Pearson(皮尔逊)相关系数及MATLAB实现
转自:http://blog.csdn.net/wsywl/article/details/5727327
由于使用的统计相关系数比较频繁,所以这里就利用几篇文章简单介绍一下这些系数。
相关系数:考察两个事物(在数据里我们称之为变量)之间的相关程度。
如果有两个变量:X、Y,最终计算出的相关系数的含义可以有如下理解:
(1)、当相关系数为0时,X和Y两变量无关系。
(2)、当X的值增大(减小),Y值增大(减小),两个变量为正相关,相关系数在0.00与1.00之间。
(3)、当X的值增大(减小),Y值减小(增大),两个变量为负相关,相关系数在-1.00与0.00之间。
相关系数的绝对值越大,相关性越强,相关系数越接近于1或-1,相关度越强,相关系数越接近于0,相关度越弱。
通常情况下通过以下取值范围判断变量的相关强度:
相关系数 0.8-1.0 极强相关
0.6-0.8 强相关
0.4-0.6 中等程度相关
0.2-0.4 弱相关
0.0-0.2 极弱相关或无相关
Pearson(皮尔逊)相关系数
1、简介
皮尔逊相关也称为积差相关(或积矩相关)是英国统计学家皮尔逊于20世纪提出的一种计算直线相关的方法。
假设有两个变量X、Y,那么两变量间的皮尔逊相关系数可通过以下公式计算:
公式一:
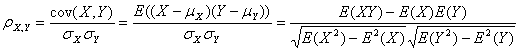
公式二:

公式三:
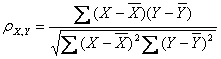
公式四:

以上列出的四个公式等价,其中E是数学期望,cov表示协方差,N表示变量取值的个数。
2、适用范围
当两个变量的标准差都不为零时,相关系数才有定义,皮尔逊相关系数适用于:
(1)、两个变量之间是线性关系,都是连续数据。
(2)、两个变量的总体是正态分布,或接近正态的单峰分布。
(3)、两个变量的观测值是成对的,每对观测值之间相互独立。
3、Matlab实现
皮尔逊相关系数的Matlab实现(依据公式四实现):
- function coeff = myPearson(X , Y)
- % 本函数实现了皮尔逊相关系数的计算操作
- %
- % 输入:
- % X:输入的数值序列
- % Y:输入的数值序列
- %
- % 输出:
- % coeff:两个输入数值序列X,Y的相关系数
- %
- if length(X) ~= length(Y)
- error('两个数值数列的维数不相等');
- return;
- end
- fenzi = sum(X .* Y) - (sum(X) * sum(Y)) / length(X);
- fenmu = sqrt((sum(X .^2) - sum(X)^2 / length(X)) * (sum(Y .^2) - sum(Y)^2 / length(X)));
- coeff = fenzi / fenmu;
- end %函数myPearson结束
也可以使用Matlab中已有的函数计算皮尔逊相关系数:
- coeff = corr(X , Y);
4、参考内容
Pearson(皮尔逊)相关系数及MATLAB实现的更多相关文章
- Pearson(皮尔逊)相关系数
Pearson(皮尔逊)相关系数:也叫pearson积差相关系数.衡量两个连续变量之间的线性相关程度. 当两个变量都是正态连续变量,而且两者之间呈线性关系时,表现这两个变量之间相关程度用积差相关系数, ...
- np.corrcoef()方法计算数据皮尔逊积矩相关系数(Pearson's r)
上一篇通过公式自己写了一个计算两组数据的皮尔逊积矩相关系数(Pearson's r)的方法,但np已经提供了一个用于计算皮尔逊积矩相关系数(Pearson's r)的方法 np.corrcoef() ...
- pandas通过皮尔逊积矩线性相关系数(Pearson's r)计算数据相关性
皮尔逊积矩线性相关系数(Pearson's r)用于计算两组数组之间是否有线性关联,举个例子: a = pd.Series([1,2,3,4,5,6,7,8,9,10]) b = pd.Series( ...
