogs.com/c-cloud/p/3224788.html
http://www.matrix67.com/blog/archives/115
这两篇文章的解释基本思路是一致的,前者提到的部分匹配值就是后者提到的P[]数组(均对应于《算法导论》中KMP算法的next数组的求解),但是不同于《大话数据结构》和严蔚敏教材里面提到的next 或者nextval数组。但是这两个版本的next数组本质上都是一致的,只不过由于二者考虑了(1)串的第一个元素是否用于存储字符个数,即起始位置是0还是1;(2)next数组是否把当前位置的字符考虑进去。二者的转换关系为:
模式串:abaabcac
next1: 00112010
next2: 01122312
把next2中的0保持不变,其余的数据全部减去1: 00011201--->把第一个0移动到最后:00112010,即为next1。
本文将第一篇帖子摘录如下:
1.kmp算法的原理:
本部分内容转自:http://www.ruanyifeng.com/blog/2013/05/Knuth%E2%80%93Morris%E2%80%93Pratt_algorithm.html
字符串匹配是计算机的基本任务之一。
举例来说,有一个字符串"BBC ABCDAB ABCDABCDABDE",我想知道,里面是否包含另一个字符串"ABCDABD"?

许多算法可以完成这个任务,Knuth-Morris-Pratt算法(简称KMP)是最常用的之一。它以三个发明者命名,起头的那个K就是著名科学家Donald Knuth。

这种算法不太容易理解,网上有很多解释,但读起来都很费劲。直到读到Jake Boxer的文章,我才真正理解这种算法。下面,我用自己的语言,试图写一篇比较好懂的KMP算法解释。
1.

首先,字符串"BBC ABCDAB ABCDABCDABDE"的第一个字符与搜索词"ABCDABD"的第一个字符,进行比较。因为B与A不匹配,所以搜索词后移一位。
2.

因为B与A不匹配,搜索词再往后移。
3.

就这样,直到字符串有一个字符,与搜索词的第一个字符相同为止。
4.

接着比较字符串和搜索词的下一个字符,还是相同。
5.

直到字符串有一个字符,与搜索词对应的字符不相同为止。
6.

这时,最自然的反应是,将搜索词整个后移一位,再从头逐个比较。这样做虽然可行,但是效率很差,因为你要把"搜索位置"移到已经比较过的位置,重比一遍。
7.
一个基本事实是,当空格与D不匹配时,你其实知道前面六个字符是"ABCDAB"。KMP算法的想法是,设法利用这个已知信息,不要把"搜索位置"移回已经比较过的位置,继续把它向后移,这样就提高了效率。
8.

怎么做到这一点呢?可以针对搜索词,算出一张《部分匹配表》(Partial Match Table)。这张表是如何产生的,后面再介绍,这里只要会用就可以了。
9.
已知空格与D不匹配时,前面六个字符"ABCDAB"是匹配的。查表可知,最后一个匹配字符B对应的"部分匹配值"为2,因此按照下面的公式算出向后移动的位数:
移动位数 = 已匹配的字符数 - 对应的部分匹配值
因为 6 - 2 等于4,所以将搜索词向后移动4位。
10.

因为空格与C不匹配,搜索词还要继续往后移。这时,已匹配的字符数为2("AB"),对应的"部分匹配值"为0。所以,移动位数 = 2 - 0,结果为 2,于是将搜索词向后移2位。
11.

因为空格与A不匹配,继续后移一位。
12.

逐位比较,直到发现C与D不匹配。于是,移动位数 = 6 - 2,继续将搜索词向后移动4位。
13.

逐位比较,直到搜索词的最后一位,发现完全匹配,于是搜索完成。如果还要继续搜索(即找出全部匹配),移动位数 = 7 - 0,再将搜索词向后移动7位,这里就不再重复了。
14.

下面介绍《部分匹配表》是如何产生的。
首先,要了解两个概念:"前缀"和"后缀"。 "前缀"指除了最后一个字符以外,一个字符串的全部头部组合;"后缀"指除了第一个字符以外,一个字符串的全部尾部组合。
15.
"部分匹配值"就是"前缀"和"后缀"的最长的共有元素的长度。以"ABCDABD"为例,
- "A"的前缀和后缀都为空集,共有元素的长度为0;
- "AB"的前缀为[A],后缀为[B],共有元素的长度为0;
- "ABC"的前缀为[A, AB],后缀为[BC, C],共有元素的长度0;
- "ABCD"的前缀为[A, AB, ABC],后缀为[BCD, CD, D],共有元素的长度为0;
- "ABCDA"的前缀为[A, AB, ABC, ABCD],后缀为[BCDA, CDA, DA, A],共有元素为"A",长度为1;
- "ABCDAB"的前缀为[A, AB, ABC, ABCD, ABCDA],后缀为[BCDAB, CDAB, DAB, AB, B],共有元素为"AB",长度为2;
- "ABCDABD"的前缀为[A, AB, ABC, ABCD, ABCDA, ABCDAB],后缀为[BCDABD, CDABD, DABD, ABD, BD, D],共有元素的长度为0。
16.
"部分匹配"的实质是,有时候,字符串头部和尾部会有重复。比如,"ABCDAB"之中有两个"AB",那么它的"部分匹配值"就是2("AB"的长度)。搜索词移动的时候,第一个"AB"向后移动4位(字符串长度-部分匹配值),就可以来到第二个"AB"的位置。
2.next数组的求解思路
通过上文完全可以对kmp算法的原理有个清晰的了解,那么下一步就是编程实现了,其中最重要的就是如何根据待匹配的模版字符串求出对应每一位的最大相同前后缀的长度。我先给出我的代码:

