Redis集群知识解析
Twemproxy 又称nutcracker ,是一个memcache、Redis协议的轻量级代理,一个用于sharding 的中间件。有了Twemproxy,客户端不直接访问Redis服务器,而是通过twemproxy 代理中间件间接访问。 Twemproxy 为 Twitter 开源产品,简单来说,Twemproxy是Twitter开发的一个redis代理proxy,类似于nginx的反向代理或者mysql的代理工具,如amoeba。Twemproxy通过引入一个代理层,可以将其后端的多台Redis或Memcached实例进行统一管理与分配,使应用程序只需要在Twemproxy上进行操作,而不用关心后面具体有多少个真实的Redis或Memcached存储。
一般来说,只要服务器上运行了Redis,那么就有可能造成一种非常可怕局面:服务器的内存将立刻被占满,而且一台Redis数据库的性能终归是有限制的,那么现在如果要求保证用户的执行速度快,就需要使用集群的设计。而对于集群的设计主要的问题就是解决单实例Redis的性能瓶颈。
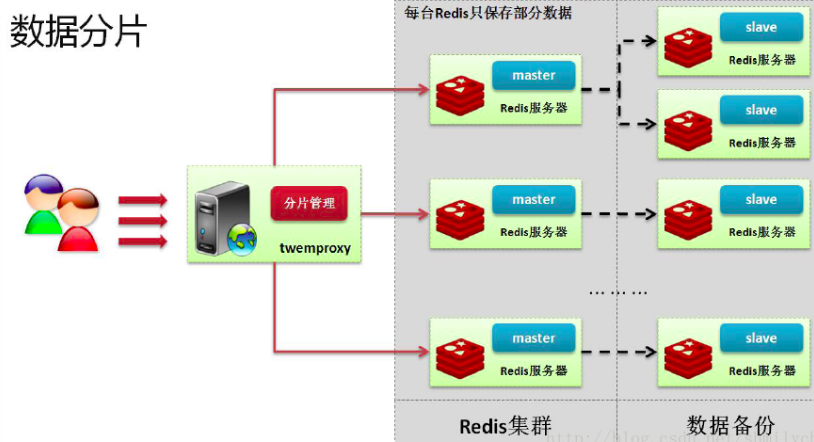
Twemproxy是一个专门为了这种nosql数据库设计的一款代理工具软件,这个工具软件最大的特征是可以实现数据的分片处理。所谓的分片指的是根据一定的算法将要保存的数据保存到不同的节点之中。 有了分片之后数据的保存节点就可能有无限多个,但是理论上如果要真进行集群的搭建,往往要求三台节点起步。Twemproxy代理机制具有如下特点:
1)支持失败节点自动删除
可以设置重新连接该节点的时间
可以设置连接多少次之后删除该节点
2)支持设置HashTag
通过HashTag可以自己设定将两个key哈希到同一个实例上去
3)减少与redis的直接连接数
保持与redis的长连接
减少了客户端直接与服务器连接的连接数量
4)自动分片到后端多个redis实例上
多种hash算法:md5、crc16、crc32 、crc32a、fnv1_64、fnv1a_64、fnv1_32、fnv1a_32、hsieh、murmur、jenkins
多种分片算法:ketama(一致性hash算法的一种实现)、modula、random
可以设置后端实例的权重
5)避免单点问题
可以平行部署多个代理层,通过HAProxy做负载均衡,将redis的读写分散到多个twemproxy上。
6)支持状态监控
可设置状态监控ip和端口,访问ip和端口可以得到一个json格式的状态信息串
可设置监控信息刷新间隔时间
7)使用 pipelining 处理请求和响应
连接复用,内存复用
将多个连接请求,组成reids pipelining统一向redis请求
8)并不是支持所有redis命令
不支持redis的事务操作
使用SIDFF, SDIFFSTORE, SINTER, SINTERSTORE, SMOVE, SUNION and SUNIONSTORE命令需要保证key都在同一个分片上。
举个小例子:比如可以把公司前台的MM看作一个proxy,你是个送快递的,你可以通过这个妹子替你代理把你要送达的包裹给公司内部的人,而你不用知道公司每个人座位在哪里。Twemproxy可以把多台redis server当作一台使用,开发人员通过twemproxy访问这些redis servers 的时候不用关心到底去哪一台redis server读取k-v数据或者把k-v数据更新到数据集中。
通过Twemproxy可以使用多台服务器来水平扩张redis服务,可以有效的避免单点故障问题。虽然使用Twemproxy需要更多的硬件资源和在redis性能有一定的损失(twitter测试约20%),但是能够提高整个系统的HA也是相当划算的。比如我所在的公司,只使用一台redis server进行读写,但是还有一台slave server一直在同步这台生产服务器的数据。这样做就是为了防止这台单一的生产服务器出现故障时能够有一个"备胎",可以把前端的redis数据读写请求切换到从服务器上,web程序因而不需要直接去访问mysql数据库。再借助于haproxy(又是proxy)或者VIP技术可以实现一个简单的HA方案,可以避免单点故障。但是这种简单的Master-Slave"备胎"方案不能扩张整个redis的容量(如果用系统内存大小衡量,且不考虑内存不足时把数据swap到磁盘上),最大容量由所有的redis servers中最小内存决定的【木桶的短板】。
Twemproxy可以把数据sharding(碎片,这里是分散的意思)到多台服务器的上,每台服务器存储着整个数据集的一部分。因而,当某一台redis服务器宕机了,那么也就失去了一部分数据。如果借助于redis的master-slave replication,能保证在任何一台redis不能工作情况下,仍然能够保证能够存在一个整个数据集的完全覆盖,那么整个redis group(或者称作cluster)仍然能够正常工作。
需要注意的是:
Twemproxy不会增加Redis的性能指标数据,据业界测算,使用twemproxy相比直接使用Redis会带来大约10%的性能下降。但是单个Redis进程的内存管理能力有限。据测算,单个Redis进程内存超过20G之后,效率会急剧下降。目前,建议单个Redis最好配置在8G以内;8G以上的Redis缓存需求,通过Twemproxy来提供支持。