- 皮尔逊(Pearson)系数矩阵——numpy
一.原理 注意 专有名词.(例如:极高相关) 二.代码 import numpy as np f = open('../file/Pearson.csv', encoding='utf-8') dat ...
- 皮尔逊相似度计算的例子(R语言)
编译最近的协同过滤算法皮尔逊相似度计算.下顺便研究R简单使用的语言.概率统计知识. 一.概率论和统计学概念复习 1)期望值(Expected Value) 由于这里每一个数都是等概率的.所以就当做是数 ...
- 皮尔逊残差 | Pearson residual
参考:Pearson Residuals 这些概念到底是写什么?怎么产生的? 统计学功力太弱了!
- Spark Mllib里的如何对两组数据用皮尔逊计算相关系数
不多说,直接上干货! import org.apache.spark.mllib.stat.Statistics 具体,见 Spark Mllib机器学习实战的第4章 Mllib基本数据类型和Mlli ...
- 从欧几里得距离、向量、皮尔逊系数到http://guessthecorrelation.com/
一.欧几里得距离就是向量的距离公式 二.皮尔逊相关系数反应的就是线性相关 游戏http://guessthecorrelation.com/ 的秘诀也就是判断一组点的拟合线的斜率y/x ------- ...
- Python基于皮尔逊系数实现股票预测
# -*- coding: utf-8 -*- """ Created on Mon Dec 2 14:49:59 2018 @author: zhen "&q ...
随机推荐
- 基于RMI服务传输大文件的完整解决方案
基于RMI服务传输大文件,分为上传和下载两种操作,需要注意的技术点主要有三方面,第一,RMI服务中传输的数据必须是可序列化的.第二,在传输大文件的过程中应该有进度提醒机制,对于大文件传输来说,这点很重 ...
- MySQL-procedure(loop,repeat)
在 MySQL-procedure(cursor,loop) 中将spam_keyword表中的文字全部分割到t表当中,且每一行的字都不重复,那t表可以用来当作一个小字典,只有1000来个字符,这次把 ...
- Linux指令备忘
这是之前初学Linux时做下的笔记,根据现在的熟悉程度增删了一些,也是做上备份查看,希望能让有用的童鞋参考一二. //将使用到的内容输出到屏幕,仅检查语法 sh -nx scripts.sh //输出 ...
- 导出HTML
版权声明:本文为博主原创文章,未经博主允许不得转载.
- stm32 加入 USE_STDPERIPH_DRIVER、STM32F10X_HD的原因
初学STM32,在RealView MDK 环境中使用STM32固件库建立工程时,初学者可能会遇到编译不通过的问题.出现如下警告或错误提示: warning: #223-D: function &qu ...
- [转] OpenStack Kilo 更新日志
OpenStack 2015.1.0 (Kilo)更新日志 原文: https://wiki.openstack.org/wiki/ReleaseNotes/Kilo/zh-hans 目录 [隐藏] ...
- 在dreamweaver上面制作表格
开始有点犯二,准备一行一行敲,五六十行,人都得敲疯,还容易出错...... 直接从wps复制粘贴到设计里面,立马就出来了,费那事干嘛,哎,工具还是用的不熟
- 这回真的是挤时间了-PHP基础(三)
hi 刚看了唐人街探案,5星好评啊亲.由于是早就约好的,也不好推辞(虽然是和男的..),但该写的还是得挤时间写.明天早上老师的项目结题,虽然和我关系不大,但不要添乱就好!! 1.PHP 一.PHP基 ...
- MVC、MVVM、MVP小结
MVC MVC(Mode View Controller)是一种设计模式,它将应用划分为三个部分: 数据(模型).展现层(视图).用户交互(控制器). 一个事件发生的过程: ① 用户和应用产生交互 ② ...
- jsp前三章小测试:错题
/bin:存放各种平台下用于启动和停止Tomcat的脚本文件 /logs:存放Tomcat的日志文件 /webapps:web应用的发布目录 /work:Tomcat把由JSP生成的Servlet存放 ...