- 1 void makeNext(const char P[],int next[])
- 2 {
- 3 int q,k;//q:模版字符串下标;k:最大前后缀长度
- 4 int m = strlen(P);//模版字符串长度
- 5 next[0] = 0;//模版字符串的第一个字符的最大前后缀长度为0
- 6 for (q = 1,k = 0; q < m; ++q)//for循环,从第二个字符开始,依次计算每一个字符对应的next值
- 7 {
- 8 while(k > 0 && P[q] != P[k])//递归的求出P[0]···P[q]的最大的相同的前后缀长度k
- 9 k = next[k-1]; //不理解没关系看下面的分析,这个while循环是整段代码的精髓所在,确实不好理解
- 10 if (P[q] == P[k])//如果相等,那么最大相同前后缀长度加1
- 11 {
- 12 k++;
- 13 }
- 14 next[q] = k;
- 15 }
- 16 }
现在我着重讲解一下while循环所做的工作:
- 已知前一步计算时最大相同的前后缀长度为k(k>0),即P[0]···P[k-1];
- 此时比较第k项P[k]与P[q],如图1所示
- 如果P[K]等于P[q],那么很简单跳出while循环;
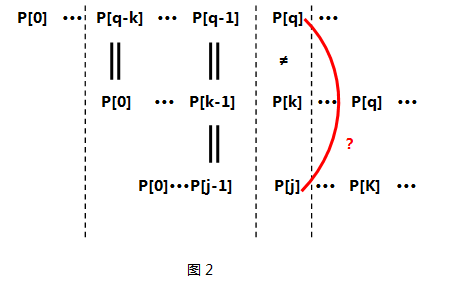
- 关键!关键有木有!关键如果不等呢???那么我们应该利用已经得到的next[0]···next[k-1]来求P[0]···P[k-1]这个子串中最大相同前后缀,可能有同学要问了——为什么要求P[0]···P[k-1]的最大相同前后缀呢???是啊!为什么呢? 原因在于P[k]已经和P[q]失配了,而且P[q-k] ··· P[q-1]又与P[0] ···P[k-1]相同,看来P[0]···P[k-1]这么长的子串是用不了了,那么我要找个同样也是P[0]打头、P[k-1]结尾的子串即P[0]···P[j-1](j==next[k-1]),看看它的下一项P[j]是否能和P[q]匹配。如图2所示