Twemproxy是一种代理分片机制,由Twitter开源,主要用于减少后端缓存服务器的连接数量。Twemproxy作为代理,可接受来自多个程序的访问,按照路由规则,转发给后台的各个Redis或memcached服务器,再原路返回。该方案很好的解决了单个Redis或memcached实例承载能力的问题。Twemproxy本身也是单点,需要用Keepalived做高可用方案,可以使用多台服务器来水平扩张redis或memcached服务,可以有效的避免单点故障问题。
-----------------------------------------------------------------------------------------------------------------------------------------------------
下面记录下Redis+Twemproxy(nutcracker)集群部署过程:
先简单看下集群架构

Twemproxy可以把多台redis server当作一台使用,扩大整个redis的容量,开发人员通过twemproxy访问这些redis servers 的时候不用关心到底去哪一台redis server读取k-v数据或者把k-v数据更新到数据集中。
- 1)集群环境
- 182.48.115.236 twemproxy-server 安装nutcracker
- 182.48.115.237 redis-server1 安装redis
- 182.48.115.238 redis-server2 安装redis
- 如果在线上使用的话:
- 中间代理层twemproxy需要2台,并且需要结合keepalived(心跳测试)实现高可用,客户端通过vip资源访问twemproxy。
- 另外,后面的redis节点也都要做主从复制环境。因为twemproxy会将数据碎片到每个redis节点上,如果节点挂了,那部分数据就没了。所以最好对每个redis节点机做主从,防止数据丢失。
- 这里做测试,我只使用一台twemproxy+2个redis节点(不做主从)。
- 关闭三台机器的iptables防火墙和selinux
- 2)在两台redis机器上安装并启动redis
- 可以参考:http://www.cnblogs.com/kevingrace/p/6265722.html
- 3)在twemproxy-server机器上安装nutcracker
- 编译安装autoconf
- [root@twemproxy-server ~]# wget http://ftp.gnu.org/gnu/autoconf/autoconf-2.69.tar.gz
- [root@twemproxy-server ~]# tar -zvxf autoconf-2.69.tar.gz
- [root@twemproxy-server ~]# cd autoconf-2.69
- [root@twemproxy-server autoconf-2.69]# ./configure && make && make install
- 编译安装automake
- [root@twemproxy-server ~]# wget http://ftp.gnu.org/gnu/automake/automake-1.15.tar.gz
- [root@twemproxy-server ~]# tar -zvxf automake-1.15.tar.gz
- [root@twemproxy-server ~]# cd automake-1.15
- [root@twemproxy-server automake-1.15]# ./configure && make && make install
- 编译安装libtool
- [root@twemproxy-server ~]# wget https://ftp.gnu.org/gnu/libtool/libtool-2.4.6.tar.gz
- [root@twemproxy-server ~]# tar -zvxf libtool-2.4.6.tar.gz
- [root@twemproxy-server ~]# cd libtool-2.4.6
- [root@twemproxy-server libtool-2.4.6]# ./configure && make && make install
- 编译安装twemproxy
- [root@twemproxy-server ~]# wget https://github.com/twitter/twemproxy/archive/master.zip
- [root@twemproxy-server ~]# unzip master.zip
- [root@twemproxy-server ~]# cd twemproxy-master
- [root@twemproxy-server twemproxy-master]# aclocal
- [root@twemproxy-server twemproxy-master]# autoreconf -f -i -Wall,no-obsolete //执行autoreconf 生成 configure文件等
- [root@twemproxy-server twemproxy-master]# ./configure --prefix=/usr/local/twemproxy/
- [root@twemproxy-server twemproxy-master]# make && make install
- .................................................................................
- 注意:如果没有安装libtool 的话,autoreconf 的时候会报错,如下:
- configure.ac:133: the top level
- configure.ac:36: error: possibly undefined macro: AC_PROG_LIBTOOL
- If this token and others are legitimate, please use m4_pattern_allow.
- See the Autoconf documentation.
- autoreconf: /usr/local/bin/autoconf failed with exit status: 1
- .................................................................................
- twemproxy配置:
- [root@twemproxy-server ~]# cd /usr/local/twemproxy/
- [root@twemproxy-server twemproxy]# ls
- sbin share
- [root@twemproxy-server twemproxy]# cp -r /root/twemproxy-master/conf /usr/local/twemproxy/
- [root@twemproxy-server twemproxy]# cd conf/
- [root@twemproxy-server conf]# ls
- nutcracker.leaf.yml nutcracker.root.yml nutcracker.yml
- [root@twemproxy-server conf]# cp nutcracker.yml nutcracker.yml.bak
- [root@twemproxy-server conf]# vim nutcracker.yml
- alpha: //这个名称可以自己随意定义
- listen: 182.48.115.236:22121
- hash: fnv1a_64
- distribution: ketama
- auto_eject_hosts: true
- redis: true
- server_retry_timeout: 2000
- server_failure_limit: 1
- servers: //这里配置了两个分片
- - 182.48.115.237:6379:1
- - 182.48.115.238:6379:1
- [root@twemproxy-server conf]# nohup /usr/local/twemproxy/sbin/nutcracker -c /usr/local/twemproxy/conf/nutcracker.yml &
- [root@twemproxy-server conf]# ps -ef|grep nutcracker
- root 6407 24314 0 23:26 pts/0 00:00:00 /usr/local/twemproxy/sbin/nutcracker -c /usr/local/twemproxy/conf/nutcracker.yml
- root 6410 24314 0 23:26 pts/0 00:00:00 grep nutcracker
- [root@twemproxy-server conf]# lsof -i:22121
- COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
- nutcracke 6407 root 5u IPv4 155109 0t0 TCP localhost:22121 (LISTEN)
- 4)测试 twemproxy set/get ,后端分片查看
- [root@twemproxy-server ~]# redis-cli -h 182.48.115.236 -p 22121
- 182.48.115.236:22121>
- 测试短key - value
- [root@twemproxy-server ~]# redis-cli -h 182.48.115.236 -p 22121
- 182.48.115.236:22121> set wangshibo 666666
- OK
- 182.48.115.236:22121> get wangshibo
- "666666"
- 测试长key - value
- 182.48.115.236:22121> set huihuihuihuihuihui "hahahahahahahahhahahahahahahahhahahahahahah"
- OK
- 182.48.115.236:22121> get huihuihuihuihuihui
- "hahahahahahahahhahahahahahahahhahahahahahah"
- 登录两台redis节点上查看,发现已经有分片了
- [root@redis-server1 ~]# redis-cli -h 182.48.115.237 -p 6379
- 182.48.115.237:6379> get wangshibo
- "666666"
- 182.48.115.237:6379> get huihuihuihuihuihui
- "hahahahahahahahhahahahahahahahhahahahahahah"
- [root@redis-server2 ~]# redis-cli -h 182.48.115.238 -p 6379
- 182.48.115.238:6379> get wangshibo
- "666666"
- 182.48.115.238:6379> get huihuihuihuihuihui
- "hahahahahahahahhahahahahahahahhahahahahahah"
Redis集群知识解析的更多相关文章
- redis集群架构(含面试题解析)
老规矩,我还是以循序渐进的方式来讲,我一共经历过三套集群架构的演进! Replication+Sentinel 这套架构使用的是社区版本推出的原生高可用解决方案,其架构图如下! 这里Sentinel的 ...