附代码:
- 1 #include<stdio.h>
- 2 #include<string.h>
- 3 void makeNext(const char P[],int next[])
- 4 {
- 5 int q,k;
- 6 int m = strlen(P);
- 7 next[0] = 0;
- 8 for (q = 1,k = 0; q < m; ++q)
- 9 {
- 10 while(k > 0 && P[q] != P[k])
- 11 k = next[k-1];
- 12 if (P[q] == P[k])
- 13 {
- 14 k++;
- 15 }
- 16 next[q] = k;
- 17 }
- 18 }
- 19
- 20 int kmp(const char T[],const char P[],int next[])
- 21 {
- 22 int n,m;
- 23 int i,q;
- 24 n = strlen(T);
- 25 m = strlen(P);
- 26 makeNext(P,next);
- 27 for (i = 0,q = 0; i < n; ++i)
- 28 {
- 29 while(q > 0 && P[q] != T[i])
- 30 q = next[q-1];
- 31 if (P[q] == T[i])
- 32 {
- 33 q++;
- 34 }
- 35 if (q == m)
- 36 {
- 37 printf("Pattern occurs with shift:%d\n",(i-m+1));
- 38 }
- 39 }
- 40 }
- 41
- 42 int main()
- 43 {
- 44 int i;
- 45 int next[20]={0};
- 46 char T[] = "ababxbababcadfdsss";
- 47 char P[] = "abcdabd";
- 48 printf("%s\n",T);
- 49 printf("%s\n",P );
- 50 // makeNext(P,next);
- 51 kmp(T,P,next);
- 52 for (i = 0; i < strlen(P); ++i)
- 53 {
- 54 printf("%d ",next[i]);
- 55 }
- 56 printf("\n");
- 57
- 58 return 0;
- 59 }
深入理解KMP算法的更多相关文章
- 理解 KMP 算法
KMP(The Knuth-Morris-Pratt Algorithm)算法用于字符串匹配,从字符串中找出给定的子字符串.但它并不是很好理解和掌握.而理解它概念中的部分匹配表,是理解 KMP 算法的 ...
- KMP算法详解 --- 彻头彻尾理解KMP算法
前言 之前对kmp算法虽然了解它的原理,即求出P0···Pi的最大相同前后缀长度k. 但是问题在于如何求出这个最大前后缀长度呢? 我觉得网上很多帖子都说的不是很清楚,总感觉没有把那层纸戳破, 后来翻看 ...
- 从头到尾测地理解KMP算法【转】
本文转载自:http://blog.csdn.net/v_july_v/article/details/7041827 1. 引言 本KMP原文最初写于2年多前的2011年12月,因当时初次接触KMP ...
- 深入理解KMP算法之续篇
前言: 纠结于KMP已经两天了,相较于本人之前博客中提到的几篇博文,本人感觉这篇文章更清楚地说明了KMP算法的来龙去脉. http://www.cnblogs.com/goagent/archive/ ...
- 真正理解KMP算法
作者:jostree 转载请注明出处 http://www.cnblogs.com/jostree/p/4403560.html 所谓KMP算法,就是判断一个模式串是否是一个字符串的子串,通常的算法当 ...
- 理解KMP算法
母串:S[i] 模式串:T[i] 标记数组:Next[i](Next[i]表示T[0~i]最长前缀/后缀数) 先来讲一下最长前缀/后缀的概念 例如有字符串T[6]=abcabd接下来讨论的全部是真前缀 ...
- KMP算法 --- 深入理解next数组
在KMP算法中有个数组,叫做前缀数组,也有的叫next数组. 每一个子串有一个固定的next数组,它记录着字符串匹配过程中失配情况下可以向前多跳几个字符. 当然它描述的也是子串的对称程度,程度越高,值 ...
- 从有限状态机的角度去理解Knuth-Morris-Pratt Algorithm(又叫KMP算法)
转载请加上:http://www.cnblogs.com/courtier/p/4273193.html 在开始讲这个文章前的唠叨话: 1:首先,在阅读此篇文章之前,你至少要了解过,什么是有限状态机, ...
- KMP算法的一次理解
1. 引言 在一个大的字符串中对一个小的子串进行定位称为字符串的模式匹配,这应该算是字符串中最重要的一个操作之一了.KMP本身不复杂,但网上绝大部分的文章把它讲混乱了.下面,咱们从暴力匹配算法讲起,随 ...
随机推荐
- FFmpeg-20160428-snapshot-bin
ESC 退出 0 进度条开关 1 屏幕原始大小 2 屏幕1/2大小 3 屏幕1/3大小 4 屏幕1/4大小 S 下一帧 [ -2秒 ] +2秒 ; -1秒 ' +1秒 下一个帧 -> -5秒 F ...
- shell脚本监控MySQL服务是否正常
监控MySQL服务是否正常,通常的思路为:检查3306端口是否启动,ps查看mysqld进程是否启动,命令行登录mysql执行语句返回结果,php或jsp程序检测(需要开发人员开发程序)等等: 方法1 ...
- Lake Counting_深度搜索_递归
Lake Counting Time Limit: 1000MS Memory Limit: 65536K Total Submissions: 30414 Accepted: 15195 D ...
- JavaScript高级程序设计学习笔记--变量、作用域和内存问题
传递参数 function setName(obj){ obj.name="Nicholas"; obj=new object(); obj.name="Greg&quo ...
- win7下安装openpyxl
想使用python来操作Excel,看资料据说openpyxl非常好用,于是到https://pypi.python.org/pypi/openpyxl下载了安装包.下面就来说说安装步骤,也算是对自己 ...
- iOS工程师Mac上的必备软件
原文链接 前言 iOS工程师一直都是那么的高逼格,用的是Mac电脑,耍的是iPhone手机,哇咔咔~~ 但是,作为一名iOS开发工程师,我们除了高逼格外,还必须是全能的.你不会点UI设计 ...
- 在HTML中禁止文字的复制
很简单,只需在<body>中添加如下代码: <body oncontextmenu='return false' ondragstart='return false' onsele ...
- 常用iOS的第三方框架
图像:1.图片浏览控件MWPhotoBrowser 实现了一个照片浏览器类似 iOS 自带的相册应用,可显示来自手机的图片或者是网络图片,可自动从网络下载图片并进行缓存.可对图片进行缩放等 ...
- DB2 SQL Mixed data in character strings
Mixed character data and graphic data are always allowed for Unicode, but for EBCDIC and ASCII, the ...
- Jmeter中通过BeanShell获取当前时间
第一步编写需要的java类: 第二步:将编写好的java类打包成jar包 第三步:将jar包放到\apache-jmeter-2.13\lib\ext下面 第四步:在Jmeter中通过BeanShel ...