- Couchbase集群和Redis集群解析
Couchbase集群和Redis集群解析 首先,关于一些数据库或者是缓存的集群有两种结构,一种是Cluster;一种是master-salve. 关于缓存系统一般使用的就是Redis,Redis是开 ...
- 【原创】那些年用过的Redis集群架构(含面试解析)
引言 今天是2019年2月12号,也就是大年初八,我接到了高中同学刘有码面试失利的消息. 他面试的时候,身份是某知名公司的小码农一枚,却因为不懂自己生产上Redis是如何部署的,导致面试失败! 人间惨 ...
- 【转】那些年用过的Redis集群架构(含面试解析)
引言 今天是2019年2月12号,也就是大年初八,我接到了高中同学刘有码面试失利的消息. 他面试的时候,身份是某知名公司的小码农一枚,却因为不懂自己生产上Redis是如何部署的,导致面试失败! 人间惨 ...
- 架构师之路-redis集群解析
引子 上篇<架构师之路-https底层原理>里我提到了上面的整体视图,文章也介绍了想要真正能在工作中及时正确解决问题的基本功:原理理解透彻.今天以redis集群解析为例介绍一个及时敏锐的发 ...
- Redis Cluster集群知识学习总结
Redis集群解决方案有两个: 1) Twemproxy: 这是Twitter推出的解决方案,简单的说就是上层加个代理负责分发,属于client端集群方案,目前很多应用者都在采用的解决方案.Twem ...
- redis集群讨论
一.生产应用场景 二.存储架构演变 三.应用最佳实践 四.运维经验总结 第1.2节:介绍redis cluster在唯品会的生产应用场景,以及存储架构的演变.第3节:redis cluster的稳定性 ...
- Redis集群研究和实践(基于redis 3.0.5)
前言 redis 是我们目前大规模使用的缓存中间件,由于它强大高效而又便捷的功能,得到了广泛的使用.现在的2.x的稳定版本是2.8.19,也是我们项目中普遍用到的版本. redis在年初发布了3.0. ...
- Redis集群最佳实践
今天我们来聊一聊Redis集群.先看看集群的特点,我对它的理解是要需要同时满足高可用性以及可扩展性,即任何时候对外的接口都要是基本可用的并具备一定的灾备能力,同时节点的数量能够根据业务量级的大小动态的 ...
随机推荐
- EntityFramework5学习
在开发面向数据的软件时我们常常为了解决业务问题实体.关系和逻辑构建模型而费尽心机,ORM的产生为我们提供了一种优雅的解决方案.ADO.NET Entity Framework是.NET开发中一种由AD ...
- Vue列表渲染
gitHub地址:https://github.com/lily1010/vue_learn/tree/master/lesson09 一 for循环数组 <!DOCTYPE html> ...
- jQuery中的尺寸及位置的取和设
1.offset(); 获取位置值: $(selector).offset().left; $(selector).offset().top; 设置位置值: $(selector).offset({t ...
- JTS Geometry关系判断和分析
关系判断 Geometry之间的关系有如下几种: 相等(Equals): 几何形状拓扑上相等. 脱节(Disjoint): 几何形状没有共有的点. 相交(Intersects): 几何形状至少有一个共 ...
- Oracle SQL Tips
左连接的同时只输出关联表的一条记录 WITH X AS (SELECT 1 ID FROM DUAL UNION SELECT 2 FROM DUAL UNION SELECT 3 FROM DUAL ...
- IOS 欢迎页(UIScrollView,UIPageControl)
本文介绍了app欢迎页的简单实现.只有第一次运行程序时才说会出现,其余时间不会出现.下面是效果图. 代码如下:(如有不明白的可以评论我,我会详细讲解) // // ViewController.m / ...
- Block的使用及循环引用的解决
Block是一个很好用的东西,这篇文章主要来介绍:1.什么是Block?2.Block的使用?3.Block的循环引用问题及解决. 1.什么是Block? 说这个问题之前,我先来说一下闭包(Closu ...
- mysql高可用之DRBD + HEARTBEAT + MYSQL
1. 架构 Mysql: master<=slave 10.24.6.4:3306<=10.24.6.6:3306 VIP: 10.24.6.20 必须使得VIP和mysql处于同一网段, ...
- Java Concurrency In Practice - Chapter 1 Introduction
1.1. A (Very) Brief History of Concurrency motivating factors for multiple programs to execute simul ...
- keepalived初探
keepalived起初是为LVS设计的,专门用来监控LVS集群系统中各个real server的健康状况的,后来又在其中实现了VRRP协议,VRRP即virtual router redundanc ...